【今日CV 计算机视觉论文速览 第125期】Wed, 5 Jun 2019
今日CS.CV 计算机视觉论文速览
Wed, 5 Jun 2019
Totally 57 papers
?上期速览✈更多精彩请移步主页

Interesting:
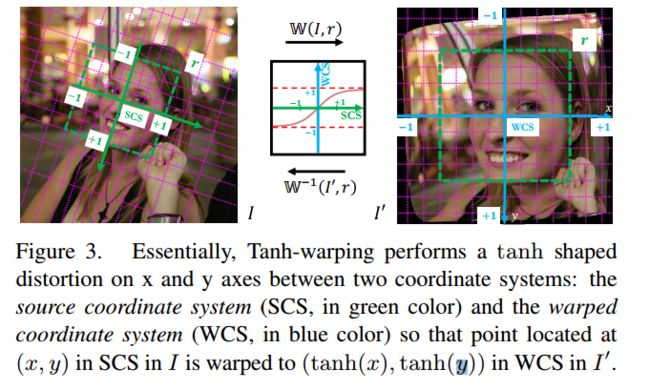
?基于ROI正切变形的人脸分析, 人脸分析是为人脸不同区域给出像素级的语义map,传统基于剪切调整大小的方法忽略了ROI区域外的特征,这对于不可预测区域不合适。这篇文章提出了一种基于正切-变形的操作子来结合中心视觉和外围视觉,解决了ROI区域集中和外围区域的周边信息的矛盾,研究人员提出了一种层级化局域方法,用于脸内区域特征,和全局方法用于外围特征。(from 厦门大学 微软)
Tanh-warping operator 操作,将图像(±1为ROI区域)映射基于SCS坐标系到WCS空间(±1为全图区域)中,将任意大小的图像通过引导*roi映射到有限的区域内。这种方法有效保留了外围信息::
网络架构如下,首先进行变换,随后对变化后的图像特征用于局域的面部分析和全局的周围区域分析,最后重新变换回去得到人脸分析结果:

手工修正了HELEN数据集2972张:

输出结果:
dataset:HELEN dataset,LFW-PL
ref:https://github.com/zhfe99/helen http://www.ifp.illinois.edu/~vuongle2/helen/
脸内:a Mask R-CNN-fashion [9]
脸外:a FCN-fashion [19] branch
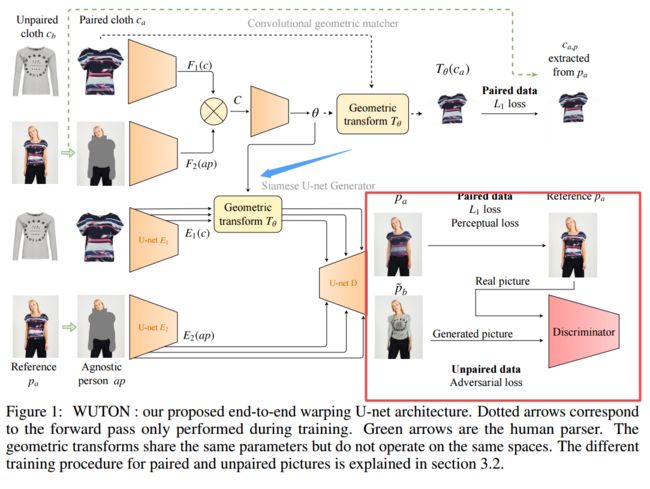
?***WUTON:基于几何形变特征图的虚拟试衣服, 基于孪生U-Net的生成器,包含一系列调节层来实现形变和卷积几何匹配,可以用多任务损失来训练,并可以利用真实的空间变化来生成高质量的合成服装图像。(from Criteo AI Lab Paris, France)
一些结果:

消融测试:

dataset:dataset from [7], CP-VTON 2[6], Image-based Multi-pose Virtual try-on dataset3 from MG-VTON [7], parse pose
lab:https://ailab.criteo.com/
?照片的自动编码用于从无标签图像中学习三维目标, 简单的基于重建来构建对称的形状和反射率,输入任意视角的单张图像模型可预测出对称的正视视角和对应的3D外形。(from VGG 牛津)

得到的一些结果如下图:

dataset:3DFAW, Soumyadip Sengupta code to generate synthetic face datasets
ref:
sfsNet: https://github.com/senguptaumd/SfSNet
nature render:https://github.com/daniilidis-group/neural_renderer
?****GANs的总结综述, 针对GAN的三个问题,高质量图像生成、多样性图像生成和稳定的训练展开,从架构和损失出发来研究各个研究如何处理上述上个问题。综述了7个架构和9中损失变体。(from 都柏林城市大学)

link:https://github.com/sheqi/GAN_Review
?***针对特定区域的字符选择性风格化, 探索了图像风格迁移在字符上的应用,包括路牌、印刷体和手写体,并提出了两种架构来实现选择区域迁移。(from Centre Tecnologic de Catalunya,Unitat de Tecnologies Audiovisuals巴塞罗那)
不同字体的迁移显示效果:

两种不同的架构,两阶段和单阶段,双阶段利用TextFCN计算了文字区域的热力图,并利用热力图权重来融合原始图与风格图:
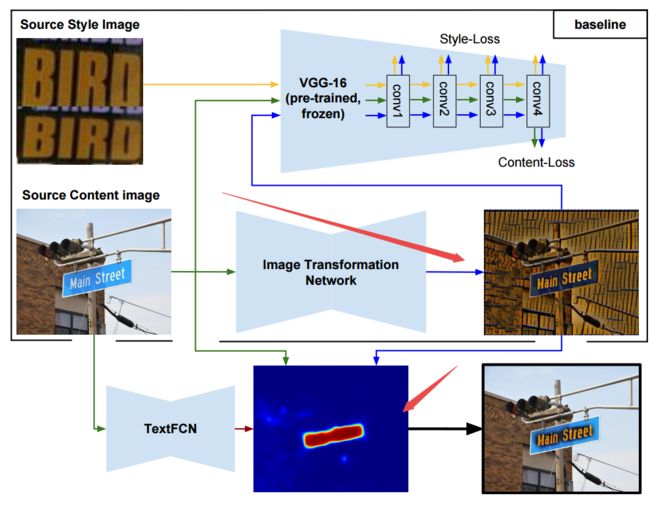
单阶段的方法利用实现计算的掩膜来训练模型只对特定区域计算,融合了字符检测和风格化方法。

基于手写分割和标签风格的文字效果迁移:


code:https://github.com/furkanbiten/SelectiveTextStyleTransfer
ref:文字区域检测TextFCN
TL;DwR
??DIPNet 深度图像先验的图像盲去噪,包含了全局(学习不同噪声水平的域不变特征)和局部(去噪图像向真实图像流型靠近)特征的融合,H-divergence theory
基于步态检测健康状况,code
KarNet用于简化数字电路的布尔表达式,ref method:Quine-McCluskey algorithm,
Karnaugh map solving, Petrick’s method and McBoole’s method
基于内容表示来迭代实现图像压缩,保持模型不变,dataset:Netflix-4K, xiphdataset
动力学神经网络架构解耦方法,从每张输入中发下网络动态激活的分层path
Triangulation Learning Network从单目到立体3D 目标检测,3Dbbox
?适应场景中心目标的风格迁移方法,基于生成的重要性map来进行不同强度的风格化,生成map的方法:patch-based, segmentation-based and superpixel-based
?保留内容图像的深度图的实时任意风格迁移,生成图更和谐, ref:AdaIN method of Huang et al
基于高斯过程和凸度分析解决(剪影图像中的)重叠凸物体,数据集来自透射电镜下的纳米粒子
Mining YouTube细粒度的动作概念数据集,基于监督的学习,基于烹调视频,数据集来自于foodnetwork, allrecipes
PhotoBook Dataset基于视觉的对话数据集,dataset:https://dmg-photobook.github.io/, ref NLTK, gensim 人类话题模型
解释深度学习成功和不稳定性的原因: 模型学习到了false structures
太阳动力学观测数据集,ref Solar Dynamics Observatory dataset, code2
ReColorAdv,基于函数对抗的攻击样本生成,单一函数生成对抗样本
Daily Computer Vision Papers
| Scene Representation Networks: Continuous 3D-Structure-Aware Neural Scene Representations Authors Vincent Sitzmann, Michael Zollh fer, Gordon Wetzstein 深度学习的出现催生了神经场景表示学习3D环境的数学模型。然而,这些表示中的许多表示没有明确地推断几何,因此不考虑场景的基础3D结构。相比之下,几何深度学习已经探索了场景几何的3D结构感知表示,但需要明确的3D监督。我们提出了场景表示网络SRN,一种连续的,3D结构感知的场景表示,它对几何和外观进行编码。 SRN将场景表示为连续函数,将世界坐标映射到局部场景属性的要素表示。通过将图像形成公式化为可微分射线行进算法,SRN可以仅从2D观察到端到端训练,而无需访问深度或几何。这个公式自然地概括了场景,在过程中学习强大的几何和外观先验。我们通过评估SRN的新颖视图合成,少量镜头重建,关节形状和外观插值以及非刚性面部模型的无监督发现来展示SRN的潜力。 |
| Dominant Set Clustering and Pooling for Multi-View 3D Object Recognition Authors Chu Wang, Marcello Pelillo, Kaleem Siddiqi 基于视图的3D对象识别策略已被证明非常成功。现有技术的方法现在在外观图像上实现了超过90个正确的类别级别识别性能。我们通过引入基于优势集的视图聚类和池化层来改进这些方法。关键思想是从相似的视图中汇集信息,从而属于同一个集群。然后,以循环方式将合并的特征向量作为输入馈送到同一层。这种经常性的聚类和汇集模块,当插入现成的预训练CNN时,可提高多视图3D对象识别的性能,在ModelNet 40数据库上实现93.8的最新测试集识别精度。我们还探索了一种快速近似学习策略,用于我们的集群CNN,它在牺牲端到端学习的同时,大大提高了其训练效率,只是将识别准确度略微降低到93.3。我们的实施可在 |
| Photo-Geometric Autoencoding to Learn 3D Objects from Unlabelled Images Authors Shangzhe Wu, Christian Rupprecht, Andrea Vedaldi 我们表明,生成模型可用于统计捕获视觉几何约束。我们使用此事实从原始单视图图像推断对象类别的3D形状。与以前的工作不同,我们不使用外部监督,也不使用对象的多个视图或视频。我们通过简单的重建任务来实现这一目标,利用物体形状和反照率的对称性。具体地,给定从任意视点看到的对象的单个图像,我们的模型预测对称规范视图,相应的3D形状和视点变换,并且以重建输入视图为目标进行训练,类似于自动编码器。我们的实验表明,这种方法可以在没有监督的情况下从单视图图像中恢复人脸,猫脸和汽车的3D形状。在基准测试中,与在2D图像对应水平上使用监督的其他方法相比,我们表现出更高的准确性。 |
| Disentangling neural mechanisms for perceptual grouping Authors Junkyung Kim, Drew Linsley, Kalpit Thakkar, Thomas Serre 在视觉场景中形成感知群体和个体化对象是迈向视觉智能的重要一步。这种能力被认为是通过神经元之间自下而上,水平和自上而下连接实现的计算在大脑中产生的。然而,这些联系对感知分组的相对贡献却知之甚少。我们通过系统地评估神经网络架构来解决这个问题,这些架构以两个合成视觉任务的这些连接组合为特征,这两个视觉任务强调低级格式塔与高级对象线索的感知分组。我们表明,增加任务的压力难度,学习仅依靠自下而上处理的网络。水平连接通过支持活动的增量空间传播来解决对具有完形符提示的任务的限制,而自上而下连接通过传播关于目标对象的位置的粗略预测来挽救对具有对象提示的任务的学习。我们的发现解除了自下而上,横向和自上而下连接的计算角色,并展示了具有所有这些相互作用的模型如何更灵活地学习形成感知群体。 |
| Learning Rotation Adaptive Correlation Filters in Robust Visual Object Tracking Authors Litu Rout, Priya Mariam Raju, Deepak Mishra, Rama Krishna Sai Subrahmanyam Gorthi 视觉对象跟踪是计算机视觉领域的主要挑战之一。相关滤波器CF跟踪器是跟踪中使用最广泛的类别之一。虽然目前有许多基于CF的跟踪算法可用,但是大多数跟踪算法都无法在动态变化的对象外观的无约束环境中有效地检测对象。为了应对这些挑战,现有策略通常依赖于一组特定的算法。在这里,我们提出了一个强大的框架,提供了在标准的判别相关滤波器DCF公式中结合照明和旋转不变性的规定。我们还通过消除卷积响应图中的误报来监督DCF跟踪器的检测阶段。此外,我们证明了置换一致性对CF跟踪器的影响。通过将我们的贡献整合到两个最先进的CF跟踪器SRDCF和ECO中来说明所提出的框架的一般性和效率。根据VOT2016数据集的综合实验,我们的顶级跟踪器在稳健性方面显示出14.7和6.41的显着改善,平均预期重叠AEO分别比基线SRDCF和ECO大11.4和1.71。 |
| Natural Vocabulary Emerges from Free-Form Annotations Authors Jordi Pont Tuset, Michael Gygli, Vittorio Ferrari 我们提出了一种使用由无向和未经训练的注释器编写的自由格式文本来注释对象类的方法。自由形式标签对于注释者来说是很自然的,它们直观地提供非常具体和详尽的标签,并且不需要培训阶段。我们首先使用124种不同的注释器在15k图像上收集729个标签。然后我们通过发现其中4020个类的自然词汇,自动丰富这些自由形式注释的结构。这个词汇表代表了对象的自然分布,直接从数据中学习,而不是在收集任何标签之前进行有根据的猜测。因此,自然词汇来自大量自由形式的注释。为此,我们将原始输入字符串映射到物理对象本体中的实体,这使得它们具有明确的含义,并且可以利用注释器之间的共同发生,以及特定于各个注释器的偏见和知识。最后,我们还自动提取尺寸缩小的自然词汇表,这些词汇表具有高对象覆盖率,同时保持特定。这些简化的词汇表代表了对象的自然分布,比常用的预定义词汇表要好得多。此外,它们在类别上具有更均匀的样本分布。 |
| Localization in Aerial Imagery with Grid Maps using LocGAN Authors Haohao Hu, Junyi Zhu, Sascha Wirges, Martin Lauer 在这项工作中,我们提出了LocGAN,我们基于地理参考航空图像和LiDAR网格图的定位方法。目前,大多数自定位方法将当前传感器观察与从先前采集的数据生成的地图相关联。不幸的是,这些数据并不总是可用,生成的地图通常是传感器设置特定的。全球导航卫星系统GNSS可以克服这个问题。然而,由于多路径和阴影效应,它们并不总是可靠的,尤其是在城市地区。由于航拍图像通常可用,我们可以将其用作先验信息。为了使航拍图像与网格图匹配,我们使用条件生成对抗网络cGAN将空中图像转换为网格图域。使用定位网络LocNet估计预测和测量的网格图之间的转换。给定地理参考航空图像变换,可以估计车辆姿态。对德国卡尔斯鲁厄地区记录的数据进行的评估表明,我们的LocGAN方法提供了可靠的全球定位结果。 |
| Visual Tree Convolutional Neural Network in Image Classification Authors Yuntao Liu, Yong Dou, Ruochun Jin, Peng Qiao 在图像分类中,卷积神经网络CNN模型随着深度学习的快速发展而取得了很高的性能。但是,图像数据集中的某些类别比其他类别更难区分。提高这些混淆类别的分类准确性有利于整体表现。在本文中,我们基于混淆的语义级别信息构建了混淆视觉树CVT,以识别混淆的类别。通过CVT提供的信息,我们可以引导CNN培训程序更加关注这些混淆的类别。因此,我们提出了基于我们的CVT嵌入的原始深CNN的Visual Tree卷积神经网络VT CNN。我们在基准数据集CIFAR 10和CIFAR 100上评估我们的VT CNN模型。在我们的实验中,我们建立了3种不同的VT CNN模型,它们分别比基于CNN的模型获得了1.36,0.89和0.64的改进。 |
| Cross-Domain Cascaded Deep Feature Translation Authors Oren Katzir, Dani Lischinski, Daniel Cohen Or 近年来,由于DNN的出现和对抗性训练策略的推动,我们目睹了不成对的图像到图像翻译方法的巨大进步。然而,大多数现有方法侧重于样式和外观的转移,而不是形状转换。后一项任务具有挑战性,因为它具有错综复杂的非本地性质,需要额外的监督。我们通过降低预训练网络的深层来缓解这种情况,其中深层特征包含更多语义,并应用这些深层特征之间的转换。具体来说,我们利用VGG,这是一个分类网络,预先培训了大规模的语义监督。我们的翻译是以级联的,深入浅层的方式进行的,沿着深层特征层次,我们首先在编码图像的高级语义内容的最深层之间进行转换,然后转换为较浅的层,以较深层为基础。我们展示了我们的方法能够在不同的域之间进行转换,这些域表现出明显不同的形状。我们定性和定量地评估我们的方法,并将其与现有技术图像与图像翻译方法进行比较。我们的代码和训练有素的模型将可用。 |
| Text-based Editing of Talking-head Video Authors Ohad Fried, Ayush Tewari, Michael Zollh fer, Adam Finkelstein, Eli Shechtman, Dan B Goldman, Kyle Genova, Zeyu Jin, Christian Theobalt, Maneesh Agrawala 编辑会话头视频以更改语音内容或删除填充词是具有挑战性的。我们提出了一种基于其抄本编辑会话头视频的新方法,以产生真实的输出视频,其中扬声器的对话被修改,同时保持无缝的视听流,即没有跳跃切换。我们的方法通过音素,视位,3D脸部姿势和几何,每帧的反射,表情和场景照明自动注释输入的说话头视频。要编辑视频,用户必须仅编辑脚本,然后优化策略选择输入语料库的片段作为基础材料。对应于所选片段的注释参数被无缝地拼接在一起并用于产生中间视频表示,其中面部的下半部分用参数面部模型来呈现。最后,循环视频生成网络将该表示转换为与编辑的转录本匹配的逼真视频。我们展示了大量的编辑内容,例如单词的添加,删除和更改,以及令人信服的语言翻译和完整的句子合成。 |
| Automatic Health Problem Detection from Gait Videos Using Deep Neural Networks Authors Rahil Mehrizi, Xi Peng, Shaoting Zhang, Ruisong Liao, Kang Li 本研究的目的是开发一种使用深度神经网络DNN检测步态相关健康问题的自动系统。所提出的系统将患者视频作为输入并使用基于DNN的方法估计其3D身体姿势。我们的代码是公开的 |
| Selective Style Transfer for Text Authors Raul Gomez, Ali Furkan Biten, Lluis Gomez, Jaume Gibert, Mar al Rusi ol, Dimosthenis Karatzas 本文探讨了图像样式转移应用于文本维护原始转录的可能性。结果在不同文本域的场景文本,机器打印文本和手写文本以及交叉模态结果表明这是可行的,并且开放了不同的研究线。此外,提出了两种用于选择性样式转换的架构,这意味着将样式转换为仅期望的图像像素。最后,场景文本选择性样式转移被评估为扩展场景文本检测数据集的数据增强技术,从而提高文本检测器性能。我们对所述模型的实施是公开的。 |
| Reconstruct and Represent Video Contents for Captioning via Reinforcement Learning Authors Wei Zhang, Bairui Wang, Lin Ma, Wei Liu 在本文中,解决了用自然语言描述视频序列的视觉内容的问题。与之前主要利用视频内容提示进行语言描述的视频字幕工作不同,我们在一种新颖的编码器解码器重构器体系结构中提出了一种重建网络RecNet,它利用前向视频到句子和后向句子到视频流的视频流。具体地,编码器解码器组件利用前向流来基于编码的视频语义特征产生句子描述。随后提出两种类型的重建器以采用后向流并分别从局部和全局视角再现视频特征,利用由解码器生成的隐藏状态序列。此外,为了全面重建视频特征,我们建议将两种类型的重构器融合在一起。由编码器解码器组件产生的生成损失和由重建器引入的重建损失共同投入到以端对端方式训练所提出的RecNet中。此外,RecNet通过强化学习的CIDEr优化进行了微调,从而显着提升了字幕性能。基准数据集的实验结果表明,所提出的重构器可以一致地提高视频字幕的性能。 |
| Active Object Manipulation Facilitates Visual Object Learning: An Egocentric Vision Study Authors Satoshi Tsutsui, Dian Zhi, Md Alimoor Reza, David Crandall, Chen Yu 受婴儿视觉学习系统卓越能力的启发,最近的一项研究收集了儿童的第一人称图像,以分析他们收到的训练数据。我们进行了一项后续研究,调查了另外两个方向。首先,鉴于婴儿可以在没有太多监督的情况下快速学会识别新物体,即很少有镜头学习,我们限制了训练图像的数量。其次,我们研究儿童如何根据对象的手动操作来控制他们在学习期间接收的监督信号。我们的实验结果表明,手动操纵监督比没有手更好,即使有少量图像,趋势也是一致的。 |
| Semi- and Weakly-supervised Human Pose Estimation Authors Norimichi Ukita, Yusuke Uematsu 对于静止图像中的人体姿态估计,本文提出了三种半监督和弱监督学习方案。虽然卷积神经网络的最新进展使用监督训练数据改善了人体姿态估计,但我们的重点是探索半监督和弱监督方案。我们提出的方案最初从少量具有人体姿势注释的标准训练图像中学习用于姿势估计的传统模型。对于第一半监督学习方案,该传统姿势模型检测没有人类注释的训练图像中的候选姿势。根据这些候选姿势,分类器仅使用表示所有身体部位的配置的姿势特征来选择真正的阳性。通过在我们的第二和第三学习方案中提供给这些图像的动作标签来改进这些候选姿势估计和真正肯定姿势选择的准确性,所述学习方案是半监督和弱监督学习。虽然第一和第二学习方案仅选择与监督训练数据中的姿势类似的姿势,但是第三方案选择与任何监督姿势显着不同的更多真实正姿势。通过使用具有Dirichlet过程混合的离群姿势检测和贝叶斯因子的姿势聚类来实现该姿势选择。所提出的方案通过大规模人体姿势数据集进行验证。 |
| KarNet: An Efficient Boolean Function Simplifier Authors Shanka Subhra Mondal, Abhilash Nandy, Ritesh Agrawal, Debashis Sen 已经设计了许多方法,例如Quine McCluskey算法,卡诺图解决方案,Petrick方法和McBoole方法,以简化布尔表达式,以优化数字电路的硬件实现。然而,这些方法的算法实现是硬编码的,并且它们的计算时间也与表达式中涉及的minterms的数量成比例。在本文中,我们提出了KarNet,其中利用卷积神经网络通过捕获空间依赖性来模拟各种单元位置和值之间的关系的能力来解决卡诺图。为此,将卡诺图表示为图像信号,其中每个单元被视为像素。实验结果表明,KarNet的计算时间与minterms的数量无关,并且是基于规则的方法的百分之一到十分之一。 KarNet是一个学习系统,可以实现近百分之百的准确性,精确度和召回率。我们训练KarNet解决四个变量卡诺图,并且还表明类似的方法可以应用于具有更多变量的卡诺图。最后,我们展示了一种使用KarNet构建完全准确且计算速度快的系统的方法。 |
| State-aware Re-identification Feature for Multi-target Multi-camera Tracking Authors Peng Li, Jiabin Zhang, Zheng Zhu, Yanwei Li, Lu Jiang, Guan Huang 多目标多摄像机跟踪MTMCT旨在从一组摄像机捕获的视频中提取轨迹。最近,采用重新识别Re ID模型,MTMCT的跟踪性能得到显着提高。然而,由于目标的遮挡和方向变化,外观特征通常变得不可靠。在MTMCT中直接应用Re ID模型将遇到由遮挡引起的身份切换IDS和跟踪片段的问题。为解决这些问题,本文提出了一种新的跟踪框架。在该框架中,在Re ID模型中利用遮挡状态和方向信息,其中考虑了人体姿势信息。另外,采用所提出的融合跟踪特征的跟踪关联来处理片段问题。建议的跟踪器在多个摄像机硬序列上实现了81.3 IDF1,大大超过了所有其他参考方法。 |
| End-to-End Learning of Geometric Deformations of Feature Maps for Virtual Try-On Authors Thibaut Issenhuth, J r mie Mary, Cl ment Calauzennes 2D虚拟尝试任务最近引起了研究界的极大兴趣,因为它在网上购物中的直接潜在应用以及其固有的和未解决的科学挑战。该任务需要在人的图像上放置店铺布图像。这是非常具有挑战性的,因为它需要在保留其图案和特征的同时翘曲目标人物上的布料,并以逼真的方式与人物构成物品。由于像素级合成步骤或几何变换,现有技术模型产生具有可见伪像的图像。在本文中,我们为虚拟试用系统提出了WUTON Warping U网。它是一个连体U网发生器,其跳过连接由卷积几何匹配器进行几何变换。整个架构是端到端训练的,包括对抗性的多任务丢失。这使我们的网络能够生成并使用布料的真实空间变换来合成高视觉质量的图像。所提出的架构可以端到端地进行训练,并允许我们朝着细节保留和照片逼真的2D虚拟试穿系统前进。我们的方法通过视觉结果以及Learned Perceptual Image Similarity LPIPS指标优于当前的技术水平。 |
| Exploiting Offset-guided Network for Pose Estimation and Tracking Authors Rui Zhang, Zheng Zhu, Peng Li, Rui Wu, Chaoxu Guo, Guan Huang, Hailun Xia 由于深度学习的发展,人体姿势估计已经取得了重大进展。最近的人体姿势估计方法倾向于直接预测位置热图,这导致量化误差并且不可避免地使降低的网络输出内的性能恶化。为了解决这个问题,我们重新考虑了热图偏移聚合方法,并为偏移引导网络OGN提供了一个直观但有效的融合策略,用于两阶段姿态估计和掩模R CNN。对于两阶段姿势估计,还提出了贪婪的盒子生成策略以在执行人员检测时保留更多必要的候选者。对于掩模R CNN,采用比率一致来提高网络的泛化能力。 COCO和PoseTrack数据集的最新结果验证了我们的偏移引导姿态估计和跟踪的有效性。 |
| Face Parsing with RoI Tanh-Warping Authors Jinpeng Lin, Hao Yang, Dong Chen, Ming Zeng, Fang Wen, Lu Yuan 面部解析为面部图像中的不同语义成分(例如,头发,嘴巴,眼睛)计算像素明智的标签图。现有的面部解析文献通过关注面部和面部组件的各个感兴趣区域RoI来说明显着的优点。然而,传统的裁剪和调整大小的聚焦机制忽略了RoI之外的所有上下文区域,因此当组件区域不可预测时,例如,不适合。头发。受人类生理视觉系统的启发,我们提出了一种新颖的RoI Tanh整经操作器,它将中心视觉和周边视觉结合在一起。它解决了用于聚焦的有限大小的RoI与用于外围信息的周围环境的不可预测区域之间的困境。为此,我们提出了一种用于面部解析的新型混合卷积神经网络。它使用基于层次局部的方法用于内部面部组件和全局方法用于外部面部组件。整个框架简单而有原则,可以端到端地进行培训。为了便于将来对面部解析的研究,我们还手动重新标记HELEN数据集的训练数据并将其公开。在HELEN和LFW PL基准测试上的实验表明我们的方法超过了现有技术的方法。 |
| Color Constancy Convolutional Autoencoder Authors Firas Laakom, Jenni Raitoharju, Alexandros Iosifidis, Jarno Nikkanen, Moncef Gabbouj 在本文中,我们研究了预训练对颜色恒常问题中泛化能力的重要性。我们提出了两种基于卷积自动编码器的新方法,一种使用微调编码器的无监督预训练算法和一种使用新型复合损失函数的半监督预训练算法。这使我们能够解决数据稀缺问题,并在最先进的结果中实现竞争,同时在ColorChecker推荐数据集上需要更少的参数。我们在最近推出的用于相机不变色彩恒定性研究的INTEL TUT数据集版本中进一步研究了过度拟合现象,其具有由三种不同相机模型获得的场和非场景。 |
| Example-Guided Style Consistent Image Synthesis from Semantic Labeling Authors Miao Wang, Guo Ye Yang, Ruilong Li, Run Ze Liang, Song Hai Zhang, Peter. M. Hall, Shi Min Hu 示例性引导图像合成旨在从语义标签图和指示样式的示例性图像合成图像。我们在这个问题中使用术语风格来指代图像的隐含特征,例如在肖像风格中包括性别,种族身份,年龄,发型在全身图片中它包括街头场景中的服装,它指的是天气和时间以及这样的。这些情况下的语义标签图表示面部表情,全身姿势或场景分割。我们使用具有样式一致性的条件生成对抗网络提出了示例引导图像合成问题的解决方案。我们的关键贡献是一种新颖的风格一致性鉴别器,用于确定一对图像在风格上是一致的,一种是自适应语义一致性丢失,另一种是训练数据采样策略,用于将样式一致的结果合成到样本中。 |
| Towards better Validity: Dispersion based Clustering for Unsupervised Person Re-identification Authors Guodong Ding, Salman Khan, Zhenmin Tang, Jian Zhang, Fatih Porikli 人物识别旨在建立通过非重叠多摄像机装置移动的人的正确身份对应。基于该任务的深度学习模型的最新进展主要集中于监督学习场景,其中假设准确注释可用于每个设置。为人员识别注释大规模数据集是苛刻且繁琐的,这使得这种监督方法在现实世界应用中的部署是不可行的。因此,有必要在没有明确监督的情况下以自主方式训练模型。在本文中,我们提出了一种优雅实用的聚类方法,用于基于聚类有效性考虑的无人监督人员识别。具体而言,我们探索统计学中的基本概念,即emph离散,以实现稳健的聚类标准。当在集群内级别使用时,色散反映了集群的紧凑性,并且当在集群间级别进行测量时,显示了分离。通过这种洞察,我们设计了一种新的基于分散的聚类DBC方法,该方法可以发现数据中的基础模式。该方法考虑了样本级成对关系的更广泛的上下文,以实现稳健的聚类亲和力评估,其处理由于普遍的不平衡数据分布而可能出现的复杂性。此外,我们的解决方案可以自动确定独立数据点的优先级,并防止较差的群集。我们对图像和视频识别基准的广泛实验分析表明,我们的方法在很大程度上优于现有技术的无监督方法。代码可在 |
| Relational Reasoning using Prior Knowledge for Visual Captioning Authors Jingyi Hou, Xinxiao Wu, Yayun Qi, Wentian Zhao, Jiebo Luo, Yunde Jia 在利用自然语言解释图像或视频方面,利用对象之间的关系取得了显着进展。大多数现有方法首先检测对象及其关系,然后生成文本描述,这在很大程度上取决于预先训练好的检测器,并且在面对重度遮挡,微小尺寸物体和物体检测中的长尾问题时导致性能下降。另外,检测和字幕的单独过程导致预定义的对象关系类别和目标词汇词之间的语义不一致。我们利用先前的人类常识知识来推理对象之间的关系,而无需任何经过预先训练的检测器,并在一个图像或视频中达到语音一致性。例如,以知识图的形式的先验知识提供了在图像和视频中不明确的对象之间的常识语义相关和约束,用作构建用于句子生成的语义图的有用指导。特别地,我们提出了一种联合推理方法,其结合了用于将图像或视频区域嵌入到语义空间中的1个常识推理来构建语义图,以及用于编码语义图以生成句子的2个关系推理。对MS COCO图像字幕基准和MSVD视频字幕基准的广泛实验验证了我们的方法在利用先前的常识知识来增强视觉字幕的关系推理方面的优越性。 |
| Evaluation of an AI system for the automated detection of glaucoma from stereoscopic optic disc photographs: the European Optic Disc Assessment Study Authors Thomas W. Rogers, Nicolas Jaccard, Francis Carbonaro, Hans G. Lemij, Koenraad A. Vermeer, Nicolaas J. Reus, Sameer Trikha 目的评估基于深度学习的人工智能AI软件在立体视盘照片中检测青光眼的性能,并将该性能与大量眼科医师和验光师的表现进行比较。 |
| Visual Diagnosis of Dermatological Disorders: Human and Machine Performance Authors Jeremy Kawahara, Ghassan Hamarneh 皮肤状况是一个全球性的健康问题,按照因残疾而损失的年数来衡量,是非致命性疾病负担的第四大原因。作为诊断或分类,皮肤病可以帮助确定有效治疗,皮肤科医生已经广泛研究如何从病人的病史和病变的视觉外观诊断病情。计算机视觉研究人员正在尝试将这种诊断能力编码到机器中,最近的几项研究报告了与皮肤科医生相当的机器水平性能。 |
| Content Adaptive Optimization for Neural Image Compression Authors Joaquim Campos, Meierhans Simon, Abdelaziz Djelouah, Christopher Schroers 神经图像压缩领域已经见证了令人兴奋的进展,因为最近提出的架构已经超越了已建立的基于变换编码的方法。虽然到目前为止,研究主要集中在架构和模型改进上,但在这项工作中我们探索了内容自适应优化。为此,我们引入了一个迭代过程,该过程使潜在表示适应我们希望压缩的特定内容,同时保持网络参数和预测模型的固定。我们的实验表明,这可以使速率失真性能整体提高,与所使用的特定架构无关。此外,我们还在将预训练网络适应视觉外观或分辨率不同的其他内容的背景下评估此策略。在这里,我们的实验表明,与专门针对给定内容训练的模型相比,我们的适应策略可以在很大程度上缩小差距,同时具有不必传输模型参数更新形式的附加数据的益处。 |
| Triangulation Learning Network: from Monocular to Stereo 3D Object Detection Authors Zengyi Qin, Jinglu Wang, Yan Lu 在本文中,我们研究立体图像中的三维物体检测问题,其中关键的挑战是如何有效地利用立体信息。与使用像素级深度图的先前方法不同,我们提出使用3D锚来明确地构建立体图像中的感兴趣区域之间的对象级对应,深度神经网络从中学习以在3D空间中检测和三角化目标对象。我们还引入了一种具有成本效益的通道重新加权策略,该策略可增强代表性功能并减弱噪声信号,从而促进学习过程。所有这些都灵活地集成到使用单眼图像的固体基线检测器中。我们证明单眼基线和立体三角测量学习网络在具有挑战性的KITTI数据集的3D对象检测和定位方面优于现有技术水平。 |
| Dynamic Neural Network Decoupling Authors Yuchao Li, Rongrong Ji, Shaohui Lin, Baochang Zhang, Chenqian Yan, Yongjian Wu, Feiyue Huang, Ling Shao 卷积神经网络CNN通过利用复杂的网络架构和大量参数获得了优越的性能,然而这些参数变得无法解释并且挑战它们在实际应用中的全部潜力。为了更好地理解网络决策背后的基本原理,我们提出了一种新颖的架构解耦方法,该方法动态地发现由每个输入图像的激活滤波器组成的分层路径。具体地,在每层中引入架构控制模块以编码网络架构并识别对应于特定输入的激活滤波器。然后,最大化架构编码和输入图像的属性之间的互信息以解耦网络架构,并且随后通过在训练期间限制滤波器的输出来解开滤波器。大量实验表明,基于所提出的架构解耦,即解释,加速和对抗攻击,已经实现了若干优点。 |
| Transfer Learning with intelligent training data selection for prediction of Alzheimer's Disease Authors Naimul Mefraz Khan, Marcia Hon, Nabila Abraham 通过机器学习从诸如MRI的神经成像数据检测阿尔茨海默氏病AD近年来已成为一项深入研究的主题。最近在计算机视觉中深度学习的成功进一步推动了这种研究。然而,这种算法的共同限制是依赖于大量训练图像,并且需要仔细优化深度网络的体系结构。在本文中,我们尝试通过转移学习来解决这些问题,其中使用来自由自然图像组成的大型基准数据集的预训练权重来初始化最先进的VGG架构。然后通过分层调谐对网络进行微调,其中仅在MRI图像上训练预定义的一组层。为了缩小训练数据大小,我们使用图像熵来选择信息量最大的切片。通过对ADNI数据集的实验,我们发现训练大小比其他现代方法小10到20倍,我们达到了AD与NC,AD与MCI以及MCI与NC分类问题的最新技术性能。 ,相对于AD与MCI和MCI与NC的现有技术水平相比,精度分别提高了4和7。我们还详细分析了智能训练数据选择方法的效果,改变训练大小,以及改变要微调的层数。最后,我们提供了类激活图CAM,它演示了所提出的模型如何关注与神经病理相关的辨别图像区域,并且可以帮助医疗从业者解释模型的决策过程。 |
| Learning Object Bounding Boxes for 3D Instance Segmentation on Point Clouds Authors Bo Yang, Jianan Wang, Ronald Clark, Qingyong Hu, Sen Wang, Andrew Markham, Niki Trigoni 我们提出了一种新颖的,概念上简单的通用框架,用于3D点云的实例分割。我们的方法称为3D BoNet,遵循每点多层感知器MLP的简单设计理念。该框架直接回归点云中所有实例的3D边界框,同时预测每个实例的点级掩码。它由一个骨干网络和两个并行网络分支组成,用于1个边界框回归和2个点掩模预测。 3D BoNet是单级,无锚和端对端训练。此外,它具有显着的计算效率,因为与现有方法不同,它不需要任何后处理步骤,例如非最大抑制,特征采样,聚类或投票。大量实验表明,我们的方法超越了ScanNet和S3DIS数据集上的现有工作,同时计算效率提高了约10倍。全面的消融研究证明了我们设计的有效性。 |
| Style Transfer With Adaptation to the Central Objects of the Scene Authors Alexey Schekalev, Victor Kitov 风格转移是使用另一图像的样式呈现具有一些内容的图像的问题,例如以一些着名艺术家的绘画风格的家庭照片。经典样式转移算法的缺点在于它在内容图像的所有部分上均匀地赋予样式,这扰乱了内容图像上的中心对象,例如面部或文本,并使它们变得不可识别。这项工作提出了一种新颖的风格转移算法,它自动检测内容图像上的中心对象,生成空间重要性掩模和强制风格非均匀中心对象的风格化较少,以保持其可识别性,图像的其他部分像往常一样风格化,以保持风格。提出了三种自动中心物体检测方法,并通过用户评估研究定性评估。与传统的样式转移方法相比,两种比较都表现出更高的程式化质量。 |
| Depth-Preserving Real-Time Arbitrary Style Transfer Authors Konstantin Kozlovtsev, Victor Kitov 样式转移是使用另一个图像的样式呈现一个具有某些内容的图像的过程,表示该样式。 Liu等人最近的研究。 2017年通过调整Gatys等人的传统方法,显示出风格转移渲染质量的显着提高。 2016年和约翰逊等人。 2016年使用正规化器,强制保留内容图像的深度图。然而,这些传统方法要么计算效率低,要么需要为新风格训练单独的神经网络。 Huang等人的AdaIN方法。 2017允许有效传输任意风格而无需训练单独的模型,但无法再现内容图像的深度图。我们建议对此方法进行扩展,以允许深度图保留。定性分析和用户评估研究结果表明,与Gatys等人的原始样式转移方法相比,所提出的方法提供了更好的样式。 2016年和黄等人。 2017年。 |
| Random Path Selection for Incremental Learning Authors Jathushan Rajasegaran, Munawar Hayat, Salman Khan, Fahad Shahbaz Khan, Ling Shao 增量终身学习是人工智能的长期目标的主要挑战。在现实生活中,学习任务按顺序到达,机器学习模型必须不断学习增加已获得的知识。现有的增量学习方法远低于同时使用所有培训课程的现有累积模型。在本文中,我们提出了一种称为RPSnet的随机路径选择算法,该算法逐步为新任务选择最佳路径,同时鼓励参数共享和重用。我们的方法避免了计算上昂贵的基于演化和强化学习的路径选择策略所带来的开销,同时实现了可观的性能提升。作为一个额外的新颖性,所提出的模型将知识蒸馏和回顾与路径选择策略相结合,以克服灾难性遗忘。为了保持先前和新获得的知识之间的平衡,我们提出了一个简单的控制器来动态平衡模型的可塑性。通过大量实验,我们证明了所提出的方法超越了增量学习的现有技术性能,并且通过利用并行计算,该方法可以在恒定时间内运行,具有与传统深度卷积神经网络几乎相同的效率。 |
| Resolving Overlapping Convex Objects in Silhouette Images by Concavity Analysis and Gaussian Process Authors Sahar Zafari, Mariia Murashkina, Tuomas Eerola, Jouni Sampo, Heikki K lvi inen, Heikki Haario 重叠凸起物体的分割具有各种应用,例如,纳米颗粒和细胞成像。通常,分割方法必须完全依赖于背景和前景之间的边缘,使得分析的图像基本上是轮廓图像。因此,为了分割对象,该方法需要能够通过利用关于对象形状的先验信息来解决多个对象之间的重叠。本文介绍了一种在轮廓图像中分割成簇的部分重叠凸面物体的新方法。所提出的方法涉及预处理,轮廓证据提取和轮廓估计三个主要步骤。通过检测凹点从二值化图像中恢复轮廓线段开始轮廓证据提取。此后,将属于相同对象的轮廓段分组。分组被公式化为组合优化问题,并使用分支定界算法求解。最后,通过高斯过程回归方法估计物体的完整轮廓。在由纳米粒子组成的具有挑战性的数据集上的实验表明,所提出的方法在重叠凸对象分割中优于三种当前的现有技术方法。该方法仅依赖于边缘信息,并且可以应用于对象部分重叠且具有凸形状的任何分割问题。 |
| A Hybrid RNN-HMM Approach for Weakly Supervised Temporal Action Segmentation Authors Hilde Kuehne, Alexander Richard, Juergen Gall 在过去十年中,行动认可已成为一个快速发展的研究领域。但随着对大规模数据的需求不断增加,手工注释数据对培训的需求变得越来越不切实际。避免基于帧的人类注释的一种方法是使用动作命令信息来学习相应的动作类。在这种情况下,我们提出了一种分层方法,通过以粗略到精细的方式构造识别来解决从有序动作标签中对人类行为进行弱监督学习的问题。给定一组视频和发生的动作的有序列表,任务是推断视频内的相关动作类的开始和结束帧并训练相应的动作分类器而不需要手标记的帧边界。我们通过将帧式RNN模型与粗略概率推理相结合来解决该问题。该组合允许长序列的时间对准,并因此允许两个元素的迭代训练。虽然这个系统本身已经产生了良好的结果,但我们表明,通过将子动作的数量近似到不同动作类别的特征以及引入正则化长度先验,可以进一步提高性能。所提出的系统在两个基准数据集上进行评估,即早餐和好莱坞扩展数据集,显示在各种弱学习任务(如时间动作分割和动作对齐)上的竞争性表现。 |
| Mining YouTube - A dataset for learning fine-grained action concepts from webly supervised video data Authors Hilde Kuehne, Ahsan Iqbal, Alexander Richard, Juergen Gall 到目前为止,动作识别主要集中在手选所选预切割动作的分类问题,并在该领域取得了令人瞩目的成果。但是,由于当前数据集的性能甚至上限,该领域的后续步骤似乎必须超出这种完全监督的分类。克服这些问题的一种方法是采用不太受限制的方案。在这种情况下,我们提出了一个大规模的现实世界数据集,旨在评估除手工制作的数据集之外的人类行为识别的学习技术。为此,我们再次收集数据的过程,并从250个烹饪视频测试集的注释开始。然后通过搜索免费可用视频的字幕内的相应注释类来收集训练数据。数据集的独特性归因于收集数据和培训的整个过程不涉及任何人为干预。为了解决这种训练数据引起的语义不一致问题,我们进一步提出了挖掘类的语义层次结构。 |
| Comparing two- and three-view Computer Vision Authors Zsolt Levente Kucsv n 为了重建三维空间中的点,我们需要至少两个图像。在本文中,我们比较了两种不同的方法,第一种只使用两种图像,第二种使用三种。在研究期间,我们测量了相机分辨率,相机角度和相机距离如何影响重建点的数量和它们的分散。本文提出使用两种视图方法,我们可以比使用另一种方法重建更多的点,但是如果我们使用三视图方法,则点的离散度更小。考虑到不同的摄像机设置,我们可以说两个和三个视图方法的行为相同,两个方法的最佳参数也相同。 |
| Evaluating Scalable Bayesian Deep Learning Methods for Robust Computer Vision Authors Fredrik K. Gustafsson, Martin Danelljan, Thomas B. Sch n 虽然深度神经网络DNN已成为计算机视觉中的一种方法,但绝大多数这些模型未能正确捕捉其预测中固有的不确定性。估计这种预测不确定性可能至关重要,例如在汽车应用中。在贝叶斯深度学习中,预测不确定性通常被分解为不同类型的任意和认知不确定性。前者可以通过让DNN输出概率分布的参数来估计。认知不确定性估计是一个更具挑战性的问题,虽然最近出现了不同的可扩展方法,但在现实世界环境中尚未进行全面的比较。因此,我们接受此任务并提出预测不确定性评估的评估框架,该框架专门用于测试现实世界计算机视觉应用中所需的稳健性。使用所提出的框架,我们对深度完成和街道场景语义分割任务的流行集成和MC丢失方法进行了广泛的比较。我们的比较表明,集成一致性提供了更可靠的不确定性估计。代码可在 |
| GAMMA: A General Agent Motion Prediction Model for Autonomous Driving Authors Yuanfu Luo, Panpan Cai 混合交通中的自动驾驶需要对附近的交通代理(例如行人,自行车,汽车,公共汽车等)进行可靠的运动预测。由于交通代理的动态和几何形状,复杂的道路状况和密集的交互作用,这种预测问题极具挑战性。它们之间。在本文中,我们提出了GAMMA,一种用于自动驾驶的通用代理运动预测模型,可以预测具有不同运动学,几何学等的异构交通代理的运动,并通过推断人类代理内部状态来生成多个轨迹假设。 GAMMA将运动预测正式化为速度空间中的几何优化问题,并将物理约束和人类内部状态集成到这个统一的框架中。我们的研究结果表明,GAMMA在不同的真实世界数据集上显着优于传统和深度学习方法。 |
| The PhotoBook Dataset: Building Common Ground through Visually-Grounded Dialogue Authors Janosch Haber, Tim Baumg rtner, Ece Takmaz, Lieke Gelderloos, Elia Bruni, Raquel Fern ndez 本文介绍了PhotoBook数据集,这是一个大规模的英语视觉基础,任务导向对话集合,旨在调查在会话期间累积的共享对话历史。从对话分析的开创性工作中汲取灵感,我们提出了一种数据收集任务,其被制定为协作游戏,促使两个在线参与者利用他们的视觉上下文以及先前建立的引用表达来参考图像。我们提供了任务设置的详细描述,并对收集的2,500个对话进行了全面分析。为了进一步说明数据集的新特征,我们提出了一个参考分辨率的基线模型,它使用一种简单的方法来考虑参考链中累积的共享信息。我们的结果表明,这些信息对于解决后面的描述特别重要,并强调需要在对话互动中开发更复杂的共同点模型。 |
| Generative Adversarial Networks: A Survey and Taxonomy Authors Zhengwei Wang, Qi She, Tomas E. Ward 生成对抗性网络GAN在过去几年中得到了广泛的研究。可以说,革命性技术属于计算机视觉领域,如合理的图像生成,图像到图像的转换,面部属性操作和类似的领域。尽管在计算机视觉领域取得了显着成功,但将GAN应用于现实世界的问题仍然存在三个主要挑战:1高质量图像生成2多样化图像生成和3个稳定培训。考虑到文献中的大量GAN相关研究,我们提供了一个关于体系结构变体和损失变体的研究,它们被提出从两个角度处理这三个挑战。我们提出了用于对大多数流行GAN进行分类的损耗和体系结构变体,并着重于这两个方面来讨论潜在的改进。虽然已经提出了针对GAN的若干评论,但是没有关于基于上述处理挑战的GAN变体的评论的工作。在本文中,我们回顾并批判性地讨论了7种架构变体GAN和9种损失变体GAN,以弥补这三个挑战。本次审查的目的是提供对当前GAN研究侧重于绩效改进的足迹的见解。本文总结了与本研究中研究的GAN变体相关的代码 |
| PCA-driven Hybrid network design for enabling Intelligence at the Edge Authors Indranil Chakraborty, Deboleena Roy, Isha Garg, Aayush Ankit, Kaushik Roy 最近IOT的出现增加了在包括医疗监测系统,自动驾驶车辆等在内的若干应用中实现基于AI的边缘计算的需求。这使得必须在计算和存储方面寻求神经网络的有效实现。虽然极端量化已被证明是在全精度网络上实现显着压缩的强大工具,但它可能导致复杂图像分类任务的性能显着下降。在这项工作中,我们提出了一种主成分分析PCA驱动方法来设计混合精度混合网络。与使用PCA降低维数的标准实践不同,我们利用PCA识别二进制网络中的重要层,通过增加重要维度的数量来对输入数据进行相关转换。随后,我们提出了混合网络,这是一种网络,其具有增加的二进制网络中重要层的权重和激活的比特精度。我们表明,与二进制网络相比,所提出的混合网络在分类精度方面实现了10多项改进,例如CIFAR 100和ImageNet数据集上的XNOR Net for ResNet和VGG架构,同时仍然实现了XNOR网络的高达94的能效。所提出的设计方法允许我们通过保持一半以上的网络二进制来更接近标准全精度网络的准确性。这项工作展示了一种有效的一次性方法,用于设计混合,混合精密网络,显着提高二进制网络的分类性能,同时获得显着的压缩。所提出的混合网络进一步提高了在基于IOT的边缘设备中使用高度压缩的神经网络进行节能神经计算的可行性。 |
| What do AI algorithms actually learn? - On false structures in deep learning Authors Laura Thesing, Vegard Antun, Anders C. Hansen 人工智能中有两个未解决的大数学问题AI 1为什么深度学习在分类问题上如此成功?2为什么基于深度学习的神经网络同时普遍不稳定,其中不稳定性使网络容易受到对抗性攻击。我们提出了这些问题的解决方案,可以用两个词来概括错误的结构。实际上,深度学习并不能学习人类在识别图像时使用的原始结构,猫有胡须,爪子,毛皮,尖耳朵等,而是与原始结构相关的不同假结构,从而产生成功。然而,与原始结构不同,假结构是不稳定的。假结构比原始结构更简单,因此更容易用更少的数据学习,并且训练中使用的数值算法将更容易地收敛到捕获错误结构的神经网络。我们正式定义了错误结构的概念,并将解决方案描述为一个猜想。鉴于经过训练的神经网络总是用近似值计算,这个猜想只能通过理论和计算结果的组合来建立,类似于在理论物理学中如何建立假设,例如:光速是恒定的。完全建立猜想需要一个庞大的研究程序来表征假结构。我们为这样一个在实践中确定虚假结构存在的程序提供了基础。最后,我们讨论了假结构存在对最先进的AI和Smale第18个问题的深远影响。 |
| What, Where and How to Transfer in SAR Target Recognition Based on Deep CNNs Authors Zhongling Huang, Zongxu Pan, Bin Lei 深度卷积神经网络DCNN最近在遥感中引起了广泛关注。与自然图像中的大规模注释数据集相比,遥感中缺少标记数据成为深入研究深度网络的障碍,特别是在SAR图像解译中。转移学习通过将源任务中的知识借用到目标任务,提供了解决此问题的有效方法。在光学遥感应用中,普遍的机制是微调在用大规模自然图像数据集(例如ImageNet)预训练的现有模型上。然而,由于SAR与光学图像之间的显着差异,该方案不能实现SAR应用的令人满意的性能。在本文中,我们试图讨论以前很少研究的三个问题,详细说明1哪些网络和源任务更好地转移到SAR目标,2哪个层转移特征更通用于SAR目标,3个如何有效地转移到SAR目标SAR目标识别。在此基础上,提出了一种基于域自适应的多源数据传递方法,以减少源数据与SAR目标之间的差异。在OpenSARShip上进行了几个实验。结果表明,自然图像中转移学习的普遍结论不能完全应用于SAR目标,分析SAR目标识别中的转移内容和位置有助于更有效地确定转移。 |
| Vision-Based Autonomous UAV Navigation and Landing for Urban Search and Rescue Authors Mayank Mittal, Rohit Mohan, Wolfram Burgard, Abhinav Valada 无人驾驶飞行器配备有生物雷达的无人机是一种挽救生命的技术,可以在地震或瓦斯爆炸等自然灾害发生后识别倒塌建筑物下的幸存者。然而,这些无人机必须能够在灾难环境中自主导航并落在碎片堆上,以便准确定位幸存者。这个问题极具挑战性,因为由于可能已经发生的结构变化而且现有的着陆点检测算法不适合识别碎片堆上的安全着陆区域,因此不能利用预先存在的地图进行导航。在这项工作中,我们提出了一个计算有效的自动无人机导航和着陆系统,不需要任何有关环境的先验知识。我们提出了一种新颖的着陆点检测算法,该算法基于几种危险因素计算成本映射,包括地形平坦度,陡度,深度精度和能耗信息。我们还引入了第一个合成数据集,其中包含超过120万个倒塌建筑物的图像,其中包括地面深度,表面法线,语义和相机姿态信息。我们使用来自城市规模超现实模拟环境的实验以及具有倒塌建筑物的现实场景来证明我们的系统的功效。 |
| Optimal Unsupervised Domain Translation Authors Emmanuel de B zenac, Ibrahim Ayed, Patrick Gallinari 域转换是在两个域之间找到有意义的对应关系的问题。由于在大多数设置中配对监督不可用,因此许多工作集中在无监督域转换UDT,其中来自每个域的数据样本未配对。继CycleGAN for UDT的开创性工作之后,已经提出了该模型的许多变体和扩展。然而,他们的成功背后仍然缺乏理论上的理解。我们观察到这些方法产生的溶液几乎是最小的w.r.t.给定的运输成本,导致我们重新制定最优运输OT框架中的问题。这一观点为我们提供了一个关于无监督域转换的新视角,并允许我们在给定大量运输成本的情况下证明检索到的映射的存在性和唯一性。然后,我们提出了一种新的框架,可以在动态环境中有效地计算最佳映射。我们展示它概括了以前的方法,并能够更加明确地控制计算出的最优映射。它还提供两个域之间的平滑插值。玩具和现实世界数据集上的实验说明了我们方法的行为。 |
| Information Competing Process for Learning Diversified Representations Authors Jie Hu, Rongrong Ji, ShengChuan Zhang, Xiaoshuai Sun, Qixiang Ye, Chia Wen Lin, Qi Tian 学习各种信息的陈述仍然是一个悬而未决的问题。为了学习多样化的表示,本文提出了一种称为信息竞争过程ICP的新方法。为了丰富特征表示所携带的信息,ICP将表示分成具有不同互信息约束的两个部分。分离的部分被迫在竞争环境中独立地完成下游任务,这阻止了两个部分学习彼此为下游任务学习的内容。然后将这些竞争部分协同组合以完成任务。通过融合在不同条件下竞争学习的代表性部分,ICP促进获得包含补充信息的多样化表示。图像分类和图像重建任务的实验证明了ICP在监督和自我监督学习环境中学习判别和解开表征的巨大潜力。 |
| Learning Deep Image Priors for Blind Image Denoising Authors Xianxu Hou, Hongming Luo, Jingxin Liu, Bolei Xu, Ke Sun, Yuanhao Gong, Bozhi Liu, Guoping Qiu 图像去噪是从噪声图像中去除噪声的过程,噪声图像是图像域转移任务,即,从单个或多个噪声级域到照片真实域。在本文中,我们通过从域对齐的角度学习两个图像先验,提出了一种有效的图像去噪方法。我们在两个层面上处理域对齐。在图1中,特征级别先验是学习具有不同水平噪声的损坏图像的域不变特征2,像素级先验用于将去噪图像推送到自然图像流形。这两个图像先验基于mathcal H发散理论,并通过对抗训练方式学习分类器来实现。我们评估我们在多个数据集上的方法。结果证明了我们的方法对合成和现实噪声图像的鲁棒图像去噪的有效性。此外,我们表明,特征级别先验能够减轻不同级别噪声之间的差异。它可用于在失真度量PSNR和SSIM方面提高盲去噪性能,而像素级先验可以有效地提高感知质量,以确保实际输出,这可以通过主观评估进一步验证。 |
| Knowledge is Never Enough: Towards Web Aided Deep Open World Recognition Authors Massimiliano Mancini, Hakan Karaoguz, Elisa Ricci, Patric Jensfelt, Barbara Caputo 虽然今天的机器人能够执行复杂的任务,但它们只能对已经训练过的物体进行识别。这是一个严重的限制,任何机器人都不可避免地会在无约束的环境中看到新物体,因此总是会有视觉知识空白。但是,标准可视化模块通常构建在一组有限的类上,并且基于强大的先于对象必须属于这些类之一。识别实例是否不属于已知类别集合(即开放集合识别),只能部分解决此问题,因为真正自主的代理不仅应该能够检测到它不知道的内容,还应该能够动态地扩展其知识。世界。我们通过深度学习架构为这一挑战做出贡献,该架构能够以端到端的方式动态更新其已知类。基于非参数模型的深度扩展,所提出的深度网络检测感知对象是否属于系统已知的类别集合并且无需从头开始重新训练整个系统来学习它。关于新类别的注释图像可以由oracle提供,即人工监督,或者通过Web的自主挖掘。在两个不同的数据库和机器人平台上进行的实验证明了我们的方法的前景。 |
| A Strong and Robust Baseline for Text-Image Matching Authors Fangyu Liu, Rongtian Ye 我们回顾了当前的文本图像匹配模型方案,并提出了培训和推理的改进。首先,我们凭经验证明了在训练文本图像嵌入中广泛使用的两种流行的损失和和最大边缘损失的局限性,并提出了利用kNN边际损失的权衡,其中1利用来自硬阴性的信息,2对于噪声是稳健的,因为所有K最难的样本被考虑在内,容忍伪阴性和异常值。其次,我们提倡在推理期间使用Inverted Softmax文本和Is和Cross模态局部缩放文本Csls来缓解高维嵌入空间中所谓的hubness问题,从而大幅提高所有度量的分数。 |
| Representation Theoretic Patterns in Multi-Frequency Class Averaging for Three-Dimensional Cryo-Electron Microscopy Authors Tingran Gao, Yifeng Fan, Zhizhen Zhao 我们在本文中开发了一种新的内在分类算法多频类平均MFCA,用于通过它们的观察方向之间的相似性来聚类从三维低温电子显微镜低温EM获得的噪声投影图像。这种新算法利用单一群的多个不可约表示来为传输数据的表示引入额外的冗余,扩展并优于Hadani和Singer Foundations of Computational Mathematics,11 5,pp.589 616 2011的先前类平均算法。只有一个代表。所提出的MFCA算法的形式代数模型和表示理论模式将Hadani和Singer的框架扩展到单一群的任意不可约表示。我们通过Wigner矩阵透镜检测二维单位球面上广义局部并行传输算子的光谱特性,从概念上建立MFCA的一致性和稳定性。我们通过数值实验证明了所提算法的有效性。 |
| A Curated Image Parameter Dataset from Solar Dynamics Observatory Mission Authors Azim Ahmadzadeh, Dustin J. Kempton, Rafal A. Angryk 我们提供了从太阳动力学天文台SDO任务的AIA仪器中提取的大型图像参数数据集,在2011年1月至当前日期期间,以6分钟的节奏,为9个波长通道提供。每年数据集的数量仅为1 TiB。为了在活动区域和冠状孔的区域分类中获得更好的结果,我们通过深入评估计算这些图像参数所需的各种假设来改进一组十个图像参数的性能。然后,在可能的情况下,设计了一种用于查找参数计算的适当设置的方法,以及用于显示我们改进结果的验证任务。此外,我们还包括使用监督分类模型比较JP2和FITS图像格式,通过调整特定于提取它们的图像格式的参数,并特定于每个波长。这些比较的结果表明,利用JP2图像(文件明显较小)对这些参数最初用于的区域分类任务没有害处。最后,我们计算AIA图像上的调整参数并提供公共API |
| Deep 3D Convolutional Neural Network for Automated Lung Cancer Diagnosis Authors Sumita Mishra, Naresh Kumar Chaudhary, Pallavi Asthana, Anil Kumar 计算机辅助诊断已经成为验证放射科医师在CT解释中的意见的不可或缺的技术。本文提出了一种深度三维卷积神经网络CNN架构,用于基于自动CT扫描的肺癌检测系统。它利用三维空间信息来学习高度辨别的三维特征,而不是需要手动生成的纹理或几何形状等2D特征。所提出的深度学习方法基于时空统计自动提取3D特征。所开发的模型是端对端的,并且能够针对给定的输入扫描预测每个体素的恶性。仿真结果证明了所提出的3D CNN网络在肺结节分类中的有效性,尽管计算能力有限。 |
| Correctness Verification of Neural Networks Authors Yichen Yang, Martin Rinard 我们提出了第一个验证,即神经网络在每个感兴趣的输入的指定容差范围内产生正确的输出。我们定义了相对于规范的正确性,该规范标识了由世界所有相关状态组成的状态空间,以及2从世界各州产生神经网络输入的观察过程。使用有限数量的切片平铺状态和输入空间,从状态切片和输入切片的网络输出边界获取地面实况边界,然后比较地面实况和网络输出边界为任何网络输出错误提供上限感兴趣的输入。案例研究的结果强调了我们的技术为所有感兴趣的输入提供严格误差界限的能力,并显示了误差界限在状态和输入空间上的变化情况。 |
| Low-rank Random Tensor for Bilinear Pooling Authors Yan Zhang, Krikamol Muandet, Qianli Ma, Heiko Neumann, Siyu Tang 双线性池化能够从数据中提取高阶信息,这使其适用于细粒度的视觉理解和信息融合。尽管在各种应用中它们具有有效性,但具有大量参数的双线性模型很容易受到维数和难以计算的诅咒的影响。在本文中,我们提出了一种基于低秩随机张量的新型双线性模型。关键思想是有效地结合低秩张量分解和随机投影,以减少参数数量,同时保留模型代表性。从理论的角度来看,我们证明了具有随机张量的双线性模型可以估计特征映射以再现具有组成核的核Hilbert空间RKHS,将高维特征融合与理论基础相结合。从应用程序的角度来看,我们的低秩张量操作是轻量级的,可以集成到标准的神经网络架构中,以实现高阶信息融合。我们进行了大量的实验,以证明我们模型的使用可以在几个具有挑战性的细粒度动作解析基准上实现最先进的性能。 |
| Functional Adversarial Attacks Authors Cassidy Laidlaw, Soheil Feizi 我们提出了功能性对抗性攻击,这是一种新颖的威胁模型,用于制作对抗性示例,以欺骗机器学习模型。与标准的椭球威胁模型不同,功能性对抗威胁模型仅允许使用单个函数来扰动输入要素以产生对抗性示例。例如,应用于图像颜色的功能性对抗攻击可以同时将所有红色像素改变为浅红色。图像中的这种全局均匀变化可以比单独扰动图像的像素更不易察觉。为简单起见,我们将对图像颜色的功能性对抗性攻击称为ReColorAdv,这是我们实验的主要焦点。我们表明,功能威胁模型可以与现有的附加威胁模型相结合,以生成更强大的威胁模型,允许小的,个别的扰动和对输入的大的,均匀的变化。此外,我们证明这种组合包含在任一组成威胁模型中都不允许的扰动。在实践中,ReColorAdv可以显着降低在CIFAR 10上训练的ResNet 32的准确性。此外,据我们所知,将ReColorAdv与其他攻击相结合即使在对抗训练后也会导致最强的现有攻击。 |
| Chinese Abs From Machine Translation |
Papers from arxiv.org
更多精彩请移步主页
pic from pexels.com