《WeNet语音识别实战》答疑回顾(三)

问 1:dpp init是会自动生成的吗?需要自己预先touch 吗?
答:自动生成的。
问 2:请问一下,远程服务器docker启动了,本地如何前端访问?

答:可以参考连接远程服务器内的docker - 知乎
问 3:8k 16bit的wav,计算 cmvn 的时候每个frame是多长?10ms?
答:帧长25ms,帧移10ms
问 4:是不是目前基于aishell预训练的模型在给定的py脚本下里面是没办法流式的?
尝试改了 encoder的初始化参数 “use_dynamic_chunk”, 推理时能够走到forward_chunk_by_chunk的分支,但是预测的结果好像不太正常。
答:如果模型训练的时候没有用dynamic chunk,在推理时强行更改配置文件也无法做流式。
问 5:WeNet做长语音识别的策略是什么?源码好像不能超过20s,如果超过怎么做?
答:超过的话,一个是 embedding 没法表示,一个是一直不能做 rescore。原理就是识别到足够长的blank就认为语音结束,rescore后清空一些状态,重新开始识别。runtime 的代码中,超过 20s 就会强制截断。
问 6:WeNet中用onnx推理提取fbank特征这块,在triton中用的是kaldifeature的库,而在recongnize_onnx.py中,用的是torchaudio,是前者比后者有优势吗?还是因为 torchaudio 对dataloader的适配性比kaldifeature好?
答:特征是相同的,两者没有差别。
问 7:那如果有长语音识别需求就需要自己手动裁剪,然后再合并?
答:开启实时长语音识别选项即可。
问 8:训了将近40轮损失咋还这么高,是什么情况?

答:可能是学习率问题,在conf下的配置文件中可以调整lr参数。
问 9:推理的时候遇到这个问题?

答:确认一下模型的路径是不是正确。
问 10:图示错误的原因是什么?
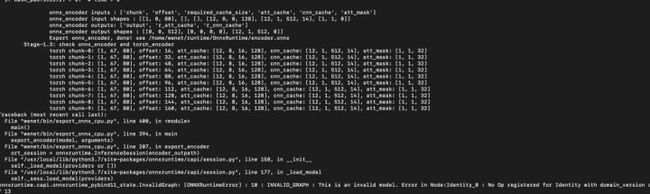
答:加载模型有问题,确认下模型路径以及模型文件是否正确。
问 11:老师,我0号pt的cv loss 64.88,1号pt的cv loss 63.87多?这对么?我记得上次训练 0 号的cv loss 63多,1号就到了10点多。当然了,两次数据不同,用的脚本也不同,这次用的是multi cn
答:数据和脚本都不同,这个没有太多对比,可以往后再训练看下loss的变化。
问 12:用multi cn 训练了3个pt,cv loss,64 - 63 - 65,,训练还在继续。
这是不是看起来,要收敛不了啊?
答:可以再继续训练看下loss的变化。
问 13:我切分成8000的chunk, tobytes 发送, 但是收不到返回是什么原因呀?

答:没开实时长语音识别。
问 14:在conda环境下,把python代码打包成so文件之后,发现原来文件里 import numpy 报错,说找不到这个模块,但是我python import确实正常的
答:如果用的是setup的方式,require要加上numpy的信息。
问 15:WeNet支持多卡训练吗?
答:多卡多机都支持。
问 16:请问下为什么流式asr中 不说话的时候好像也会一直会有字输出?
答:训练的模型没有适应噪音,鲁棒性不够,可以尝试在外面套一个vad。
问 17:为什么无论是用自己编译的WeNet windows版本,还是直接从github上下载release版本,运行示例的时候都没有日志输出,都是直接输出结果呢?
这个是通过wsl2安装了一个ubuntu系统,通过set设置也不行,另外直接使用powerShell 运行还是一样的结果。
![]()
答:windows 应该用 set 而不是 export,
虽然是 ubuntu 系统,但是调用的还是 windows 的 exe 程序。还有一种方法就是直接在 windows 的环境变量页面通过非命令行的方式添加。可参考https://jingyan.baidu.com/article/3c343ff72632df4c3679636c.html,添加后记得重启命令行工具。
问 18:从github上下载了代码,仅仅修改数据存放位置字段,执行时报错,怎么回事呀?


答:需要手工把这个压缩文件解压,stage -1 是download and untar。要跟stage -1的output一致。
问 19:用WeNetspeech的checkpoint做增量训练,数据有40个小时左右。训练出来的模型效果不如直接发出来的好,请问还需要更多的数据吗?还是说大概率是训练方式出错呢?loss本身是有下降的。
答:应该是数据过拟合了,可以查看下test loss的变化。
问 20:Chunk size 16 和 full 的 attention rescoring 解码结果 wer相差过大(8%+),该怎么理解这个现象呢,是否可以考虑增加训练时chunk size 在1-25上的随机概率,来缓解这个问题?
答:推理时给16的话它还是不能获取足够多的上下文信息。
问 21:WeNet在训练语言模型时需要分词吗?ctc的输出结果是字 感觉用不到分词。
答:不需要。
问 22:想请教下unified这篇论文中的two pass指的是什么,是融合了流式和非流式的意思吗?还是先Nbest然后rescore这种叫two pass?
答:unified是指融合了流式和非流式的意思,其核心是dynamic chunk,two pass是指先做Nbest然后rescore。
问 23:WeNet可以做流式识别,那Kaldi也能做流式识别吗?
答:当然可以的。
问 24:WeNet中aishell1这个例子用cpu跑和用gpu跑结果有差别吗?
答:cpu的速度比较慢,但是解码结果应该差距不大。
问 25: run.sh里面,gpu id,跟rank id 有对应关系么?是什么样的关系?
答:可以参考https://mp.weixin.qq.com/s/6FYJ