我眼中的大数据(三)——MapReduce
CSDN话题挑战赛第2期
参赛话题:大数据技术分享
这次来聊聊Hadoop中使用广泛的分布式计算方案——MapReduce。MapReduce是一种编程模型,还是一个分布式计算框架。
MapReduce作为一种编程模型功能强大,使用简单。运算内容不只是常见的数据运算,几乎大数据中常见的计算需求都可以通过它来实现。使用的时候仅仅需要通过实现Map和Reduce接口的方式来完成计算逻辑,其中Map的输入是一对
下面,就以WordCount为例,熟悉一下MapReduce:
WordCount是为了统计文本中不用词汇出现的次数。如果统计一篇文本的内容,只需要写一个程序将文本数据读入内存,创建一个字典,记录每个词出现的次数就可以了。但是如果想统计互联网中网页的词汇数量,就需要用MapReduce来解决。
public class WordCount {
public static class TokenizerMapper
extends Mapper{
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value, Context context
) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
}
public static class IntSumReducer
extends Reducer {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable values,
Context context
) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
} 从上面代码不难发现,MapReduce核心是一个map函数和一个reduce函数。map函数的输入主要是一个
MapReduce在运行过程中有三个关键进程,分别是Driver进程、JobTracker进程、TaskTracker进程。
1.Driver进程:是启动MapReduce的主入口,主要是实现Map和Reduce类、输入输出文件路径等,并提交作业给Hadoop集群,也就是下面的JobTracker进程。
2.JobTracker进程:根据输入数据数量,命令TaskTracker进程启动相应数量的Map和Reduce进程,并管理整个生命周期的任务调度和监控。
3.TaskTracker进程:负责启动和管理Map以及Reduce进程。因为需要每个数据块都有对应的map函数,TaskTracker进程通常和HDFS的DataNode进程启动在同一个服务器。
JobTracker进程和TaskTracker进程是主从关系,同一时间提供服务的主服务器通常只有一台,从服务器有多台,所有的从服务器听从主服务器的控制和调度安排。主服务器负责为应用程序分配服务器资源以及作业执行的调度,而具体的计算操作则在从服务器上完成。MapReduce的主服务器就是JobTracker,从服务器就是TaskTracker。
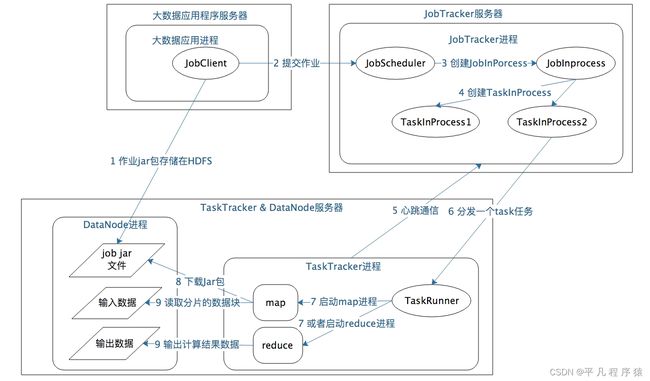
1.JobClient将包含MapReduce的JAR包存储在HDFS中,将来这些JAR包会分发给Hadoop集群中的服务器执行计算。
2.向JobTracker提交Job。
3.JobTracker根据调度策略创建JobInProcess树,每个作业都会有一个自己的JobInProcess树。
4.JobInProcess根据输入数据的块数和配置中的Reduce数目创建相应数量的TaskInProcess。
5.TaskTracker和JobTracker进行心跳通信。
6.如果TaskTracker有空闲的计算资源,JobTracker就会给它分配任务。
7.TaskTracker收到任务类型(是Map还是Reduce)和任务参数(JAR包路径、输入数据文件路径),启动相应的进程。
8.Map或者Reduce进程启动后,检查本地是否有要执行任务的JAR包文件,如果没有,就去HDFS上下载,然后加载Map或者Reduce代码开始执行。
9.如果是Map进程,从HDFS读取数据;如果是Reduce进程,将结果写出到HDFS。
我们仅仅是编写一个map函数和一个reduce函数就可以了,不用关心这两个函数是如何被分布启动到集群上的,也不用关心数据块又是如何分配给计算任务的。
MapReduce框架要将一个相对简单的程序,在分布式的大规模服务器集群上并行执行起来却并不简单。理解MapReduce作业的启动和运行机制,对理解大数据的核心原理,做到真正意义上把握大数据作用巨大。