【图像分割】UNet网络学习笔记
原论文:U-Net: Convolutional Networks for Biomedical Image Segmentation Olaf Ronneberger, Philipp Fischer, and Thomas Brox
一、研究背景
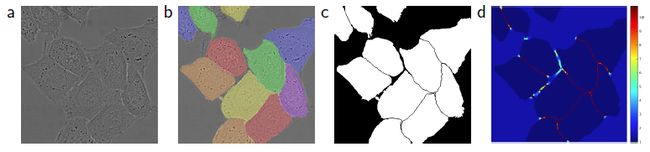
首先理解什么是图像分割。图像分割是指把图像分成各个具有相应特性的区域并提取出感兴趣的目标的技术和过程。特性可以是灰度、颜色、纹理等;目标可以对应单个区域,也可以对应多个区域。如图a为原图,图b为分割后的图像。

CNN 用于生物医学图像存在着困难,因为CNN常用于分类,并且训练模型需要大规模的数据,但是生物医学关注的是分割和定位任务,并且医学图像很难获得大规模的数据。以往的解决方法是使用滑窗,滑窗滑过整个图像,增大了训练的数据量,并且完成了定位任务,但是前向传播和反向传播的速度会变慢,同时滑窗大小的选择也会影响网络的局部准确性和获取上下文之间能力。FCN网络通过卷积层的级联,上层卷积得到的特征图用做下层卷积的输入,感受野增大,获取上下文的能力增强,提取到的特征图更好,再由反卷积层恢复得到分割图,但得到的分割图不够精细,图像过于模糊或平滑,没有分割出目标图像的细节。
UNet是为解决生物医学图像方面的问题,对FCN的优化,它采用了Contracting-Expanding(Encoder-Decoder)的对称结构,结构简单有效。
U-Net利用了数据增强(Data Augmentation)的思想,最大限度的利用有限的数据集去训练模型。
二、UNet网络结构
1.整体结构
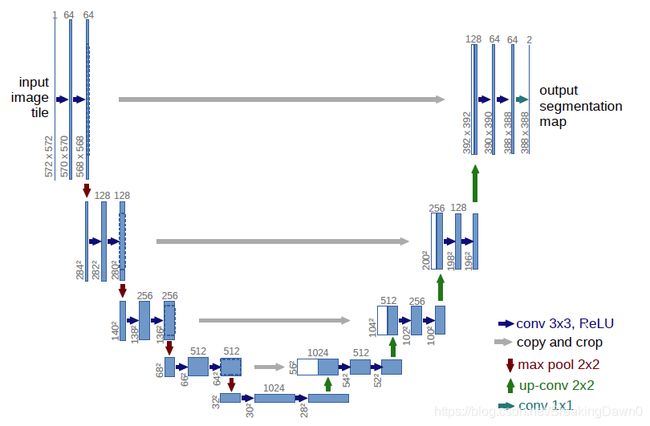
Unet网络的典型特点是:
- U型对称结构。左侧是下采样层(编码层),右侧是上采样层(解码层)。原文的Unet结构中,编码层有4层卷积池化层,解码层有4层反卷积层。在实现的时,既可以从头实现网络,然后进行模型训练;也可以借用现有网络的卷积层结构(如VGG)和对应的已训练好的权重文件,再加上后面的加码层进行训练计算,可以大大加快训练的速度。
- 每层编码层与解码层之间的级联(concatenate)。上一层的特征图反卷积(特征恢复)的结果,与同层编码层的特征图连接,扩大图像的通道数后,再对其进行卷积提取特征,实现了编码层和解码层的特征融合,有助于特征恢复过程中保留图像的更多细节。
2.下采样层(编码层)
编码层由N个结构相同的卷积层L(i)级联组成,L(i)包含两个3x3卷积层和一个2x2最大池化层,经过L(i)后图像通道数加倍。
其中卷积和池化的padding都是‘valid’(不补0),即只对图像的有效部分进行窄卷积,得到图像的有效特征,因此得到的输出图像会比输入图像小。解决这个问题的方法是根据输出图像的大小应该等于原图像大小(out_size=img_size),沿着网络逆向计算出输入图像的大小in_size,对原图像沿着四条边进行镜像扩大,作为输入图像。图中,输出分割图像的黄框与输入图像的黄框对应,输入图像中蓝框的边缘部分由于窄卷积丢失,最后的到输出图像中的黄框,因此输出的分割图像对应输入图像中原图img的位置。
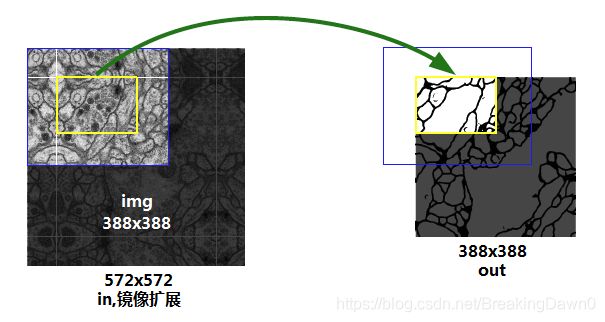
在编码层与解码层之间,用两个3x3卷积层进行连接。
3.上采样层(解码层)
解码层由N个结构相同的反卷积层L(i)级联组成,L(i)包含一个2x2反卷积层和两个3x3卷积层,经过L(i)后图像通道减半。
每层解码层会将反卷积恢复的特征,与同层编码层提取的特征连接(concatenate),再进行卷积,实现了编码层和解码层的特征融合,有助于特征恢复过程中保留图像的更多细节,使得到的分割图像轮廓更清晰。如图,在训练左心室内外膜分割的UNet网络时,c得到的特征比b更接近标签。
最后,解码层连接一个1x1全卷积网络,逐像素二分类,得到2个通道的输出图像。
三、关键技术
1.数据增强(Data Augmentation)
本文的核心思想之一是数据增强。对于只有少量训练样本的问题,数据增强可以让网络学习到所需的不变性和鲁棒性。
就作者文中用到的显微图像而言,需要旋转和平移不变性,弹性形变和灰度值变化鲁棒性。为此作者的解决思路是使用变形模型对图像进行空间变形,以获取更多的原始数据。
- 本文在3x3的网格上,使用符合高斯分布的10像素变形向量来进行变形,使用双三次插值来计算每个像素的位移;
- 在下采样路径的最后加入了Drop-Out方法,进一步隐式的扩充数据集。
DropOut的意思是, 在训练过程中, 每次随机选择一部分节点不要去"学习" 。这样做的原理是什么呢?
从样本数据的分析来看,数据本身是不可能很纯净的,即任何一个模型不能100%把数据完全分开, 在某一类中一定会有一些异常数据, 过拟合的问题恰恰是把这些异常数据当成规律来学习了。对于模型来讲,我们希望它能够有一定的“智商”,把异常数据过滤掉, 只关心有用的规律数据。
异常数据的特点是,它与主流样本中的规律都不同, 但是量非常少,相当于在一个样本中出现的概率比主流数据出现的概率低很多。我们就是利用这个特性, 通过在每次模型中忽略一些节点的数据学习,将小概率的异常数据获得学习的机会降低, 这样这些异常数据对模型的影响就会更小了。
2.无缝拼接(seamless tiling)
为了使得输出的分割图无缝拼接,重要的是选择输入块的大小,使编码层中所有的 2×2 的池化层都可以应用于长宽(x_size,y_size)是偶数的特征图。一个比较好的方法是从最底层的分辨率从反向推到,例如原文网络中最小的是32×32,沿着编码路径的反向进行推导可知,输入图像的尺寸应该为 572×572。这样在处理输入图像时同样用到上文提到的镜像操作。
3.预计算网络权重(weight initialization)
权值的初始化好坏程度会影响模型的效果以及训练时间,因为随着网络层数的增加,训练过程中会出现梯度消失的问题,这导致深层的网络参数无法被有效地训练。理想的权值初始化是使得网络中的每一个特征图方差都接近1。
在U-Net中,可以通过高斯分布随机生成网络权值,高斯分布的均方差为![]() ,其中N为前一神经层的输入节点数,例如。 上一层是3x3卷积和64个特征通道,N = 9·64 = 576
,其中N为前一神经层的输入节点数,例如。 上一层是3x3卷积和64个特征通道,N = 9·64 = 576
4.损失函数加权(weight map)
损失函数是交叉熵损失函数,其中需要注意的是这里的损失函数有加权w(x),对于每一个像素点有着自己的权重。
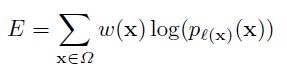
每一个像素在损失函数中的权值w(x)需要预先计算,这种方法补偿了训练数据中每类像素出现的频率差异,并且使网络更注重学习分割的边缘。
w(x)使用形态学运算,特征图的计算方法如下:

其中的![]() 是用于平衡类别频率的权重图,
是用于平衡类别频率的权重图,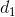 是该像素点到最近的细胞边界的距离;
是该像素点到最近的细胞边界的距离;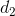 是该像素点到第二近的细胞边界的距离。作者的实验中,
是该像素点到第二近的细胞边界的距离。作者的实验中,![]() ,将
,将 ![]() 。
。
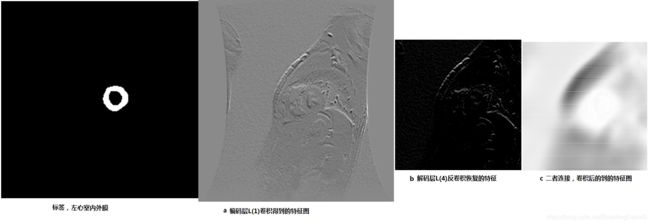
如图a是显微图原图,c是细胞分割的标签,d是计算得到的特征图w(x)。可以看到,w(x)在细胞分割边界的值更大,使网络更注重学习分割的边缘。