Improved Schemes for Episodic Memory-based Lifelong Learning 论文阅读+代码解析
论文地址点这里
一. 介绍
目前深度神经网络能够在单一任务上取得了显著的性能,然而当网络被重新训练到一个新的任务时,他的表现在以前训练过的任务上急剧下降,这种现象被称为灾难性遗忘。与之形成鲜明对比的是,人类的认知系统能够在不破坏以前学到的情况下获得新的知识。
灾难性遗忘激发了终身学习的领域。终身学习的一个核心难题是如何在旧任务和新任务之间取得平衡。在学习到新任务的过程中,原来学习到的知识通常会被打乱,从而导致灾难性遗忘。另一方面,偏向旧任务的学习算法会干扰新任务的学习。而针对这种场景下,目前提出了几种策略。包括基于正则化的方法,基于知识转移的方法和基于情景记忆的方法。特别是在基于情景记忆的方法,如梯度情景记忆(GEM)和平均梯度情景记忆(A-GEM)变现出显著的性能。在情景记忆中,使用小情景记忆存储旧任务中的实例,以指导当前任务的优化。
作者在本文中,从优化角度提出了基于情景记忆的终身学习方法的观点(针对GEM和A- GEM)。通过使用一步随机梯度下降法近似地解决了优化问题,并将标准梯度替换为混合随机梯度法。同时提出了两种不同的方案,MEGA-1,MEGA-2,可用于不同的场景。
二. 相关工作
基于正则化的方式: 经典方法EWC采用fisher information矩阵防止老任务的权重剧烈变化。PI中,作者介绍了智能突触,并赋予每一个突出的一个局部重要性度量,以避免旧的记忆被覆盖。R-WALK中利用基于KL发散的正则化来保存旧任务的知识。而在MAS中,网络的每个参数的重要性度量是基于预测输出函数对参数变化的敏感程度来计算的。
基于知识转移的方式: 在PROG-NN中,为每个任务添加一个新的列,该列和之前任务的隐藏层进行连接。同时,也有通过利用未标记(未使用)的数据来避免灾难性遗忘的方法,即使用知识蒸馏。
基于情景记忆的方式: 使用外部记忆增强标准神经网络是一种被广发采用的实践。在基于情景记忆的终身学习方法中,一个小的参考记忆用于存储旧任务中的信息。当当前的梯度和参考存储器上计算的梯度之间的角度为钝角时,GEM和A-GEM旋转当前的梯度。
作者提出的方案旨在改善基于情景记忆的方法。与A-GEM不同,该方案明确考虑了模型在当前梯度旋转过程中对旧任务和新任务的性能。
三. 终身学习
终身学习考虑的是在不降低旧任务性能的情况下学习新任务的问题去避免灾难性遗忘。假设有T个任务对应于T个数据集: { D 1 , D 2 , . . . , D T } \{D_1,D_2,...,D_T\} {D1,D2,...,DT}。每一个数据集 D t D_t Dt为一个元组 { x i , y i , t } \{x_i,y_i,t\} {xi,yi,t}组成的列表。和监督学习类似,每一个数据集 D t D_t Dt可以划分为训练集 D t t r D_t^{tr} Dttr和测试集 D t t e D_t^{te} Dtte。
在A-GEM中,任务被划分为 D C V = { D 1 , D 2 , . . . , D T C V } D^{CV}=\{D_1,D_2,...,D_{T^{CV}}\} DCV={D1,D2,...,DTCV}和 D E V = { D T C V + 1 D T C V + 2 , . . . , D T } D^{EV}=\{D_{T^{CV}+1}D_{T^{CV}+2},...,D_T\} DEV={DTCV+1DTCV+2,...,DT}。其中 D C V D^{CV} DCV用于交叉验证来搜索超参数。 D E V D^{EV} DEV用于实际的训练和评估。在搜索超参数时,我们可以在 D C V D^{CV} DCV中对示例进行多次传播,在 D E V D^{EV} DEV上执行训练,只对示例进行一次传递。
在终身学习中,一个模型 f ( x ; w ) f(x;w) f(x;w)被训练于一系任务 { D T C V + 1 , D T C V + 2 , . . . , D T } \{D_{T^{CV}+1},D_{T^{CV}+2},...,D_T\} {DTCV+1,DTCV+2,...,DT}。当模型训练到任务 D t D_t Dt,目标是预测 D t t e D_t^{te} Dtte的标签通过最小化 D t t r D^{tr}_t Dttr经验损失 l t ( w ) l_t(w) lt(w)而不会降低在 { D T C V + 1 t e , D T C V + 2 t e , . . . , D t − 1 t e } \{D_{T^{CV}+1}^{te},D_{T^{CV}+2}^{te},...,D_{t-1}^{te}\} {DTCV+1te,DTCV+2te,...,Dt−1te}
四. 基于情景记忆的终身学习观点
GEM和A-GEM通过使用一个小的情景记忆 M k M_k Mk来存储任务k中例子的子集。 情景记忆是通过为每个任务随机均匀地选择例子来填充的。当训练在任务 t t t时,情景记忆的损失可以被计算为: l r e f ( w t ; M k ) = 1 ∣ M k ∣ ∑ ( x i , y i ) ∈ M k l ( f ( x i ; w t ) , y i ) l_{ref}(w_t;M_k)=\frac{1}{|M_k|}\sum_{(x_i,y_i)\in M_k}l(f(x_i;w_t),y_i) lref(wt;Mk)=∣Mk∣1∑(xi,yi)∈Mkl(f(xi;wt),yi)。
在GEM和A-GEM中,采用小批量随机梯度下降法训练终身学习模型。我们使用 w k t w_k^t wkt表示为模型在任务t是尬部分训练到第k个mini-batch的权重。为了建立旧任务与第t个任务的性能权衡,我们在每个更新步骤中考虑以下的复合目标优化问题:
min w α 1 ( w k t ) l t ( w ) + α 2 ( w k t ) l r e f ( w ) = E ξ , ζ [ α 1 ( w k t ) l t ( w ; ξ ) + α 2 ( w k t ) l r e f ( w ; ζ ) ] \min_{w}\alpha_1(w_k^t)l_t(w)+\alpha_2(w_k^t)l_{ref}(w)=\mathbb{E_{\xi,\zeta}}[\alpha_1(w_k^t)l_t(w;\xi)+\alpha_2(w_k^t)l_{ref}(w;\zeta)] wminα1(wkt)lt(w)+α2(wkt)lref(w)=Eξ,ζ[α1(wkt)lt(w;ξ)+α2(wkt)lref(w;ζ)]
其中 ξ , ζ \xi,\zeta ξ,ζ表示有限支持的随机向量, l t ( w ) l_t(w) lt(w)为第t个任务的训练损失, l r e f ( w ) l_{ref}(w) lref(w)为根据情景记忆中存储的数据计算的预测损失, α 1 ( w ) , α 2 ( w ) \alpha_1(w),\alpha_2(w) α1(w),α2(w)为控制在每个mini-batch中 l t ( w ) l_t(w) lt(w)和 l r e f ( w ) l_{ref}(w) lref(w)的相关重要性。
因此从数学上来看,我们可以考虑使用以下更新:
w k + 1 t = a r g min w α 1 ( w k t ) l t ( w ; ξ ) + α 2 ( w k t ) l r e f ( w ; ζ ) w^t_{k+1} = arg\min_{w}\alpha_1(w_k^t)l_t(w;\xi)+\alpha_2(w_k^t)l_{ref}(w;\zeta) wk+1t=argwminα1(wkt)lt(w;ξ)+α2(wkt)lref(w;ζ)
GEM和A- GEM的思想时采用一阶方法(随机梯度)近似优化上式,其中一步随机梯度是从初始点 w k t w_k^t wkt开始的:
w k + 1 t = w k t − η ( α 1 ( w k t ) ∇ l t ( w ; ξ ) + α 2 ∇ ( w k t ) l r e f ( w ; ζ ) ) w^t_{k+1} = w_k^t - \eta( \alpha_1(w_k^t)\nabla l_t(w;\xi)+\alpha_2\nabla (w_k^t)l_{ref}(w;\zeta)) wk+1t=wkt−η(α1(wkt)∇lt(w;ξ)+α2∇(wkt)lref(w;ζ))
在GEM和A-GEM中 α 1 ( w ) \alpha_1(w) α1(w)为1,这意味着在训练期间总是对当前任务给予相同的重视,无论损失如何随时间变化。在终身学习过程中,当前损失和情景损失在每个小批量中都是动态变化的,而如果 α 1 ( w ) \alpha_1(w) α1(w)始终为1可能不能很好取得平衡。
五. 混合随机梯度
在本节中,作者引入了混合随机梯度(MEGA)来解决GEM和A-GEM的局限性。由于A-GEM的性能优于GEM,采用A- GEM的方式来计算情景参考损失。
5.1 MEGA-I
MEGA-I 为一种自适应的基于损失的方法,通过仅利用损失信息来平衡当前任务与旧任务。作者引入了一个预定义的灵敏参数 ϵ \epsilon ϵ。如下:
{ α 1 ( w ) = 1 , α 2 ( w ) = l r e f ( w ; ζ ) / l t ( w ; ξ ) if l t ( w ; ξ ) > ϵ α 1 ( w ) = 0 , α 2 ( w ) = 1 if l t ( w ; ξ ) < = ϵ \begin{dcases} \alpha_1(w)=1,\alpha_2(w)=l_{ref}(w;\zeta)/l_t(w;\xi) \ \ \ \ &\text{if } l_t(w;\xi) > \epsilon\\ \alpha_1(w)=0,\alpha_2(w)=1 &\text{if } l_t(w;\xi) <= \epsilon \end{dcases} {α1(w)=1,α2(w)=lref(w;ζ)/lt(w;ξ) α1(w)=0,α2(w)=1if lt(w;ξ)>ϵif lt(w;ξ)<=ϵ
从直观上来看,如果模型在当前任务上表现很好(也就是loss很小),那么MEGA-I关注于改善存储在情景记忆中的数据的性能。因为选择 α 1 ( w ) = 0 , α 2 ( w ) = 1 \alpha_1(w)=0,\alpha_2(w)=1 α1(w)=0,α2(w)=1。否则,当损失较大时候,MEGA-I则保持这两项混合随机梯度的平衡通过 l r e f ( w ; ζ ) , l t ( w ; ξ ) l_{ref}(w;\zeta),l_t(w;\xi) lref(w;ζ),lt(w;ξ)。
5.2 MEGA-II
MEGA-I混合梯度的大小取决于当前梯度和情景相关梯度,以及当前任务和情景记忆的损失。而MEGA-II的混合梯度失守到了A- GEM的启发,由当前梯度的旋转得到,其大小仅取决于当前梯度。
MEGA-II的关键思想时首先对当前任务计算的随机梯度进行适当的旋转,通过一个角度 θ k t \theta^t_k θkt。然后将旋转后的矢量作为混合随机梯度,对每个小批量进行更新。
我们使用 g m i x g_{mix} gmix来表示期望的混合随机梯度,其大小与 ∇ l t ( w ; ξ ) \nabla l_t(w;\xi) ∇lt(w;ξ)一样。我们寻找方向符合 ∇ l t ( w ; ξ ) , ∇ l r e f ( w ; ζ ) \nabla l_t(w;\xi),\nabla l_{ref}(w;\zeta) ∇lt(w;ξ),∇lref(w;ζ)。与MEGA-I类似,我们使用损失平衡方案并希望使其最大化:
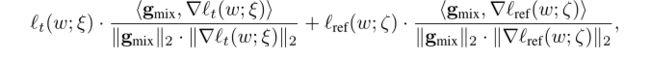
去找如下的 θ \theta θ:
θ = a r g max β ∈ [ 0 , π ] l t ( w ; ξ ) c o s ( β ) + l r e f ( w ; ξ ) c o s ( θ ~ − β ) \theta = arg\max_{\beta\in[0,\pi]}l_t(w;\xi)cos(\beta)+l_{ref}(w;\xi)cos(\tilde{\theta}-\beta) θ=argβ∈[0,π]maxlt(w;ξ)cos(β)+lref(w;ξ)cos(θ~−β)
其中 θ ~ ∈ [ 0 , π ] \tilde{\theta}\in[0,\pi] θ~∈[0,π]为在 ∇ l t ( w ; ξ ) \nabla l_t(w;\xi) ∇lt(w;ξ)到 ∇ l r e f ( w ; ζ ) \nabla l_{ref}(w;\zeta) ∇lref(w;ζ)之间的角度, β ∈ [ 0 , π ] \beta\in[0,\pi] β∈[0,π]为在 g m i x g_{mix} gmix和 ∇ l t ( w ; ξ ) \nabla l_t(w;\xi) ∇lt(w;ξ)之间的角度。其中 θ \theta θ的闭合形式为 θ = π 2 − α \theta = \frac{\pi}{2}-\alpha θ=2π−α,其中 α = a r c t a n ( k + c o s θ ~ s i n θ ~ ) , k = l t ( w ; ξ ) / l r e f ( w ; ζ ) \alpha = arctan(\frac{k+cos\tilde{\theta}}{sin\tilde{\theta}}),k=l_t(w;\xi)/l_{ref}(w;\zeta) α=arctan(sinθ~k+cosθ~),k=lt(w;ξ)/lref(w;ζ)。
-
这里讨论一下一些特殊的情况
- 当 l r e f ( w ; ζ ) = 0 l_{ref}(w;\zeta)=0 lref(w;ζ)=0,此时 θ = 0 \theta =0 θ=0,在这种情况下 α 1 ( w ) = 1 , α 2 ( w ) = 0 \alpha_1(w)=1,\alpha_2(w)=0 α1(w)=1,α2(w)=0。此时表示无遗忘,因此直接进行新任务学习。
- 当 l t ( w ; ξ ) = 0 l_{t}(w;\xi)=0 lt(w;ξ)=0,此时 θ = θ ~ \theta =\tilde{\theta} θ=θ~,在这种情况下 α 1 ( w ) = 0 \alpha_1(w)=0 α1(w)=0, α 2 ( w ) = ∣ ∣ ∇ l t ( w ; ξ ) ∣ ∣ 2 / ∣ ∣ ∇ l r e f ( w ; ζ ) ∣ ∣ 2 \alpha_2(w) = ||\nabla l_t(w;\xi)||_2/||\nabla l_{ref}(w;\zeta)||_2 α2(w)=∣∣∇lt(w;ξ)∣∣2/∣∣∇lref(w;ζ)∣∣2。这种情况下,混合随机梯度的方向和情景记忆中根据数据计算出来的随机梯度方向相同。
六.关键代码解读
代码点这里
作者的代码写的很复杂,将多种终身学习方法都融入了进去,而本文作者提出的算法主要是针对GEM和A-GEM中的 α 1 ( w ) \alpha_1(w) α1(w)和 α 2 ( w ) \alpha_2(w) α2(w)进行改动的,因此代码部分只针对这部分进行说明,而GEM部分我会用其他代码配合论文再进行讲解。MEGA-II可以说是MEGA-I的更加适用性的版本,我们针对次进行说明。
首先,明确参数,根据上文当我们模型进行反向传播后,我们可以获取到 ∇ l t ( w ; ξ ) \nabla l_t(w;\xi) ∇lt(w;ξ)和 ∇ l r e f ( w ; ζ ) \nabla l_{ref}(w;\zeta) ∇lref(w;ζ),为了方便书写,分别记为 g t g_t gt和 g r g_r gr(对应的损失记作 l t , l r l_t,l_r lt,lr)。再MEGA-II中, θ ~ \tilde{\theta} θ~为 g t g_t gt和 g r g_r gr之间的角度:
θ ~ = a r c c o s ( g t ∗ g r ∣ ∣ g t ∣ ∣ 2 ∗ ∣ ∣ g r ∣ ∣ 2 ) \tilde{\theta}=arccos(\frac{g_t*g_r}{||g_t||_2*||g_r||_2}) θ~=arccos(∣∣gt∣∣2∗∣∣gr∣∣2gt∗gr)
对应的代码如下:
## 将两个向量距离相乘
self.deno1 = (tf.norm(flat_task_grads) * tf.norm(flat_ref_grads))
## 两个向量相乘
self.num1 = tf.reduce_sum(tf.multiply(flat_task_grads, flat_ref_grads))
## 求角度
self.angle_tilda = tf.acos(self.num1/self.deno1)
之后有了 θ ~ \tilde{\theta} θ~之后,我们可以更新 θ \theta θ了,这里用一次梯度进行更新。
设 k = l r l t k = \frac{l_r}{l_t} k=ltlr,我们求解 θ \theta θ的公式变为:
θ = a r g max β [ c o s ( β ) + k ∗ c o s ( θ ~ − β ) ] \theta = arg\max_{\beta}[cos(\beta)+k*cos(\tilde{\theta}-\beta)] θ=argβmax[cos(β)+k∗cos(θ~−β)]
进行梯度更新(由于时求argmax因此用的+号)
θ = θ + [ − s i n ( θ ) + k ∗ s i n ( θ ~ − θ ) ] \theta=\theta+[-sin(\theta)+k*sin(\tilde{\theta}-\theta)] θ=θ+[−sin(θ)+k∗sin(θ~−θ)]
θ \theta θ的范围为 [ 0 , π 2 ] [0,\frac{\pi}{2}] [0,2π](这里作者给了证明)

因此我们更新后还要防止溢出。
对应的代码为:
def loop(steps, theta):
## \theta的计算,值得注意的是,作者前面还*上了个1/(1+k),这里的self.ratio对应的就是k
theta = theta + (1 / (1+self.ratio)) * (-tf.sin(theta) + self.ratio * tf.sin(self.angle_tilda - theta))
## 防止超过范围
theta = tf.cond(tf.greater_equal(theta, 0.5*pi), lambda: tf.identity(0.5*pi), lambda: tf.identity(theta))
theta = tf.cond(tf.less_equal(theta, 0.0), lambda: tf.identity(0.0), lambda: tf.identity(theta))
steps = tf.add(steps, 1)
作者这里进行了多次的求解 θ \theta θ,为:
for idx in range(3):
steps = tf.constant(0.0)
_, thetas[idx] = tf.while_loop(
condition,
loop,
[steps, thetas[idx]]
)
objectives[idx] = self.old_task_loss * tf.cos(thetas[idx]) + self.ref_loss * tf.cos(self.angle_tilda - thetas[idx])
objectives = tf.convert_to_tensor(objectives)
max_idx = tf.argmax(objectives)
self.theta = tf.gather(thetas, max_idx)
最后就是根据 θ \theta θ求解 α 1 \alpha_1 α1和 α 2 \alpha_2 α2了,这里作者也给出了求解方式:

也就是联立方程求解a和b即可,对应的代码如下:
tr = tf.reduce_sum(tf.multiply(flat_task_grads, flat_ref_grads))
tt = tf.reduce_sum(tf.multiply(flat_task_grads, flat_task_grads))
rr = tf.reduce_sum(tf.multiply(flat_ref_grads, flat_ref_grads))
def compute_g_tilda(tr, tt, rr, flat_task_grads, flat_ref_grads):
a = (rr * tt * tf.cos(self.theta) - tr * tf.norm(flat_task_grads) * tf.norm(flat_ref_grads) * tf.cos(self.angle_tilda-self.theta)) / self.deno
b = (-tr * tt * tf.cos(self.theta) + tt * tf.norm(flat_task_grads) * tf.norm(flat_ref_grads) * tf.cos(self.angle_tilda-self.theta)) / self.deno
return a * flat_task_grads + b * flat_ref_grads
self.deno = tt * rr - tr * tr
g_tilda = tf.cond(tf.less_equal(self.deno, 1e-10), lambda: tf.identity(flat_task_grads), lambda: compute_g_tilda(tr, tt, rr, flat_task_grads, flat_ref_grads))
到这里关于MEGA-II也就完成了,作者结合A-GEM利用旋转角度平衡了旧任务损失和新任务损失,还是可以借鉴的。