CS 224D lecture 5 笔记 分类: CS224D notes 2015-07-18 00:04 3人阅读 评论(0) 收藏
哈哈哈,终于又到了写博客的时间,这次的内容,其实说实话不太多,就是Recommendreading太多看的人头大,而且Recommendreading大多是没有接触到的模型,更让人摸不着头脑,权当是预习吧,哈哈!
废话不多说哦,先写写这一讲的整体结构。Lecture5主要有三部分内容。第一部分是对project的建议和介绍;第二部分就是详细介绍NeuralNetwork的结构,并且如何tune这个模型的parameters;第三部分还补充了一些数学内容。
ProjectIdea
这才发现国外的大学教育真的很重视实践哦,project的比重如此之大,而且特别重视这个东西。
其实做项目首先得对dataset进行选择,可以选择现成的academicdataset这样有baselines而且可以知道自己的结果怎么样到底好还是不好;也可以自己想办法弄一个dataset这样有很强的专用的,可以满足自己的research或者产品的使用,但是没有现成的baseline作为参考。然后就是做之前给自己定一个目标(^- ^)。再对自己的dataset做一个简单的处理。
老师建议了两个方向~第一就是applyexisting NNets to tasks;第二就有点野心了,自己发明一个model(--)。
我等菜鸟还是选择第一个吧。
最后老师在Applyexisting NNets to newtasks的部分讲了几个Ideas。这几个Ideas我大概思考了一下大概弄明白了讲得什么东西,还没想清楚选哪个题目(选择困难症- -)
NeuralNetwork的结构及如何对这个model调参
课上的model的例子是基于windowclassifier。
首先讲的是Feed-forwardcomputation就是bottom-top的行进路线。这个上一讲也有详细说明,slides上讲的也很详细,没啥说的。还推荐UFLDL的课程。我感觉讲得更详细一些,而且更直观。Feed-forwardcomputation的目的就是自底向上的将每一层的activation求出来,然后最终把结果(score)求出来。这就是它的目的。然后根据最后的score和它的真实数值进行比较做出一个costfunction或者lossfunction我们的目标就是求出使costfunction最大或者lossfunction最小的parameters。后面就是重头戏了,详细的讲解了backpropagation的运算过程。BP的重点目标有两个一个是求每一层的每个node的对应的delta也就是残差;另一个就是求最终error对应每个weight的倒数。有了以上两个的计算方法整体调参就很简单了,哈哈哈。
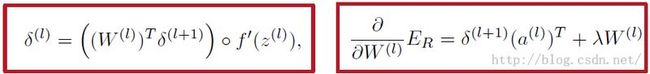
这里把那两个重点的公式记录下来,具体计算过程slide上讲得特详细,就不赘述啦。
Chainrule的补充
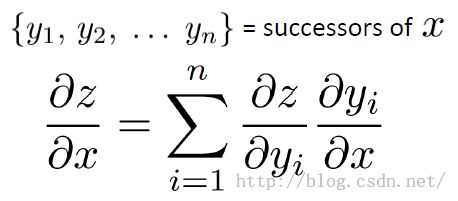
知道这个东西就好,这个公式是一般式,其他的公式都是可以从这个公式推导出来。
Papersummary
NLP scratch
第一篇paper可不是一般的长啊,从头到尾看一遍都看了好久。不过这篇paper只是对NLP的一个简要介绍(scratch)。虽说是scratch但我觉得这篇paper还是很值得看的。当以后做实际NLP项目遇到实际问题的时候可以回过头来看这个paper中相应的章节。相应的章节中一般都给出了前人所得到的benchmarks及如何得到这个benchmarks的paper参照这些就能得到更好的思路,解决目前所遇到的问题。那就总结总结这篇paper所讲的内容吧。1.paper介绍了各种NLP的分支任务:part-of-speechtagging, chunking, Named Entity Recognition and Semantic RoleLabeling。这部分介绍了各种分支任务是什么,以及前人到达的benchmarks。
2.简要详细的介绍了实现各种分支任务的方法(Networks)。然后是模型的优化的方法。
3.介绍了使用Lotsof unlabeled data提高模型精确度的方法。
4.Multi-tasklearning就是将有些模型混搭到一起,得到混搭后的模型的精度比之前的高
5.最后讲了NLP总体还可以进行改进的地方和如果要改进的话,可以入手的方面。
以上五条每一条中的每一个小分支都能进行research进行提高,这个paper也算给出一个总结或者目录性质的东西以供参考查阅吧。
lecture5推荐的其他四篇paper全是RNN的应用的。我也没学RNN不知道RNN是怎么回事好吗(--)。可怜的我~~~
Neuralnetwork for factoid question answering over paragraphs
这篇论文讲的是NN在FactoidQuestion Answering中的应用,就是类似之前的一款综艺节目“幸运52”,“开心辞典”或者“你来描述我来猜”。
这篇论文实现的思路是:将answers和questions一起进行training放到同一个模型里,这样训练后的answers和questions就在同一个space里,如果训练的好的话相应的answer就会在这个space里距离对应的question近,就可以用求距离的方法找到对应questions的答案。建立costfunction是用max-margin的方法。第五部分写了提高精确度的思路。
GroundedCompositional Semantics for finding and describing images withsentences
这篇论文的目标是给一张图片,然后计算机自动描述这张图片里的内容。
思路:其实和上面的paper类似,把sentences和images投影到同一个embeddingspace然后就容易retrieve啦!
首先要形成sentences就有难度!得先进行semanticvector space的描述然后进行compositionality具体方法用到了DT-RNNs(--没弄明白)。再用NeuralNetworks将Images里的features提取出来。最后把两者一综合进行MultimodalMapping,使用到了Max-margin,就能描述啦!这个东西的应用很棒唉,想象一下以后给计算机输入一个图片,就能“说”出来图片里是什么东西;反过来人类说一句话,计算机就能检索出来这句话相近的图片,不是很神奇的一件事吗!
DeepVisual-Semantic Alignments for Generating Image Descriptions
这个应用和之前paper里的应用类似,不同的是这个应用还将图片里相应的entity圈出来,这就更高大上一些了。
思路是先把images表示成一个vectors串;再把sentences表示成一个vectors串;最后把image里的object和sentences里的对应的entities对齐(alignment)。
最后一篇论文是俺们的老师的大作。
RecursiveDeep Models for Semantic Compositionality Over a Sentiment Treebank
这篇论文的目的是从一句话中提取出这句话的感情色彩并量化表示出来。
思路:一句话里能够代表这句话整体思路的单词不多,只要能处理好这几个关键词就能很好的把握整句话的感情色彩。作者发现dataset中其中五个levels的数据特别多,提取出这五个levels的数据,然后对数据进行processing。之后再用到了RNN,这个我就看不懂了(--)。等学完RNN再回头看吧。
版权声明:本文为博主原创文章,未经博主允许不得转载。