【HBASE】Hbase的Shell操作
文章目录
- 任务
- 1、基本操作
-
- 1.1 进入客户端
- 1.2 namespace
- 1.3 DDL
- 1.4 DML
任务
- 搭建分布式HBASE集群
- 学会使用基本的shell命令,完成数据增删改查的操作
1、基本操作
1.1 进入客户端
在这之前已经配置好环境变量
[wzy@hadoop102 hbase]$ hbase shell
1.2 namespace
- 创建命名空间
hbase:001:0> create_namespace 'bigdata'
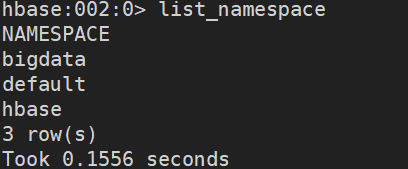
- 查看所有的命名空间
hbase:002:0> list_namespace
1.3 DDL

以网上的一个学生成绩表的例子来演示hbase的用法。这里grad对于表来说是一个只有它自己的列族,course对于表来说是一个有两个列的列族,这个列族由两个列组成math和art,当然我们可以根据我们的需要在course中建立更多的列族,如computer,physics等相应的列添加入course列族。
- 建立一个表scores,有两个列族grad和course
hbase:003:0> create 'bigdata:scores','grad','course'
- 查看所有表名
hbase:004:0> list
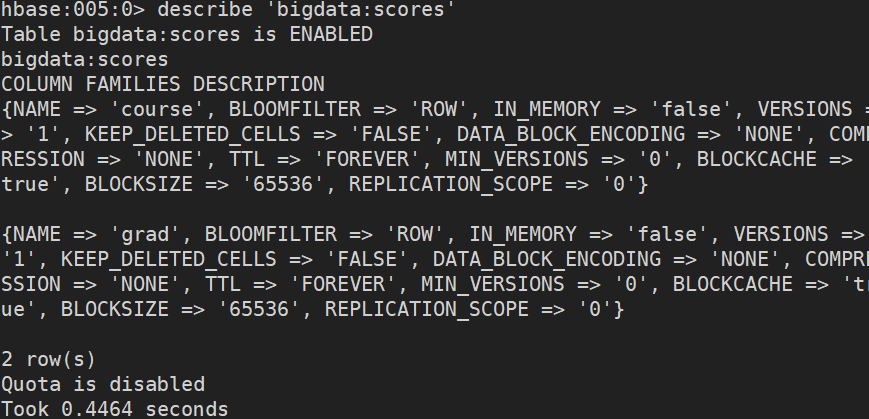
- 查看表的详情
hbase:005:0> describe 'bigdata:scores'
4.修改表
- 增加列族和修改信息都使用覆盖的方法
hbase:006:0> alter 'bigdata:scores',{NAME=>'grad',VERSIONS=>3}
- 删除信息使用特殊的语法
alter "bigdata:scores",'delete'=>'grad'
5.删除表
shell中删除表,需要将表格设置为不可用
disable 'bigdata:scores'
drop 'bigdata:scores'
1.4 DML
- 写入数据
put 'scores','Tom','grade:','5'
put 'scores','Tom','course:math','97'
put 'scores','Tom','course:art','87'
put 'scores','Jim','grade:','4'
put 'scores','Jim','course:','89'
put 'scores','Jim','course:','80'
put命令比较简单,只有这一种用法:
hbase> put 't1', 'r1', 'c1', 'value', 'ts1'
t1指表名,r1指行键名,c1指列名,value指单元格值。ts1指时间戳,一般都省略掉了。
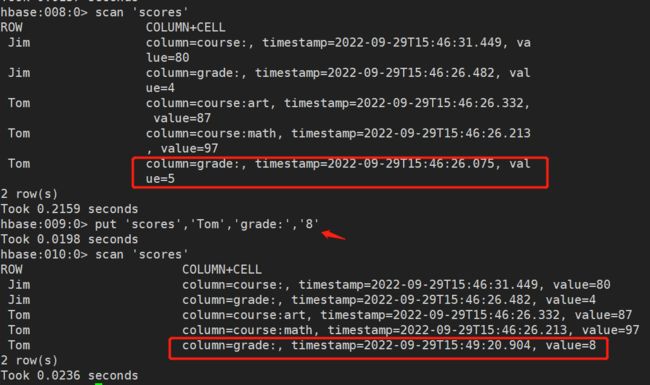
如果重复写入多个rowkey,相同列的数据,会写入多个版本进行覆盖。
2. 读取数据
- 根据键值查询数据
get 'scores','Jim'
get 'scores','Jim','grade'
可能你就发现规律了,HBase的shell操作,一个大概顺序就是操作关键词后跟表名,行名,列名这样的一个顺序,如果有其他条件再用花括号加上。

- 扫描所有数据
scan 'scores'
也可以指定一些修饰词:TIMERANGE, FILTER, LIMIT, STARTROW, STOPROW, TIMESTAMP, MAXLENGTH,or COLUMNS。没任何修饰词,就是上边例句,就会显示所有数据行。

3. 删除数据
- delete
delete表示删除一个版本的数据,即为1个cell,不填写版本默认删除最新的版本。
delete 'scores','Jim','grade'
- deleteall
删除所有版本的数据,即为当前行当前列的多个cell。(执行这个命令不会删除数据,而是标记为delete,只有在清理磁盘的时候才会删除)
deleteall 'scores','Jim','grade'