- Python PyV8: 在Python中运行JavaScript的利器
莱财一哥
本文还有配套的精品资源,点击获取简介:PythonPyV8是一个在Python环境中执行JavaScript代码的库,基于Google的V8JavaScript引擎,实现Python与JavaScript之间的互操作性。本文将详细讨论PyV8的安装方法,包括通过pip安装和自行编译安装特定版本的步骤,以及如何在Python程序中使用PyV8执行JavaScript代码。1.PythonPyV8库介
- Pycharm开发Djnago项目部署详细教程(2021更新)
af9f873c915c
项目部署:这里用的是非常干净的ubuntu16.04系统环境,没有使用任何云服务器,原因是因为不同的云服务器环境都不一样。我们就从零开始来完成部署。在开发机上的准备工作:确认项目没有bug。用pipfreeze>requirements.txt将当前环境的包导出到requirements.txt文件中,方便部署的时候安装。把dysms_python文件准备好。因为短信验证码的这个包必须通过将项目上
- 医疗AI与融合数据库的整合:挑战、架构与未来展望(上)
Loving_enjoy
计算机学科论文创新点机器学习facebook课程设计经验分享
在医疗AI爆发式增长的今天,单一数据库已无法满足多模态医疗数据的处理需求。本文将揭秘医疗融合数据库的核心架构,通过真实代码示例展示如何破解医疗数据整合的世纪难题。###一、医疗数据的"四维挑战"####1.多模态数据洪流```python#典型患者数据组成patient_data={"时序数据":"ECG/EEG波形(1000Hz采样)","影像数据":"CT/MRI(单次扫描2GB+)","文本
- PyQt5学习笔记,带例子源码
一、很程序员,都喜欢开发windows桌面应用系统,基于python3开发,效率高二、PyQt5开发的桌面应用系统是可以跨平台的,可以在Mac上、Window上、Linux桌面系统上运行,以下为学习笔记及总级三、源码下载登录后复制1、QDateTimeEdit日期输入框setCalendarPopup弹出日期选择框setDisplayFormat("yyyy-MM-ddHH:mm:ss")设置展示
- DataWhale 二月组队学习-深入浅出pytorch-Task04
-273.15K
DataWhale组队学习学习pytorch人工智能
一、自定义损失函数1.损失函数的作用与自定义意义在深度学习中,损失函数(LossFunction)用于衡量模型预测结果与真实标签之间的差异,是模型优化的目标。PyTorch内置了多种常用损失函数(如交叉熵损失nn.CrossEntropyLoss、均方误差nn.MSELoss等)。但在实际任务中,可能需要针对特定问题设计自定义损失函数,例如:处理类别不平衡问题(如加权交叉熵)实现特殊业务需求(如对
- Python爬虫实战:高效提取与解析JSON格式数据
Python爬虫项目
python爬虫宽度优先数据库json深度优先开发语言
1.JSON数据爬取概述在当今互联网时代,JSON(JavaScriptObjectNotation)已成为最流行的数据交换格式之一。相比传统的HTML页面,JSON格式数据具有结构清晰、体积小、解析方便等优势,使得它成为API接口的首选数据格式。1.1为什么选择JSON数据爬取数据结构化:JSON数据本身就是结构化的,不需要像HTML那样进行复杂的解析传输高效:JSON通常比HTML体积小,传输
- 手绘电路图的节点和端点检测一个简化版的算法实现框架
zhangfeng1133
算法
于论文描述,我将提供一个简化版的算法实现框架,用于手绘电路图的节点和端点检测,并整合生成电路原理图。以下代码结合了YOLOv5目标检测和传统图像处理技术,符合论文中提到的98.2%mAP和92%节点识别准确率的关键指标。核心算法实现(Python+OpenCV+YOLOv5)importcv2importnumpyasnpimporttorchfromyolov5importYOLOv5#需要安装
- 大模型核心概念 | 嵌入模型(Embedding)、向量模型(Vector Model)
一、核心概念解析1.1嵌入模型(Embedding)作为AI领域的核心基础技术,嵌入模型通过将非结构化数据映射为低维稠密向量,实现语义特征的深度捕捉:文本嵌入:如将语句转换为1536维向量,使"机器学习"与"深度学习"的向量余弦相似度达0.92跨模态嵌入:支持图像与文本的联合向量空间映射,如CLIP模型实现文图互搜1.2向量模型(VectorModel)作为嵌入技术的下游应用体系,主要包含两大方向
- Python实现神经网络算法指南
代码编织匠人
python神经网络算法
Python实现神经网络算法指南神经网络是一种模拟人脑神经元结构进行信息处理的机器学习算法。在深度学习领域中,神经网络是最为强大的算法之一。Python作为一门简单易学的编程语言,也成为了许多人选择实现神经网络算法的首选语言。在本篇文章中,我们将通过Python代码来实现神经网络算法。导入必要的库为了实现神经网络算法,我们需要导入一些必要的Python库,包括numpy和matplotlib。其中
- 使用LangChain构建多代理系统实现复杂任务自动化
LCG元
工具langchain自动化运维
目录一、系统架构设计模块说明:二、核心工作流程(双流程图对比)横向对比:单代理vs多代理纵向核心流程三、企业级实现方案1.Python核心代码(LangChain0.1.8+)2.TypeScript前端集成代码四、性能对比测试五、生产级部署方案安全审计要点:高可用部署拓扑:六、技术前瞻性分析附录:完整技术图谱摘要:本文深度解析如何基于LangChain框架构建企业级多代理系统,通过模块化架构设计
- 时序数据库选型避坑全攻略:IoTDB性能与成本双杀的秘密!
LCG元
数据库时序数据库iotdbjava
文章目录一、架构设计深度解析1.1IoTDB架构图谱1.2核心流程对比二、企业级实战代码2.1Python数据写入示例2.2TypeScript客户端实现2.3集群配置YAML三、性能对比分析四、生产部署方案4.1安全加固配置4.2安全策略实施五、技术前瞻分析5.1云原生演进路径5.2新型存储引擎预测六、技术图谱附录一、架构设计深度解析1.1IoTDB架构图谱数据写入协议适配层内存表管理持久化引擎
- 大规模图计算引擎的分区与通信优化:负载均衡与网络延迟的解决方案
LCG元
系统服务架构负载均衡网络运维
目录一、系统架构设计与核心流程1.1原创架构图解析1.2双流程对比分析二、分区策略优化实践2.1动态权重分区算法实现(Python)三、通信优化机制实现3.1基于RDMA的通信层实现(TypeScript)四、性能对比与调优4.1分区策略基准测试五、生产级部署方案5.1Kubernetes部署配置(YAML)5.2安全审计配置六、技术前瞻与演进附录:完整技术图谱一、系统架构设计与核心流程1.1原创
- 用Python实现神经网络(四)
使用多层神经网络我们展示如何用TensorFlow构建多层神经网络###低出生率数据LowBirthratedata:#Columns Variable Abbreviation#---------------------------------------------------------------------#Lo
- 基于DTLC-AEC与DTLN的轻量级实时语音增强系统设计与实现
神经网络15044
仿真模型神经网络机器学习图像处理cnn人工智能机器人
基于DTLC-AEC与DTLN的轻量级实时语音增强系统设计与实现前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住分享一下给大家。点击跳转到网站。1.引言在当今的互联网通信时代,实时语音通信已成为人们日常生活中不可或缺的一部分。然而,语音通信质量常常受到回声、背景噪声等因素的严重影响。为了解决这些问题,我们需要高效的语音增强技术。本文将详细介绍如何将DTLC-AEC(深度学习回声消
- 自平衡摩托车控制系统设计:Python实现方案
神经网络15044
仿真模型算法机器学习python开发语言
自平衡摩托车控制系统设计:Python实现方案摘要本文针对5CCE2MCT机电一体化补考项目要求,提出了一种基于Python的自平衡摩托车控制系统完整实现方案。该系统结合PID控制、状态空间方法和数字信号处理技术,实现了稳定的平衡与运动控制。我们从数学模型建立到硬件测试进行了完整展示,提供了可替代MATLAB/Simulink方案的可行解决方案。该实现方案在保持与参考Arduino工程套件相当性能
- python基础语法9,用os库实现系统操作并用sys库实现文件操作(简单易上手的python语法教学)
AI 嗯啦
python开发语言
一、os库os.system()是Pythonos库中用于执行操作系统命令的重要方法,它允许在Python程序中直接调用系统shell命令(如Linux的bash命令或Windows的cmd命令)。基本语法importosos.system(command)command:要执行的系统命令字符串(与在终端/命令提示符中输入的命令格式一致)返回值:命令执行的退出状态码(0表示成功,非0表示执行出错)
- Python教程:你一定要知道的26个Python魔术方法(快记下来)
旦莫
Python进阶python开发语言
Python中的魔术方法是指以双下划线__开头和结尾的特殊方法,也被称为特殊方法或魔术方法。这些方法在类中具有特殊的用途,它们可以让你自定义类的行为,使得你的对象可以像内置类型一样工作。这些方法由解释器调用,而不是你直接调用它们。例如,当你使用+运算符时,实际上是调用了对象的__add__方法。这些方法允许你重载运算符、改变对象的构造和初始化行为、自定义属性访问等等。使用魔术方法可以使你的代码更具
- 快捷删除python中pip安装的所有外部库
m0_74366096
pythonpip开发语言
windows环境首先,列出所有安装的第三方库并导出到一个文件:pipfreeze>requirements.txt然后,批量卸载这些库:pipuninstall-y-rrequirements.txt最后,用del命令删除requirements.txt文件:delrequirements.txt这样就能在Windows系统上完成卸载并清理文件的操作。
- Python与Java互操作性的桌面应用开发
master_chenchengg
pythonpythonPythonpython开发IT
Python与Java互操作性的桌面应用开发跨语言协作的魅力:Python遇上Java为什么选择Python和Java进行桌面应用开发?两种语言的优势互补:Python的简洁与Java的强大实际案例分享:当Python遇见Java,会发生什么奇妙的化学反应?搭建桥梁:Jython与JPype介绍Jython:用Python编写Java程序安装与配置:轻松几步让你上手调用Java类库:如何在Pyth
- Python常见的魔术方法和魔术属性
景天科技苑
python轻松入门基础语法到高阶实战教学python开发语言魔术方法魔术属性
文章目录魔术方法1、`__new__`魔术方法(1)基本使用(2)`__new__`触发时机要快于`__init__`(3)`__new__`的参数要和`__init__`参数一一对应。参数个数一致就行(4)`__new__`和`__init__`之间的注意点2、单态模式:同一个类,无论实例化多少次,都有且只有一个对象3、`__del__`魔术方法(析构方法)(1)基本语法(2)模拟文件操作4、`
- Docker 基本操作
dufufd
other
https://zhuanlan.zhihu.com/p/23599229Docker是什么?Docker是一个虚拟环境容器,可以将你的开发环境、代码、配置文件等一并打包到这个容器中,并发布和应用到任意平台中。比如,你在本地用Python开发网站后台,开发测试完成后,就可以将Python3及其依赖包、Flask及其各种插件、Mysql、Nginx等打包到一个容器中,然后部署到任意你想部署到的环境。
- python调用java的方法
月下老葫
python自动化测试pythonjava
最近自己开发的一套测试平台,因为上游系统经常修改主数据,导致其中一个功能经常失败,要频繁找上游测试帮忙修改数据。基于此种原因,对于这种过于依赖上游系统的接口,决定放弃直接调上游系统的http请求下发数据,改成调本地系统的java接口,直接构造数据。而这有两个难点,一个python怎么调用java方法,一个是我不会java编程。。。经常不懈的努力,终于解决了这2个问题,这里做个简单的记录。这里有同学
- 北京-4年功能测试2年空窗-报培训班学测开-第四十五天
今天自习,在教室白天都在复习python的面向对象之所以先复习以前的课而不是复习昨天的,一是因为这块还没复习,二是因为,新学的unittest框架,用到封装继承的部分太多了,面向对象学的都忘了,所以昨天很多部分都不理解面向对象三大特征,封装,继承,多态封装是把属性和方法封装到一个类里方便复用,继承是类之间的从属关系,子类可以继承父类的所有属性和方法在类里,类对象用cls表示,实例对象用self表示
- 在python程序中调用java代码
Meryoufdd
javajvm开发语言
在python程序中调用java代码Python是一门“胶水”语言,非常灵活多变,但是在一些特殊的时候,也需要调用其它语言来协助实现更多的功能;在公司使用python进行接口测试的时候,会遇到有些接口数据是由公司的开发人员进行自定义的加密算法进行加密的,此时,要开发告诉加密代码是不太可能的。跟开发小哥沟通时,很多时候都是由他给一个jar包,然后剩下的就由测试人员来发挥了。那python该如何使用这
- 学习日志14 python
im_AMBER
学习python开发语言
1divmod(a,b)divmod(a,b)是Python内置函数,用于返回两个数相除的商和余数,返回值是一个元组(tuple)。divmod(a,b)是Python的内置函数,用于同时计算两个数值的商和余数,返回一个包含这两个结果的元组(商,余数)。该函数在处理需要同时获取整除结果和余数的场景(如时间单位转换、分页计算)时非常高效。基本用法python运行result=divmod(a,b)#
- 离线部署视觉模型Qwen2.5-VL方案【企业应用级】
LensonYuan
机器视觉自然语言处理qwenvl视觉模型大模型部署qwen2.5qwen2.5环境qwen2.5-vl镜像包
离线多卡部署视觉模型Qwen2.5-VL企业级服务方案一、背景公司网络是有严格限制,所有涉及境外服务器的网站都无法访问,包括docker等镜像源。本教程,是在提前下载或构建好资源,通过上传到服务器后,做离线部署。二、参考环境大模型服务发布工具:VLLM=0.7.2。大模型版本:qwen2.5-vl-7b,其他版本也可。python版本:python==3.12。环境可选:docker或直接pyth
- 小白学Python,压缩和解压文件
目录前言一、判断文件是否为Zip文件二、打开压缩文件三、解压文件四、获取Zip文件中文件的属性信息前言Python标准库中的zipfile库可用于处理压缩文件,.zip是一种常用的压缩文件格式。zipfile库中包含用于查看Zip文件、解压Zip文件、将文件压缩为Zip文件等的方法。需要注意的是,在使用zipfile库前需要使用import导入zipfile库。一、判断文件是否为Zip文件zipf
- Python 魔术方法
坚定的小辣鸡在努力
Pythonpython开发语言
Python魔术方法Python中的魔术方法(MagicMethods),又叫“双下方法(dundermethods)”,像__init__、__str__、__eq__这样的名字,是Python面向对象非常强大的特性。阅读原文https://www.xiaozaoshu.top/articles/python/maigc-method常用魔术方法详解最常见也最有用的几个魔术方法:1.__init
- 《Python Web 框架深度剖析:Django、Flask 与 FastAPI 的选择之道》
清水白石008
课程教程学习笔记开发语言python前端django
《PythonWeb框架深度剖析:Django、Flask与FastAPI的选择之道》开篇引入:从“胶水语言”到Web架构核心Python,自1991年由GuidovanRossum发布以来,凭借其简洁优雅的语法和强大的生态系统,逐渐成为全球最受欢迎的编程语言之一。它不仅在数据科学、人工智能、自动化脚本等领域大放异彩,更在Web开发领域构建起一套成熟的技术体系。作为一位长期从事Python开发与教
- 目标检测-YOLOv5
wydxry
深度学习目标检测YOLO人工智能深度学习
YOLOv5介绍YOLOv5是YOLO系列的第五个版本,由Ultralytics团队发布。虽然YOLOv5并非JosephRedmon原团队发布,但它在YOLOv4的基础上进行了重要的优化和改进,成为了深度学习目标检测领域中的热门模型之一。YOLOv5的优势不仅体现在其性能上,还包括其简洁易用、部署便捷的特点。相较于YOLOv4,YOLOv5对于代码框架的重构、推理速度的提升,以及模型的轻量化等方
- 解读Servlet原理篇二---GenericServlet与HttpServlet
周凡杨
javaHttpServlet源理GenericService源码
在上一篇《解读Servlet原理篇一》中提到,要实现javax.servlet.Servlet接口(即写自己的Servlet应用),你可以写一个继承自javax.servlet.GenericServletr的generic Servlet ,也可以写一个继承自java.servlet.http.HttpServlet的HTTP Servlet(这就是为什么我们自定义的Servlet通常是exte
- MySQL性能优化
bijian1013
数据库mysql
性能优化是通过某些有效的方法来提高MySQL的运行速度,减少占用的磁盘空间。性能优化包含很多方面,例如优化查询速度,优化更新速度和优化MySQL服务器等。本文介绍方法的主要有:
a.优化查询
b.优化数据库结构
- ThreadPool定时重试
dai_lm
javaThreadPoolthreadtimertimertask
项目需要当某事件触发时,执行http请求任务,失败时需要有重试机制,并根据失败次数的增加,重试间隔也相应增加,任务可能并发。
由于是耗时任务,首先考虑的就是用线程来实现,并且为了节约资源,因而选择线程池。
为了解决不定间隔的重试,选择Timer和TimerTask来完成
package threadpool;
public class ThreadPoolTest {
- Oracle 查看数据库的连接情况
周凡杨
sqloracle 连接
首先要说的是,不同版本数据库提供的系统表会有不同,你可以根据数据字典查看该版本数据库所提供的表。
select * from dict where table_name like '%SESSION%';
就可以查出一些表,然后根据这些表就可以获得会话信息
select sid,serial#,status,username,schemaname,osuser,terminal,ma
- 类的继承
朱辉辉33
java
类的继承可以提高代码的重用行,减少冗余代码;还能提高代码的扩展性。Java继承的关键字是extends
格式:public class 类名(子类)extends 类名(父类){ }
子类可以继承到父类所有的属性和普通方法,但不能继承构造方法。且子类可以直接使用父类的public和
protected属性,但要使用private属性仍需通过调用。
子类的方法可以重写,但必须和父类的返回值类
- android 悬浮窗特效
肆无忌惮_
android
最近在开发项目的时候需要做一个悬浮层的动画,类似于支付宝掉钱动画。但是区别在于,需求是浮出一个窗口,之后边缩放边位移至屏幕右下角标签处。效果图如下:
一开始考虑用自定义View来做。后来发现开线程让其移动很卡,ListView+动画也没法精确定位到目标点。
后来想利用Dialog的dismiss动画来完成。
自定义一个Dialog后,在styl
- hadoop伪分布式搭建
林鹤霄
hadoop
要修改4个文件 1: vim hadoop-env.sh 第九行 2: vim core-site.xml <configuration> &n
- gdb调试命令
aigo
gdb
原文:http://blog.csdn.net/hanchaoman/article/details/5517362
一、GDB常用命令简介
r run 运行.程序还没有运行前使用 c cuntinue
- Socket编程的HelloWorld实例
alleni123
socket
public class Client
{
public static void main(String[] args)
{
Client c=new Client();
c.receiveMessage();
}
public void receiveMessage(){
Socket s=null;
BufferedRea
- 线程同步和异步
百合不是茶
线程同步异步
多线程和同步 : 如进程、线程同步,可理解为进程或线程A和B一块配合,A执行到一定程度时要依靠B的某个结果,于是停下来,示意B运行;B依言执行,再将结果给A;A再继续操作。 所谓同步,就是在发出一个功能调用时,在没有得到结果之前,该调用就不返回,同时其它线程也不能调用这个方法
多线程和异步:多线程可以做不同的事情,涉及到线程通知
&
- JSP中文乱码分析
bijian1013
javajsp中文乱码
在JSP的开发过程中,经常出现中文乱码的问题。
首先了解一下Java中文问题的由来:
Java的内核和class文件是基于unicode的,这使Java程序具有良好的跨平台性,但也带来了一些中文乱码问题的麻烦。原因主要有两方面,
- js实现页面跳转重定向的几种方式
bijian1013
JavaScript重定向
js实现页面跳转重定向有如下几种方式:
一.window.location.href
<script language="javascript"type="text/javascript">
window.location.href="http://www.baidu.c
- 【Struts2三】Struts2 Action转发类型
bit1129
struts2
在【Struts2一】 Struts Hello World http://bit1129.iteye.com/blog/2109365中配置了一个简单的Action,配置如下
<!DOCTYPE struts PUBLIC
"-//Apache Software Foundation//DTD Struts Configurat
- 【HBase十一】Java API操作HBase
bit1129
hbase
Admin类的主要方法注释:
1. 创建表
/**
* Creates a new table. Synchronous operation.
*
* @param desc table descriptor for table
* @throws IllegalArgumentException if the table name is res
- nginx gzip
ronin47
nginx gzip
Nginx GZip 压缩
Nginx GZip 模块文档详见:http://wiki.nginx.org/HttpGzipModule
常用配置片段如下:
gzip on; gzip_comp_level 2; # 压缩比例,比例越大,压缩时间越长。默认是1 gzip_types text/css text/javascript; # 哪些文件可以被压缩 gzip_disable &q
- java-7.微软亚院之编程判断俩个链表是否相交 给出俩个单向链表的头指针,比如 h1 , h2 ,判断这俩个链表是否相交
bylijinnan
java
public class LinkListTest {
/**
* we deal with two main missions:
*
* A.
* 1.we create two joined-List(both have no loop)
* 2.whether list1 and list2 join
* 3.print the join
- Spring源码学习-JdbcTemplate batchUpdate批量操作
bylijinnan
javaspring
Spring JdbcTemplate的batch操作最后还是利用了JDBC提供的方法,Spring只是做了一下改造和封装
JDBC的batch操作:
String sql = "INSERT INTO CUSTOMER " +
"(CUST_ID, NAME, AGE) VALUES (?, ?, ?)";
- [JWFD开源工作流]大规模拓扑矩阵存储结构最新进展
comsci
工作流
生成和创建类已经完成,构造一个100万个元素的矩阵模型,存储空间只有11M大,请大家参考我在博客园上面的文档"构造下一代工作流存储结构的尝试",更加相信的设计和代码将陆续推出.........
竞争对手的能力也很强.......,我相信..你们一定能够先于我们推出大规模拓扑扫描和分析系统的....
- base64编码和url编码
cuityang
base64url
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.io.PrintWriter;
import java.io.StringWriter;
import java.io.UnsupportedEncodingException;
- web应用集群Session保持
dalan_123
session
关于使用 memcached 或redis 存储 session ,以及使用 terracotta 服务器共享。建议使用 redis,不仅仅因为它可以将缓存的内容持久化,还因为它支持的单个对象比较大,而且数据类型丰富,不只是缓存 session,还可以做其他用途,一举几得啊。1、使用 filter 方法存储这种方法比较推荐,因为它的服务器使用范围比较多,不仅限于tomcat ,而且实现的原理比较简
- Yii 框架里数据库操作详解-[增加、查询、更新、删除的方法 'AR模式']
dcj3sjt126com
数据库
public function getMinLimit () { $sql = "..."; $result = yii::app()->db->createCo
- solr StatsComponent(聚合统计)
eksliang
solr聚合查询solr stats
StatsComponent
转载请出自出处:http://eksliang.iteye.com/blog/2169134
http://eksliang.iteye.com/ 一、概述
Solr可以利用StatsComponent 实现数据库的聚合统计查询,也就是min、max、avg、count、sum的功能
二、参数
- 百度一道面试题
greemranqq
位运算百度面试寻找奇数算法bitmap 算法
那天看朋友提了一个百度面试的题目:怎么找出{1,1,2,3,3,4,4,4,5,5,5,5} 找出出现次数为奇数的数字.
我这里复制的是原话,当然顺序是不一定的,很多拿到题目第一反应就是用map,当然可以解决,但是效率不高。
还有人觉得应该用算法xxx,我是没想到用啥算法好...!
还有觉得应该先排序...
还有觉
- Spring之在开发中使用SpringJDBC
ihuning
spring
在实际开发中使用SpringJDBC有两种方式:
1. 在Dao中添加属性JdbcTemplate并用Spring注入;
JdbcTemplate类被设计成为线程安全的,所以可以在IOC 容器中声明它的单个实例,并将这个实例注入到所有的 DAO 实例中。JdbcTemplate也利用了Java 1.5 的特定(自动装箱,泛型,可变长度
- JSON API 1.0 核心开发者自述 | 你所不知道的那些技术细节
justjavac
json
2013年5月,Yehuda Katz 完成了JSON API(英文,中文) 技术规范的初稿。事情就发生在 RailsConf 之后,在那次会议上他和 Steve Klabnik 就 JSON 雏形的技术细节相聊甚欢。在沟通单一 Rails 服务器库—— ActiveModel::Serializers 和单一 JavaScript 客户端库——&
- 网站项目建设流程概述
macroli
工作
一.概念
网站项目管理就是根据特定的规范、在预算范围内、按时完成的网站开发任务。
二.需求分析
项目立项
我们接到客户的业务咨询,经过双方不断的接洽和了解,并通过基本的可行性讨论够,初步达成制作协议,这时就需要将项目立项。较好的做法是成立一个专门的项目小组,小组成员包括:项目经理,网页设计,程序员,测试员,编辑/文档等必须人员。项目实行项目经理制。
客户的需求说明书
第一步是需
- AngularJs 三目运算 表达式判断
qiaolevip
每天进步一点点学习永无止境众观千象AngularJS
事件回顾:由于需要修改同一个模板,里面包含2个不同的内容,第一个里面使用的时间差和第二个里面名称不一样,其他过滤器,内容都大同小异。希望杜绝If这样比较傻的来判断if-show or not,继续追究其源码。
var b = "{{",
a = "}}";
this.startSymbol = function(a) {
- Spark算子:统计RDD分区中的元素及数量
superlxw1234
sparkspark算子Spark RDD分区元素
关键字:Spark算子、Spark RDD分区、Spark RDD分区元素数量
Spark RDD是被分区的,在生成RDD时候,一般可以指定分区的数量,如果不指定分区数量,当RDD从集合创建时候,则默认为该程序所分配到的资源的CPU核数,如果是从HDFS文件创建,默认为文件的Block数。
可以利用RDD的mapPartitionsWithInd
- Spring 3.2.x将于2016年12月31日停止支持
wiselyman
Spring 3
Spring 团队公布在2016年12月31日停止对Spring Framework 3.2.x(包含tomcat 6.x)的支持。在此之前spring团队将持续发布3.2.x的维护版本。
请大家及时准备及时升级到Spring
- fis纯前端解决方案fis-pure
zccst
JavaScript
作者:zccst
FIS通过插件扩展可以完美的支持模块化的前端开发方案,我们通过FIS的二次封装能力,封装了一个功能完备的纯前端模块化方案pure。
1,fis-pure的安装
$ fis install -g fis-pure
$ pure -v
0.1.4
2,下载demo到本地
git clone https://github.com/hefangshi/f

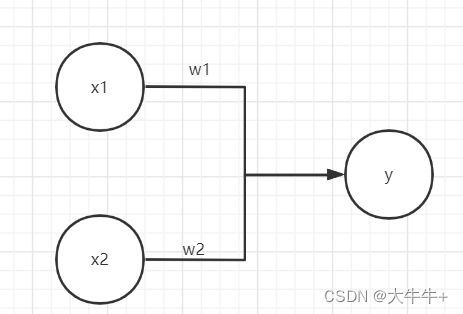
 为初始化权重所计算得出的估计值
为初始化权重所计算得出的估计值 :
: