Mysql-存储引擎 InnoDB详解
原文地址 mp.weixin.qq.com
作者:陌北有棵树,Java 人,架构师社区合伙人!
关于 MySQL 对于后端程序员的重要性不言而喻,而 InnoDB 也已经是 MySQL 默认的存储引擎。作为我们每天打交道的存储引擎,我们对它可能需要对它有更多的了解。这样对于很多灵异事件,才能从容应对。
本次文章的内容大部分来自 MySQL8.0 的官方文档,之所以没有选择现成的资料,而去挑战自己的弱点——英语。是因为最近意识到,学习知识应该到知识的源头,可能最开始会很吃力,但我相信对于后续的技术提升一定是有帮助的。与所有希望在技术上深挖的程序员同胞共勉~
简介
首先来看官方文档对 InnoDB 的解释:
InnoDB 是一个平衡了高可用和高性能的通用存储引擎。
优势
-
保护用户数据:DML 操作,通过事务来遵循 ACID 模型
-
高性能:行级锁,一致性读取
-
最小化主键查找的 IO:聚簇索引
-
数据完整性:外键
-
崩溃恢复
-
在主内存缓存索引数据和缓存表
-
外键
-
校验机制
-
只要你在设计表时选择了合适的主键,主键列 where、order by、group by、join 操作会被自动优化
-
自适应哈希索引
InnoDB 架构
InnoDB 的整体架构可以分为两个部分:内存架构、磁盘架构
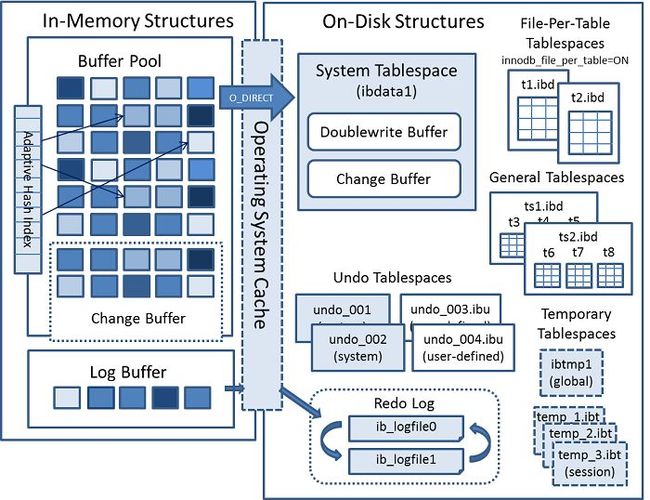
InnoDB 内存架构
InnoDB 在内存中主要包括下面几个部分:缓冲池、Change 缓冲区、自适应哈希索引、Log 缓冲区
【一】缓冲池
简介: 存储访问时的缓存表和索引数据。在专用服务器上,通常会为缓冲池分配 80% 的物理内存
作用: 可以快速从内存获取数据,加快了处理速度。
技术要点:
Page:为了 high-volume 的读取效率,缓冲池进一步被分为页的结构。
LRU:为了缓存的管理效率,缓冲池实现 page 间的链表,使用 LRU 算法。缓冲池使用调整后的 LRU(最近最少使用)算法,当需求添加新的 page 时,最近最少使用的 page 被清除,同时新页面被添加到链表的中间部分
这种中间点插入的策略,把链表分为两个子链表
-
头部:最近被访问过的 “年轻” 页
-
尾部:最近被访问的 old page
这样使新子列表中保存更重要的 page,旧子列表包含较少使用的 page,这部分 page 是被清除的候选 page
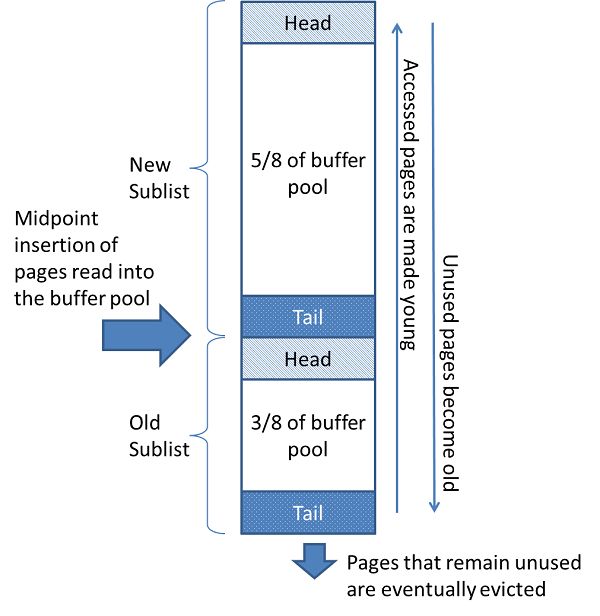
默认情况下,算法配置如下:
-
旧子列表:缓冲池的 3/8
-
midpoint(中间点)是新子列表尾部和旧子列表头部的交界
-
当旧页被访问,会被移动到缓冲池的头部,随着数据库的运行,一直没有被访问的页会一直后移,直至最后被移除。
【二】Change Buffer
Change Buffer 是一种特殊的数据结构,当某些页面不在缓冲池中,缓存会改变二级索引 page,这可能会造成 insert,update,delete(DML)操作会与其他从缓冲池中的读操作加载的 page 合并。
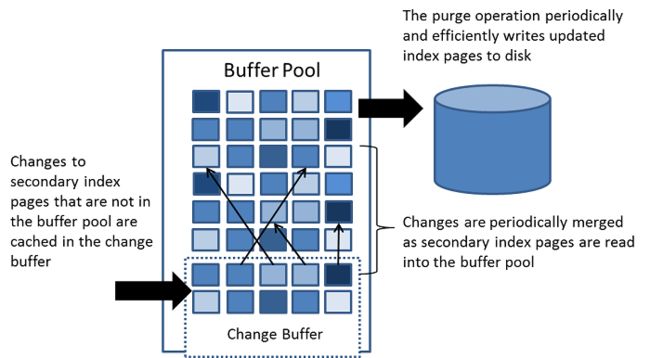
不同于聚簇索引,二级索引通常不唯一,同时二级索引的插入相对随机。
同时,为了避免频繁的 IO 随机读写,当更新和删除操作时,并不会立即写入磁盘,而是会选择系统空闲时定期进行写入磁盘的操作。Change Buffer 在内存中,是缓冲池中的一部分,在磁盘中,是系统表空间的一部分。
【三】自适应哈希索引
简介: InnoDB 可以基于搜索的模式,使用索引键前缀构建哈希索引,也就是说,这个哈希索引是由经常访问的索引页面构建的。
作用: 在不牺牲事务特性和可靠性的基础上,使 InnoDB 像一个内存数据库一样工作,也就是说在一定情况下,通过这种哈希索引的方式会提升查询速度。InnoDB 中存在一种监视索引搜索的机制,但这种机制有时反倒带来额外的开销。所以在选择是否使用哈希索引前,可能需要做好基准测试,否则还是建议禁用。
InnoDB 磁盘架构
通过上面的整体架构图可以看到,InnoDB 在磁盘中存储的信息包括:各种表空间(TableSpace),Redo Log。
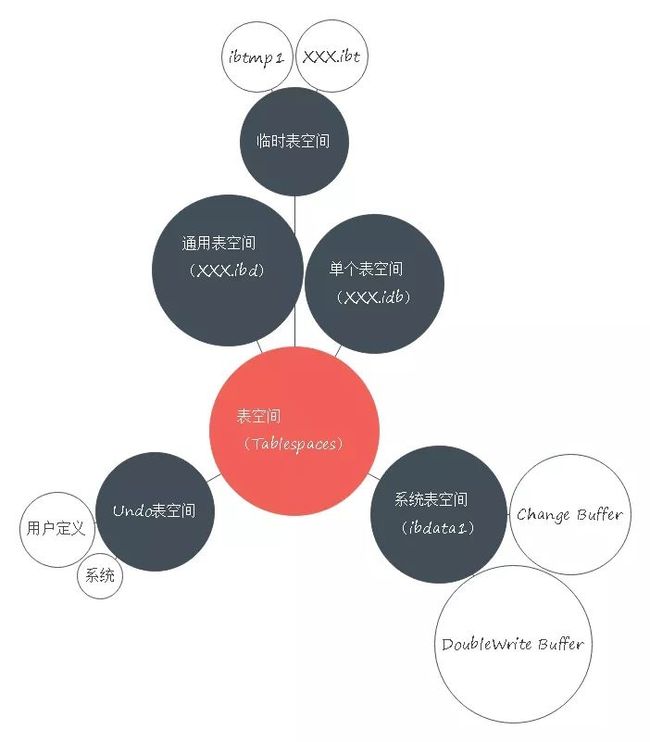
InnoDB 对数据存储方式的设计,主要是基于表空间的形式。表空间的种类如下图所示:
使用 InnoDB 表的限制,来自 MySQL 官方文档,感觉有些还是挺有趣的,但可能实际场景中并不会用到:
-
一个表最多包含 1017 列,表示并没有创建过这样多列的表
-
一个表最多可以创建 64 个二级索引
-
索引键前缀长度限制为 3072 字节
Undo Log 和 Redo Log
这里还有两个 Log 区域需要关注一下:
Undo Log
Undo Log 是与事务读写关联的,主要作用在事务回滚和多版本并发控制中。
Undo Log 在回滚段中存储,回滚段在 Undo 表空间和全局临时表空间中。Undo log 被分为 insert undo log 和 update undo log。Insert undo log 只在事务回滚时需要,一旦事务提交就被丢弃。Update undo log 也被用在一致性读,在一致性读中可能需要 update undo log 的信息来生成该行数据早期的版本。
关于 undo log 的建议
定期地提交事务,包括哪些只包含一致性读的事务,否则,InnoDB 不会丢弃 update undo log 中的数据,回滚段会变得越来越大,占满空间。undo log 中回滚段的物理空间,通常小于相应插入或更新的行,可以利用这个信息计算回滚段需要的空间
Redo Log
也就是 ib_logfile0 和 ib_logfile1 两个文件
这里结合的是 MySQL 的 WAL(Write-Ahead Logging)也就是先写日志,再写磁盘,具体过程是下面这样:当有一条记录要更新,先将记录写到 redo log,并更新内存,InnoDB 会在空闲的时候,把操作记录更新到磁盘。
官方建议的最佳实践
-
指定主键
-
外键
-
关闭自动提交
-
DML 的事务进行分组
-
不要用 lock table,如果希望某行的独占写,用 select … for update
-
启用 innode_file_per_table
参考:MySQL 官方文档