峰回路转?贾跃亭重组班底拿融资;插画师的噩梦:AI能根据故事文本画图了;批量图片转文字;机器学习数据工程实战教程;前沿论文 | ShowMeAI资讯日报

日报合辑 | 电子月刊 | 公众号下载资料 | @韩信子
贾跃亭率合伙人重组FF董事会,再成功获得1亿美元融资
https://www.faradayfuturecn.com/cn/
Faraday Future(法拉第未来,简称 FF)9月26日晚间发布公告,宣布与公司大股东FF Top(FF全球合伙人公司)达成协议,包含FF Top同意立即撤回对FF董事会的诉讼、调整FF董事会成员和董事会规模等内容。经历了破产重整、上市融资、管理层和大股东内部纷争之后,贾跃亭与合伙人团队重新赢得 FF 控制权。
与此同时FF宣布获得来自Daguan和ATW超过1亿美元融资。毫无疑问,这一系列关键融资不仅为FF 91 Futurist的量产交付提供充足的资金保障,还说明FF创始人贾跃亭再次获得了国际资本市场信任与支持。
工具&框架
『Long Stable Diffusion』长文本图像生成
https://github.com/sharonzhou/long_stable_diffusion
Long Stable Diffusion 是一个专注长文本图像生成的项目实现。当前的 Stable Diffusion 模型只能接受短提示来作图,如果你有长文本(甚至描述了一个故事),你可以借助 Long Stable Diffusion 来完成这个场景下的多图像生成。
『Umi-OCR』批量图片转文字工具
https://github.com/hiroi-sora/Umi-OCR
适用于 Win10 x64 平台的离线 OCR 软件。可以批量导入本地图片或者读取剪贴板,识别图片中的文本,并输出 .txt 文件或者 .md 文件。具备开源、方便、高效、精准等诸多优点,可排除图片中水印区域的干扰,提取干净的文本。
『SynapseML』轻量大规模可扩展分布式机器学习库
https://github.com/microsoft/SynapseML
https://microsoft.github.io/SynapseML/
SynapseML(以前称为MMLSpark)是一个开源库,它简化了大规模可扩展机器学习(ML)管道的创建。SynapseML为各种不同的机器学习任务(如文本分析、视觉、异常检测等)提供简单、可组合和分布式的API。
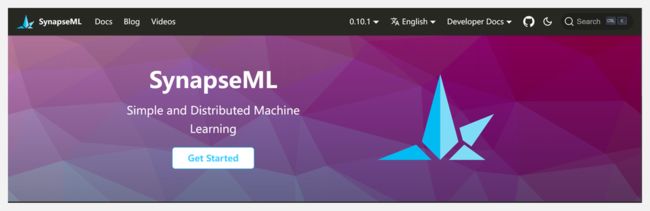
SynapseML建立在Apache Spark分布式计算框架上,与SparkML/MLLib库共享相同的API,你可以轻松将SynapseML模型无缝嵌入到现有的Apache Spark工作流中。SynapseML可以帮你构建可扩展的智能系统,解决异常检测、计算机视觉、深度学习、文本分析等领域的挑战,支持Python、R、Scala、Java和.NET等编程语言。

『Cuby Text』开源个人知识管理应用
https://github.com/vincentdchan/CubyText
许多优秀的知识管理应用程序是基于扩展的 Markdown 文件,虽然很强大但没有表现力。因此,很多新的笔记软件产品使用块『Blocks』来组织内容。受此启发,作者创建了 CubyText,在实现功能的同时保护隐私和原生体验,速度快并且可扩展。
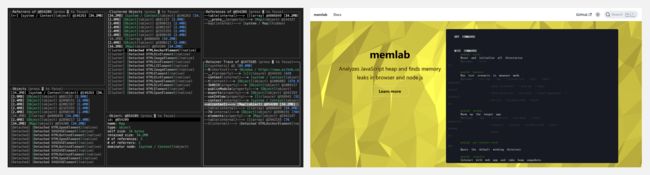
『memlab』E2E测试和分析框架
https://github.com/facebookincubator/memlab
https://facebookincubator.github.io/memlab/
memlab是一个E2E测试和分析框架,用于检查JavaScript的内存泄漏和优化。它具备以下特点:
- 浏览器内存泄露检测
- 面向对象的堆遍历API
- 内存CLI工具箱 - 内置工具箱和API
- Node.js中的内存断言
博文&分享
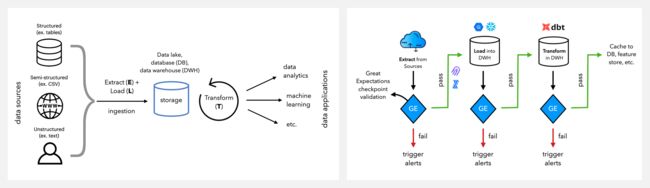
『Data Engineering for Machine Learning』机器学习数据工程实战
https://github.com/GokuMohandas/data-engineering
Repo 是 MLOPs 教程 的一部分,旨在构建数据分析和机器学习应用的数据堆栈,帮助学习数据工程的基础知识。本项目涉及的『Data stack(数据堆栈)』和『Orchestration(编排工具)』两部分,将学习如何编排我们的数据工作流程并以编程方式执行任务,以便为下游消费者(分析、ML 等)准备高质量的数据。

Data stack
https://madewithml.com/courses/mlops/data-stack/
- Set up
- Extract via Airbyte
- Load into BigQuery
- Transform via dbt-cloud
- Applications
Orchestration
https://madewithml.com/courses/mlops/orchestration/
- Set up Airflow
- Extract and load
- Validate via GE
- Transform via dbt-core
数据&资源
『Awesome Panel Lightning』Panel+Lightning.ai 构建机器学习&深度学习应用程序
https://github.com/MarcSkovMadsen/awesome-panel-lightning
Repo 将 Panel 和 Lightning.ai 结合起来,构建、扩展和部署强大的机器学习和深度学习数据应用程序。

『System Design Questions』系统设计问题集
https://github.com/relogX/system-design-questions
资源库包含了 Arpit 的『系统设计大师班』所进行的围绕软件架构和系统设计的一系列问题陈述。
- Design a Blogging Platform
- Design Online Offline Indicator
- Design Airline Check-in
- Design SQL backed KV Store
- Design Slack’s Realtime Communication - NEW
- Design a Load Balancer
- Design Synchronized Queue Consumers
- Design an Image Service
- Design a HashTag Service
- Design OnePic
- Design Photo Tagging
- Design User Affinity
- Design Newly Unread Message Indicator
- Design a Distributed Cache
- Design a Word Dictionary
- Design a Superfast KV Store
- Design S3
- Design a Faster Superfast KV Store
- Design a Video Processing Pipeline for Steaming Service
- Design a Text-based Search Engine
- Design a service that serves Recent Searches for a user
- Design a Text-based Cricket Commentary Service
- Design a SQL backed Message Broker
- Design a Distributed Task Scheduler
- Design Flash Sale
- Design Counting Impressions at Scale
- Designing a Remote File Sync Service
- Designing a “who’s near me” Service
研究&论文

可以点击 这里 回复关键字 日报,免费获取整理好的论文合辑。
科研进展
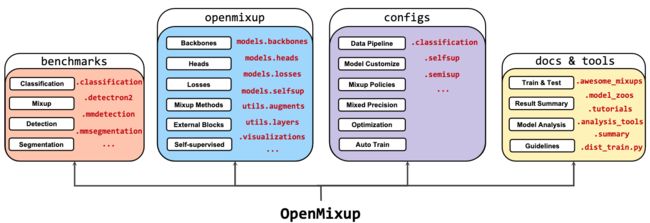
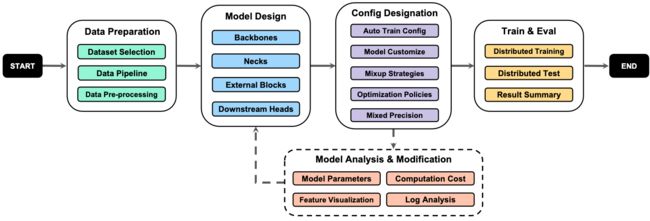
- 2022.09.11 『图像分类』 OpenMixup: Open Mixup Toolbox and Benchmark for Visual Representation Learning
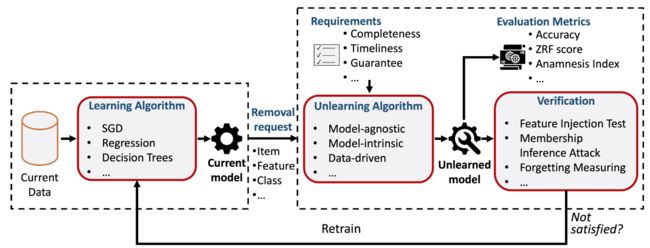
- 2022.09.06 『机器学习』 A Survey of Machine Unlearning
- 2022.09.13 『深度预估』 A Benchmark and a Baseline for Robust Multi-view Depth Estimation
⚡ 论文:OpenMixup: Open Mixup Toolbox and Benchmark for Visual Representation Learning
论文时间:11 Sep 2022
领域任务:Image Classification, Representation Learning, 图像分类,表征学习
论文地址:https://arxiv.org/abs/2209.04851
代码实现:https://github.com/Westlake-AI/openmixup
论文作者:Siyuan Li, Zedong Wang, Zicheng Liu, Di wu, Stan Z. Li
论文简介:With the remarkable progress of deep neural networks in computer vision, data mixing augmentation techniques are widely studied to alleviate problems of degraded generalization when the amount of training data is limited./随着计算机视觉中深度神经网络的显著进步,数据混合增强技术被广泛研究,以缓解训练数据量有限时泛化能力下降的问题。
论文摘要:随着计算机视觉中深度神经网络的显著进步,数据混合增强技术被广泛研究,以缓解训练数据量有限时泛化能力下降的问题。然而,在目前的视觉工具箱中,混合策略还没有被很好地组装起来。在本文中,我们提出了OpenMixup,一个开源的一体化工具箱,用于监督、半监督和自监督的视觉表示学习与混合。它提供了一个集成的模型设计和训练平台,包括一套丰富的主流网络架构和模块、一组数据混合增强方法以及实用的模型分析工具。此外,我们还在各种数据集上提供了标准的混合图像分类基准,这加快了从业人员在相同设置下对最先进的方法进行公平的比较。源代码和用户文件可在 https://github.com/Westlake-AI/openmixup 上获取。
⚡ 论文:A Survey of Machine Unlearning
论文时间:6 Sep 2022
领域任务:Machine Learning, Artificial Intelligence, 机器学习,人工智能
论文地址:https://arxiv.org/abs/2209.02299
代码实现:https://github.com/tamlhp/awesome-machine-unlearning
论文作者:Thanh Tam Nguyen, Thanh Trung Huynh, Phi Le Nguyen, Alan Wee-Chung Liew, Hongzhi Yin, Quoc Viet Hung Nguyen
论文简介:Recent regulations require that private information about a user can be removed from computer systems in general and from ML models in particular upon request (e. g. the “right to be forgotten”)./最近的法规要求,关于用户的私人信息可以根据要求从一般的计算机系统,特别是ML模型中删除(例如,“被遗忘的权利”)。
论文摘要:计算机系统在数十年间拥有大量的个人数据。一方面,这种数据的丰富性使得人工智能(AI),特别是机器学习(ML)模型取得了突破。另一方面,它可能威胁到用户的隐私,并削弱人类和人工智能之间的信任。最近的法规要求,关于用户的私人信息可以根据要求从一般的计算机系统,特别是ML模型中删除(例如,“被遗忘的权利”)。虽然从后端数据库中删除数据应该是直接的,但在人工智能方面是不够的,因为ML模型经常 "记住 "旧数据。现有的对抗性攻击证明,我们可以从训练的模型中学习训练数据的私人成员或属性。这种现象需要一种新的范式,即机器解除学习,以使ML模型忘记特定的数据。事实证明,由于缺乏通用的框架和资源,最近关于机器解除学习的工作并没有能够完全解决这个问题。在这篇调查报告中,我们试图对机器学习的定义、场景、机制和应用进行彻底调查。具体来说,作为对最先进的研究的分类收集,我们希望为那些寻求机器解除学习的入门知识的人提供一个广泛的参考,以及它的各种表述、设计要求、清除要求、算法和在各种ML应用中的使用。此外,我们希望概述该范式的关键发现和趋势,并强调尚未看到机器学习应用的新研究领域,但仍可从中获益匪浅。我们希望这项调查为ML研究人员以及那些寻求隐私技术革新的人提供有价值的参考。我们的资源可以在 https://github.com/tamlhp/awesome-machine-unlearning 获取。
⚡ 论文:A Benchmark and a Baseline for Robust Multi-view Depth Estimation
论文时间:13 Sep 2022
领域任务:Depth Estimation,深度预估
论文地址:https://arxiv.org/abs/2209.06681
代码实现:https://github.com/lmb-freiburg/robustmvd
论文作者:Philipp Schröppel, Jan Bechtold, Artemij Amiranashvili, Thomas Brox
论文简介:We show that recent approaches do not generalize across datasets in this setting./我们表明,最近的方法在这种情况下并不具有跨数据集的普遍性。
论文摘要:最近用于多视角深度估计的深度学习方法被用于从视频中获取深度或多视角立体设置中。尽管设置不同,这些方法在技术上是相似的:它们将多个源视图与一个关键视图相关联,以估计关键视图的深度图。在这项工作中,我们介绍了Robust Multi-View Depth Benchmark,它建立在一组公共数据集上,并允许在这两种设置下对来自不同领域的数据进行评估。我们评估了最近的方法,发现各领域的表现不平衡。此外,我们还考虑了第三种情况,在这种情况下,摄像机的姿势是可用的,目标是以正确的比例估计相应的深度图。我们表明,在这种情况下,最近的方法在不同的数据集上并不通用。这是因为他们的成本量输出跑出了分布。为了解决这个问题,我们提出了用于多视图深度估计的Robust MVD Baseline模型,它建立在现有的组件上,但采用了一个新的尺度增强程序。它可以应用于稳健的多视图深度估计,不受目标数据的影响。我们提供了拟议的基准和基线模型的代码,可以在 https://github.com/lmb-freiburg/robustmvd 查看。
我们是 ShowMeAI,致力于传播AI优质内容,分享行业解决方案,用知识加速每一次技术成长!
◉ 点击 日报合辑,在公众号内订阅话题 #ShowMeAI资讯日报,可接收每日最新推送。
◉ 点击 电子月刊,快速浏览月度合辑。
◉ 点击 这里 ,回复关键字 日报 免费获取AI电子月刊与论文 / 电子书等资料包。
