CharTextCNN:使用字符级别的卷积神经网络来做文本分类任务
文章目录
- 文章目录
- 论文《**Character-level Convolutional Networks for Text Classification**》
- 论文总览
- 学习目标
- 第一课:论文导读
-
- 卷积神经网络的发展
- 论文背景
- 研究成果及意义
-
- 研究成果
- 研究意义
- 第二课:论文精读
-
- 摘要
- CharTextCNN模型
-
- 卷积神经网络公式
- CharTextCNN Model
- 实验结果分析
- 论文总结
- 代码实现
文章目录
论文《Character-level Convolutional Networks for Text Classification》
论文总览
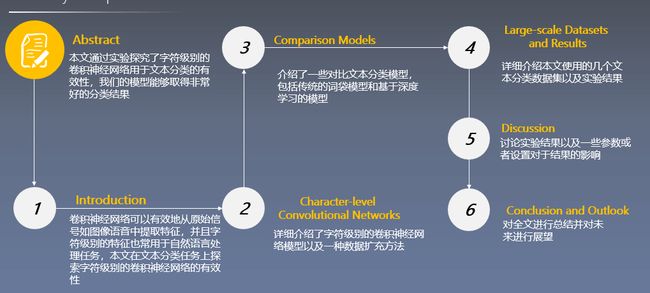
学习目标
第一课:论文导读
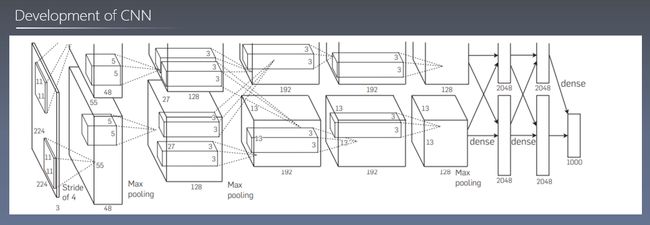
卷积神经网络的发展
卷积神经网络用于图像特征提取
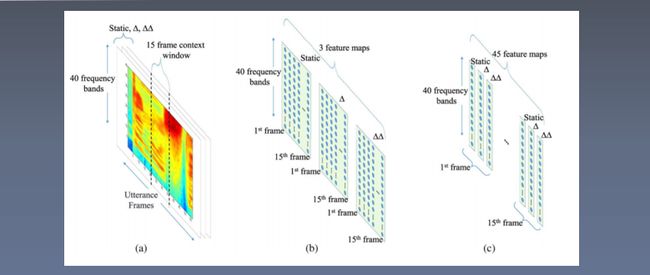
卷积神经网络用于声音特征提取
卷积神经网络用于文本特征提取
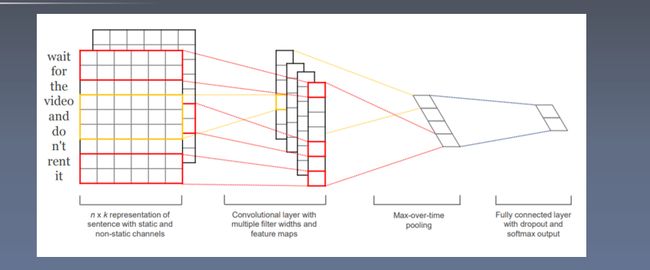
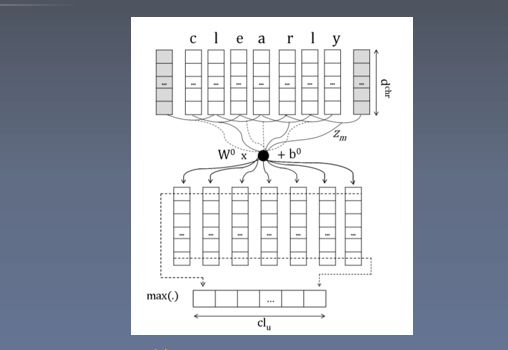
字符信息用于生成词表示
论文背景
- 文本分类是自然语言处理的基础任务之一,目前大多数文本分类任务都是基于词的。
- 卷积神经网络能够成功提取出原始信息中的特征,如图像和语音,于是本文在字符级别的数据上使用卷积神经网络来提取特征。
- 在文本上使用卷积神经网络已经很常见了,而且使用字符级别的特征来提高自然语言处理任务的性能也有很多研究。
- 本文首次使用纯字符级别的卷积神经网络,我们发现我们的卷积神经网络不需要单词级别的信息就能够在大规模预料上得到很好的结果。
研究成果及意义
研究成果
- 构造了几个大的文本分类数据集,这些数据集成为了文本分类最常用的一些数据集。
- 提出的CharTextCnn模型在多个数据集上能够取得最好的或者非常有竞争力的结果。
研究意义
- 构建了多个文本分类数据集,极大地推动了文本分类的研究工作。
- 提出的CharTextCNN方法因为只使用的字符信息,所以可以用于多种语言中。

第二课:论文精读
摘要
- 本文从实验角度探索了字符级别卷积神经网络用于文本分类的有效性。
- 我们构造了几个大规模的文本分类数据集,实验结果表明我们的字符级别文本分类模型能够取得最好的或者非常有竞争力的结果。
- 对比模型包括传统的词袋模型、n-grams模型以及他们的tf-idf变体,还有一些基于深度学习的模型,包括基于卷积神经网络和循环神经网络的文本分类模型。
CharTextCNN模型
卷积神经网络公式
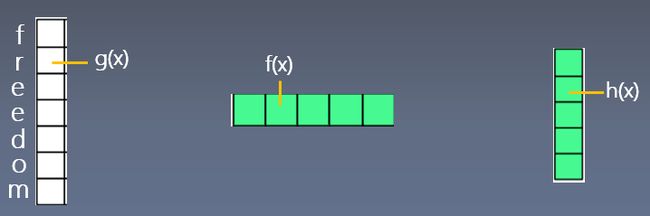
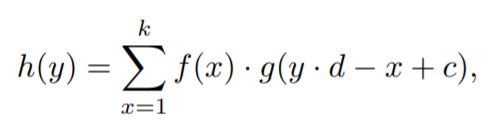
CharTextCNN Model
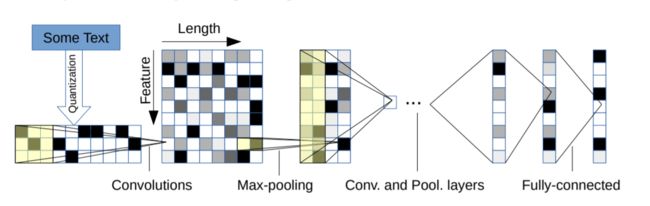
缺点 :
- 字符级别的文本长度特别长, 不利于处理长文本的分类。
- 只使用字符级别信息, 所以模型学习到的语义方面的信息较少
- 在小语料上效果较差
优点 :
- 模型结构简单,并且在大语料上效果很好。
- 可以用于各种语言, 不需要做分词处理。
- 在噪音比较多文本上表现较好,因为基本不存在OOV问题。
实验结果分析
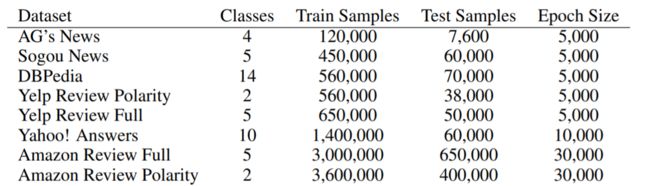
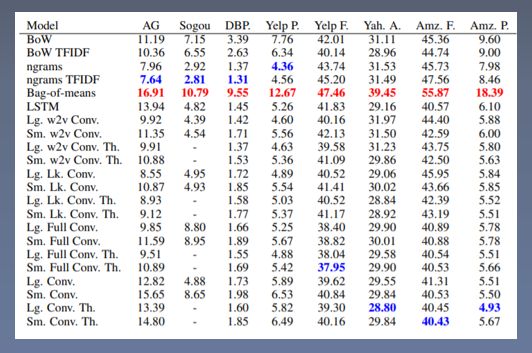
数据集介绍
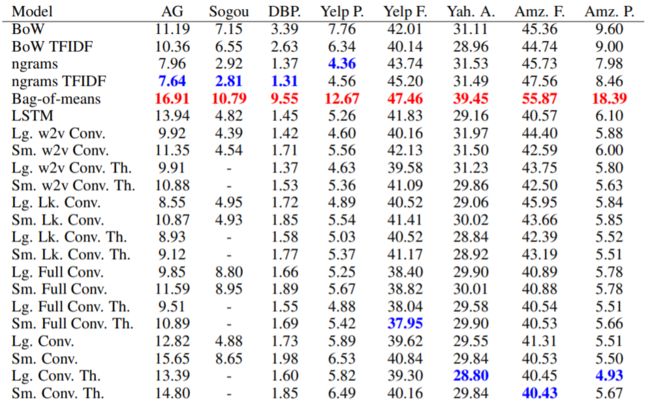
和多种对比模型在多个数据集上的效果对比。
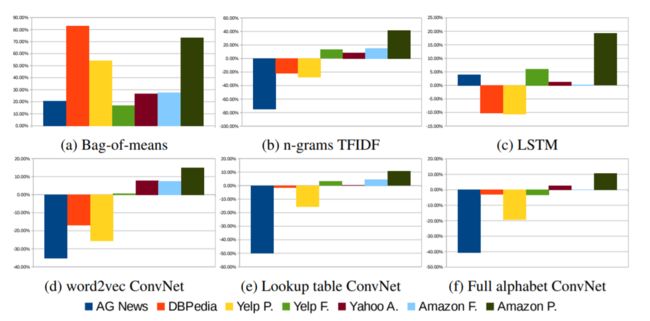
和对比模型的相对错误率比较
论文总结
关键点 :
- 卷积神经网络能够有效地提取关键的特征
- 字符级别的特征对于自然语言处理的有效性
- CharTextCNN模型
创新点 :
- 提出了一种新的文本分类模型—CharTextCNN
- 提出了多个的大规模的文本分类数据集
- 在多个文本分类数据集上取得最好或者非常有竞争力的结果
启发点 :
-
基于卷积神经网络的文本分类不需要语言的语法和语义结构的知识。
ConvNets do not require the knowledge about the syntactic or semantic structure of a language(Introduction P6)
-
实验结果告诉我们没有一个机器学习模型能够在各种数据集上都能表现的很好。
Our experiments once again verifies that there is not a single machine learning model that can work for all kinds of datasets(5 Discussion P8)
- 本文从实验的角度分析了字符级别卷积神经网络在文本分类任务上的适用性。
This article offers an empirical study on character-level convolutional networks for text classification. (6 Conclusion and Outlook P1)
代码实现
数据预处理:
#coding:utf-8
from torch.utils import data
import os
import torch
import json
import csv
import numpy as np
class AG_Data(data.DataLoader):
def __init__(self,data_path,l0 = 1014):
self.path = os.path.abspath('.')
if "data" not in self.path:
self.path += "/data"
self.data_path = data_path
self.l0 = l0
self.load_Alphabet()
self.load(self.data_path)
def __getitem__(self, idx):
X = self.oneHotEncode(idx)
y = self.y[idx]
return X, y
def __len__(self):
return len(self.label)
def load_Alphabet(self):
with open(self.path+"/alphabet.json") as f:
self.alphabet = "".join(json.load(f))
def load(self,data_path,lowercase=True):
self.label = []
self.data = []
with open(self.path+data_path,"r") as f:
datas = list(csv.reader(f,delimiter=',', quotechar='"'))
for row in datas:
self.label.append(int(row[0])-1)
txt = " ".join(row[1:])
if lowercase:
txt = txt.lower()
self.data.append(txt)
self.y = self.label
def oneHotEncode(self,idx):
X = np.zeros([len(self.alphabet),self.l0]) # torch的1d卷积和1d的池化; batch_size*feature*length
for index_char, char in enumerate(self.data[idx][::-1]):
if self.char2Index(char)!=-1:
X[self.char2Index(char)][index_char] = 1.0
return X
def char2Index(self,char):
return self.alphabet.find(char)
模型的构建
# -*- coding: utf-8 -*-
import torch
import torch.nn as nn
import torch.nn.functional as F
class CharTextCNN(nn.Module):
def __init__(self,config):
super(CharTextCNN, self).__init__()
in_features = [config.char_num] + config.features[0:-1]
out_features = config.features
kernel_sizes = config.kernel_sizes
self.convs = []
self.conv1 = nn.Sequential(
nn.Conv1d(in_features[0], out_features[0], kernel_size=kernel_sizes[0], stride=1),
nn.BatchNorm1d(out_features[0]),
nn.ReLU(),
nn.MaxPool1d(kernel_size=3, stride=3)
)
self.conv2 = nn.Sequential(
nn.Conv1d(in_features[1], out_features[1], kernel_size=kernel_sizes[1], stride=1),
nn.BatchNorm1d(out_features[0]),
nn.ReLU(),
nn.MaxPool1d(kernel_size=3, stride=3)
)
self.conv3 = nn.Sequential(
nn.Conv1d(in_features[2], out_features[2], kernel_size=kernel_sizes[2], stride=1),
nn.BatchNorm1d(out_features[2]),
nn.ReLU()
)
self.conv4 = nn.Sequential(
nn.Conv1d(in_features[3], out_features[3], kernel_size=kernel_sizes[3], stride=1),
nn.BatchNorm1d(out_features[3]),
nn.ReLU()
)
self.conv5 = nn.Sequential(
nn.Conv1d(in_features[4], out_features[4], kernel_size=kernel_sizes[4], stride=1),
nn.BatchNorm1d(out_features[4]),
nn.ReLU()
)
self.conv6 = nn.Sequential(
nn.Conv1d(in_features[5], out_features[5], kernel_size=kernel_sizes[5], stride=1),
nn.BatchNorm1d(out_features[5]),
nn.ReLU(),
nn.MaxPool1d(kernel_size=3, stride=3)
)
self.fc1 = nn.Sequential(
nn.Linear(8704, 1024),
nn.ReLU(),
nn.Dropout(p=config.dropout)
)
self.fc2 = nn.Sequential(
nn.Linear(1024, 1024),
nn.ReLU(),
nn.Dropout(p=config.dropout)
)
self.fc3 = nn.Linear(1024, config.num_classes)
def forward(self, x):
x = self.conv1(x)
x = self.conv2(x)
x = self.conv3(x)
x = self.conv4(x)
x = self.conv5(x)
x = self.conv6(x)
x = x.view(x.size(0), -1)
x = self.fc1(x)
x = self.fc2(x)
x = self.fc3(x)
return x
参数设置
# —*- coding: utf-8 -*-
import argparse
def ArgumentParser():
parser = argparse.ArgumentParser()
parser.add_argument("--epoch",type=int,default=200,help="epoch of training")
parser.add_argument("--cuda",type=bool,default=True,help="whether use gpu")
parser.add_argument("--gpu",type=int,default=0,help="whether use gpu")
parser.add_argument("--label_num",type=int,default=4,help="the label number of samples")
parser.add_argument("--learning_rate",type=float,default=0.0001,help="learning rate during training")
parser.add_argument("--batch_size",type=int,default=50,help="batch size during training")
parser.add_argument("--char_num",type=int,default=70,help="character number of samples")
parser.add_argument("--features",type=str,default="256,256,256,256,256,256",help="filters size of conv")
parser.add_argument("--kernel_sizes",type=str,default="7,7,3,3,3,3",help="kernel size of conv")
parser.add_argument("--pooling",type=str,default="1,1,0,0,0,1",help="is use pooling of convs")
parser.add_argument("--l0",type=int,default="1014",help="length of character sentence")
parser.add_argument("--dropout",type=float,default=0.5,help="dropout of training")
parser.add_argument("--num_classes",type=int,default=4,help="number classes of data")
parser.add_argument("--seed",type=int,default=1,help="seed of random")
return parser.parse_args()
主函数:
# -*- coding: utf-8 -*-
import torch
import torch.autograd as autograd
import torch.nn as nn
import torch.optim as optim
from model import CharTextCNN
from data import AG_Data
from tqdm import tqdm
import numpy as np
import config as argumentparser
config = argumentparser.ArgumentParser()
config.features = list(map(int,config.features.split(",")))
config.kernel_sizes = list(map(int,config.kernel_sizes.split(",")))
config.pooling = list(map(int,config.pooling.split(",")))
if config.gpu and torch.cuda.is_available():
torch.cuda.set_device(config.gpu)
def get_test_result(data_iter,data_set):
# 生成测试结果
model.eval()
data_loss = 0
true_sample_num = 0
for data, label in data_iter:
if config.cuda and torch.cuda.is_available():
data = data.cuda()
label = label.cuda()
else:
data = torch.autograd.Variable(data).float()
out = model(data)
loss = criterion(out, autograd.Variable(label.long()))
data_loss += loss.data.item()
true_sample_num += np.sum((torch.argmax(out, 1) == label).cpu().numpy())
acc = true_sample_num / data_set.__len__()
return data_loss,acc
training_set = AG_Data(data_path="/AG/train.csv",l0=config.l0)
training_iter = torch.utils.data.DataLoader(dataset=training_set,
batch_size=config.batch_size,
shuffle=True,
num_workers=0)
test_set = AG_Data(data_path="/AG/test.csv",l0=config.l0)
test_iter = torch.utils.data.DataLoader(dataset=test_set,
batch_size=config.batch_size,
shuffle=False,
num_workers=0)
model = CharTextCNN(config)
if config.cuda and torch.cuda.is_available():
model.cuda()
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=config.learning_rate)
loss = -1
for epoch in range(config.epoch):
model.train()
process_bar = tqdm(training_iter)
for data, label in process_bar:
if config.cuda and torch.cuda.is_available():
data = data.cuda()
label = label.cuda()
else:
data = torch.autograd.Variable(data).float()
label = torch.autograd.Variable(label).squeeze()
out = model(data)
loss_now = criterion(out, autograd.Variable(label.long()))
if loss == -1:
loss = loss_now.data.item()
else:
loss = 0.95*loss+0.05*loss_now.data.item()
process_bar.set_postfix(loss=loss_now.data.item())
process_bar.update()
optimizer.zero_grad()
loss_now.backward()
optimizer.step()
test_loss, test_acc = get_test_result(test_iter, test_set)
print("The test acc is: %.5f" % test_acc)
数据集的下载地址:AG News: https://s3.amazonaws.com/fast-ai-nlp/ag_news_csv.tgz