《概率论与数理统计》学习笔记
重温《概率论与数理统计》进行查漏补缺,并对其中的概念公式等内容进行总结,以便日后回顾。
目录
第一章 概率论的基本概念
第二章 随机变量及其分布
第三章 多维随机变量及其分布
第四章 随机变量的数字特征
第五章 大数定律及中心极限定理
第六章 样本及抽样分布
第七章 参数估计
第八章 假设检验
第一章 概率论的基本概念
1.随机试验
随机试验——具有下述三个特点的试验:(1)可以在相同的条件下重复地进行;(2)每次试验的可能结果不止一个,并且能事先明确试验的所有可能结果;(3)进行一次试验之前不能确定哪一个结果会出现。
2.样本空间、随机事件
样本空间——随机试验的所有可能结果组成的集合。
样本点——样本空间的元素。
随机事件——随机试验的样本空间的子集。
事件间的关系:
事件B包含事件A:事件A发生必导致事件![]() 发生时。若,则称事件A与事件相等。
发生时。若,则称事件A与事件相等。
事件A与事件B的和事件:当且仅 当A,B中至少有一个发生时。
事件A与事件B的积事件:当且仅当A,B同时发生时。
事件且称为事件A与事件B的差事件:当且仅当A发生、B不发生时。
事件A与B是互不相容的或互斥的:事件 A与事件B不能同时发生。
事件A与事件B互为逆事件.又称对立事件,事件A、B中必有一个发生,且仅有一个发生。
3.频率与概率
在相同的条件下,进行了n次试验,在这n次试验中,事件A发生的次数nA称为事件A发生的频数。比值n/nA称为事件A发生的频率。
设E是随机试验,S是它的样本空间。对于E的每一事件人赋予一 个实数,记为P(A),称为事件A的概率。如果集合函数P(・)满足下列条件:非负性,规范性,可列可加性。
4.等可能概型
特点:
- 试验的样本空间只包含有限个元素;
- 试验中每个基本事件发生的可能性相冋。
5.条件概率
设A,B是两个事件,且P(A)>0,称
![]()
为在事件A发生的条件下事件B发生的条件概率。
全概率公式:
设试验E的样本空间为S,A为E的事件,B1,B2,…Bn为S的一个划分,且P(Bi)>0(i=1,2,…n),则
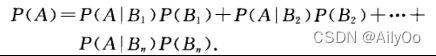
贝叶斯公式:
设试验E的样本空间为S,A为E的事件,B1,B2,…Bn为S的一个划分,且P(A)>0(i=1,2,…n),P(Bi)>0(i=1,2,…n),则
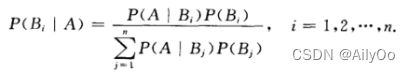
6.独立性
设A,B是两个事件,如果满足等式
![]()
则称事件A,B相互独立。
第二章 随机变量及其分布
1.随机变量
2.离散型随机变量及其分布
三种重要离散型随机变量
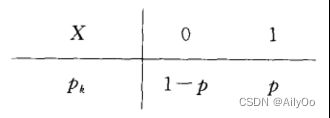
(0-1)分布
设随机变量X只可能取0与1两个值,它的分布律是
![]()
则称X服从以为参数的(0 — 1)分布或两点分布.
(0-1)分布的分布律也可写成
伯努利试验、二项分布
设试验E只有两个可能结果:A及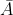 ,则称E为伯努利试验. 设P(A)=p(0
,则称E为伯努利试验. 设P(A)=p(0
泊松分布
设随机变量X所有可能取的值为0,1,2,…,而取各个值的概率为
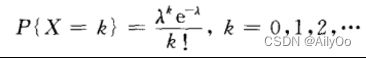
其中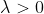 是常数,则称X服从参数为人的泊松分布,记为
是常数,则称X服从参数为人的泊松分布,记为![]()
泊松定理:
设是一个常数,n是任意正整数,设![]() 则对于任一固 定的非负整数k有
则对于任一固 定的非负整数k有
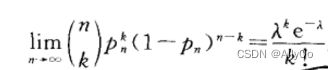
以n,p,为参数的二项分布的概率值可以由参数为的泊松分布的概率值近似。
3.随机变量的分布函数
设X是一个随机变量,x是任意实数,函数
![]()
称为X的分布函数。
4.连续型随机变量及其概率密度
三种重要连续型随机变量
均匀分布
若连续型随机变量X具有概率密度
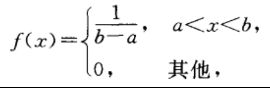
则称X在区间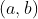 上服从均匀分布,记为
上服从均匀分布,记为![]()
X的分布函数为
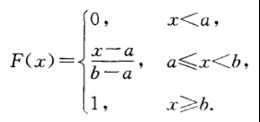
指数分布
若连续型随机变量X具有概率密度
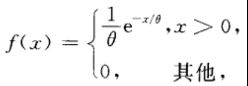
其中![]() 为常数,则称X服从指数分布。
为常数,则称X服从指数分布。
X的分布函数为

正态分布
若连续型随机变量X具有概率密度
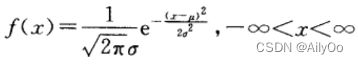
其中![]() 为常数,则称X服从参数为的正态分布。
为常数,则称X服从参数为的正态分布。
第三章 多维随机变量及其分布
1. 二维随机变量及分布
设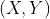 是二维随机变量,对于任意实数
是二维随机变量,对于任意实数 ,二元函数:
,二元函数:
![]()
称为二维随机变量的分布函数。
如果二维随机变量全部可能取到的值是有限对或可列无限多对,则称是离散型的随机变量。
设二维离散型随机变量所有可能取的值为![]() ,记
,记
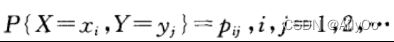
称为二维离散型随机变量的概率分布。

称为二维离散型随机变量 关于X和关于Y的边缘分布。
对于给定的 ,如果
,如果![]() ,
,
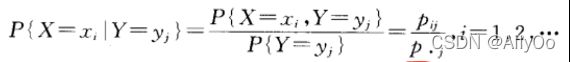
称为![]() 条件下随机变量X的条件分布律。
条件下随机变量X的条件分布律。
对于二维随机变量的分布函数,如果存在非负的函数,使对于任意有

称是连续型的二维随机变量,函数称为二维随机变量的概率密度。
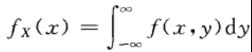
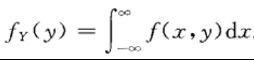
分别称为![]() 和
和![]() 为 关于X和关于Y的边缘概率密度。
为 关于X和关于Y的边缘概率密度。
设二维随机变量的概率密度为 , 关于Y的边缘概率密度为
, 关于Y的边缘概率密度为![]() 。若对于固定的y,
。若对于固定的y,![]() ,则称
,则称![]() 为在Y=y的条件下X的条件概率密度,记为
为在Y=y的条件下X的条件概率密度,记为

2. 相互独立的随机变量
设![]() 及
及![]() 、
、![]() 分别是二维随机变量的分布函数及边缘分布函数。若对于所有有
分别是二维随机变量的分布函数及边缘分布函数。若对于所有有
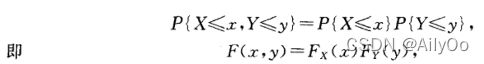
则称随机变量 和
和 是相互独立的.
是相互独立的.
第四章 随机变量的数字特征
1. 数学期望
设离散型随机变量X的分布律为
![]()
若级数
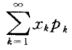
绝对收敛,则称级数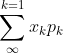 的和为随机变量X的数学期望,记为,即
的和为随机变量X的数学期望,记为,即
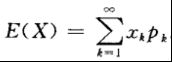
设连续型随机变量的概率密度为 ,若积分
,若积分![]() 绝对收敛,则称
绝对收敛,则称![]() 的值为随机变量X的数学期望,记为
的值为随机变量X的数学期望,记为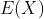 ,即
,即
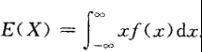
2. 方差
方差:![]()
标准差:![]()
对于离散型随机变量:![]()
对于连续型随机变量:![]()
设随机变量具有数学期望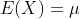 ,方差
,方差![]() ,则对于任意正数,不等式
,则对于任意正数,不等式
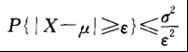
成立。这一不等式称为切比雪夫不等式。
切比雪夫不等式给出了在随机变量的分布未知,而知道均值、方差的情况下估计概率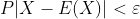 的界限。
的界限。
至少有75%的数据在平均数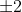 个标准差的范围之内;
个标准差的范围之内;
至少有89%的数据在平均数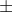 3个标准差的范围之内;
3个标准差的范围之内;
至少有94%的数据在平均数4个标准差的范围之内。
3. 协方差及相关系数
协方差:![]()
相关系数: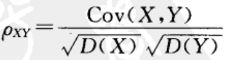
4. 矩、协方差矩阵
k阶原点矩(k阶矩):![]()
k阶中心矩![]()
k+l阶混合矩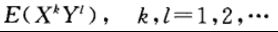
k+l阶混合中心矩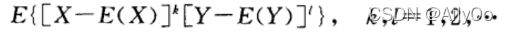
设 维随机变量
维随机变量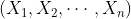 的二阶混合中心矩
的二阶混合中心矩
![]()
都存在,称
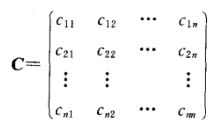
维随机变量 的协方差矩阵。
第五章 大数定律及中心极限定理
1.大数定律:叙述随机变量序列的前一些项的算术平均值在某种条件下收敛到这些项的算术平均值
弱大数定理(辛钦大数定理) 设![]() 是相互独立,服从同一分布的随机变量序列,且具有数学期望
是相互独立,服从同一分布的随机变量序列,且具有数学期望![]() 。作前n个变量的算术平均
。作前n个变量的算术平均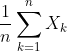 则对于任意
则对于任意![]() ,有
,有
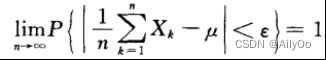
弱大数定理(辛钦大数定理) 设随机变量![]() 相互独立,服从同一分布且具有数学期望
相互独立,服从同一分布且具有数学期望![]() ,则序列
,则序列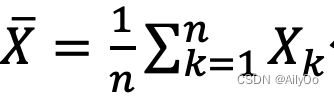 依概率收敛于
依概率收敛于![]() ,即
,即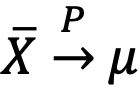
伯努利大数定理 设![]() 是n次独立重复试验中事件A发生的次数,是事件A在每次试验中发生的概率,则对于任意正数
是n次独立重复试验中事件A发生的次数,是事件A在每次试验中发生的概率,则对于任意正数 >0,有
>0,有
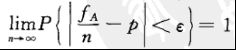
2. 中心极限定理:是确定在什么条件下,大量随机变量之和的分布逼近于正态分布
设随机变量![]() 相互独立,服从同一分布,且具有数学期望和方差
相互独立,服从同一分布,且具有数学期望和方差![]() ,则随机变量之和的标准化变量
,则随机变量之和的标准化变量
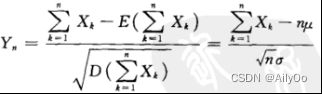
的分布函数![]() 对于任意x满足
对于任意x满足
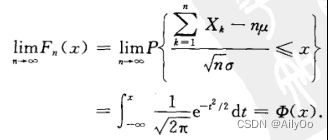
(设从均值为 ,方差为
,方差为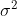 (有限)的任意一个总体中抽取样本量为n的样本,当n充分大的时,样本均值的抽样分布近似服从均值为,方差为
(有限)的任意一个总体中抽取样本量为n的样本,当n充分大的时,样本均值的抽样分布近似服从均值为,方差为![]() 的正态分布)
的正态分布)
第六章 样本及抽样分布
1. 随机样本
设X是具有分布函数F的随机变量,若![]() 是具有同一分布函数F的、相互独立的随机变量,则称
是具有同一分布函数F的、相互独立的随机变量,则称![]() 为从分布函数F(或总体F、或总体X)得到的容量为n的简单随机样本。
为从分布函数F(或总体F、或总体X)得到的容量为n的简单随机样本。
2. 抽样分布
样本均值: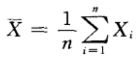
样本方差: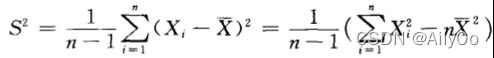
样本标准差: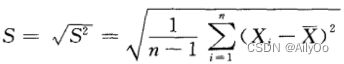
样本k阶(原点)矩: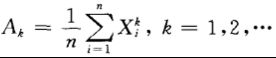
样本k阶中心矩: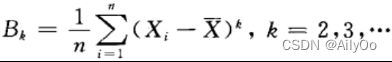
3. 常用统计量分布
(1)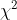 分布
分布
设![]() 是来自总体
是来自总体 的样本,则称统计量
的样本,则称统计量
![]()
服从自由度为n的分布,记为![]()
(2) 分布
分布
设![]() ,且X,Y相互独立,则称随机变量
,且X,Y相互独立,则称随机变量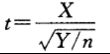
服从自由度为n的t分布,记为![]()
(3) 分布
分布
设![]() ,且U,V相互独立,则称随机变量
,且U,V相互独立,则称随机变量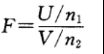
服从自由度为![]() 的F分布,记为
的F分布,记为![]()
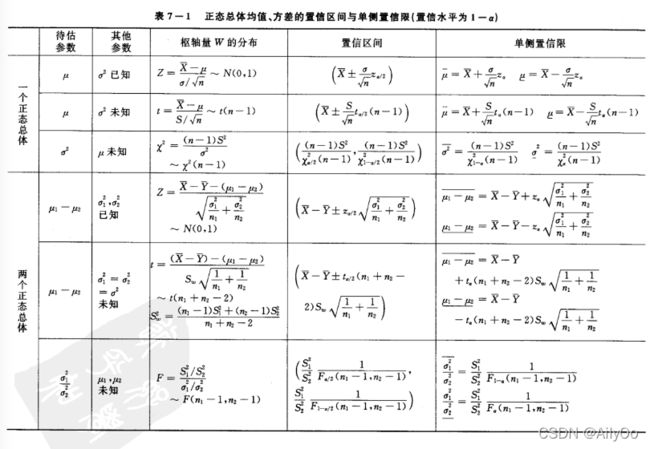
第七章 参数估计
1. 点估计
点估计是适当地选择一个统计量作为未知参数的估计(称为估计量),若已取得一样本,将样本值代入估计量,得到估计量的值,以估计量的值作为未知参数的近似值(称为估计值)。
两种求点估计的方法:矩估计法和最大似然估计法。
矩估计法的做法是,以样本矩作为总体矩的估计量,而以样本矩的连续函数作为相应的 总体矩的连续函数的估计最,从而得到总体未知参数的估计。
最大似然估计法的基本想法是,若已观察到样本 的样本值![]() ,而取到这一样本值的概率为p(在离散型的情况),或落在这一样本值
,而取到这一样本值的概率为p(在离散型的情况),或落在这一样本值![]() 的邻域内的概率为p(在连续型的情况),而P与未知参数有关,就取的估计值使概率取到最大。
的邻域内的概率为p(在连续型的情况),而P与未知参数有关,就取的估计值使概率取到最大。
2. 估计量的评选标准
无偏性、有效性、相合性
3. 区间估计
点估计不能反映估计的精度,引入了区间估计。置信区间是一个随机区间,它覆盖未知参数具有预先给定的高概率(置信水平),即对于任意![]() ,有
,有
![]()
第八章 假设检验
1. 假设检验
实际推断原理
小概率事件在一次试验中实际上是不会发生的,实际推断原理又称小概率原理。
假设检验
(1)假设是指关于总体的论断或命题,常用字母“H”表示,假设分为基本假设 (又称原假设,零假设)和备选假设(又称备择假设,对立假设)。还可将假设分为参数假设和非参数假设,参数假设是指已知总体分布函数形式,对其中未知参数的假设,其他的假设就是非参数假设,也可将假设分为简单假设和复合假设。完全决定总体分布的假设为简单假设,否则为复合假设。
(又称原假设,零假设)和备选假设(又称备择假设,对立假设)。还可将假设分为参数假设和非参数假设,参数假设是指已知总体分布函数形式,对其中未知参数的假设,其他的假设就是非参数假设,也可将假设分为简单假设和复合假设。完全决定总体分布的假设为简单假设,否则为复合假设。
(2)假设检验:根据样本,按照一定规则判断所做假设的真伪,并作出接受还是拒绝接受的决定。
两类错误
拒绝实际真的假设(弃真)称为第一类错误。
接受实际不真的假设(纳伪)称为第二类错误。
显著性检验
(1)显著性水平:在假设检验中允许犯第一类错误的概率,记为α(0<α<1),则α称为显著水平,它表现了对弃真的控制程度,一般α取0.1,0.05,0.01,0.001等值。
(2)显著性检验:只控制第一类错误概率α的统计检验,称为显著性检验.
(3)显著性检验的一般步骤
1)根据问题要求提出原假设及备择假设 ;
;
2)给出显著性水平α(0<α<1)以及样本容量n;
3)确定检验统计量及拒绝域形式;
4)按犯第一类错误的概率等于α求出拒绝域W;
5) 根据样本值计算检验统计量T的观测值t,当t W时,拒绝原假设;否则,接受原假设。
W时,拒绝原假设;否则,接受原假设。
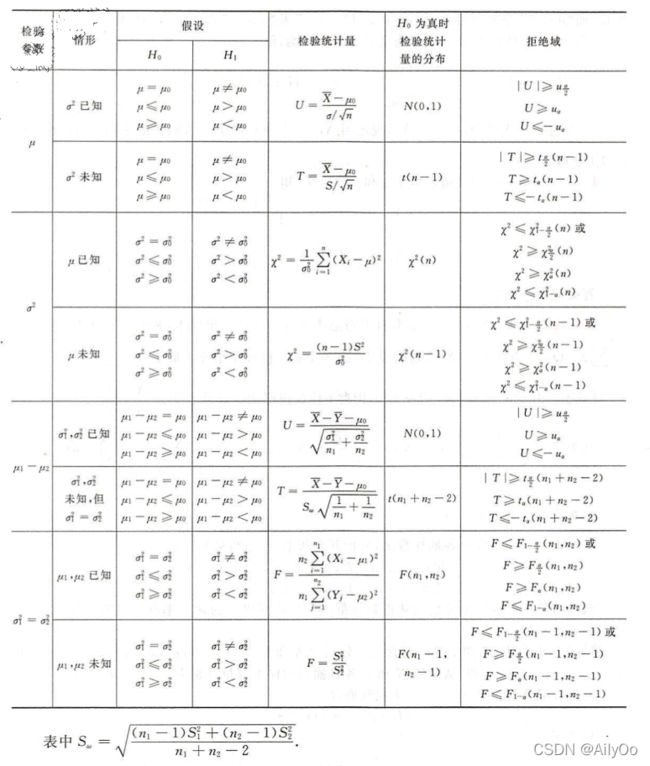
正态总体参数的假设检验
2. p值检验法
假设检验问题的p值是由检验统计量的样本观察值得出的原假设可被拒绝的最小显著性水平。
利用p值来确定检验拒绝域的方法,称为P值检验法。
- 若p值<=α,则在显著性水平α下拒绝;
- 若p值>α,则在显著性水平α下接受。