【ML】拆分数据集以进行机器学习
简介
为了确定我们模型的有效性,我们需要有一个公正的测量方法。为此,我们将数据集拆分为training、validation和testing数据拆分。
- 使用训练拆分来训练模型。
在这里,模型将可以访问输入和输出以优化其内部权重。
- 在训练拆分的每个循环(epoch)之后,我们将使用验证拆分来确定模型性能。
在这里,模型不会使用输出来优化其权重,而是使用性能来优化训练超参数,例如学习率等。
- 训练停止(epoch(s))后,我们将使用测试拆分对模型进行一次性评估。
这是我们衡量模型在新的、看不见的数据上表现的最佳方法。请注意,当性能改进不显着或我们可能指定的任何其他停止标准时,训练会停止。
我们需要在拆分之前先清理我们的数据,至少对于拆分所依赖的特征。所以这个过程更像是:预处理(全局,清洗)→分裂→预处理(局部,转换)。
朴素的分裂
我们首先将数据集拆分为三个数据拆分,用于训练、验证和测试。
from sklearn.model_selection import train_test_split# Split sizes
train_size = 0.7
val_size = 0.15
test_size = 0.15对于我们的多类任务(每个输入都有一个标签),我们希望确保每个数据拆分具有相似的类分布。stratify我们可以通过添加关键字参数来指定如何对拆分进行分层来实现这一点。
# Split (train)
X_train, X_, y_train, y_ = train_test_split(
X, y, train_size=train_size, stratify=y)print (f"train: {len(X_train)} ({(len(X_train) / len(X)):.2f})\n"
f"remaining: {len(X_)} ({(len(X_) / len(X)):.2f})")Output:
train: 668 (0.70) remaining: 287 (0.30)
# Split (test)
X_val, X_test, y_val, y_test = train_test_split(
X_, y_, train_size=0.5, stratify=y_)print(f"train: {len(X_train)} ({len(X_train)/len(X):.2f})\n"
f"val: {len(X_val)} ({len(X_val)/len(X):.2f})\n"
f"test: {len(X_test)} ({len(X_test)/len(X):.2f})")train: 668 (0.70) val: 143 (0.15) test: 144 (0.15)
# 获取每个类的计数
counts = {}
counts["train_counts"] = {tag: label_encoder.decode(y_train).count(tag) for tag in label_encoder.classes}
counts["val_counts"] = {tag: label_encoder.decode(y_val).count(tag) for tag in label_encoder.classes}
counts["test_counts"] = {tag: label_encoder.decode(y_test).count(tag) for tag in label_encoder.classes}# 查看分布
pd.DataFrame({
"train": counts["train_counts"],
"val": counts["val_counts"],
"test": counts["test_counts"]
}).T.fillna(0)| computer-vision | mlops | natural-language-processing | other | |
|---|---|---|---|---|
| train | 249 | 55 | 272 | 92 |
| val | 53 | 12 | 58 | 20 |
| test | 54 | 12 | 58 | 20 |
很难比较这些,因为我们的训练和测试比例不同。让我们看看平衡后的分布是什么样子。我们需要将测试比率乘以多少才能得到与训练比率相同的数量?
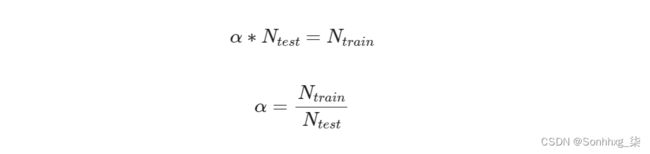
# 调整拆分的计数
for k in counts["val_counts"].keys():
counts["val_counts"][k] = int(counts["val_counts"][k] * \
(train_size/val_size))
for k in counts["test_counts"].keys():
counts["test_counts"][k] = int(counts["test_counts"][k] * \
(train_size/test_size))dist_df = pd.DataFrame({
"train": counts["train_counts"],
"val": counts["val_counts"],
"test": counts["test_counts"]
}).T.fillna(0)
dist_df| computer-vision | mlops | natural-language-processing | other | |
|---|---|---|---|---|
| train | 249 | 55 | 272 | 92 |
| val | 247 | 56 | 270 | 93 |
| test | 252 | 56 | 270 | 93 |
我们可以通过计算每个拆分的类计数与平均值(理想拆分)的标准差来查看我们的原始数据拆分中有多少偏差。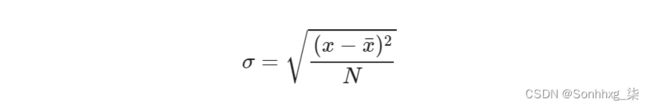
# Standard deviation
np.mean(np.std(dist_df.to_numpy(), axis=0))0.9851056877051131
# Split DataFrames
train_df = pd.DataFrame({"text": X_train, "tag": label_encoder.decode(y_train)})
val_df = pd.DataFrame({"text": X_val, "tag": label_encoder.decode(y_val)})
test_df = pd.DataFrame({"text": X_test, "tag": label_encoder.decode(y_test)})
train_df.head()| text | tags | |
|---|---|---|
| 0 | laplacian pyramid reconstruction refinement se... | computer-vision |
| 1 | extract stock sentiment news headlines project... | natural-language-processing |
| 2 | big bad nlp database collection 400 nlp datasets... | natural-language-processing |
| 3 | job classification job classification done usi... | natural-language-processing |
| 4 | optimizing mobiledet mobile deployments learn ... | computer-vision |
多类别分类
如果我们有一个多标签分类任务,那么我们将通过skmultilearn库应用迭代分层,该库本质上将每个输入分成子集(其中每个标签都被单独考虑),然后从最少的“正面”开始分配样本样本并处理具有最多标签的输入。
from skmultilearn.model_selection import IterativeStratification def iterative_train_test_split(X, y, train_size): """Custom iterative train test split which 'maintains balanced representation with respect to order-th label combinations.' """ stratifier = IterativeStratification( n_splits=2, order=1, sample_distribution_per_fold=[1.0-train_size, train_size, ]) train_indices, test_indices = next(stratifier.split(X, y)) X_train, y_train = X[train_indices], y[train_indices] X_test, y_test = X[test_indices], y[test_indices] return X_train, X_test, y_train, y_test迭代分层本质上会产生分裂,同时“试图保持关于顺序标签组合的平衡表示”。我们习惯于
order=1迭代拆分,这意味着我们关心在拆分中提供每个标签的代表性分布。但是我们也可以考虑更高阶的标签关系,我们可能关心标签组合的分布。