35、ubuntu20.04搭建瑞芯微的npu仿真环境和测试rv1126的Debain系统下的yolov5+npu检测功能以及RKNN推理部署
基本思想:手中有一块core-1126/1109-JD4,记录一下其刷机过程和开发人数统计,与树莓派的nanodet 每帧200ms对比一下



第一步:刷机,真的是难,各种各样的小问题,反正成功的方法只有一个,遇到问题,断电重新进行连接,刷机,基本都能解决上次的问题,这说的我都无语了,刷的debain10系统
这里注意是otg接口 外侧边缘的usb接口
刷机固件网址和方法参考官方手册,附录固件升级
工具是:F:\rv1126\RKDevTool\RKDevTool_Release_v2.86
镜像是:F:\rv1126\AIO-RV1126(1109)-JD4\Buildroot\薪火车牌识别固件\AIO-RV1126_RV1109-XHLPR_IPC_2021_0906_1125
替换配置是:F:\rv1126\Debian10\debian10_2021_0429_1902
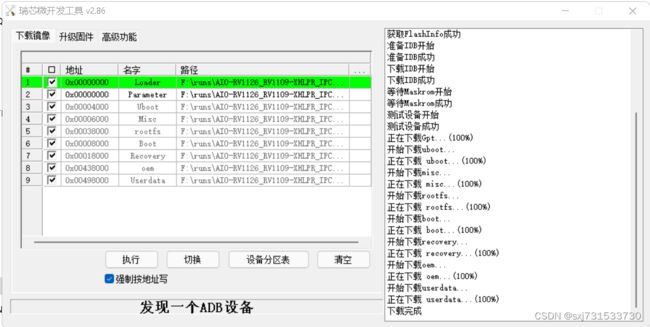
第二步:插上网线,进行ip地址搜索
在window的cmd命令行中,输入搜索命令
C:\Users\Administrator>for /L %i IN (1,1,254) DO ping -w 2 -n 1 192.168.10.%i
显示搜索同一网络下的ip地址
C:\Users\Administrator>arp -a
Interface: 192.168.10.155 --- 0x9
Internet Address Physical Address Type
192.168.10.1 ff-ff-ff-ff-ff-ff dynamic
192.168.10.117 ff-ff-ff-ff-ff-ff dynamic
192.168.10.134 ff-ff-ff-ff-ff-ff dynamic
192.168.10.210 ff-ff-ff-ff-ff-ff dynamic
192.168.10.255 ff-ff-ff-ff-ff-ff static
224.0.0.2 01-00-5e-00-00-02 static
224.0.0.22 01-00-5e-00-00-16 static
224.0.0.251 01-00-5e-00-00-fb static
224.0.0.252 01-00-5e-00-00-fc static
239.255.255.250 ff-ff-ff-ff-ff-ff static
255.255.255.255 ff-ff-ff-ff-ff-ff static然后进行ssh远程连接用户名:firefly密码:firefly 使用方法 — Firefly Wiki
ubuntu@sxj731533730:~$ ssh [email protected]
[email protected]'s password:
Linux firefly 4.19.111 #1 SMP PREEMPT Thu Jul 8 17:38:26 CST 2021 armv7l
The programs included with the Debian GNU/Linux system are free software;
the exact distribution terms for each program are described in the
individual files in /usr/share/doc/*/copyright.
Debian GNU/Linux comes with ABSOLUTELY NO WARRANTY, to the extent
permitted by applicable law.
firefly@firefly:~$第三步:参考手册配置,参考附录RKNN使用
补充:官方支持了python3.8,可以不用安装conda环境
RKNN-Toolkit Version 1.7.3已正式发布,请大家尽量使用最新版本!
https://github.com/rockchip-linux/rknn-toolkit
https://github.com/rockchip-linux/rknpu
GitHub - airockchip/RK3399Pro_npu
OP支持情况:
https://github.com/rockchip-linux/rknn-toolkit/blob/master/doc/RKNN_OP_Support_V1.7.3.md
主要更新:
1. 功能优化:
精度分析接口打印各层精度信息时显示量化类型。
完善图优化规则。
2. 完善op支持,给出op限制表格。
3. 移除对Ubuntu 16.04 / Python3.5的支持,增加对Ubuntu20.04 / Python3.8的支持。
4. 升级部分依赖模块。
5. 修复已知bug
本博客写的早,所以仍然安装conda环境和配置输出
firefly@firefly:~$ sudo apt-get update && sudo apt-get install python3-pip
firefly@firefly:~$ pip3 install numpy==1.16.3 psutil==5.6.2 ruamel.yaml==0.15.81 -i https://pypi.tuna.tsinghua.edu.cn/simple
firefly@firefly:~$ sudo apt-get install wget git cmake
firefly@firefly:~$ sudo apt-get install multiarch-support
firefly@firefly:~$ wget http://security.debian.org/debian-security/pool/updates/main/j/jasper/libjasper1_1.900.1-debian1-2.4+deb8u6_armhf.deb
firefly@firefly:~$ sudo dpkg -i libjasper1_1.900.1-debian1-2.4+deb8u6_armhf.deb
firefly@firefly:~$ wget http://security.debian.org/debian-security/pool/updates/main/j/jasper/libjasper-dev_1.900.1-debian1-2.4+deb8u6_armhf.deb
firefly@firefly:~$ sudo dpkg -i libjasper-dev_1.900.1-debian1-2.4+deb8u6_armhf.deb
firefly@firefly:~$ sudo apt-get install libhdf5-dev
firefly@firefly:~$ sudo apt-get install libatlas-base-dev
firefly@firefly:~$ sudo apt-get install libqtgui4
firefly@firefly:~$ sudo apt-get install libqt4-test
firefly@firefly:~$ git clone https://github.com/rockchip-linux/rknn-toolkit.git
firefly@firefly:~$ wget https://www.piwheels.org/simple/opencv-python/opencv_python-4.0.1.24-cp37-cp37m-linux_armv7l.whl
firefly@firefly:~$ pip3 install opencv_python-4.0.1.24-cp37-cp37m-linux_armv7l.whl
Processing ./opencv_python-4.0.1.24-cp37-cp37m-linux_armv7l.whl
Requirement already satisfied: numpy>=1.16.2 in ./.local/lib/python3.7/site-packages (from opencv-python==4.0.1.24) (1.16.3)
Installing collected packages: opencv-python
Successfully installed opencv-python-4.0.1.24
firefly@firefly:~/rknn-toolkit/rknn-toolkit-lite/packages$ pip3 install rknn_toolkit_lite-1.7.1-cp37-cp37m-linux_armv7l.whl
Processing ./rknn_toolkit_lite-1.7.1-cp37-cp37m-linux_armv7l.whl
Requirement already satisfied: ruamel.yaml==0.15.81 in /home/firefly/.local/lib/python3.7/site-packages (from rknn-toolkit-lite==1.7.1) (0.15.81)
Requirement already satisfied: numpy==1.16.3 in /home/firefly/.local/lib/python3.7/site-packages (from rknn-toolkit-lite==1.7.1) (1.16.3)
Requirement already satisfied: psutil==5.6.2 in /home/firefly/.local/lib/python3.7/site-packages (from rknn-toolkit-lite==1.7.1) (5.6.2)
Installing collected packages: rknn-toolkit-lite
Successfully installed rknn-toolkit-lite-1.7.1
firefly@firefly:~$ python3
Python 3.7.3 (default, Jan 22 2021, 20:04:44)
[GCC 8.3.0] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> from rknnlite.api import RKNNLite
>>>第四步:配置pc端转,支持模型转rknnn和生成模型移植到板子上使用RKNNlite调用 rknn_toolkit :Index of /pypi/simple/
ubuntu@ubuntu:~$ wget https://mirrors.tuna.tsinghua.edu.cn/anaconda/miniconda/Miniconda3-latest-Linux-x86_64.sh
ubuntu@ubuntu:~$ bash Miniconda3-latest-Linux-x86_64.sh
ubuntu@ubuntu:~$ source ~/.bashrc
ubuntu@ubuntu:~$ conda config --set auto_activate_base false
ubuntu@ubuntu:~$ conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/
ubuntu@ubuntu:~$ conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main/
ubuntu@ubuntu:~$ conda config --set show_channel_urls yes
ubuntu@ubuntu:~$ conda create -n rknnpy36 python=3.6
ubuntu@ubuntu:~$ conda activate rknnpy36
(rknnpy36) ubuntu@ubuntu:~$ git clone https://github.com/rockchip-linux/rknn-toolkit.git
(rknnpy36) ubuntu@ubuntu:~/Downloads/rknn-toolkit-master/packages$ pip3 install -r requirements-cpu.txt -i https://pypi.tuna.tsinghua.edu.cn/simple
(rknnpy36) ubuntu@ubuntu:~/Downloads/rknn-toolkit-master/packages$ pip3 install -r requirements-cpu.txt
(rknnpy36) ubuntu@ubuntu:~/Downloads/rknn-toolkit-master/rknn-toolkit-lite/packages$ (rknnpy36) ubuntu@ubuntu:~/rknn-toolkit/rknn-toolkit-lite/packages$ pip3 install rknn_toolkit_lite-1.6.1-cp36-cp36m-linux_x86_64.whl -i https://pypi.tuna.tsinghua.edu.cn/simple
Looking in indexes: https://pypi.tuna.tsinghua.edu.cn/simple
Processing ./rknn_toolkit_lite-1.7.1-cp36-cp36m-linux_x86_64.whl
Requirement already satisfied: ruamel.yaml==0.15.81 in /home/ubuntu/miniconda3/envs/rknnpy36/lib/python3.6/site-packages (from rknn-toolkit-lite==1.7.1) (0.15.81)
Requirement already satisfied: numpy==1.16.3 in /home/ubuntu/miniconda3/envs/rknnpy36/lib/python3.6/site-packages (from rknn-toolkit-lite==1.7.1) (1.16.3)
Requirement already satisfied: psutil==5.6.2 in /home/ubuntu/miniconda3/envs/rknnpy36/lib/python3.6/site-packages (from rknn-toolkit-lite==1.7.1) (5.6.2)
Installing collected packages: rknn-toolkit-lite
Successfully installed rknn-toolkit-lite-1.7.1
(rknnpy36) ubuntu@ubuntu:~/Downloads$ wget http://repo.rock-chips.com/pypi/simple/rknn-toolkit/rknn_toolkit-1.7.1-cp36-cp36m-linux_x86_64.whl
(rknnpy36) ubuntu@ubuntu:~/rknn-toolkit/rknn-toolkit-lite/packages$ pip3 install rknn_toolkit-1.7.1-cp36-cp36m-linux_x86_64.whl -i https://pypi.tuna.tsinghua.edu.cn/simple
(rknnpy36) ubuntu@ubuntu:~/Downloads$ python3
Python 3.6.13 |Anaconda, Inc.| (default, Jun 4 2021, 14:25:59)
[GCC 7.5.0] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> from rknn.api import RKNN
>>> from rknnlite.api import RKNNLite
>>>第五步 先测试一下仿真环境,以yolov5测试
ubuntu@ubuntu:~$ source ~/.bashrc
ubuntu@ubuntu:~$ conda activate rknnpy36
(rknnpy36) ubuntu@ubuntu:~$ cd rknn-toolkit/examples/onnx/yolov5
(rknnpy36) ubuntu@ubuntu:~/rknn-toolkit/examples/onnx/yolov5$ python3 test.py
--> Config model
done
--> Loading model
W Call onnx.optimizer.optimize fail, skip optimize
W Please confirm that your onnx opset_version <= 11 (current opset_verison = 12)!!!
生成模型

模型生成和测试成功

第六步:使用转的模型测试rv1126在开发板上执行
firefly@firefly:~/rknn-toolkit/rknn-toolkit-lite/examples/inference_with_lite$ python3 test.py
--> Load RKNN model
done
--> Init runtime environment
E [vnn_CreateRKNN:5512]rknn model target platform[0] is RK1808, while current platform is RK1109
Create RKNN model fail, error=-13
E Catch exception when init runtime!
E Traceback (most recent call last):
File "/home/firefly/.local/lib/python3.7/site-packages/rknnlite/api/rknn_lite.py", line 157, in init_runtime
self.rknn_runtime.build_graph(self.rknn_data, self.load_model_in_npu)
File "rknnlite/api/rknn_runtime.py", line 733, in rknnlite.api.rknn_runtime.RKNNRuntime.build_graph
Exception: RKNN init failed. error code: RKNN_ERR_TARGET_PLATFORM_UNMATCH
Init runtime environment failed我测试过程中,发现官方模型不适合我的开发板,所以修改yolov5代码中的
rknn.config(reorder_channel='0 1 2',
mean_values=[[0, 0, 0]],
std_values=[[255, 255, 255]],
optimization_level=3,
target_platform = 'rk1808',
output_optimize=1,
quantize_input_node=QUANTIZE_ON)修改之后,重新生成模型
rknn.config(reorder_channel='0 1 2',
mean_values=[[0, 0, 0]],
std_values=[[255, 255, 255]],
optimization_level=3,
target_platform = 'rv1126',
output_optimize=1,
quantize_input_node=QUANTIZE_ON)测试环境
firefly@firefly:~/yolov5$ dpkg -l | grep npu
ii libxi6:armhf 2:1.7.9-1 armhf X11 Input extension library
ii rknpu 1.6.0 armhf 测试代码 官方代码改的
import os
import urllib
import traceback
import time
import sys
import numpy as np
import cv2
from rknnlite.api import RKNNLite
import time
ONNX_MODEL = 'yolov5s.onnx'
RKNN_MODEL = 'yolov5s.rknn'
IMG_PATH = 'bus.jpg'
DATASET = 'dataset.txt'
QUANTIZE_ON = True
BOX_THRESH = 0.5
NMS_THRESH = 0.6
IMG_SIZE = 640
CLASSES = ("person", "bicycle", "car","motorbike ","aeroplane ","bus ","train","truck ","boat","traffic light",
"fire hydrant","stop sign ","parking meter","bench","bird","cat","dog ","horse ","sheep","cow","elephant",
"bear","zebra ","giraffe","backpack","umbrella","handbag","tie","suitcase","frisbee","skis","snowboard","sports ball","kite",
"baseball bat","baseball glove","skateboard","surfboard","tennis racket","bottle","wine glass","cup","fork","knife ",
"spoon","bowl","banana","apple","sandwich","orange","broccoli","carrot","hot dog","pizza ","donut","cake","chair","sofa",
"pottedplant","bed","diningtable","toilet ","tvmonitor","laptop ","mouse ","remote ","keyboard ","cell phone","microwave ",
"oven ","toaster","sink","refrigerator ","book","clock","vase","scissors ","teddy bear ","hair drier", "toothbrush ")
def sigmoid(x):
return 1 / (1 + np.exp(-x))
def xywh2xyxy(x):
# Convert [x, y, w, h] to [x1, y1, x2, y2]
y = np.copy(x)
y[:, 0] = x[:, 0] - x[:, 2] / 2 # top left x
y[:, 1] = x[:, 1] - x[:, 3] / 2 # top left y
y[:, 2] = x[:, 0] + x[:, 2] / 2 # bottom right x
y[:, 3] = x[:, 1] + x[:, 3] / 2 # bottom right y
return y
def process(input, mask, anchors):
anchors = [anchors[i] for i in mask]
grid_h, grid_w = map(int, input.shape[0:2])
box_confidence = sigmoid(input[..., 4])
box_confidence = np.expand_dims(box_confidence, axis=-1)
box_class_probs = sigmoid(input[..., 5:])
box_xy = sigmoid(input[..., :2])*2 - 0.5
col = np.tile(np.arange(0, grid_w), grid_w).reshape(-1, grid_w)
row = np.tile(np.arange(0, grid_h).reshape(-1, 1), grid_h)
col = col.reshape(grid_h, grid_w, 1, 1).repeat(3, axis=-2)
row = row.reshape(grid_h, grid_w, 1, 1).repeat(3, axis=-2)
grid = np.concatenate((col, row), axis=-1)
box_xy += grid
box_xy *= int(IMG_SIZE/grid_h)
box_wh = pow(sigmoid(input[..., 2:4])*2, 2)
box_wh = box_wh * anchors
box = np.concatenate((box_xy, box_wh), axis=-1)
return box, box_confidence, box_class_probs
def filter_boxes(boxes, box_confidences, box_class_probs):
"""Filter boxes with box threshold. It's a bit different with origin yolov5 post process!
# Arguments
boxes: ndarray, boxes of objects.
box_confidences: ndarray, confidences of objects.
box_class_probs: ndarray, class_probs of objects.
# Returns
boxes: ndarray, filtered boxes.
classes: ndarray, classes for boxes.
scores: ndarray, scores for boxes.
"""
box_classes = np.argmax(box_class_probs, axis=-1)
box_class_scores = np.max(box_class_probs, axis=-1)
pos = np.where(box_confidences[...,0] >= BOX_THRESH)
boxes = boxes[pos]
classes = box_classes[pos]
scores = box_class_scores[pos]
return boxes, classes, scores
def nms_boxes(boxes, scores):
"""Suppress non-maximal boxes.
# Arguments
boxes: ndarray, boxes of objects.
scores: ndarray, scores of objects.
# Returns
keep: ndarray, index of effective boxes.
"""
x = boxes[:, 0]
y = boxes[:, 1]
w = boxes[:, 2] - boxes[:, 0]
h = boxes[:, 3] - boxes[:, 1]
areas = w * h
order = scores.argsort()[::-1]
keep = []
while order.size > 0:
i = order[0]
keep.append(i)
xx1 = np.maximum(x[i], x[order[1:]])
yy1 = np.maximum(y[i], y[order[1:]])
xx2 = np.minimum(x[i] + w[i], x[order[1:]] + w[order[1:]])
yy2 = np.minimum(y[i] + h[i], y[order[1:]] + h[order[1:]])
w1 = np.maximum(0.0, xx2 - xx1 + 0.00001)
h1 = np.maximum(0.0, yy2 - yy1 + 0.00001)
inter = w1 * h1
ovr = inter / (areas[i] + areas[order[1:]] - inter)
inds = np.where(ovr <= NMS_THRESH)[0]
order = order[inds + 1]
keep = np.array(keep)
return keep
def yolov5_post_process(input_data):
masks = [[0, 1, 2], [3, 4, 5], [6, 7, 8]]
anchors = [[10, 13], [16, 30], [33, 23], [30, 61], [62, 45],
[59, 119], [116, 90], [156, 198], [373, 326]]
boxes, classes, scores = [], [], []
for input,mask in zip(input_data, masks):
b, c, s = process(input, mask, anchors)
b, c, s = filter_boxes(b, c, s)
boxes.append(b)
classes.append(c)
scores.append(s)
boxes = np.concatenate(boxes)
boxes = xywh2xyxy(boxes)
classes = np.concatenate(classes)
scores = np.concatenate(scores)
nboxes, nclasses, nscores = [], [], []
for c in set(classes):
inds = np.where(classes == c)
b = boxes[inds]
c = classes[inds]
s = scores[inds]
keep = nms_boxes(b, s)
nboxes.append(b[keep])
nclasses.append(c[keep])
nscores.append(s[keep])
if not nclasses and not nscores:
return None, None, None
boxes = np.concatenate(nboxes)
classes = np.concatenate(nclasses)
scores = np.concatenate(nscores)
return boxes, classes, scores
def draw(image, boxes, scores, classes):
"""Draw the boxes on the image.
# Argument:
image: original image.
boxes: ndarray, boxes of objects.
classes: ndarray, classes of objects.
scores: ndarray, scores of objects.
all_classes: all classes name.
"""
for box, score, cl in zip(boxes, scores, classes):
top, left, right, bottom = box
print('class: {}, score: {}'.format(CLASSES[cl], score))
print('box coordinate left,top,right,down: [{}, {}, {}, {}]'.format(top, left, right, bottom))
top = int(top)
left = int(left)
right = int(right)
bottom = int(bottom)
cv2.rectangle(image, (top, left), (right, bottom), (255, 0, 0), 2)
cv2.putText(image, '{0} {1:.2f}'.format(CLASSES[cl], score),
(top, left - 6),
cv2.FONT_HERSHEY_SIMPLEX,
0.6, (0, 0, 255), 2)
def letterbox(im, new_shape=(640, 640), color=(0, 0, 0)):
# Resize and pad image while meeting stride-multiple constraints
shape = im.shape[:2] # current shape [height, width]
if isinstance(new_shape, int):
new_shape = (new_shape, new_shape)
# Scale ratio (new / old)
r = min(new_shape[0] / shape[0], new_shape[1] / shape[1])
# Compute padding
ratio = r, r # width, height ratios
new_unpad = int(round(shape[1] * r)), int(round(shape[0] * r))
dw, dh = new_shape[1] - new_unpad[0], new_shape[0] - new_unpad[1] # wh padding
dw /= 2 # divide padding into 2 sides
dh /= 2
if shape[::-1] != new_unpad: # resize
im = cv2.resize(im, new_unpad, interpolation=cv2.INTER_LINEAR)
top, bottom = int(round(dh - 0.1)), int(round(dh + 0.1))
left, right = int(round(dw - 0.1)), int(round(dw + 0.1))
im = cv2.copyMakeBorder(im, top, bottom, left, right, cv2.BORDER_CONSTANT, value=color) # add border
return im, ratio, (dw, dh)
if __name__ == '__main__':
# Create RKNN object
rknn = RKNNLite()
# load RKNN model
print('--> Load RKNN model')
ret = rknn.load_rknn('./yolov5s.rknn')
if ret != 0:
print('Load RKNN model failed')
exit(ret)
print('done')
# init runtime environment
print('--> Init runtime environment')
#ret = rknn.init_runtime()
ret = rknn.init_runtime('rv1126', device_id='rv1126')
if ret != 0:
print('Init runtime environment failed')
exit(ret)
print('done')
start = time.time()
# Set inputs
img = cv2.imread(IMG_PATH)
# img, ratio, (dw, dh) = letterbox(img, new_shape=(IMG_SIZE, IMG_SIZE))
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
img = cv2.resize(img,(IMG_SIZE, IMG_SIZE))
# Inference
print('--> Running model')
outputs = rknn.inference(inputs=[img])
# post process
input0_data = outputs[0]
input1_data = outputs[1]
input2_data = outputs[2]
input0_data = input0_data.reshape([3,-1]+list(input0_data.shape[-2:]))
input1_data = input1_data.reshape([3,-1]+list(input1_data.shape[-2:]))
input2_data = input2_data.reshape([3,-1]+list(input2_data.shape[-2:]))
input_data = list()
input_data.append(np.transpose(input0_data, (2, 3, 0, 1)))
input_data.append(np.transpose(input1_data, (2, 3, 0, 1)))
input_data.append(np.transpose(input2_data, (2, 3, 0, 1)))
boxes, classes, scores = yolov5_post_process(input_data)
img_1 = cv2.cvtColor(img, cv2.COLOR_RGB2BGR)
if boxes is not None:
draw(img_1, boxes, scores, classes)
end = time.time()
print (end-start,"s")
cv2.imwrite("result.jpg", img_1)
rknn.release()
测试结果
firefly@firefly:~/yolov5$ sudo python3 test.py
--> Load RKNN model
done
--> Init runtime environment
done
--> Running model
class: person, score: 0.9981504082679749
box coordinate left,top,right,down: [479.5712496638298, 257.1674613952637, 560.4287503361702, 516.2188911437988]
class: person, score: 0.9968554973602295
box coordinate left,top,right,down: [110.34747083485126, 229.37330585718155, 220.6373619288206, 531.1496433615685]
class: person, score: 0.9822962880134583
box coordinate left,top,right,down: [209.4318208694458, 244.13265788555145, 287.1548795700073, 506.1707478761673]
class: bus , score: 0.9902657866477966
box coordinate left,top,right,down: [90.29679995775223, 138.5124049782753, 552.5043475031853, 440.2887424826622]
0.619182825088501 s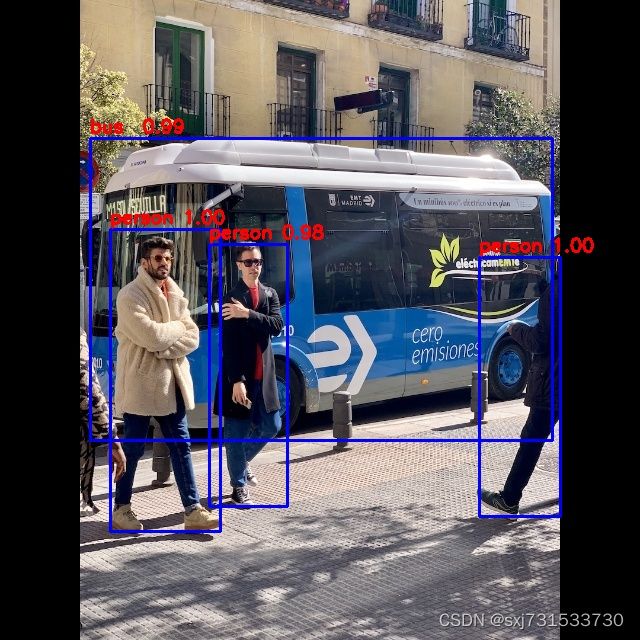
方法一:
第七步:我对比了官方模型和yolov5的版本,感觉最像yolov5 5.0版本,所以训练一个看看32 、 YOLO5训练自己的模型以及转ncnn模型_sxj731533730的博客-CSDN博客
ubuntu@ubuntu:~/yolov5-5.0$ python3 train.py --img 640 --batch 16 --epoch 10 --data data/trainData.yaml --cfg models/yolov5s.yaml --weights weights/yolov5s.pt --device "0"
ubuntu@ubuntu:~/yolov5-5.0$ python3 export.py --weights runs/train/exp3/weights/best.pt --img 640 --batch 1
转模型成功
from rknn.api import RKNN
ONNX_MODEL = '/home/ubuntu/yolov5-5.0/runs/train/exp3/weights/best.onnx'
RKNN_MODEL = 'yolov5s.rknn'
if __name__ == '__main__':
# Create RKNN object
rknn = RKNN(verbose=True)
# pre-process config
print('--> config model')
rknn.config(mean_values=[[0, 0, 0]], std_values=[[255, 255, 255]], reorder_channel='0 1 2',
target_platform='rv1126',
quantized_dtype='asymmetric_affine-u8', optimization_level=3, output_optimize=1)
print('done')
print('--> Loading model')
ret = rknn.load_onnx(model=ONNX_MODEL)
if ret != 0:
print('Load model failed!')
exit(ret)
print('done')
# Build model
print('--> Building model')
ret = rknn.build(do_quantization=True, dataset='/home/ubuntu/yolov5-5.0/dataset.txt') # ,pre_compile=True
if ret != 0:
print('Build yolov5s failed!')
exit(ret)
print('done')
# Export rknn model
print('--> Export RKNN model')
ret = rknn.export_rknn(RKNN_MODEL)
if ret != 0:
print('Export yolov5s.rknn failed!')
exit(ret)
print('done')
rknn.release()但是测试失败....,然后对比了两个onnx文件,感觉应该修改onnx的输出,然后果然发现了志同道合的大佬,参考附录rv1126
修改一下/home/ubuntu/yolov5-5.0/models/yolo.py,重新生成onnx ,我差点去修改onnx,在重新生成一下onnx
x[i] = x[i].view(bs, self.na, self.no, ny, nx).permute(0, 1, 3, 4, 2).contiguous()
修改为
x[i] = x[i].view(bs, self.na, self.no, ny, nx)
然后在转rknn,量化图片自己搞,最后大佬贴心的还提供了检测代码,稍微修改
import os
import urllib
import traceback
import time
import sys
import numpy as np
import cv2
from rknn.api import RKNN
RKNN_MODEL = '/home/ubuntu/yolov5-5.0/yolov5s.rknn'
IMG_PATH = 'dog.jpg'
QUANTIZE_ON = True
BOX_THRESH = 0.5
NMS_THRESH = 0.6
IMG_SIZE = 640
CLASSES = ("drug",
"battery",
"apple",
"bottle",
"banana",
"smoke",
"ylg")
def sigmoid(x):
return 1 / (1 + np.exp(-x))
def xywh2xyxy(x):
# Convert [x, y, w, h] to [x1, y1, x2, y2]
y = np.copy(x)
y[:, 0] = x[:, 0] - x[:, 2] / 2 # top left x
y[:, 1] = x[:, 1] - x[:, 3] / 2 # top left y
y[:, 2] = x[:, 0] + x[:, 2] / 2 # bottom right x
y[:, 3] = x[:, 1] + x[:, 3] / 2 # bottom right y
return y
def resize_postprocess(x, offset_x, offset_y):
# Convert [x1, y1, x2, y2] to [x1, y1, x2, y2]
y = np.copy(x)
y[:, 0] = x[:, 0] / offset_x # top left x
y[:, 1] = x[:, 1] / offset_y # top left y
y[:, 2] = x[:, 2] / offset_x # bottom right x
y[:, 3] = x[:, 3] / offset_y # bottom right y
return y
def process(input, mask, anchors):
anchors = [anchors[i] for i in mask]
grid_h, grid_w = map(int, input.shape[0:2])
box_confidence = sigmoid(input[..., 4])
box_confidence = np.expand_dims(box_confidence, axis=-1)
box_class_probs = sigmoid(input[..., 5:])
box_xy = sigmoid(input[..., :2]) * 2 - 0.5
col = np.tile(np.arange(0, grid_w), grid_w).reshape(-1, grid_w)
row = np.tile(np.arange(0, grid_h).reshape(-1, 1), grid_h)
col = col.reshape(grid_h, grid_w, 1, 1).repeat(3, axis=-2)
row = row.reshape(grid_h, grid_w, 1, 1).repeat(3, axis=-2)
grid = np.concatenate((col, row), axis=-1)
box_xy += grid
box_xy *= int(IMG_SIZE / grid_h)
box_wh = pow(sigmoid(input[..., 2:4]) * 2, 2)
box_wh = box_wh * anchors
box = np.concatenate((box_xy, box_wh), axis=-1)
return box, box_confidence, box_class_probs
def filter_boxes(boxes, box_confidences, box_class_probs):
"""Filter boxes with box threshold. It's a bit different with origin yolov5 post process!
# Arguments
boxes: ndarray, boxes of objects.
box_confidences: ndarray, confidences of objects.
box_class_probs: ndarray, class_probs of objects.
# Returns
boxes: ndarray, filtered boxes.
classes: ndarray, classes for boxes.
scores: ndarray, scores for boxes.
"""
box_classes = np.argmax(box_class_probs, axis=-1)
box_class_scores = np.max(box_class_probs, axis=-1)
pos = np.where(box_confidences[..., 0] >= BOX_THRESH)
boxes = boxes[pos]
classes = box_classes[pos]
scores = box_class_scores[pos]
return boxes, classes, scores
def nms_boxes(boxes, scores):
"""Suppress non-maximal boxes.
# Arguments
boxes: ndarray, boxes of objects.
scores: ndarray, scores of objects.
# Returns
keep: ndarray, index of effective boxes.
"""
x = boxes[:, 0]
y = boxes[:, 1]
w = boxes[:, 2] - boxes[:, 0]
h = boxes[:, 3] - boxes[:, 1]
areas = w * h
order = scores.argsort()[::-1]
keep = []
while order.size > 0:
i = order[0]
keep.append(i)
xx1 = np.maximum(x[i], x[order[1:]])
yy1 = np.maximum(y[i], y[order[1:]])
xx2 = np.minimum(x[i] + w[i], x[order[1:]] + w[order[1:]])
yy2 = np.minimum(y[i] + h[i], y[order[1:]] + h[order[1:]])
w1 = np.maximum(0.0, xx2 - xx1 + 0.00001)
h1 = np.maximum(0.0, yy2 - yy1 + 0.00001)
inter = w1 * h1
ovr = inter / (areas[i] + areas[order[1:]] - inter)
inds = np.where(ovr <= NMS_THRESH)[0]
order = order[inds + 1]
keep = np.array(keep)
return keep
def yolov5_post_process(input_data):
masks = [[0, 1, 2], [3, 4, 5], [6, 7, 8]]
anchors = [[10, 13], [16, 30], [33, 23], [30, 61], [62, 45],
[59, 119], [116, 90], [156, 198], [373, 326]]
boxes, classes, scores = [], [], []
for input, mask in zip(input_data, masks):
b, c, s = process(input, mask, anchors)
b, c, s = filter_boxes(b, c, s)
boxes.append(b)
classes.append(c)
scores.append(s)
boxes = np.concatenate(boxes)
boxes = xywh2xyxy(boxes)
classes = np.concatenate(classes)
scores = np.concatenate(scores)
nboxes, nclasses, nscores = [], [], []
for c in set(classes):
inds = np.where(classes == c)
b = boxes[inds]
c = classes[inds]
s = scores[inds]
keep = nms_boxes(b, s)
nboxes.append(b[keep])
nclasses.append(c[keep])
nscores.append(s[keep])
if not nclasses and not nscores:
return None, None, None
boxes = np.concatenate(nboxes)
classes = np.concatenate(nclasses)
scores = np.concatenate(nscores)
return boxes, classes, scores
def draw(image, boxes, scores, classes):
"""Draw the boxes on the image.
# Argument:
image: original image.
boxes: ndarray, boxes of objects.
classes: ndarray, classes of objects.
scores: ndarray, scores of objects.
all_classes: all classes name.
"""
for box, score, cl in zip(boxes, scores, classes):
top, left, right, bottom = box
print('class: {}, score: {}'.format(CLASSES[cl], score))
print('box coordinate left,top,right,down: [{}, {}, {}, {}]'.format(top, left, right, bottom))
top = int(top)
left = int(left)
right = int(right)
bottom = int(bottom)
cv2.rectangle(image, (top, left), (right, bottom), (255, 0, 0), 2)
cv2.putText(image, '{0} {1:.2f}'.format(CLASSES[cl], score),
(top, left - 6),
cv2.FONT_HERSHEY_SIMPLEX,
0.6, (0, 0, 255), 2)
def letterbox(im, new_shape=(640, 640), color=(0, 0, 0)):
# Resize and pad image while meeting stride-multiple constraints
shape = im.shape[:2] # current shape [height, width]
if isinstance(new_shape, int):
new_shape = (new_shape, new_shape)
# Scale ratio (new / old)
r = min(new_shape[0] / shape[0], new_shape[1] / shape[1])
# Compute padding
ratio = r, r # width, height ratios
new_unpad = int(round(shape[1] * r)), int(round(shape[0] * r))
dw, dh = new_shape[1] - new_unpad[0], new_shape[0] - new_unpad[1] # wh padding
dw /= 2 # divide padding into 2 sides
dh /= 2
if shape[::-1] != new_unpad: # resize
im = cv2.resize(im, new_unpad, interpolation=cv2.INTER_LINEAR)
top, bottom = int(round(dh - 0.1)), int(round(dh + 0.1))
left, right = int(round(dw - 0.1)), int(round(dw + 0.1))
im = cv2.copyMakeBorder(im, top, bottom, left, right, cv2.BORDER_CONSTANT, value=color) # add border
return im, ratio, (dw, dh)
def letter_box_postprocess(x, scalingfactor, xy_correction):
y = np.copy(x)
y[:, 0] = (x[:, 0] - xy_correction[0]) / scalingfactor # top left x
y[:, 1] = (x[:, 1] - xy_correction[1]) / scalingfactor # top left y
y[:, 2] = (x[:, 2] - xy_correction[0]) / scalingfactor # bottom right x
y[:, 3] = (x[:, 3] - xy_correction[1]) / scalingfactor # bottom right y
return y
def get_file(filepath):
templist = []
with open(filepath, "r") as f:
for item in f.readlines():
templist.append(item.strip())
return templist
if __name__ == '__main__':
# Create RKNN object
rknn = RKNN()
image_process_mode = "letter_box"
print("image_process_mode = ", image_process_mode)
if not os.path.exists(RKNN_MODEL):
print('model not exist')
exit(-1)
# Load ONNX model
print('--> Loading model')
ret = rknn.load_rknn(RKNN_MODEL)
if ret != 0:
print('Load rknn model failed!')
exit(ret)
print('done')
# init runtime environment
print('--> Init runtime environment')
ret = rknn.init_runtime()
# ret = rknn.init_runtime('rk180_8', device_id='1808')
if ret != 0:
print('Init runtime environment failed')
exit(ret)
print('done')
image = cv2.imread("/home/ubuntu/yolov5-5.0/trainData/images/dc1_02.jpg")
img_height = image.shape[0]
img_width = image.shape[1]
# img, ratio, (dw, dh) = letterbox(img, new_shape=(IMG_SIZE, IMG_SIZE))
img = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
if image_process_mode == "resize":
img = cv2.resize(img, (IMG_SIZE, IMG_SIZE))
elif image_process_mode == "letter_box":
img, scale_factor, correction = letterbox(img)
# Inference
print('--> Running model')
outputs = rknn.inference(inputs=[img])
# post process
input0_data = outputs[0]
input1_data = outputs[1]
input2_data = outputs[2]
input0_data = input0_data.reshape([3, -1] + list(input0_data.shape[-2:]))
input1_data = input1_data.reshape([3, -1] + list(input1_data.shape[-2:]))
input2_data = input2_data.reshape([3, -1] + list(input2_data.shape[-2:]))
input_data = list()
input_data.append(np.transpose(input0_data, (2, 3, 0, 1)))
input_data.append(np.transpose(input1_data, (2, 3, 0, 1)))
input_data.append(np.transpose(input2_data, (2, 3, 0, 1)))
boxes, classes, scores = yolov5_post_process(input_data)
if image_process_mode == "resize":
scale_h = IMG_SIZE / img_height
scale_w = IMG_SIZE / img_width
boxes = resize_postprocess(boxes, scale_w, scale_h)
elif image_process_mode == "letter_box":
boxes = letter_box_postprocess(boxes, scale_factor[0], correction)
# img_1 = cv2.cvtColor(img, cv2.COLOR_RGB2BGR)
if boxes is not None:
draw(image, boxes, scores, classes)
cv2.imwrite("image.jpg", image)
rknn.release()测试结果 yyds
/home/ubuntu/miniconda3/envs/rknnpy36/bin/python /home/ubuntu/yolov5-5.0/rknn_detect.py
image_process_mode = letter_box
--> Loading model
done
--> Init runtime environment
librknn_runtime version 1.7.1 (bd41dbc build: 2021-10-28 16:15:23 base: 1131)
done
--> Running model
class: battery, score: 0.9596196413040161
box coordinate left,top,right,down: [100.91769161224364, 57.873418962955476, 129.09340457916258, 105.65749076604843]
Process finished with exit code 0

开发板上实测代码,需要修改,代码中有bug,需要修改
import os
import urllib
import traceback
import time
import sys
import numpy as np
import cv2
from rknnlite.api import RKNNLite
RKNN_MODEL = 'yolov5s.rknn'
QUANTIZE_ON = True
BOX_THRESH = 0.5
NMS_THRESH = 0.6
IMG_SIZE = 640
CLASSES = ("drug",
"battery",
"apple",
"bottle",
"banana",
"smoke",
"ylg")
def sigmoid(x):
return 1 / (1 + np.exp(-x))
def xywh2xyxy(x):
# Convert [x, y, w, h] to [x1, y1, x2, y2]
y = np.copy(x)
y[:, 0] = x[:, 0] - x[:, 2] / 2 # top left x
y[:, 1] = x[:, 1] - x[:, 3] / 2 # top left y
y[:, 2] = x[:, 0] + x[:, 2] / 2 # bottom right x
y[:, 3] = x[:, 1] + x[:, 3] / 2 # bottom right y
return y
def resize_postprocess(x, offset_x, offset_y):
# Convert [x1, y1, x2, y2] to [x1, y1, x2, y2]
y = np.copy(x)
y[:, 0] = x[:, 0] / offset_x # top left x
y[:, 1] = x[:, 1] / offset_y # top left y
y[:, 2] = x[:, 2] / offset_x # bottom right x
y[:, 3] = x[:, 3] / offset_y # bottom right y
return y
def process(input, mask, anchors):
anchors = [anchors[i] for i in mask]
grid_h, grid_w = map(int, input.shape[0:2])
box_confidence = sigmoid(input[..., 4])
box_confidence = np.expand_dims(box_confidence, axis=-1)
box_class_probs = sigmoid(input[..., 5:])
box_xy = sigmoid(input[..., :2]) * 2 - 0.5
col = np.tile(np.arange(0, grid_w), grid_w).reshape(-1, grid_w)
row = np.tile(np.arange(0, grid_h).reshape(-1, 1), grid_h)
col = col.reshape(grid_h, grid_w, 1, 1).repeat(3, axis=-2)
row = row.reshape(grid_h, grid_w, 1, 1).repeat(3, axis=-2)
grid = np.concatenate((col, row), axis=-1)
box_xy += grid
box_xy *= int(IMG_SIZE / grid_h)
box_wh = pow(sigmoid(input[..., 2:4]) * 2, 2)
box_wh = box_wh * anchors
box = np.concatenate((box_xy, box_wh), axis=-1)
return box, box_confidence, box_class_probs
def filter_boxes(boxes, box_confidences, box_class_probs):
"""Filter boxes with box threshold. It's a bit different with origin yolov5 post process!
# Arguments
boxes: ndarray, boxes of objects.
box_confidences: ndarray, confidences of objects.
box_class_probs: ndarray, class_probs of objects.
# Returns
boxes: ndarray, filtered boxes.
classes: ndarray, classes for boxes.
scores: ndarray, scores for boxes.
"""
box_classes = np.argmax(box_class_probs, axis=-1)
box_class_scores = np.max(box_class_probs, axis=-1)
pos = np.where(box_confidences[..., 0] >= BOX_THRESH)
boxes = boxes[pos]
classes = box_classes[pos]
scores = box_class_scores[pos]
return boxes, classes, scores
def nms_boxes(boxes, scores):
"""Suppress non-maximal boxes.
# Arguments
boxes: ndarray, boxes of objects.
scores: ndarray, scores of objects.
# Returns
keep: ndarray, index of effective boxes.
"""
x = boxes[:, 0]
y = boxes[:, 1]
w = boxes[:, 2] - boxes[:, 0]
h = boxes[:, 3] - boxes[:, 1]
areas = w * h
order = scores.argsort()[::-1]
keep = []
while order.size > 0:
i = order[0]
keep.append(i)
xx1 = np.maximum(x[i], x[order[1:]])
yy1 = np.maximum(y[i], y[order[1:]])
xx2 = np.minimum(x[i] + w[i], x[order[1:]] + w[order[1:]])
yy2 = np.minimum(y[i] + h[i], y[order[1:]] + h[order[1:]])
w1 = np.maximum(0.0, xx2 - xx1 + 0.00001)
h1 = np.maximum(0.0, yy2 - yy1 + 0.00001)
inter = w1 * h1
ovr = inter / (areas[i] + areas[order[1:]] - inter)
inds = np.where(ovr <= NMS_THRESH)[0]
order = order[inds + 1]
keep = np.array(keep)
return keep
def yolov5_post_process(input_data):
masks = [[0, 1, 2], [3, 4, 5], [6, 7, 8]]
anchors = [[10, 13], [16, 30], [33, 23], [30, 61], [62, 45],
[59, 119], [116, 90], [156, 198], [373, 326]]
boxes, classes, scores = [], [], []
for input, mask in zip(input_data, masks):
b, c, s = process(input, mask, anchors)
b, c, s = filter_boxes(b, c, s)
boxes.append(b)
classes.append(c)
scores.append(s)
boxes = np.concatenate(boxes)
boxes = xywh2xyxy(boxes)
classes = np.concatenate(classes)
scores = np.concatenate(scores)
nboxes, nclasses, nscores = [], [], []
for c in set(classes):
inds = np.where(classes == c)
b = boxes[inds]
c = classes[inds]
s = scores[inds]
keep = nms_boxes(b, s)
nboxes.append(b[keep])
nclasses.append(c[keep])
nscores.append(s[keep])
if not nclasses and not nscores:
return None, None, None
boxes = np.concatenate(nboxes)
classes = np.concatenate(nclasses)
scores = np.concatenate(nscores)
return boxes, classes, scores
def draw(image, boxes, scores, classes):
"""Draw the boxes on the image.
# Argument:
image: original image.
boxes: ndarray, boxes of objects.
classes: ndarray, classes of objects.
scores: ndarray, scores of objects.
all_classes: all classes name.
"""
for box, score, cl in zip(boxes, scores, classes):
top, left, right, bottom = box
print('class: {}, score: {}'.format(CLASSES[cl], score))
print('box coordinate left,top,right,down: [{}, {}, {}, {}]'.format(top, left, right, bottom))
top = int(top)
left = int(left)
right = int(right)
bottom = int(bottom)
cv2.rectangle(image, (top, left), (right, bottom), (255, 0, 0), 2)
cv2.putText(image, '{0} {1:.2f}'.format(CLASSES[cl], score),
(top, left - 6),
cv2.FONT_HERSHEY_SIMPLEX,
0.6, (0, 0, 255), 2)
def letterbox(im, new_shape=(640, 640), color=(0, 0, 0)):
# Resize and pad image while meeting stride-multiple constraints
shape = im.shape[:2] # current shape [height, width]
if isinstance(new_shape, int):
new_shape = (new_shape, new_shape)
# Scale ratio (new / old)
r = min(new_shape[0] / shape[0], new_shape[1] / shape[1])
# Compute padding
ratio = r, r # width, height ratios
new_unpad = int(round(shape[1] * r)), int(round(shape[0] * r))
dw, dh = new_shape[1] - new_unpad[0], new_shape[0] - new_unpad[1] # wh padding
dw /= 2 # divide padding into 2 sides
dh /= 2
if shape[::-1] != new_unpad: # resize
im = cv2.resize(im, new_unpad, interpolation=cv2.INTER_LINEAR)
top, bottom = int(round(dh - 0.1)), int(round(dh + 0.1))
left, right = int(round(dw - 0.1)), int(round(dw + 0.1))
im = cv2.copyMakeBorder(im, top, bottom, left, right, cv2.BORDER_CONSTANT, value=color) # add border
return im, ratio, (dw, dh)
def letter_box_postprocess(x, scalingfactor, xy_correction):
y = np.copy(x)
y[:, 0] = (x[:, 0] - xy_correction[0]) / scalingfactor # top left x
y[:, 1] = (x[:, 1] - xy_correction[1]) / scalingfactor # top left y
y[:, 2] = (x[:, 2] - xy_correction[0]) / scalingfactor # bottom right x
y[:, 3] = (x[:, 3] - xy_correction[1]) / scalingfactor # bottom right y
return y
def get_file(filepath):
templist = []
with open(filepath, "r") as f:
for item in f.readlines():
templist.append(item.strip())
return templist
if __name__ == '__main__':
# Create RKNN object
rknn = RKNNLite()
image_process_mode = "letter_box"
print("image_process_mode = ", image_process_mode)
if not os.path.exists(RKNN_MODEL):
print('model not exist')
exit(-1)
# Load ONNX model
print('--> Loading model')
ret = rknn.load_rknn(RKNN_MODEL)
if ret != 0:
print('Load rknn model failed!')
exit(ret)
print('done')
# init runtime environment
print('--> Init runtime environment')
ret = rknn.init_runtime()
# ret = rknn.init_runtime('rk180_8', device_id='1808')
if ret != 0:
print('Init runtime environment failed')
exit(ret)
print('done')
image = cv2.imread("0.jpg")
img_height = image.shape[0]
img_width = image.shape[1]
# img, ratio, (dw, dh) = letterbox(img, new_shape=(IMG_SIZE, IMG_SIZE))
img = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
if image_process_mode == "resize":
img = cv2.resize(img, (IMG_SIZE, IMG_SIZE))
elif image_process_mode == "letter_box":
img, scale_factor, correction = letterbox(img)
# Inference
print('--> Running model')
start = time.time()
outputs = rknn.inference(inputs=[img])
# post process
input0_data = outputs[0]
input1_data = outputs[1]
input2_data = outputs[2]
input0_data = input0_data.reshape([3, -1] + list(input0_data.shape[-2:]))
input1_data = input1_data.reshape([3, -1] + list(input1_data.shape[-2:]))
input2_data = input2_data.reshape([3, -1] + list(input2_data.shape[-2:]))
input_data = list()
input_data.append(np.transpose(input0_data, (2, 3, 0, 1)))
input_data.append(np.transpose(input1_data, (2, 3, 0, 1)))
input_data.append(np.transpose(input2_data, (2, 3, 0, 1)))
boxes, classes, scores = yolov5_post_process(input_data)
if boxes is not None:
if image_process_mode == "resize":
scale_h = IMG_SIZE / img_height
scale_w = IMG_SIZE / img_width
boxes = resize_postprocess(boxes, scale_w, scale_h)
elif image_process_mode == "letter_box":
boxes = letter_box_postprocess(boxes, scale_factor[0], correction)
# img_1 = cv2.cvtColor(img, cv2.COLOR_RGB2BGR)
if boxes is not None:
draw(image, boxes, scores, classes)
end = time.time()
print (end-start,"s")
cv2.imwrite("image.jpg", image)
rknn.release()
开发板实测结果
firefly@firefly:~/yolov5/yolov5_0$ sudo python3 test_rknn.py
image_process_mode = letter_box
--> Loading model
done
--> Init runtime environment
done
--> Running model
class: battery, score: 0.9596196413040161
box coordinate left,top,right,down: [100.91770471334458, 57.873415207862855, 129.09341284036637, 105.65749452114105]
0.21574974060058594 s方法二 :
第八步:发现有人写过这方面的文章,下载官方手册指导的源码的github指导和结合yolov5训练即可,参考附录如何训练yolov5
ubuntu@ubuntu:~$ git clone https://github.com/littledeep/YOLOv5-RK3399Pro
ubuntu@ubuntu:~/YOLOv5-RK3399Pro$ python3 train.py --img 640 --batch 16 --epoch 10 --data data/trainData.yaml --hyp data/hyp.scratch.yaml --cfg models/yolov5s.yaml --weights weights/yolov5s.pt --device "0"
其中的超参数配置文件和与预训练的权重都来自yolov5 v4.0
https://github.com/ultralytics/yolov5/blob/v4.0/data/hyp.scratch.yaml训练结果
Epoch gpu_mem box obj cls total labels img_size
199/199 2.33G 0.01391 0.006809 0.0007568 0.02147 23 640: 100%|█| 106/106 [00:17<00:00,
Class Images Labels P R [email protected] [email protected]:.95: 100%|█| 53/53 [00:
all 1692 1692 0.999 0.999 0.996 0.92
drug 1692 359 1 1 0.997 0.937
battery 1692 157 0.999 1 0.995 0.889
apple 1692 116 0.998 1 0.996 0.959
bottle 1692 358 1 1 0.996 0.898
banana 1692 225 1 0.996 0.996 0.918
smoke 1692 107 1 1 0.996 0.894
ylg 1692 370 1 1 0.996 0.942
200 epochs completed in 1.518 hours.
Optimizer stripped from runs/train/exp6/weights/last.pt, 14.4MB
Optimizer stripped from runs/train/exp6/weights/best.pt, 14.4MB
第九步:修改optset=11,且添加--grid 设置false
parser.add_argument('--grid', default=False, action='store_true', help='export Detect() layer grid')
然后转模型
ubuntu@ubuntu:~/YOLOv5-RK3399Pro$ cp models/export.py .
ubuntu@ubuntu:~/YOLOv5-RK3399Pro$ python3 export.py --weights /home/ubuntu/YOLOv5-RK3399Pro/runs/train/exp6/weights/best.pt --rknn_mode --img 640 --batch 1然后将onnx模型转成rknn模型,/home/ubuntu/YOLOv5-RK3399Pro/convert/rknn_convert.py代码做了细微修改,去掉远程连接开发板测试,改成本地测试(注意此时环境要切换rknnpy36)
import yaml
from rknn.api import RKNN
import cv2
_model_load_dict = {
'caffe': 'load_caffe',
'tensorflow': 'load_tensorflow',
'tflite': 'load_tflite',
'onnx': 'load_onnx',
'darknet': 'load_darknet',
'pytorch': 'load_pytorch',
'mxnet': 'load_mxnet',
'rknn': 'load_rknn',
}
yaml_file = './config.yaml'
def main():
with open(yaml_file, 'r') as F:
config = yaml.safe_load(F)
# print('config is:')
# print(config)
model_type = config['running']['model_type']
print('model_type is {}'.format(model_type))#检查模型的类型
rknn = RKNN(verbose=True)
#配置文件
print('--> config model')
rknn.config(**config['config'])
print('done')
print('--> Loading model')
load_function = getattr(rknn, _model_load_dict[model_type])
ret = load_function(**config['parameters'][model_type])
if ret != 0:
print('Load yolo failed! Ret = {}'.format(ret))
exit(ret)
print('done')
####
#print('hybrid_quantization')
#ret = rknn.hybrid_quantization_step1(dataset=config['build']['dataset'])
if model_type != 'rknn':
print('--> Building model')
ret = rknn.build(**config['build'])
print('acc_eval')
rknn.accuracy_analysis(inputs='/home/ubuntu/YOLOv5-RK3399Pro/convert/dataset 1.txt', target='rk1126')#根据个人开发板设置
print('acc_eval done!')
if ret != 0:
print('Build yolo failed!')
exit(ret)
else:
print('--> skip Building model step, cause the model is already rknn')
#导出RKNN模型
if config['running']['export'] is True:
print('--> Export RKNN model')
ret = rknn.export_rknn(**config['export_rknn'])
if ret != 0:
print('Init runtime environment failed1')
exit(ret)
else:
print('--> skip Export model')
#初始化
print('--> Init runtime environment2')
ret = rknn.init_runtime()
if ret != 0:
print('Init runtime environment failed2')
exit(ret)
print('done')
print('--> load img')
img = cv2.imread(config['img']['path'])
print('img shape is {}'.format(img.shape))
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
inputs = [img]
print(inputs[0][0:10,0,0])
#推理
if config['running']['inference'] is True:
print('--> Running model')
config['inference']['inputs'] = inputs
#print(config['inference'])
outputs = rknn.inference(inputs)
#outputs = rknn.inference(config['inference'])
print('len of output {}'.format(len(outputs)))
print('outputs[0] shape is {}'.format(outputs[0].shape))
print(outputs[0][0][0:2])
else:
print('--> skip inference')
#评价
if config['running']['eval_perf'] is True:
print('--> Begin evaluate model performance')
config['inference']['inputs'] = inputs
perf_results = rknn.eval_perf(inputs=[img])
else:
print('--> skip eval_perf')
if __name__ == '__main__':
main()
同时需要修改同目录下的配置文件config.yaml
1)设置要转模型的onnx路径 内部rk3399 pro 我一律改成rv1126
onnx:
model: '/home/ubuntu/YOLOv5-RK3399Pro/runs/train/exp6/weights/best.onnx'2)设置要进行量化的图片列表
build:
do_quantization: True
dataset: '/home/ubuntu/YOLOv5-RK3399Pro/convert/dataset 1.txt' # '/home/zen/rknn_convert/quant_data/hand_dataset/pic_path_less.txt'
pre_compile: Falsedataset 1.txt填入要量化的图片全路径即可,多行
3)设置要输出rknn模型的路径
export_rknn:
export_path: './best_noop1.rknn'4)设置测试rknn模型的图片路径
img: &img
path: '/home/ubuntu/YOLOv5-RK3399Pro/trainData/images/yp4_09.jpg'5)batch_size设置大一些
config:
#mean_value: [[0,0,0]]
#std_value: [[58.82,58.82,58.82]]
channel_mean_value: '0 0 0 255' # 123.675 116.28 103.53 58.395 # 0 0 0 255
reorder_channel: '0 1 2' # '2 1 0'
need_horizontal_merge: False
batch_size: 20
epochs: -1
target_platform: ['rk1126']
quantized_dtype: 'asymmetric_quantized-u8'
#asymmetric_quantized-u8,dynamic_fixed_point-8,dynamic_fixed_point-16
optimization_level: 1进行模型转换 本菜机电脑 i5 12代 RTX3060 12G 内存16G
ubuntu@ubuntu:~/YOLOv5-RK3399Pro$ conda activate rknnpy36
(rknnpy36) ubuntu@ubuntu:~/YOLOv5-RK3399Pro$ cd convert/
(rknnpy36) ubuntu@ubuntu:~/YOLOv5-RK3399Pro/convert$ python3 rknn_convert.pyubuntu@ubuntu:~/YOLOv5-RK3399Pro$ conda activate rknnpy36
(rknnpy36) ubuntu@ubuntu:~/YOLOv5-RK3399Pro$ cd convert/
(rknnpy36) ubuntu@ubuntu:~/YOLOv5-RK3399Pro/convert$ python3 rknn_convert.py
.....
D 546(36.76%), Queue size 1
D 547(36.82%), Queue size 1
D 548(36.89%), Queue size 1
D 549(36.96%), Queue size 1
D 550(37.02%), Queue size 1
D 551(37.09%), Queue size 1
D 552(37.16%), Queue size 1
D 553(37.23%), Queue size 1
D 554(37.29%), Queue size 1
D 555(37.36%), Queue size 1
D 556(37.43%), Queue size 1
D 557(37.50%), Queue size 1
D 558(37.56%), Queue size 1
D 559(37.63%), Queue size 1
D 560(37.70%), Queue size 1
....
10 convolution.relu.pooling.layer2_2 143
4 openvx.tensor_transpose_3 16
40 convolution.relu.pooling.layer2_2 1016
22 convolution.relu.pooling.layer2_2 325
48 convolution.relu.pooling.layer2_2 325
33 convolution.relu.pooling.layer2_2 82
21 convolution.relu.pooling.layer2_2 360
12 convolution.relu.pooling.layer2_2 208
9 convolution.relu.pooling.layer2_2 98
3 openvx.tensor_transpose_3 7
Total Time(us): 31431
FPS(600MHz): 23.86
FPS(800MHz): 31.82
Note: Time of each layer is converted according to 800MHz!
========================================================================
第十步:测试模型 ,修改i配置/home/ubuntu/YOLOv5-RK3399Pro/rknn_detect/models
class: rknn_detect_yolov5.Detector
opt:
model: "/home/ubuntu/YOLOv5-RK3399Pro/convert/best_noop1.rknn"
size: [ 640, 640 ]
masks: [ [ 0, 1, 2 ], [ 3, 4, 5 ], [ 6, 7, 8 ] ]
anchors: [ [ 10,13 ], [ 16,30 ], [ 33,23 ], [ 30,61 ], [ 62,45 ], [ 59,119 ], [ 116,90 ], [ 156,198 ], [ 373,326 ] ]
names: [ "drug","battery","apple","bottle","banana","smoke","ylg" ]
conf_thres: 0.3
iou_thres: 0.5
platform: 0
代码也是该作者的/home/ubuntu/YOLOv5-RK3399Pro/rknn_detect/rknn_detect_for_yolov5_original.py,问题不大,贴一下 输入改成640
import cv2
import time
import random
import numpy as np
from rknn.api import RKNN
"""
yolov5 官方原版 预测脚本 for rknn
"""
def get_max_scale(img, max_w, max_h):
h, w = img.shape[:2]
scale = min(max_w / w, max_h / h, 1)
return scale
def get_new_size(img, scale):
return tuple(map(int, np.array(img.shape[:2][::-1]) * scale))
def sigmoid(x):
return 1 / (1 + np.exp(-x))
def filter_boxes(boxes, box_confidences, box_class_probs, conf_thres):
box_scores = box_confidences * box_class_probs # 条件概率, 在该cell存在物体的概率的基础上是某个类别的概率
box_classes = np.argmax(box_scores, axis=-1) # 找出概率最大的类别索引
box_class_scores = np.max(box_scores, axis=-1) # 最大类别对应的概率值
pos = np.where(box_class_scores >= conf_thres) # 找出概率大于阈值的item
# pos = box_class_scores >= OBJ_THRESH # 找出概率大于阈值的item
boxes = boxes[pos]
classes = box_classes[pos]
scores = box_class_scores[pos]
return boxes, classes, scores
def nms_boxes(boxes, scores, iou_thres):
x = boxes[:, 0]
y = boxes[:, 1]
w = boxes[:, 2]
h = boxes[:, 3]
areas = w * h
order = scores.argsort()[::-1]
keep = []
while order.size > 0:
i = order[0]
keep.append(i)
xx1 = np.maximum(x[i], x[order[1:]])
yy1 = np.maximum(y[i], y[order[1:]])
xx2 = np.minimum(x[i] + w[i], x[order[1:]] + w[order[1:]])
yy2 = np.minimum(y[i] + h[i], y[order[1:]] + h[order[1:]])
w1 = np.maximum(0.0, xx2 - xx1 + 0.00001)
h1 = np.maximum(0.0, yy2 - yy1 + 0.00001)
inter = w1 * h1
ovr = inter / (areas[i] + areas[order[1:]] - inter)
inds = np.where(ovr <= iou_thres)[0]
order = order[inds + 1]
keep = np.array(keep)
return keep
def plot_one_box(x, img, color=None, label=None, line_thickness=None):
tl = line_thickness or round(0.002 * (img.shape[0] + img.shape[1]) / 2) + 1 # line/font thickness
color = color or [random.randint(0, 255) for _ in range(3)]
c1, c2 = (int(x[0]), int(x[1])), (int(x[2]), int(x[3]))
cv2.rectangle(img, c1, c2, color, thickness=tl, lineType=cv2.LINE_AA)
if label:
tf = max(tl - 1, 1) # font thickness
t_size = cv2.getTextSize(label, 0, fontScale=tl / 3, thickness=tf)[0]
c2 = c1[0] + t_size[0], c1[1] - t_size[1] - 3
cv2.rectangle(img, c1, c2, color, -1, cv2.LINE_AA) # filled
cv2.putText(img, label, (c1[0], c1[1] - 2), 0, tl / 3, [225, 255, 255], thickness=tf, lineType=cv2.LINE_AA)
print(label)
def auto_resize(img, max_w, max_h):
h, w = img.shape[:2]
scale = min(max_w / w, max_h / h, 1)
new_size = tuple(map(int, np.array(img.shape[:2][::-1]) * scale))
return cv2.resize(img, new_size), scale
def letterbox(img, new_wh=(640, 640), color=(114, 114, 114)):
new_img, scale = auto_resize(img, *new_wh)
shape = new_img.shape
new_img = cv2.copyMakeBorder(new_img, 0, new_wh[1] - shape[0], 0, new_wh[0] - shape[1], cv2.BORDER_CONSTANT,
value=color)
return new_img, (new_wh[0] / scale, new_wh[1] / scale)
def load_model(model_path, npu_id):
rknn = RKNN()
print('-->loading model : ' + model_path)
rknn.load_rknn(model_path)
ret = rknn.init_runtime()
if ret != 0:
print('Init runtime environment failed')
exit(ret)
print('done')
return rknn
class Detector:
def __init__(self, opt):
self.opt = opt
model = opt['model']
wh = opt['size']
masks = opt['masks']
anchors = opt['anchors']
names = opt['names']
conf_thres = opt['conf_thres']
iou_thres = opt['iou_thres']
platform = opt['platform']
self.wh = wh
self.size = wh
self._masks = masks
self._anchors = anchors
self.names = list(
filter(lambda a: len(a) > 0, map(lambda x: x.strip(), open(names, "r").read().split()))) if isinstance(
names, str) else names
self.conf_thres = conf_thres
self.iou_thres = iou_thres
if isinstance(model, str):
model = load_model(model, platform)
self._rknn = model
self.draw_box = False
def _predict(self, img_src, img, gain):
src_h, src_w = img_src.shape[:2]
# _img = cv2.cvtColor(_img, cv2.COLOR_BGR2RGB)
img = img[..., ::-1] #
img = np.concatenate([img[::2, ::2], img[1::2, ::2], img[::2, 1::2], img[1::2, 1::2]], 2)
t0 = time.time()
pred_onx = self._rknn.inference(inputs=[img])
print("inference time:\t", time.time() - t0)
boxes, classes, scores = [], [], []
for t in range(3):
input0_data = sigmoid(pred_onx[t][0])
input0_data = np.transpose(input0_data, (1, 2, 0, 3))
grid_h, grid_w, channel_n, predict_n = input0_data.shape
anchors = [self._anchors[i] for i in self._masks[t]]
box_confidence = input0_data[..., 4]
box_confidence = np.expand_dims(box_confidence, axis=-1)
box_class_probs = input0_data[..., 5:]
box_xy = input0_data[..., :2]
box_wh = input0_data[..., 2:4]
col = np.tile(np.arange(0, grid_w), grid_h).reshape(-1, grid_w)
row = np.tile(np.arange(0, grid_h).reshape(-1, 1), grid_w)
col = col.reshape((grid_h, grid_w, 1, 1)).repeat(3, axis=-2)
row = row.reshape((grid_h, grid_w, 1, 1)).repeat(3, axis=-2)
grid = np.concatenate((col, row), axis=-1)
box_xy = box_xy * 2 - 0.5 + grid
box_wh = (box_wh * 2) ** 2 * anchors
box_xy /= (grid_w, grid_h) # 计算原尺寸的中心
box_wh /= self.wh # 计算原尺寸的宽高
box_xy -= (box_wh / 2.) # 计算原尺寸的中心
box = np.concatenate((box_xy, box_wh), axis=-1)
res = filter_boxes(box, box_confidence, box_class_probs, self.conf_thres)
boxes.append(res[0])
classes.append(res[1])
scores.append(res[2])
boxes, classes, scores = np.concatenate(boxes), np.concatenate(classes), np.concatenate(scores)
nboxes, nclasses, nscores = [], [], []
for c in set(classes):
inds = np.where(classes == c)
b = boxes[inds]
c = classes[inds]
s = scores[inds]
keep = nms_boxes(b, s, self.iou_thres)
nboxes.append(b[keep])
nclasses.append(c[keep])
nscores.append(s[keep])
if len(nboxes) < 1:
return [], []
boxes = np.concatenate(nboxes)
classes = np.concatenate(nclasses)
scores = np.concatenate(nscores)
label_list = []
box_list = []
for (x, y, w, h), score, cl in zip(boxes, scores, classes):
print(score)
x *= gain[0]
y *= gain[1]
w *= gain[0]
h *= gain[1]
x1 = max(0, np.floor(x).astype(int))
y1 = max(0, np.floor(y).astype(int))
x2 = min(src_w, np.floor(x + w + 0.5).astype(int))
y2 = min(src_h, np.floor(y + h + 0.5).astype(int))
# label_list.append(self.names[cl])
label_list.append(cl)
box_list.append((x1, y1, x2, y2))
if self.draw_box:
plot_one_box((x1, y1, x2, y2), img_src, label=self.names[cl])
return label_list, np.array(box_list)
def detect_resize(self, img_src):
"""
预测一张图片,预处理使用resize
return: labels,boxes
"""
_img = cv2.resize(img_src, self.wh)
gain = img_src.shape[:2][::-1]
return self._predict(img_src, _img, gain)
def detect(self, img_src):
"""
预测一张图片,预处理保持宽高比
return: labels,boxes
"""
_img, gain = letterbox(img_src, self.wh)
return self._predict(img_src, _img, gain)
def close(self):
self._rknn.release()
def __enter__(self):
return self
def __exit__(self, exc_type, exc_val, exc_tb):
self.close()
def __del__(self):
self.close()
def test_video(det, video_path):
reader = cv2.VideoCapture()
reader.open(video_path)
while True:
ret, frame = reader.read()
if not ret:
break
t0 = time.time()
det.detect(frame)
print("total time", time.time() - t0)
cv2.imshow("res", auto_resize(frame, 1200, 600)[0])
cv2.waitKey(1)
if __name__ == '__main__':
import yaml
import cv2
image = cv2.imread("/home/ubuntu/YOLOv5-RK3399Pro/trainData/images/ylg2_098.jpg")
with open("/home/ubuntu/YOLOv5-RK3399Pro/rknn_detect/models/yolov5_rknn_640x640.yaml", "rb") as f:
cfg = yaml.load(f, yaml.FullLoader)
d = Detector(cfg["opt"])
d.draw_box = True
d.detect(image)
cv2.imshow("res", image)
cv2.imwrite("image.jpg",image)
cv2.waitKey()
cv2.destroyAllWindows()
测试结果
(rknnpy36) ubuntu@ubuntu:~/YOLOv5-RK3399Pro/rknn_detect$ python3 rknn_detect_for_yolov5_original.py
-->loading model : /home/ubuntu/YOLOv5-RK3399Pro/convert/best_noop1.rknn
librknn_runtime version 1.7.1 (bd41dbc build: 2021-10-28 16:15:23 base: 1131)
done
inference time: 62.44455170631409
0.85787344
ylg #易拉罐
-->loading model : /home/ubuntu/YOLOv5-RK3399Pro/convert/best_noop1.rknn
librknn_runtime version 1.7.1 (bd41dbc build: 2021-10-28 16:15:23 base: 1131)
done
inference time: 64.14252042770386
banana
ylg


量化影响精度,可以换其他量化手段
asymmetric_quantized-u8,dynamic_fixed_point-8,dynamic_fixed_point-16修改配置文件即可,也或许是我的图片太小了,或者其它问题,下一篇使用c++修改官方demo
贴个结果2g+16g
firefly@firefly:~/sxj_client/build$ sudo ./sxj_client
sdk version: librknn_runtime version 1.6.0 (6523e57 build: 2021-01-15 15:56:31 base: 1126) driver version: 6.4.3.5.293908
model input num: 1, output num: 3
index=0 name=images_220 n_dims=4 dims=[1 3 640 640] n_elems=1228800 size=2457600 fmt=0 type=1 qnt_type=0 fl=-65 zp=191 scale=0.073182
index=0 name=Reshape_Reshape_259/out0_0 n_dims=5 dims=[3 85 80 80] n_elems=1632000 size=1632000 fmt=0 type=3 qnt_type=2 fl=-56 zp=200 scale=0.088509
index=1 name=Reshape_Reshape_274/out0_1 n_dims=5 dims=[3 85 40 40] n_elems=408000 size=408000 fmt=0 type=3 qnt_type=2 fl=-69 zp=187 scale=0.081693
index=2 name=Reshape_Reshape_289/out0_2 n_dims=5 dims=[3 85 20 20] n_elems=102000 size=102000 fmt=0 type=3 qnt_type=2 fl=-65 zp=191 scale=0.073182
model is NCHW input fmt
input_width=640 input_height=640
model input height=640, width=640, channel=3
img.cols: 640, img.rows: 640
171.162007 ms
dog @ (279 18 458 216) 0.492511
cat @ (176 103 605 406) 0.41341736、rk3399 pro 环境搭建和yolov5 c++修改使用opencv开发使用_sxj731533730的博客-CSDN博客
参考:
Index of /pypi/simple/
RKNN 使用 — Firefly Wiki
使用方法 — Firefly Wiki
固件升级 — Firefly Wiki
32 、 YOLO5训练自己的模型以及转ncnn模型_sxj731533730的博客-CSDN博客
瑞芯微RV1126/1109开发流程之模型转换_xidaoliang123的博客-CSDN博客_rv1126开发
YOLOv5s部署在瑞芯微电子RK3399Pro中使用NPU进行加速推理_Deepsdu的博客-CSDN博客
yolov5和rknn模型的问题_走错路的程序员的博客-CSDN博客_rknn yolov5