CS224d lecture 6札记
哈哈哈,终于又到了每课的写笔记时间。这次课程的内容比较少,可能是为了给Problem set 1空余时间吧。
废话不多说。写喽
这次的video讲的东西主要就是把推荐的论文稍微详细的讲解了一部分,然后外加给RNN模型开了个头。
1.Multi-task learning / weight sharing
这个第一部分其实在NLP(almost) from scratch里也有讲解它的理念就是,在DL model里面底下几层里学到的feature是相同或者近似的,那么这样的话,只需要统一给DL model的下面的几层建模,然后根据不同的任务再在之上分别建立不同的模型就好。这样可以大大简化模型的复杂度,又可以最大限度的利用到现有的数据,提取出更多的features。
然后后面就列出来了几个表格,说明俺们的multi-task learning就是好,用事实说话么。
2.Non-linearity
接下来就是每一层里对输入数据进行non-linearity的操作了。主要有以下几种:1.sigmoid function 2.hyperbolic tangent function 3.hard tanh function 4.soft sign 5.rectified linear function这五种函数根据实际情况的不同灵活选择。具体怎么选课上也没说- -,不过在推荐阅读里给出了论文引用,具体遇到问题的时候参考这篇论文就会万事OK啦。

这一段在推荐阅读的第十四页的左下角,每篇论文都有链接可以很方便的查到。
下面是五个常用non-linearities的函数表达式和对应的图形:
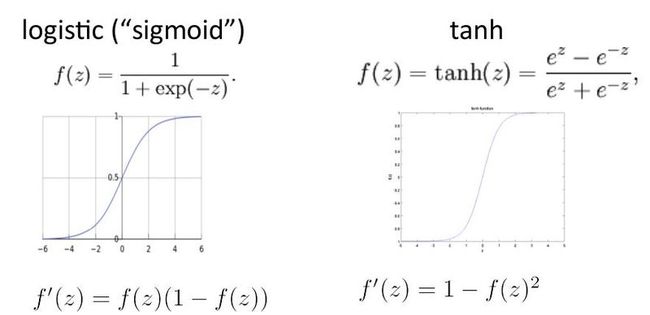

其实tanh就是sigmoid rescaled及shifted后的产物。
tanh(z) = 2*logistic(2z) - 1
3.Gradient checks
哎呀这个gradient checks可是很厉害哦不过一定要使用精度高的那个公式,也就是f(x + e) - f(x - e) / 2e不能用f(x + e) - f(x) / e因为后面的那个精度低。
epsilon的选择也很有讲究哦,不能太大也不能太小。用paper里的话说就是:Contrary to naive expectiations, the relative difference may grow if we choose an eplison that is too small. i.e., the error should first decrease as eplison is decreased and then may worsen when numerical precision kicks in, due to non-linearities.
最终根据不断的尝试和经验选择我们发现eplison选为10^-4的效果最好。
如果gradient checks失败了怎么办呢?
首先第一步:简化模型知道没有bug
第二步:增加一个hidden layer
。。。。。。
就是一步又一步增加你模型的复杂度,然后在某一步出现bug了就知道bug出现在这里,排错,然后接着增加复杂度,再排错,直到恢复到原来的模型为止。
4.Parameter initialization
parameter initialization也很有讲究,由于DL的node太多复杂度很高,所以一不小心就优化到local optimum里了。还容易使得初始值在一大段“高原”附近,优化时间就会很长。parameters也不能是对称的否则往上一层输出的结果就会太相似,无法进行优化。
综合以上考虑,还有实际经验,初始化parameters应当选用uniform distribution(uniform(-r, r)),当non-linear function是sigmoid function的时候 r = sqrt(6 / fan-in + fan-out),当non-linear function是tanh的时候 r = 4 * sqrt(6 / fan-in + fan-out)其中fan-in和fan-out是当前layer的之前layer的size和之后的layer的size。
5.Learning rates
learning rates不能太大,太大容易over shooting太小的话训练速度太慢。
有一个方法就是 epsilon_t = epsilon_0 * period / max(t, period)超过period的时候epsilon_t就会随着时间减小。
另一个方法更神奇,不同的parameter有不同的learning rate,这个参数之前更新的梯度之和很大则learning rate就小,反之则大
实现方法就是用一个数组记录下所有这个参数之前使用过的梯度,这次的learning rate = fixed number / sqrt(sum(all gradients used before))
6.Prevent overfitting
防止overfitting的出现的方法很多常用的有四种:1.降低模型的复杂度,减少模型每层的unit数量,或者直接减少layers 2.使用weight decay常用的就是L1 and L2 regularization on weights 3.训练到一定程度就停止,使用有最佳validation error的parameters 4.sparsity contraints on hidden activations这个方法我在auto-encoder里见到过
7.Recurrent Neural network language model
这一课里对RNN的介绍很简单就说了,这个模型叫recurrent是因为里面的parameters是recurrent使用的,有啥好处也没介绍 - -
期待下一课详细讲解