竞赛获奖系统解读:远场说话人确认中基于两阶段迁移学习解决域不匹配问题
作为Interspeech2022的赛事活动,远场说话人验证挑战赛 (FFSVC) 由昆山杜克大学、新加坡国立大学、南加州大学和希尔贝壳联合组织,主要关注极具挑战性的远场说话人确认任务。2020年举办的第一届FFSVC赛事主要关注多通道跨域说话人确认问题 [1]。今年第二届FFSVC赛事[2]考察单通道说话人确认的跨域问题,具体分为两个赛道,赛道一主要关注完全监督的说话人确认,其中允许使用VoxCeleb和FFSVC的数据作为训练集;赛道二考察半监督方法的远场说话人确认,具体来说只允许用VoxCeleb数据的说话人标签,不允许使用FFSVC数据的说话人标签。竞赛网址为:https://ffsvc.github.io/。
本文介绍了西工大音频语音与语言处理研究组与华为云合作提交在FFSVC2022上的说话人确认系统。FFSVC2022的挑战性主要体现在两个方面:(1) 域外数据只允许使用VoxCeleb数据[3],VoxCeleb是一个带噪的真实场景采集的英文数据,而域内数据FFSVC是中英混杂的麦克风阵列、IPhone和IPAD录制的数据,这意味域外数据训练集和域内数据训练集之间存在语种、场景、设备等域不匹配问题;(2)测试集中注册和测试存在同性别、跨语种、跨设备、跨距离等域不匹配问题。

图1 说话人确认任务中多重域不匹配问题
为了解决上述问题,我们提出了一个两阶段迁移学习框架。具体来说,在第一阶段,我们采用说话人感知权重迁移方法,使用 FFSVC 数据集和 VoxCeleb 数据集的一部分对预训练的域外模型进行微调。说话人感知是通过 VoxCeleb 预训练的域外模型评估域内 FFSVC 数据的分类准确度来获得的,目的是在域内模型中保持其强大的说话人区分能力。在第二阶段,我们在师生学习框架下使用说话人中心迁移学习方法来学习领域不变的说话人表征空间。具体来说,近场数据训练的教师模型的说话人表征空间在使用 FFSVC 数据进行训练期间指导学生模型的学习。此外,我们采用模型汤(model soup)策略来平均多个模型的权重、自适应对称分数归一化 (as-norm) 以及分数融合提升模型性能。综合上述方法,提交系统(NPU-HC)在此次竞赛中取得了双赛道第二名的优异成绩。

图2 竞赛获奖证书
论文题目:NPU-HC Speaker Verification System for Far-field Speaker Verification Challenge 2022
作者列表:张丽, 李越, 王娜敏, 刘杰, 谢磊
论文网址:https://ffsvc.github.io/assets/pdf/npu_22.pdf

图3 论文截图
1、背景动机
近年来,基于深度神经网络的说话人确认技术在相对可控场景下取得了卓越的性能。但是在实际应用场景中,外在不可控的环境噪声、人与设备交互距离所产生的远场语音衰减、房间混响混响、近场注册与远场验证的域不匹配、域外训练数据与远场域内数据不匹配(domain mismatch)等问题都会导致说话人确认系统性能的大幅度下降。针对这个问题,在我们先前提出的说话人确认中近场到远场的多层级迁移学习方案的基础上,我们进一步完善,提出了两阶段的迁移学习框架,该框架不仅考虑注册语音和测试语音之间的域不匹配问题,还考虑少量的远场域内数据训练集与大量域外数据集之间的不匹配问题。具体而言,第一阶段是将域外数据VoxCeleb训练的模型迁移到域内数据FFSVC上,第二阶段是在教师-学生 (teacher-student) 框架下,利用高质量的近讲语音说话人表征引导远场语音说话人表征的学习。
2、两阶段迁移学习
两阶段迁移学习方案如图5所示。在第一阶段,我们使用域内数据微调出一个在 IPhone录制的数据上表现良好的教师模型。在微调过程中,我们采用说话人感知权重迁移损失来正则化说话人嵌入提取器。具体来说,域外模型是由域外的大型说话人数据集VoxCeleb训练的,在用域内数据微调域外数据训练的模型时,我们的目标是保留其强大的说话人识别能力,但是又不过拟合到少量的域内数据,因此我们提出了说话人感知的权重迁移损失来实现模型泛化同时防止灾难遗忘。在第二阶段,我们使用说话人中心迁移学习方法来映射来自教师模型和学生模型的说话人表征。我们改进了之前的多级迁移学习方法[4],在教师-学生迁移学习框架中,教师模型由第一阶段训练的域内模型初始化,并通过近场(iPhone录制)语音进行微调。中心化的说话人表征比单个说话人表征更有表征能力更鲁棒,并且它们对近场数据具有良好的说话人识别能力。我们通过根据说话人标签平均获得说话人嵌入的 iPhone 数据来生成说话人中心嵌入空间。而后使用来自教师模型的说话人嵌入空间来指导学生模型学习,并提出说话人中心转移损失。
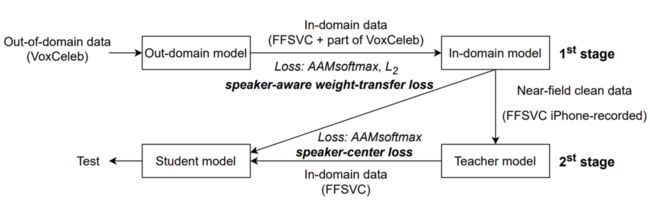
图5 两阶段迁移学习方法的流程
说话人感知权重迁移
在第一阶段,说话人感知的权重传递损失是限制预训练模型和微调模型的权重之间的距离。微调损失包括说话人分类损失 AAMSoftmax [5]、权重传递损失和常用的 L2 正则化损失。
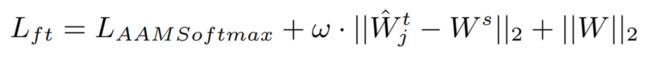
ω 是说话者感知权重,表示每层中卷积核参数的可转移程度。首先,我们微调VoxCeleb 预训练的域外模型,并将最后一个分类层替换为一个新层,该层的节点数等于 FFSVC 数据集中说话人的数量,然后我们只用 FFSVC数据训练新的分类层。我们使用这个模型来评估每一层中每个卷积核参数对说话人分类准确度的影响。具体来说,我们依次对每个卷积核的参数进行掩码,计算掩码后的损失函数与之前的损失函数的差值。因此,这种差异表明了卷积核的域内 FFSVC 数据的可迁移性的大小。它通过 softmax 函数进一步归一化,产生说话人感知矩阵ω.
中心化说话人表征迁移
为了缓解注册-测试不匹配 (包括测试中的跨信道、跨距离、跨时间不匹配), 我们提出了中心化说话人表征迁移方案。它包括两个步骤:
第一步:通过教师模型提取 iPhone 录制语音的说话人嵌入,然后根据说话人标签对所有说话人嵌入进行平均,得到每个说话人的说话人中心。

第二步:减少来自教师和学生模型的说话人表征之间的 MSE 和角度距离损失

其中L_M 是 MSE 距离损失,L_A 是角度损失,分别为:


3、融合方案
为了进一步提升我们说话人确认系统的性能,我们采用了两种融合方案,模型汤(model soup)融合和分数融合,并且在分数融合之前进行自适应对称归一化。
模型融合
模型汤是一种有效的模型融合策略[6],其中模型的融合是通过对模型的权重进行平均而不是组合每个单独的输出来构成的。因此在此次挑战赛中,我们采用贪心汤法来提高模型融合的性能。具体来说,对于训练过程中的每种类型的神经网络模型,我们在针对开发集的实验中按照 minDCF 的降序对模型进行排序,并选择前 5 个模型进行融合。然后通过随后将前5个模型中的每个模型添加为汤中的潜在成分来构造贪心汤,并且如果其在开发集上的性能表现有所提高,我们即保留该模型在汤中。最终将留在汤中的模型参数求均值得到最后融合好的模型。
分数融合
在分数融合前,我们采用了自适应对称归一化[7]。之后我们根据模型在开发集上的效果分配权重,将所选模型的分数融合在一起。
4、实验
实验配置
数据集采用的是VoxCeleb和FFSVC 2020 & 2022。后端打分方式是余弦距离。在FFSVC2022竞赛中,我们按照表 1 的模型配置训练了四个模型。
表1 模型配置
| 模型名称 |
参数配置 |
| ECAPA_TDNN (1024) [8] |
帧级卷积层中有 1024 个通道 池化层是注意力统计池化(ASP) [10] 倒数第二层的说话人表征大小为 192 |
| ECAPA_TDNN (2048) |
帧级卷积层中有 2048 个通道 池化层是注意力统计池化(ASP) 倒数第二层的说话人表征大小为 256 |
| ResNet34SE (256) [9] |
帧级卷积层中有 1024 个通道 池化层是注意力的统计池化(SAP) [11] 倒数第二层的说话人表征大小为 192 |
| ResNet34SE (512) |
残差块的通道配置为 {64, 128, 256, 512} 池化层是自注意力池化(SAP) 倒数第二层的说话人表征大小为 512 |
实验结果
我们首先在 ECAPA-TDNN (1024) 模型上验证了所提出方法的有效性,结果总结于表 2 。从表2 中的消融实验结果可以看出,本文提出的各种方法在开发集(DEV)上均取得了正向收益。用上所有的方法,ECAPA-TNDD (1024)最终在开发集上的最佳 EER/minDCF 分别为 3.921%/0.356 和 4.033%/0.359。
表2 提出的方法在赛道一的开发和测试集上的效果,说话人表征提取模型是ECAPA-TDNN (1024)

之后,我们将提出的方案(使用所有方法)应用于 ECAPA-TDNN (2048)、ResNet34SE-256 和 ResNet34SE512。实验结果如表 3 所示。我们可以看到,最好的单一模型是 ECAPA-TDNN (2048),在评估集(EVAL)上的 EER/minDCF 为 3.708%/0.339。融合来自 ECAPA-TDNN (1024)、ECAPATDNN (2048)、ResNet34SE-256 和 ResNet34SE-512 的分数后,最终的 EER 和 minDCF 在评估集上分别为 3.470% 和 0.319,作为我们提交到赛道一的最终分数。
表3 提出的方法在赛道一的开发和测试集上的效果,包括不同模型和模型融合的结果

在赛道二中,我们首先使用 k-means [12] 生成伪说话人标签,然后使用靠近集群中心的高置信度话语来微调域外模型。在得到域内模型后,我们从域内模型中选择每个说话人的十个具有最准确后验概率的句子来获得说话人中心嵌入空间。最后,说话人中心嵌入空间用于指导使用 FFSVC 数据集进行学生模型训练。赛道二的结果如表 4 所示。可以看到,融合来自 ECAPA-TDNN (2048) 和 ResNet34SE (512) 的分数获得了最佳 EER/minDCF ( 5.342%/0.545),这是我们系统在赛道二上的最终分数。
表4 提出的方法在赛道二上的表现

5、结论
本文描述了 NPU-HC 团队提交到 FFSVC2022 的系统。在竞赛中,我们提出了一个两阶段迁移学习框架来处理域不匹配问题。具体来说,采用说话人感知权重转移来解决训练数据不匹配问题,采用基于说话人中心迁移损失的教师-学生框架来解决注册-测试不匹配问题。实验证明了所提出的两阶段迁移学习方法的有效性。此外,模型汤融合和自适应对称分数归一化对系统性能提升也有帮助。通过上述方法,我们系统在评估集中的 EER/minDCF 分数在赛道一和赛道二上分别为 3.470%/0.319 和 5.342%/0.545,最终获得了双赛道第二名的成绩。
6、参考文献
[1] Xiaoyi Qin , Ming Li , Hui Bu , Rohan Kumar Das, Wei Rao, Shrikanth Narayanan , Haizhou Li. "The FFSVC2020 evaluation plan." INTERSPEECH (2020).
[2] Xiaoyi Qin, Ming Li, Hui Bu, Shrikanth Narayanan, Haizhou Li . "Far-field Speaker Verification Challenge (FFSVC) 2022: Challenge Evaluation Plan." INTERSPEECH (2022).
[3] Nagrani, Arsha, Joon Son Chung, and Andrew Zisserman. "Voxceleb: a large-scale speaker identification dataset." INTERSPEECH (2017).
[4] Li Zhang, Q Wang, Kong Aik Lee, Lei Xie, Haizhou Li. "Multi-level transfer learning from near-field to far-field speaker verification." INTERSPEECH (2021).
[5] Yi Liu, Liang He, Jia Liu, “Large Margin Softmax Loss for Speaker Verification,”INTERSPEECH, 2019, pp. 2873–2877.
[6] Mitchell Wortsman, Gabriel Ilharco, Samir Ya Gadre, Rebecca Roelofs, Raphael Gontijo-Lopes, Ari S Morcos, Hongseok Namkoong, Ali Farhadi, Yair Carmon, Simon Kornblith, Ludwig Schmidt., “Model soups: averaging weights of multiple fine-tuned models improves accuracy without increasing inference time,” PMLR, 2022.
[7] Pavel Matejka, Ondrej Novotny, Oldrich Plchot, Lukas Burget, Mireia Diez Sanchez, Jan “Honza” Cernocky, “Analysis of score normalization in multilingual ` speaker recognition.” INTERSPEECH , 2017, pp.
[8] Desplanques, Brecht, Jenthe Thienpondt, and Kris Demuynck. "ECAPA-TDNN: Emphasized channel attention, propagation and aggregation in tdnn based speaker verification." INTERSPEECH (2020).
[9] Hee Soo Heo, Bong-Jin Lee, Jaesung Huh, Joon Son Chung. "Clova baseline system for the voxceleb speaker recognition challenge 2020." INTERSPEECH (2020).
[10] K. Okabe, T. Koshinaka, and K. Shinoda, “Attentive Statistics Pooling for Deep Speaker Embedding,” INTERSPEECH. 2018.
[11] Weicheng Cai, Jinkun Chen and Ming Li, “Exploring the Encoding Layer and Loss Function in End-to-End Speaker and Language Recognition System,” Odyssey 2018, 2018, pp. 74–81.
[12] K. Krishna and M. N. Murty, “Genetic k-means algorithm,” IEEE Transactions on Systems, Man, and Cybernetics, Part B (Cybernetics), vol. 29, no. 3, pp. 433–439, 1999.