Spring Cloud 概述: 一文看懂 Spring Cloud 到底在干嘛
Spring Cloud 概述: 一文看懂 Spring Cloud 到底在干嘛
文章目录
- Spring Cloud 概述: 一文看懂 Spring Cloud 到底在干嘛
-
- 简介
- 参考
- 正文
-
- 什么是 Spring Cloud?
- 核心模块
-
- Service Discovery 服务发现
- Configuration 服务配置
- Routing & Messaging 路由 & 消息传递
- API Gateway 服务网关
- Circuit Breakers 断路器
- Tracing 服务追踪
- CI Pipeline & Testing 自动化集成 & 测试
- 结语
简介
经过一些前后端项目的洗礼,也经历过几次使用 SpringBoot 开发后端服务器,搭配 mybatis + mysql 数据库、redis 缓存等技术。接下来从本篇开始将要开始进入微服务的架构。
Spring 全家桶继 SpringBoot 之后最火的技术便是 SpringCloud 微服务架构。有关什么是微服务可以查看参考链接,网络上也有很多对于微服务的说明和讨论,接下来我们就来纵览 Spring Cloud 到底有哪些成员以及功能吧!
备注:推荐读者可以先去看看参考链接二的视频再回来本篇的说明,会有更清晰的认识
参考
| 什么是微服务架构? | https://www.zhihu.com/question/65502802 |
| The Beginner’s Guide To Spring Cloud - Ryan Baxter | https://www.youtube.com/watch?v=aO3W-lYnw-o&t=3538s |
| Spring Cloud | https://spring.io/projects/spring-cloud |
| SpringCloud之Eureka注册中心原理及其搭建 | https://www.cnblogs.com/jing99/p/11576133.html |
| 分布式配置——Spring Cloud Configuration | https://www.jianshu.com/p/b43f41cdcbe2 |
| 从0开始构建你的api网关--Spring Cloud Gateway网关实战及原理解析 | https://www.cnblogs.com/davidwang456/p/10411451.html |
| 断路器(Curcuit Breaker)模式 | https://www.cnblogs.com/chry/p/7278853.html |
| Spring Cloud Pipeline–契约测试(Contracts Test) | http://huhanlin.com/2018/06/06/spring-cloud-pipeline-%E5%A5%91%E7%BA%A6%E6%B5%8B%E8%AF%95%EF%BC%88contracts-test%EF%BC%89/ |
正文
什么是 Spring Cloud?
我先假设读者都查过微服务是个啥东西了(还不知道的先去查一查吧),那么话说这个 Spring Cloud 又是个啥东西呢?很多人的第一印象就是(包括我也是):哦就是 Spring 全家桶中关于微服务架构的项目。
嗯你要这样理解也没错,不过有些过于笼统了。Spring Cloud 跟 Spring Boot 不一样,并不是单一个核心项目组成的框架。我们知道想要写 MVC 风格的 web 服务器,那就用 spring-boot-starter-web 作为核心依赖,再根据数据库和采用技术的需要搭上相应的 JDBC 就行了。
然而 Spring Cloud 却是指众多依赖的集合,各个依赖分别实现微服务架构所需要的各个核心功能,多个功能共同作用才组成我们所谓的微服务架构。
核心模块
既然我们了解了 Spring Cloud 其实是一堆依赖的集合,接下来我们就来介绍 Spring Cloud 的核心特性(feature),每个特性可能存在多个依赖都能发挥类似的作用(例如 Hibernate 与 Mybatis 都作为数据库链接的抽象层依赖使用),首先根据官方解释可分为一下几种特性:
| Features | Usage |
|---|---|
| Distributed/versioned configuration | 分布式/版本配置 |
| Service registration and discovery | 服务注册&发现 |
| Routing | 路由 |
| Service-to-service calls | 服务间调用 |
| Load balancing | 负载均衡 |
| Circuit Breakers | 断路器 |
| Global locks | 全局锁 |
| Leadership election and cluster state | 集群控制&选拔 |
| Distributed messaging | 分布式消息通知 |
相关的主要项目(main projects)有下列这些:
| Spring Cloud Config | Spring Cloud Netflix | Spring Cloud Bus | Spring Cloud Cloudfoundry |
| Spring Cloud Open Service Broker | Spring Cloud Cluster | Spring Cloud Consul | Spring Cloud Security |
| Spring Cloud Sleuth | Spring Cloud Data Flow | Spring Cloud Stream | Spring Cloud Stream App Starters |
| Spring Cloud Task | Spring Cloud Task App Starters | Spring Cloud Zookeeper | Spring Cloud Connectors |
| Spring Cloud Starters | Spring Cloud CLI | Spring Cloud Contract | Spring Cloud Gateway |
| Spring Cloud OpenFeign | Spring Cloud Pipelines | Spring Cloud Function |
相关社区实在是非常活跃,项目也是一个接一个的冒出来hhh,刚入门的时候真的是眼花缭乱。所以我们稍微重新划分整理一下,并挑出几个不敢说一定是最核心但势必是最具代表性的几个模块来解说(也是参考链接二的视频):

(由于排版问题模块顺序和位置不具意义,以下列介绍顺序为准)
接下来我们就一个个来介绍各个模块的意义和可用项目(可用项目名统一省略 Spring Cloud 前缀)吧。
Service Discovery 服务发现
代表项目:Netflix Eureka、Zookeeper、Consul
首先按照微服务的构建进程,我第一个想介绍的服务是 Service Discovery(服务发现)。其实这个服务的完整说法应该参照官方的分类:Service registration and discovery 服务的注册和查找
微服务相当于将过于庞大的系统按照服务切分为多个独立的服务分别开发、部署、应用,也就是我们一直在说的微服务(microservice)。所谓的服务发现就是将众多的微服务作为独立的服务客户端(client),向一个或多个注册中心(register center)注册自己所能提供的服务信息,如下图所示。
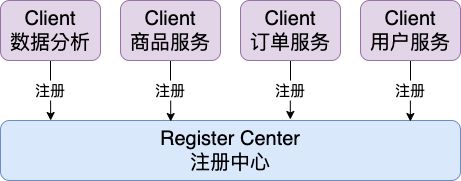
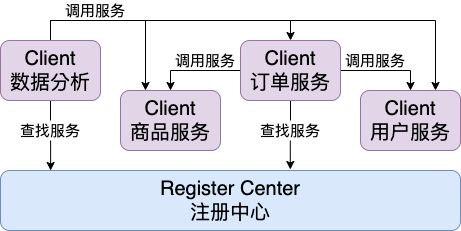
而每次需要查找系统内其他微服务的时候,只需要从注册中中心查找服务注册信息就能够找到对应的服务客户端了,而不需要记住实际的位置信息。
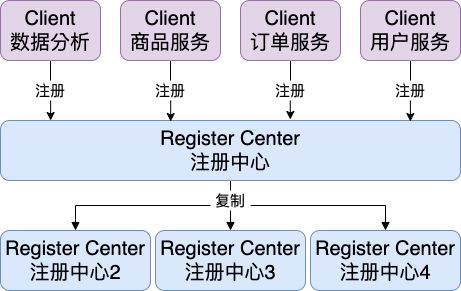
甚至我们还能够透过复制注册中心来实现服务发现的高可用性(注册中心死掉之后可以自动推举出新的注册中心,避免系统崩溃)
Configuration 服务配置
代表项目:Config
第二个模块是服务配置,当我们创建出多个微服务(microservice)之后,必然需要为每个服务进行相应的配置,可能有些配置需要每个服务一致(公共配置)、也可能是各个服务独有的配置(私有配置),因此将会差生许多配置文件如下图

这时候会差生一个问题,很多时候我们可能只是想根据运行模式、部署模式等原因修改配置,但是由于配置项跟项目源码绑定在一起且在启动时固定引入了。每次进行单纯的配置修改就需要整个项目重新打包、集成、部署 blablabla 的,即便整个流程自动化依旧会严重影响效率。
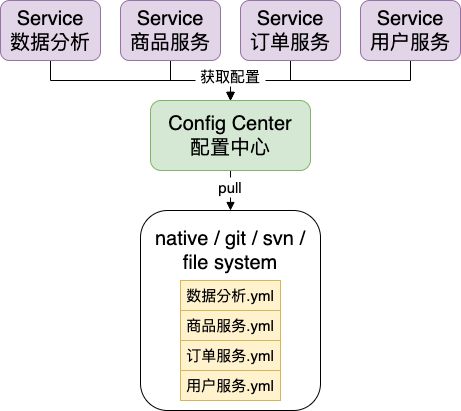
Configuration 服务配置便提供这样一个功能:将服务配置和服务本身分离,统一交由一个配置中心(config center)来管理,至于配置文件的来源就由配置中心决定,对于服务本身是不可见的,可以是本地 / git 仓库 / svn / 文件系统等多种数据源
Routing & Messaging 路由 & 消息传递
代表项目:Netflix Ribbon、Open Feign(Routing & Load Balancing)、RabbitMQ、Kafka(Messaging)
接着回到第一个模块提到的,我们的微服务中可能会差生服务间调用(service-to-service calls)。如果我们就这么放任它直接简单的透过 HTTP 请求/响应的话,那就与一般外部使用者的调用一样。这样不是不行,但是既然属于内部的服务调用,我们就应该对它有进一步的控制。
对于服务间调用我们可以使用某种消息队列(Message Queue)来进行消息传递,借此与外部一般请求做区分,也能够对内部调用有更进一步的掌控(如请求排序、优先级等判断),这就是 Messaging 消息传递 在做的事
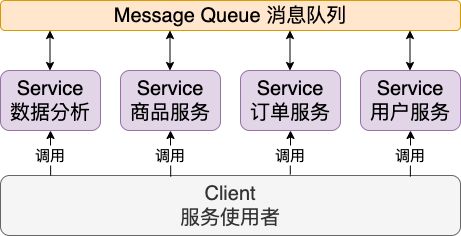
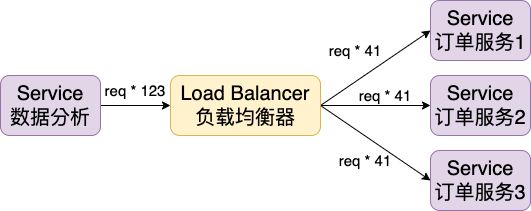
同时我们还可以在此基础上对这些服务间调用实现负载均衡(Load Balancing),将调用平均分配给多个实例提高利用率和性能。
API Gateway 服务网关
代表项目:Netflix Zuul、Gateway
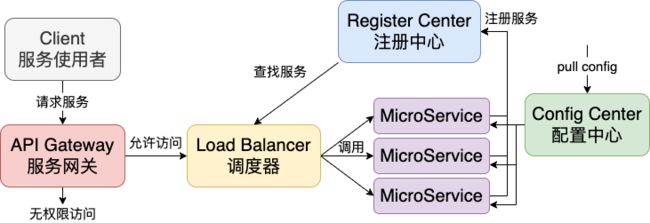
在安全性方面,本来所有服务写在同一个 Spring Boot 项目的时候,我们可以使用 Spring Security 来统一管理控制访问 API 的权限、跨域、流量控制等问题;当我们将服务切分成微服务时势必也需要类似的角色来统一处理这些事情(如果我们将网关分散到各个服务内部会使得整个服务体系权限管理混乱不堪,同时极有可能因此多出太多不必要的检查引发性能问题),这个角色在 Spring Cloud 里面就是由 API Gateway 服务网关来负责(图中稍微加入前面的几个服务)
Circuit Breakers 断路器
代表项目:Netflix Hystrix
下一个比较特别,是关于服务错误处理和恢复。上面几个服务已经能够组合成基本的微服务架构了,然而我们能注意到服务间调用存在一个盲区,当前的内部调用没办法检查服务的可用状态,仅仅只是“调用”而已。所以当服务因为某些原因不可用(数据库错误、服务过载、主动停用等),调用方并不知道服务已经无效了还是会不断的调用直到超时(timeout)
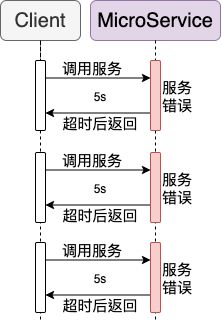
试想一下如果短时间重复发送请求或是多层调用,那只需要简单的几个请求就足以在超时过程中使服务器过载或是异常的延迟(一等就是天荒地老,或是因为内部调用累加使得所有服务都超时)
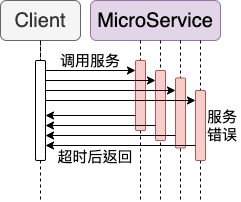
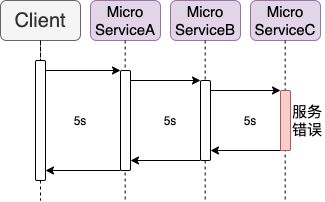
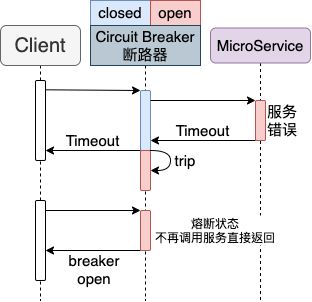
这时候我们就能够借由 Circuit Breakers 断路器模式的实现,在一定次数的失败之后进入(trip)熔断状态(breaker open),也就是宣告服务失效,等待服务重启或是其他方法重置(reset)才能再次提供服务(breaker close)
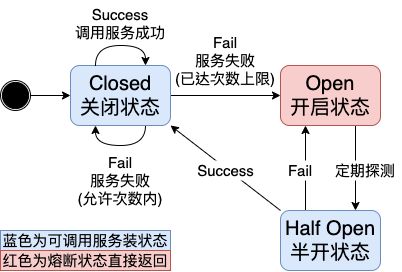
最后我们给出通用场景下,普通的断路器模式(circuit breaker)实现状态转移图(上图中的 trip 操作即为下图中请求 Fail 执行的状态转移)
Tracing 服务追踪
代表项目:Sleuth、Zipkin
Tracing 服务追踪的场景在于开发过程以及后期维护时,用于记录并追踪服务调用路径日志,方便程序员 debug。在原本的单体 Sprint Boot 应用中,我们可以直接从项目中找的确切的服务调用顺序(包括 Service 层的交互调用);至于在 Spring Cloud 中服务间调用(service-to-service calls)主要是依赖于 HTTP 或其他通信协议的跨服务器调用,我们就需要配置一个统一记录并追踪所有内部服务调用的类似日志模块(Logger)的功能(可能是一般日志形式,甚至能够表示成图数据结构并可视化展示)。
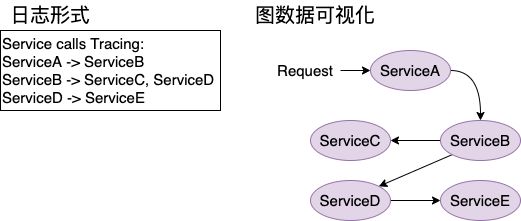
CI Pipeline & Testing 自动化集成 & 测试
代表项目:Pipelines、Contract
前面的各项特性从构建项目、架构、配置、服务可用性到服务追踪等,在整个软件开发的生命周期中就只剩下集成、测试到部署等,而这也正是最后一个特性所支持的。在微服务架构下,CI/CD 以及测试所面临问题与一般单体应用不大相同:
- 单体应用:在一般单体应用中自动化集成、测试等工具已经足够成熟,源代码开发完成后只要东东手指就能一键完成集成和部署
- 微服务架构:在微服务架构中当然你也可以把一个个服务分别
构建(build)然后再部署(deploy),这样一个自动化构建和单元测试的流程就是Pipeline 流水线提供的功能,如下图

然而这却会引发一些问题,例如当我们更新某个服务的版本,即便构建成功也透过单元测试(仅测试微服务内部单元),但是却依旧有可能与现存的其他微服务不相容(逻辑冲突甚至破坏接口)

这时候你会说那就在最后加上一个集成测试(E2E = End-to-End Test)吧,这样在集成测试的时候就能够提前发现服务不相容的问题
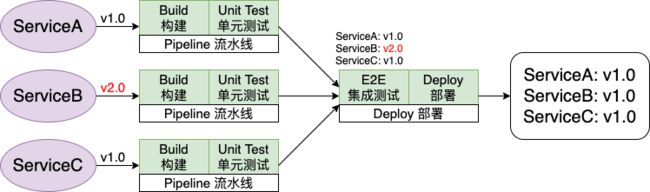
然而实际上这样做的后果就失去了微服务的意义了,因为不管是哪个服务的更新都要重新进行所有服务的集成测试,相当于整个微服务架构只是一个看起来分开的大型应用罢了。
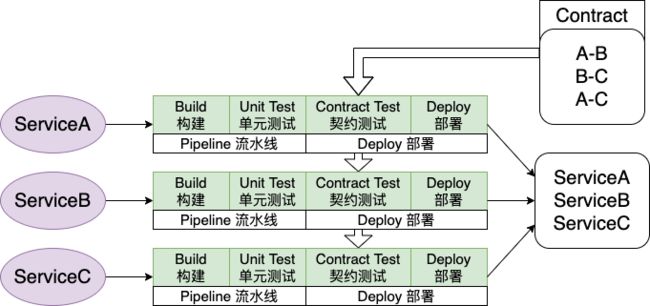
也就是说在微服务架构中的持续交付(CD)重点摆在微服务的独立交付问题上。既然都切分成了一个个的微服务,我们当然希望能各个模块独立(划重点)的集成、测试、交付。也就是说实际上我们的集成测试应该要长成这幅模样

这边的重点在于新的集成测试策略是每个服务交付时自己进行一次 E2E 测试(注意版本号,都是与当前最新通过测试的版本来做 E2E)。这时候会遗留一个问题,如果上图中两个 E2E 都通过了,还是有可能在部署后产生 v2.0 与 v3.0 的冲突,于是就要轮到契约测试(Contract Test)的登场了
- 契约测试 Contract Test
由于契约测试的不同实现相差较多,所以这边略微提一下通用概念就行了。
所谓的契约就是在每次集成时会根据微服务两两生成一个通过版本,之后的每一次契约测试都需要对现有“契约”进行测试,并更新契约,图示如下
有关微服务(分布式)的集成和测试还是一块非常大的领域,这边就不展开详细说明(就不跟专业的献丑了hhh
结语
终于写完了hhh,本来想着看看视频写写概念再来开始实践项目,但是实际上为了写这一篇就几乎快把每个服务的用法跟常用的依赖的概念和代码都快看了一遍才写得出来,也侧面证明实践才是帮助理解最快的途径。
下面几篇将开始实践 Spring Cloud 各个模块的服务和不同依赖的使用,敬请期待。