【GAT】如何理解Graph Attention Network(注意力机制)?

论文链接:Graph Attention Networks
Github链接:https://github.com/PetarV-/GAT
1 GAT的背景

2 GAT的主要结构

3 GAT的创新点是什么?
先介绍GCN的局限性,然后介绍GAT的创新点。
GAT的局限性
-
GCN 无法完成inductive任务(unseen node in test)
-
GCN 无法分配不同的学习权重给不同的neighbor
-
对于一个图结构训练好的模型,不能运用于另一个图结构(所以此文称自己为半监督的方法)
GAT的创新点
- 引入masked self-attentional layers 来改进 GCN 无法分配不同的学习权重给不同的neighbor的缺点
- 对不同的相邻节点分配相应的权重,既不需要矩阵运算,也不需要事先知道图结构
- 四个数据集上达到state-of-the-art的准确率Cora、Citeseer、Pubmed、protein interaction
4 masked self-attentional layers
4.1 Attention Mechanism
神经网络中的注意力机制(Attention Mechanism)是在计算能力有限的情况下,将计算资源分配给更重要的任务,同时解决信息超载问题的一种资源分配方案。这就类似于人类的视觉注意力机制,通过扫描全局图像,获取需要重点关注的目标区域,而后对这一区域投入更多的注意力资源,获取更多与目标有关的细节信息,而忽视其他无关信息。
有关注意力机制的详细内容请参考:https://www.cnblogs.com/Luv-GEM/p/10712256.html、https://blog.csdn.net/hahajinbu/article/details/81940355
4.2 Self-attention Models
在一般任务的Encoder-Decoder框架中,输入Source和输出Target内容是不一样的,比如对于英-中机器翻译来说,Source是英文句子,Target是对应的翻译出的中文句子,Attention机制发生在Target的元素Query和Source中的所有元素之间。
而Self Attention顾名思义,指的不是Target和Source之间的Attention机制,而是Source内部元素之间或者Target内部元素之间发生的Attention机制,也可以理解为Target=Source这种特殊情况下的注意力计算机制。Self Attention可以捕获同一个句子中单词之间的一些句法特征 或者 语义特征。
有关自注意力模型的详细内容请参考:https://zhuanlan.zhihu.com/p/37601161
4.3 Masked的含义?
相当于盖住你当前关注的词的后面所有词,我只关心前面出现的词,而后面的词我不关注,因为我要生成后面的词。

有关Masked自注意力机制的详细内容请参考:https://zhuanlan.zhihu.com/p/94998435
4.4 multi-head attention机制
神似卷积神经网络里的多通道,GAT 引入了多头注意力来丰富模型的能力和稳定训练的过程。每一个注意力的头都有它自己的参数。如何整合多个注意力机制的输出结果一般有两种方式:
- 拼接
h i ( l + 1 ) = ∥ k = 1 , … , K σ ( ∑ j ∈ N ( i ) α i j k W k h j ( l ) ) (5) h_{i}^{(l+1)}=\|_{k=1, \ldots, K} \sigma\left(\sum_{j \in N(i)} \alpha_{i j}^{k} W^{k} h_{j}^{(l)}\right) \tag{5} hi(l+1)=∥k=1,…,Kσ⎝⎛j∈N(i)∑αijkWkhj(l)⎠⎞(5) - 平均
h i ( l + 1 ) = σ ( 1 k ∑ k = 1 K ∑ j ∈ N ( i ) α i j k W k h j ( l ) ) (6) h_{i}^{(l+1)}=\sigma\left(\frac{1}{k} \sum_{k=1}^{K} \sum_{j \in N(i)} \alpha_{i j}^{k} W^{k} h_{j}^{(l)}\right) \tag{6} hi(l+1)=σ⎝⎛k1k=1∑Kj∈N(i)∑αijkWkhj(l)⎠⎞(6)
4.5 Transformer Vs GAT
NLP中大火的Transformer和GAT本质在做一样的事情。Transformer利用self-attention机制将输入中的每个单词用其上下文的加权来表示,而GAT是利用self-attention机制将每个节点用其邻居的加权来表示。下面是经典的Transformer公式,
A t t e n t i o n ( Q , K , V ) = s o f t m a x ( Q K T d k ) Attention(Q,K,V) = softmax \left( \frac{QK^T}{\sqrt{d_k}} \right) Attention(Q,K,V)=softmax(dkQKT)
这里的 Q , K , V Q,K,V Q,K,V 是一个单词的三种描述, 其中, Q Q Q 是当单词作为上下文的中心位置时的表示, K K K 是当单词作为上下文时的表示, V V V 是当单词作为加权输入时的表示。
因此, Q K T QK^T QKT 其实代表了单词之间的相似性,在经过softmax归一化之后就可以得到注意力权重。有了注意力权重,我们再对上下文单词的表示进行加权,就可以得到单词的表示了。
上述过程和GAT的核心思想非常相似:都是通过探索输入之间的关联性(注意力权重),通过对上下文信息(句子上下文/节点邻居)进行聚合,来获得各个输入(单词/节点)的表示。
Transformer和GAT的主要区别是:
- 在GAT中,作者对自注意力进行了简化。每个节点无论是作为中心节点/上下文/聚合输出,都只用一种表示 h h h。也就是说,在GAT中, Q = K = V Q=K=V Q=K=V。
- 在图上,节点的邻居是一个集合,具有不变性。Transformer将文本隐式的建图过程中丢失了单词之间的位置关系,这对NLP的一些任务是很致命的。为了补偿这种建图损失的位置关系,Transformer用了额外了的位置编码来描述位置信息。
5 深入了解GAT
5.1 GAT的输入如何获得?
GAT的输入是节点的特征向量,可以通过随机初始化来得到初始节点向量。
5.2 GAT适合处理有向图?
GAT摒弃了拉普拉斯矩阵,进行逐点计算(node-wise)。
GCN使用拉普拉斯矩阵,并进行是逐层运算。
个人理解:只要在公式中没有使用拉普拉斯矩阵特征分解的方法都可以说适用于有向图,比如GraphSage和GAT,因此特征分解的充要条件只有对称矩阵才能满足,而有向图的拉普拉斯矩阵并不是对称矩阵。
5.3 inductive和transductive ?
GCN 本质是频域卷积,是一种全图的计算方式,一次卷积更新所有节点特征,计算过程涉及表征图结构的拉普拉斯矩阵,所以一旦出现了没有见过的图结构,拉普拉斯矩阵随之变化,以前训练好的基于原图结构的模型也就失效了——transductive(顶点的特征变了)
GAT 逐顶点运算方式,学习参数是 W W W 与 a ( ⋅ ) a(\cdot) a(⋅) 仅与顶点特征相关,与图的结构(邻接矩阵 A A A)毫无关系,所以可计算新图——inductive
训练的参数只有 a ( ⋅ ) a(\cdot) a(⋅) 和 W W W,无论节点个数如何变化,邻居节点间这两个参数是共享的,所以逐节点训练是可行的。
此处参考知乎:https://www.zhihu.com/question/409415383、https://zhuanlan.zhihu.com/p/74242097
5.4 共享参数W
GAT 共享参数 W W W 的线性映射对顶点特征增维,这个特征增维是数据维度的变换。
GCN中的矩阵乘法里的矩阵系数是待训练的卷积核参数 Θ \Theta Θ 和拉普拉斯矩阵 L L L 的共同表达,而 L L L 矩阵是一个表征图整体结构的矩阵,所以说它是一步卷积。
GCN逐层更新公式:输入节点矩阵 X ∈ R N × C X\in \mathbb{R}^{N\times C} X∈RN×C, 每个输入节点有 C C C个通道(channels, 即每个图节点有 C C C维特征),卷积操作包含 F F F个滤波器(filters)或特征映射(feature maps), 如下:
Y = σ ( D ~ − 1 2 A ~ D ~ − 1 2 X Θ ) Y=\sigma\left(\tilde{D}^{-\frac{1}{2}} \tilde{A} \tilde{D}^{-\frac{1}{2}} X \Theta\right) Y=σ(D~−21A~D~−21XΘ)
其中 Θ ∈ R C × F \Theta\in \mathbb{R}^{C\times F} Θ∈RC×F 是filters的参数矩阵, Y ∈ R N × F Y\in \mathbb{R}^{N\times F} Y∈RN×F 是卷积之后的节点矩阵。
而GAT中 L L L 不固定,是由注意力系数矩阵 A = ( a i j k ) n × n A = (a^{k}_{ij})_{n\times n} A=(aijk)n×n 组成,而 A A A 是逐点计算和整图结构关系不大,所以GAT训练的 W W W 可以在test时继续用。
W的维度并不受图的具体拓扑结构限制,只和你设置的hidden layer维度有关。
5.5 GAT核心公式
图注意力模型GAT用注意力机制替代了图卷积中固定的标准化操作。下图和公式定义了如何对第 l l l 层节点特征做更新得到第 l + 1 l+1 l+1 层节点特征:

z i ( l ) = W ( l ) h i ( l ) (1) z_{i}^{(l)}=\mathbf{W}^{(l)} h_{i}^{(l)} \tag{1} zi(l)=W(l)hi(l)(1)
e i j ( l ) = LeakyReLU ( a ⃗ ( l ) T ( z i ( l ) ∥ z j ( l ) ) ) (2) e_{i j}^{(l)}=\operatorname{LeakyReLU}\left(\vec{a}^{(l)^{T}}\left(z_{i}^{(l)} \| z_{j}^{(l)}\right)\right) \tag{2} eij(l)=LeakyReLU(a(l)T(zi(l)∥zj(l)))(2)
α i j ( l ) = exp ( e i j ( l ) ) ∑ k ∈ N ( i ) exp ( e i k ( l ) ) (3) \alpha_{i j}^{(l)}=\frac{\exp \left(e_{i j}^{(l)}\right)}{\sum_{k \in \mathcal{N}(i)} \exp \left(e_{i k}^{(l)}\right)} \tag{3} αij(l)=∑k∈N(i)exp(eik(l))exp(eij(l))(3)
h i ( l + 1 ) = σ ( ∑ j ∈ N ( i ) α i j ( l ) z j ( l ) ) (4) h_{i}^{(l+1)}=\sigma\left(\sum_{j \in \mathcal{N}(i)} \alpha_{i j}^{(l)} z_{j}^{(l)}\right) \tag{4} hi(l+1)=σ⎝⎛j∈N(i)∑αij(l)zj(l)⎠⎞(4)
对于上述公式的一些解释:
- 公式 (1) 对 l l l 层节点的embedding h i ( l ) h_{i}^{(l)} hi(l) 做了一个线性变换, W ( l ) \mathbf{W}^{(l)} W(l) 是一个该变换的一个可训练的参数。
- 公式 (2) 计算了成对节点间的原始注意力分数。它首先拼接了两个节点的embedding z z z, 注意||在这里表示拼接; 随后对拼接好的embedding以及一个可学习的权重向量 a ⃗ ( l ) \vec{a}^{(l)} a(l) 做点积; 最后应用了一个LeakyReLU 激活函数。这一形式的注意力机制通常被称为加性注意力(additive attention),区别于Transformer(Attention Is All You Need) 里的点积注意力(dot-product attention)。
- 公式 (3) 对于一个节点所有入边得到的原始注意力分数应用了一个softmax操作, 得到了注意力权重。
- 公式 (4), 形似GCN的节点特征更新规则,对所有邻节点的特征做了基于注意力的加权求和。
核心公式详细内容请参考:https://docs.dgl.ai/tutorials/models/1_gnn/9_gat.html
6 图注意力机制的类型
目前主要有三种注意力机制算法,它们分别是:学习注意力权重(Learn attention weights),基于相似性的注意力(Similarity-based attention),注意力引导的随机游走(Attention-guided walk)。这三种注意力机制都可以用来生成邻居的相对重要性,下文会阐述他们之间的差异。
首先我们对“图注意力机制”做一个数学上的定义:
定义(图注意力机制):给定一个图中节点 v 0 v_0 v0 和 v 0 v_0 v0的邻居节点 { v 1 , ⋯ , v ∣ Γ v 0 ∣ } ∈ Γ v 0 \left\{v_{1}, \cdots, v_{\vert\Gamma_{v_{0}}\vert}\right\} \in \Gamma_{v_{0}} {v1,⋯,v∣Γv0∣}∈Γv0 (这里的 Γ v 0 \Gamma_{v_{0}} Γv0 和GraphSAGE博文中的 N ( v 0 ) \mathcal{N}(v_0) N(v0) 表示一个意思)。注意力机制被定义为将 Γ v 0 \Gamma_{v_{0}} Γv0中每个节点映射到相关性得分(relevance score)的函数 f ′ : { v 0 } × Γ v 0 → [ 0 , 1 ] f^{\prime} :\left\{v_{0}\right\} \times \Gamma_{v_{0}} \rightarrow[0,1] f′:{v0}×Γv0→[0,1],相关性得分表示该邻居节点的相对重要性。满足:
∑ i = 1 ∣ Γ v 0 ∣ f ′ ( v 0 , v i ) = 1 \sum_{i=1}^{\vert\Gamma_{v_{0}}\vert} f^{\prime}\left(v_{0}, v_{i}\right)=1 i=1∑∣Γv0∣f′(v0,vi)=1
下面再来看看这三种不同的图注意力机制的具体细节
6.1 学习注意力权重
学习注意力权重的方法来自于Velickovic et al. 2018 其核心思想是利用参数矩阵学习节点和邻居之间的相对重要性。
给定节点 v 0 , v 1 , ⋯ , v ∣ Γ x 0 ∣ v_{0}, v_{1}, \cdots, v_{\vert\Gamma_{x_{0}}\vert} v0,v1,⋯,v∣Γx0∣相应的特征(embedding) x 0 , x 1 , ⋯ , x ∣ Γ o ∗ ∣ \mathbf{x}_{0}, \mathbf{x}_{1}, \cdots, \mathbf{x}_{\vert\Gamma_{o^{*}}\vert} x0,x1,⋯,x∣Γo∗∣ ,节点 v 0 v_0 v0和节点 v j v_j vj注意力权重 α 0 , j \alpha_{0, j} α0,j可以通过以下公式计算:
α 0 , j = e 0 , j ∑ k ∈ Γ v 0 e 0 , k \alpha_{0, j}=\frac{e_{0, j}}{\sum_{k \in \Gamma_{v_{0}}} e_{0, k}} α0,j=∑k∈Γv0e0,ke0,j
其中, e 0 , j e_{0, j} e0,j 表示节点 v j v_j vj对节点 v 0 v_0 v0的相对重要性。在实践中,可以利用节点的属性结合softmax函数来计算 e 0 , j e_{0, j} e0,j间的相关性。比如,GAT 中是这样计算的:
α 0 , j = exp ( LeakyReLU ( a [ W x 0 ∥ W x j ] ) ) ∑ k ∈ Γ v 0 exp ( LeakyReLU ( a [ W x 0 ∥ W x k ] ) ) \alpha_{0, j}=\frac{\exp \left(\text { LeakyReLU }\left(\mathbf{a}\left[\mathbf{Wx}_{0} \| \mathbf{Wx}_{j}\right]\right)\right)}{\sum_{k \in \Gamma_{v_{0}}} \exp \left(\text { LeakyReLU }\left(\mathbf{a}\left[\mathbf{W} \mathbf{x}_{0} \| \mathbf{W} \mathbf{x}_{k}\right]\right)\right)} α0,j=∑k∈Γv0exp( LeakyReLU (a[Wx0∥Wxk]))exp( LeakyReLU (a[Wx0∥Wxj]))
其中, a \mathbf{a} a 表示一个可训练的参数向量, 用来学习节点和邻居之间的相对重要性, W \mathbf{W} W 也是一个可训练的参数矩阵,用来对输入特征做线性变换, ∣ ∣ \vert\vert ∣∣表示向量拼接(concate)。

如上图,对于一个目标对象 v 0 v_0 v0, a 0 , i a_{0,i} a0,i 表示它和邻居 v i v_i vi的相对重要性权重。 a 0 , i a_{0, i} a0,i可以根据 v 0 v_0 v0 和 v i v_i vi 的 embedding x 0 x_0 x0 和 x i x_i xi 计算,比如图中 α 0 , 4 \alpha_{0, 4} α0,4 是由 x 0 , x 4 , W , a x_0, x_4, \mathbf{W}, \mathbf{a} x0,x4,W,a 共同计算得到的。
6.2 基于相似性的注意力
上面这种方法使用一个参数向量 a \mathbf{a} a学习节点和邻居的相对重要性,其实另一个容易想到的点是:既然我们有节点 v v v的特征表示 x x x,假设和节点自身相像的邻居节点更加重要,那么可以通过直接计算 x x x之间相似性的方法得到节点的相对重要性。这种方法称为基于相似性的注意力机制,比如说论文 TheKumparampil et al. 2018 是这样计算的:
α 0 , j = exp ( β ⋅ cos ( W x 0 , W x j ) ) ∑ k ∈ Γ v 0 exp ( β ⋅ cos ( W x 0 , W x k ) ) \alpha_{0, j}=\frac{\exp \left(\beta \cdot \cos \left(\mathbf{W} \mathbf{x}_{0}, \mathbf{W} \mathbf{x}_{j}\right)\right)}{\sum_{k \in \Gamma_{v_{0}}} \exp \left(\beta \cdot \cos \left(\mathbf{W} \mathbf{x}_{0}, \mathbf{W} \mathbf{x}_{k}\right)\right)} α0,j=∑k∈Γv0exp(β⋅cos(Wx0,Wxk))exp(β⋅cos(Wx0,Wxj))
其中, β \beta β 表示可训练偏差(bias), cos \cos cos函数用来计算余弦相似度,和上一个方法类似, W \mathbf{W} W 是一个可训练的参数矩阵,用来对输入特征做线性变换。
这个方法和上一个方法的区别在于,这个方法显示地使用 cos \cos cos函数计算节点之间的相似性作为相对重要性权重,而上一个方法使用可学习的参数 a \mathbf{a} a学习节点之间的相对重要性。
6.3 注意力引导的游走法
前两种注意力方法主要关注于选择相关的邻居信息,并将这些信息聚合到节点的embedding中。第三种注意力的方法的目的不同,我们以Lee et al. 2018 作为例子:
GAM方法在输入图进行一系列的随机游走,并且通过RNN对已访问节点进行编码,构建子图embedding。时间 t t t的RNN隐藏状态 h t ∈ R h \mathbf{h}_{t} \in \mathbb{R}^{h} ht∈Rh 编码了随机游走中 1 , ⋯ , t 1, \cdots, t 1,⋯,t 步访问到的节点。然后,注意力机制被定义为函数 f ′ : R h → R k f^{\prime} : \mathbb{R}^{h} \rightarrow \mathbb{R}^{k} f′:Rh→Rk,用于将输入的隐向量 f ′ ( h t ) = r t + 1 f'\left(\mathbf{h}_{t}\right)=\mathbf{r}_{t+1} f′(ht)=rt+1映射到一个 k k k维向量中,可以通过比较这 k k k维向量每一维的数值确定下一步需要优先游走到哪种类型的节点(假设一共有 k k k种节点类型)。下图做了形象的阐述:
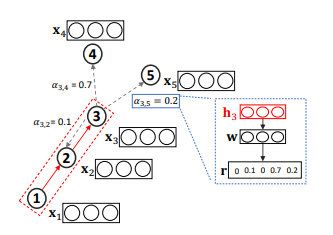
如上图, h 3 h_3 h3聚合了长度 L = 3 L=3 L=3的随机游走得到的信息 ( x 1 , x 2 , x 3 ) \left(x_{1}, x_2, x_{3}\right) (x1,x2,x3),我们将该信息输入到排序函数中,以确定各个邻居节点的重要性并用于影响下一步游走。
7 后话
至此,图注意力机制就讲完了,还有一些细节没有涉及,比如在 GAT论文 中讨论了对一个节点使用多个注意力机制(multi-head attention), 在AGNN论文中分析了注意力机制是否真的有效,详细的可以参考原论文。
8 Reference
Attention Models in Graphs: A Survey
Graph Attention Networks
Attention-based Graph Neural Network for Semi-supervised Learning
Graph Classification using Structural Attention