【损失函数:1】L1、L2、SmoothL1(附Pytorch实现)
损失函数
- 前言
- 一、基础损失
-
- 1.L1损失(MAE:平均绝对误差)
- 2.L2损失(MSE:均方差)
- 3.L1、L2对比
- 三、扩展
-
- 1.Smooth L1损失(平滑L1损失)
- 参考:
前言
作者自己是做图像去雾的,平常也会看一些其他的图像恢复方向的文章,比如图像去噪、图像增强、图像去模糊以及图像超分辨等。我们知道损失函数决定了网络训练目标,对于一个任务最后可以实现的功能影响很大,这里我就想把我见过的一些损失函数进行记录,供大家学习参考。
一、基础损失
假设网络输入为x,输出为 y ‾ \overline{\text{y}} y=f(x),x的真实标签为y,其中:
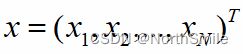 、
、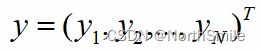 、
、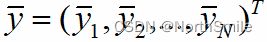
上述定义中的N通常表示一个批次中所包含的样本数量,因为在网络训练时我们通常是逐批次送入网络训练,每个批次计算一次损失,然后进行参数更新。
1.L1损失(MAE:平均绝对误差)
L1损失是最常用的一种网络训练损失,通常指平均绝对误差损失,公式如下:


1)调用方式
torch.nn.L1Loss(size_average=None, reduce=None, reduction='mean')
该类对于其输入特征的形状没有要求,可以输入任意维度的特征,其输出特征形状与输入保持一致。
2)代码实例
import torch
import torch.nn as nn
import numpy as np
y=torch.randint(10,size=(10,4),dtype=torch.float32)
y_=torch.randint(10,size=(10,4),dtype=torch.float32)
print(np.transpose(y))
print(np.transpose(y_))
print('-'*25)
# print(torch.sum(y))
# 1.L1损失
# 手动实现
def l1_loss(y_,y):
n,features=y_.shape[0],y_.shape[1]
loss=0
for i in range(0,n):
loss+=torch.sum(torch.square(y_[i]-y[i]))/features
return loss/n
loss_manual=l1_loss(y_,y)
# Pytorch内部实现
creation=nn.L1Loss()
loss=creation(y_,y)
print(loss_manual)
print(loss)
y:
tensor([[6., 4., 4., 0., 0., 0., 4., 5., 0., 9.],
[4., 0., 8., 9., 6., 7., 0., 5., 1., 2.],
[4., 8., 3., 4., 9., 4., 2., 4., 4., 8.],
[0., 6., 4., 6., 6., 9., 6., 0., 2., 2.]])
y_:
tensor([[7., 2., 6., 5., 7., 4., 2., 0., 1., 3.],
[7., 5., 6., 3., 2., 9., 8., 6., 5., 3.],
[9., 1., 0., 7., 5., 3., 4., 2., 0., 5.],
[7., 5., 5., 5., 5., 6., 3., 6., 1., 5.]])
-------------------------
tensor(3.3000)
tensor(3.3000)
2.L2损失(MSE:均方差)
L2损失通常指均方差损失,在一些回归任务中比较常用,公式如下:
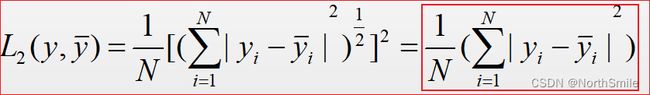

1)调用方式
torch.nn.MSELoss(size_average=None, reduce=None, reduction='mean')
该类对于其输入特征的形状没有要求,可以输入任意维度的特征,其输出特征形状与输入保持一致。
2)代码实例
y=torch.randint(10,size=(10,4),dtype=torch.float32)
y_=torch.randint(10,size=(10,4),dtype=torch.float32)
print(np.transpose(y))
print(np.transpose(y_))
print('-'*25)
# 2.L2损失
# 手动实现
def l2_loss(y_,y):
n,features=y_.shape[0],y_.shape[1]
loss=0
for i in range(0,n):
loss+=torch.sum(torch.square(y_[i]-y[i]))/features
return loss/n
loss_manual=l2_loss(y_,y)
# 内部实现
creation=nn.MSELoss()
loss=creation(y_,y)
print(loss_manual)
print(loss)
tensor([[3., 3., 7., 5., 8., 0., 4., 0., 9., 9.],
[9., 1., 1., 3., 0., 4., 9., 9., 2., 5.],
[4., 8., 5., 6., 5., 3., 9., 0., 7., 6.],
[0., 0., 1., 3., 6., 7., 3., 5., 5., 4.]])
tensor([[7., 1., 3., 9., 8., 9., 7., 8., 0., 6.],
[8., 8., 9., 8., 6., 9., 8., 4., 7., 6.],
[4., 7., 5., 7., 9., 5., 6., 0., 7., 5.],
[5., 3., 3., 8., 3., 9., 9., 4., 2., 1.]])
-------------------------
tensor(17.7750)
tensor(17.7750)
3.L1、L2对比
1)L1损失函数的鲁棒性比L2强:
- L2函数将真实标签y与网络输出 y ‾ \overline{\text{y}} y之间的误差进行了放大(二者之间误差大于1时)或缩小(二者之间误差小于1时),使用L2函数为训练目标的模型会对这种类型的样本更加敏感,在优化过程中模型不断调整适应这些样本,而这些样本可能本身是一个异常值,模型对这些异常值的优化适应则会导致其训练方向偏离目标。
2)L2拥有比L1更光滑的曲线,更利于网络收敛:
- L1曲线连续,但是在y−y_=0处不可导,且L1大部分情况下梯度是保持不变的,这不利于函数的收敛和模型的学习,所以在使用时,通常配以学习率衰减策略,逐渐降低学习率。但是,无论对于什么样的输入值,都有着稳定的梯度,不会导致梯度爆炸问题,具有较为稳健性的解。
- L2的函数曲线光滑、连续,处处可导,便于使用梯度下降算法,且随着误差的减小,梯度也在减小,这有利于收敛,即使使用固定的学习速率,也能较快的收敛到最小值。

可看一下:对于同样的y和 y ‾ \overline{\text{y}} y两种损失函数对应的输出结果
y和 y ‾ \overline{\text{y}} y分别如下:
y=torch.tensor([[3., 3., 7., 5., 8., 0., 4., 0., 9., 9.],
[9., 1., 1., 3., 0., 4., 9., 9., 2., 5.],
[4., 8., 5., 6., 5., 3., 9., 0., 7., 6.],
[0., 0., 1., 3., 6., 7., 3., 5., 5., 4.]])
y_=torch.tensor([[7., 1., 3., 9., 8., 9., 7., 8., 0., 6.],
[8., 8., 9., 8., 6., 9., 8., 4., 7., 6.],
[4., 7., 5., 7., 9., 5., 6., 0., 7., 5.],
[5., 3., 3., 8., 3., 9., 9., 4., 2., 1.]])
对应输出结果如下:
l1损失,tensor(3.3750)
l2损失,tensor(17.7750)
三、扩展
1.Smooth L1损失(平滑L1损失)
平滑L1损失对前面的L1、L2损失进行中和改进,与L1损失最直观的区别在于y-y_=0处可导,公式如下:

其中,

函数曲线如下图所示:

1)调用方式
torch.nn.SmoothL1Loss(size_average=None, reduce=None, reduction='mean', beta=1.0)
该类对于其输入特征的形状没有要求,可以输入任意维度的特征,其输出特征形状与输入保持一致。
Pytorch内部在实现时对该函数进行了一定的优化,如下所示:

可以看到当beta=1时,就是开头说到的特殊情况。
2)代码实例
# 3.平滑L1损失
# 手动实现
def smooth_item(x,beta):
if x<beta:
loss_item=(0.5*torch.square(x))/beta
else:
loss_item=x-0.5*beta
return loss_item
def smooth_l1(y_,y,beta=1):
n, features = y_.shape[0], y_.shape[1]
loss=0
for i in range(0,n):
loss_row=0
for j in range(0,features):
loss_row+=smooth_item(torch.abs(y_[i][j]-y[i][j]),beta)
loss_row/=features
loss+=loss_row
return loss/n
loss_manual=smooth_l1(y_,y)
# 内部实现
creation=nn.SmoothL1Loss()
loss=creation(y_,y)
print(loss_manual)
print(loss)
tensor([[1., 5., 3., 6., 9., 2., 8., 0., 4., 3.],
[6., 5., 0., 6., 1., 7., 9., 8., 5., 0.],
[2., 9., 2., 8., 2., 6., 0., 9., 6., 6.],
[0., 4., 4., 9., 0., 8., 8., 0., 7., 2.]])
tensor([[7., 7., 9., 3., 0., 7., 3., 9., 1., 9.],
[4., 9., 9., 9., 6., 3., 2., 0., 7., 1.],
[8., 8., 7., 5., 9., 3., 0., 7., 8., 1.],
[7., 8., 3., 2., 1., 6., 0., 1., 6., 1.]])
-------------------------
tensor(3.6625)
tensor(3.6625)
3)与L1、L2损失对比
- SmoothL1损失既解决了L1损失在y-y_=0处不可导的问题,又避免了L2在误差大于1时会放大误差的问题,很好地避开了他们的缺陷;
- 相对于L1来说,SmoothL1可以更好地收敛;
- 相对于L2来说,SmoothL1对于那些异常值不敏感;
- 本质来看,在(-1,1)区间内SmoothL1近似L2,(-1,1)区间外SmoothL1近似L1;

参考:
1)https://www.cnblogs.com/wangguchangqing/p/12021638.html#autoid-0-4-0