图像对抗生成网络GAN学习02 在TPU上训练pix2pixGan实战解决素描上色问题(tensorflow)
图像对抗生成网络GAN学习02: 实现我的第一个TPU训练自定义模型项目:pix2pixGan实战解决素描上色问题(tensorflow)
文章目录
-
- 图像对抗生成网络GAN学习02: 实现我的第一个TPU训练自定义模型项目:pix2pixGan实战解决素描上色问题(tensorflow)
- 前言
- 1.数据集介绍以及数据预处理
- 2.pix2pixGAN模型的搭建
-
- 2.1生成器的搭建
- 2.2 判别器的搭建
- 2.3损失函数以及优化器的定义
- 2.4整个模型的组件
- 3.结果评估
- 4.结语
前言
pix2pixGan又称图像翻译,他的作者提出以往的GAN多是在学习原图的特征从而创造相似的同一类的图片,那么如果我们需要的不是原有的相似的图片呢换个说法就是GAN网络是否能够完成输入图像到另一种模式的图的的转换(如下图所示)。

比如在CityScapes数据集中,我们拥有每张图像对应的分割图,我们为了加强网络的训练,我们想要获得更多的数据,但是拍摄有用的数据是如此的代价巨大,而我们希望GAN网络能帮我们达到输入同一张分割图,但是却可以产生与原图不一样的数据(分割结果与原图一致,但是细节中产生差别),如下:

从左往右依次为输入分割图,真值,和GAN生成网络生成的图(这个是我自己编写代码跑出来的效果限于设备,效果仍然有些模糊,但可以看到已经是有显示照片拍摄的样子了)这里我们可以看到原图和生成的只在分割效果上会大致接近但是,在细节方面,却出现了很多差别(这也正是我们想要的生成图片多样化),而做到这些你只需要训练一下模型而非亲自去拍摄,这也正是pix2pixGAN的强大之处。
那么,在本节中我还测试了模型在TPU上运行(总算是成功了。。,就记录一下),那么先简单介绍一下什么是TPU。TPU是谷歌公司最近几年研发出来的希望用于替代GPU在深度学习训练模型中的广泛使用,可以说他是专门为了深度学习,张量计算设计的,在网络资料中曾经这么介绍他
“简单的结论是:TPU与同期的CPU和GPU相比,可以提供15-30倍的性能提升,以及30-80倍的效率(性能/瓦特)提升”
并且并非在运算效率上TPU在加快模型收敛上貌似会比GPU更好(这来自于我个人实践可能有各种巧合),比如在KAGGLE网站提供的GPU上我进行了150次的模型训练,显存总是很容易爆满,并且最终效果也不尽如人意:

这个模型也就是我们本篇博客所采用的,是希望GAN网络能够自动给我们的素描图上色,可以看到在跑了150次之后生成的图片,仍然有着部分身体轮廓忽大忽小,上的颜色过于混杂,那么当我在KAGGLE提供的TPUv3-8上训练一次之后的效果如下:
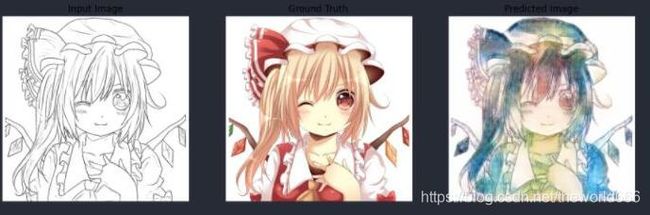
惊奇地发现,这跑了一次就比GPU跑了150次的效果更加好看,我说生成的图片好看也没错吧,色调什么的都很不错(当然我个人没学过画画只是我自己觉得不错)。所以TPU对于设备不行的童鞋,想要实现更高的正确率或处理更多数据却限于设备,那么学习TPU如何使用一定会对你有更大的帮助。
1.数据集介绍以及数据预处理
那么我们就先介绍一下,我们本次的数据,Anime Sketch Colorization Pair,他提供了14000多张的图片,其中每张图片的大小是 512*1024,每张图片的内容如下

为提供对应的上过色后的图片,和原有的素描,那么我们本次pix2pixGAN的任务就是输入一张素描画,生成一张上过色的图片 这里我们为了和原图不相同会添加一些参数使得生成的图片更加多样化。
那么这里相信很多同学都已经知道数据怎么预处理,但如果要想在kaggle提供的TPU上运行,我们的数据预处理步骤则需要经过改进去写。。所以这里我就啰嗦一点把适用在TPU上的数据预处理给写出来(对于GPU则不需要这么麻烦,但是为了效率更高,我们就多花点时间修改代码)
from kaggle_datasets import KaggleDatasets
GCS_PATH = KaggleDatasets().get_gcs_path('anime-sketch-colorization-pair')#这个是数据集的文件名
print(GCS_PATH)
这里get_gcs_path的意思是获取数据集在Google Cloud Storage上的路径,这里之所以是要这么做是因为GOOGLE公司规定使用TPU训练模型,必须将数据集上传到Google Cloud Storage,并使用gcs路径才能完成模型读取数据
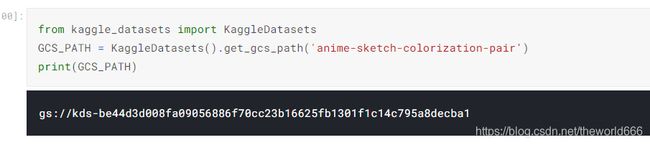
可以看到输出的路径是一串代码,区别于我们一般处理路径的时候的绝对地址与相对地址,那么通过这一步得到图片的路径接下来就跟平常预处理代码一样了
#这里补一步把TPU的strategey属性赋值
try:
tpu = tf.distribute.cluster_resolver.TPUClusterResolver()
print('Device:', tpu.master())
tf.config.experimental_connect_to_cluster(tpu)
tf.tpu.experimental.initialize_tpu_system(tpu)
strategy = tf.distribute.experimental.TPUStrategy(tpu)
except:
strategy = tf.distribute.get_strategy()
print('Number of replicas:', strategy.num_replicas_in_sync)
import glob
all_img_path=tf.io.gfile.glob(GCS_PATH + '/data/train/*.png') #仍然是利用glob匹配所有图片的路径
len(all_img_path)#查看一下图片的个数,看是否匹配完全
14224 #可以看到14000多张图片都被我们匹配到当前列表
获取了所有图片的地址了,那我们再编写一个将地址转换为图片的函数
def read_png(path):
img=tf.io.read_file(path)
img=tf.image.decode_png(img,channels=3)
return img #tf推荐将多个小函数组件在一起
@tf.function
def normalize(mask,img):
mask=tf.cast(mask,tf.float32)
mask=mask/127.5-1
img=tf.cast(img,tf.float32)
img=img/127.5-1#将数据和原图的值限制在-1,1之间是GAN模型的惯例
return mask,img
def read_img(path):
img=read_png(path) #读取图片
w=tf.shape(img)[1]
w=w//2
input_mask=img[:,w:,:] #这里由于图片是由素描图和原图拼凑在一起所以我按照中间对半切开素描图和原图
input_img=img[:,:w,:]
input_img=tf.image.resize(input_img,(256,256))#调整图片大小
input_mask=tf.image.resize(input_mask,(256,256))
if tf.random.uniform(())>0.5:#uniform值返回在0到1之间所以这里用0.5的概率来决定是否左右翻转图像
input_img=tf.image.flip_left_right(input_img)
input_mask=tf.image.flip_left_right(input_mask)
return normalize(input_mask,input_img)#归一化图片
编写完读取图片函数之后,我们就开始创造数据输入管道,利用TF2提供的非常方便的Datatset模块
import tensorflow as tf
keras=tf.keras
layers=keras.layers
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
data = tf.data.Dataset.from_tensor_slices(all_img_path)
auto=tf.data.experimental.AUTOTUNE #提高图片读取速度的效率
data=data.map(read_img,num_parallel_calls=auto)
BATCH_SIZE=64#规定批次数量
BUFFER_SIZE=100#每次迭代打乱图片的个数
data=data.shuffle(BUFFER_SIZE).batch(BATCH_SIZE)
data=data.prefetch(auto)#让计算机根据性能选取每次预期数量的图片
data
<PrefetchDataset shapes: ((None, 256, 256, 3), (None, 256, 256, 3)), types: (tf.float32, tf.float32)> #可以看到data的形状正是我们想要的
2.pix2pixGAN模型的搭建
了解过GAN模型的同学一定知道,GAN生成对抗网络是由两个网络组成的,图像生成器和图像鉴别器,整个网络的原理,我在我的上篇博客图像对抗生成网络 GAN学习01:从头搭建最简单的GAN网络,利用神经网络生成手写体数字数据(tensorflow)_theworld666的博客-CSDN博客_gan网络里讲过,结构大概如下图:

这里我这边就只讲一下本篇博客涉及的整个系统的大概,我在查阅pix2pixGAN论文的时候,作者称这种GAN为CGAN即Conditional GAN条件GAN(这个GAN我原本想介绍的。。但耽搁了,以后找时间补档)条件GAN是解决了我们无法控制GAN随机生成的图片的种类问题,在条件GAN中拿mnist举例,如果是一般的GAN我们无法让系统生成指定数字的图片,当我们只想要1,系统却很可能给我们随机生成一堆不必要的,那么条件GAN就是说我们能够控制系统完成我们指定的类型的图片输出。
那么在本篇中我们输入的条件毫无疑问是没有上色的素描图,但是我们不需要像传统GAN随机噪声输入。那么回到主题,接下来我们开始时候生成器和判别器的搭建。
2.1生成器的搭建
在搭建生成器方面,是有讲究的。作者认为 对与pix2pix任务来说,输入和输出之间会共享很多的信息。比如轮廓信息是共享的。那么如果使用一般的神经网络,卷积编码,反卷积解码这样的顺序,那么会导致每一层都承载保存着所有的信息,这样神经网络很容易出错。所以受U-net启发作者是想到将生成器改写为Unet这样的结构:
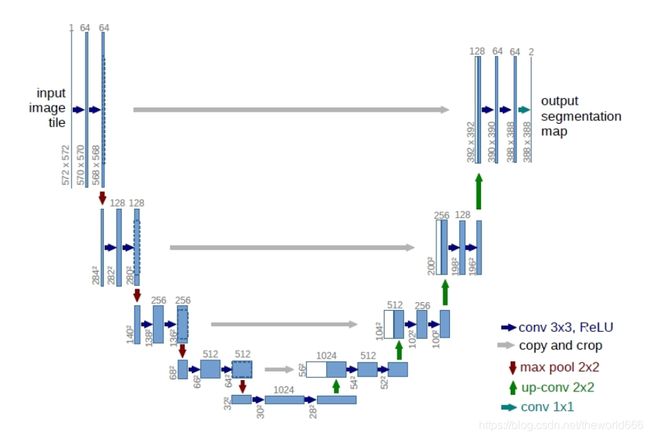
即使用跳接结构,将前面层的信息用Concat的方法与后面的层输出合并,(这里我插一嘴,使用Concate方法算是比较老的办法,现在较为流行resNet的残差网络块方法,我个人感觉先不管正确性在性能方面Concate结构的如果不添加显存动态申请控制和断点训练,极容易出现显存爆满,对于设备负荷较重,而残差结构则不会出现这样的问题,也算我个人经验)作者认为通过Concate操作可以防止信息丢失加强我们对数据的处理,那么总体介绍到这里里,具体细节看代码
#先定义我们的下采样函数
def downSample(units,kernel_size,use_bn=True):
model=keras.Sequential()
model.add(layers.Conv2D(units,kernel_size,strides=2,padding='same',use_bias=False))
if use_bn :
model.add(layers.BatchNormalization())#使用BN层加快函数收敛
model.add(layers.LeakyReLU())#GAN的激活函数一般使用leakyrelu
return model
#定义图像上采样函数
def upSample(units,size,use_dropout=False):
model=keras.Sequential()
model.add(layers.Conv2DTranspose(units,kernel_size=size,strides=2,padding='same',use_bias=False))#反卷积放大
model.add(layers.BatchNormalization())
if use_dropout:
model.add(layers.Dropout(0.5))#使用Dropout给生成数据添加多样性
model.add(layers.ReLU())#上采样过程中一般使用relu激活
return model
定义完U-Net的上采样,下采样函数之后我们相当于吧UNet的左右两边的基本组件给组件完了,那么我们接下来就把整个U-Net拼在一起
#下面这个UNet代码是我在网上偶然看到的,非常的优美的将跳接结构写的很整洁,所以这里我就不详细叙说了大家直接看
def Generator():
inputs=layers.Input(shape=((256,256,3)))
down_stack=[
downSample(64,4,use_bn=False),#生成器第一层不要使用BN层 128*128*64
downSample(128,4), #64*64*128
downSample(256,4), #32*32*256
downSample(512,4) ,#16*16*512
downSample(512,4) ,#8*8*512
downSample(512,4) ,#4*4*512
downSample(512,4) ,#2*2*512
downSample(512,4) #1*1*512
]
up_stack=[
upSample(512,4,use_dropout=True),#2*2*512
upSample(512,4,use_dropout=True),#4 4 512
upSample(512,4,use_dropout=True), # 8 8 512
upSample(512,4), # 16 16 512
upSample(256,4) ,#32 32 256
upSample(128,4) ,#64 64 128
upSample(64,4) #128 128 64
]
skips=[]
x=inputs
for d in down_stack:
x=d(x)
skips.append(x)
skips=skips[:-1]
skips=reversed(skips)
for up,skip in zip(up_stack,skips):
x=up(x)
x=layers.Concatenate()([x,skip])
x = layers.Conv2DTranspose(3, 4, strides=2,
padding='same',
activation='tanh')(x)
return keras.Model(inputs=inputs,outputs=x)
2.2 判别器的搭建
在判别器中,这里相对于普通的GAN也有改变,判别器这里由于是图像变换,作者认为,我们为了让生成图往我们期望的方向走,我们需要判别的话应该是捆绑输入,即当输入的素描图与真值一起输入的时候,我们输出判定为真输出1,当输入的素描图与生成的图一起输入的时候,我们判定为假输出0.还有一个做的改变是Patch-D,即一般的GAN网络最终判断真假我们会将最终输出压缩为1层然后输出计算损失,然而作者这样认为这样对细节生成不好,作者认为如果我们最终输出的不是单一的一层而是一个块一个快比如原图256 * 256我们输出多个30 * 30的块然后去判断真假计算损失,这样会倒逼生成器更加注重细节方面的生成,从而提高生成器的质量,那么讲了这么多,我们具体就来看下代码怎么实现的
def discriminator_model():
input1=layers.Input(shape=((256,256,3)))
tar=layers.Input(shape=((256,256,3)))
x=layers.Concatenate()([input1,tar])
x=downSample(64,4,use_bn=False)(x) #128 128 32
x=downSample(128,4)(x)#64 64 64
x=downSample(256,4)(x) #32 32 256
x=layers.BatchNormalization()(x)
x=layers.LeakyReLU()(x)
x=layers.Conv2D(1,3,strides=1)(x) #30 30 1 这里就是PATCH-D输出只生成块
return keras.Model(inputs=([input1,tar]),outputs=x)
2.3损失函数以及优化器的定义
生成器和判别器都定义完之后,我们就开始定义训练整个模型的损失函数以及模型的优化器方面,从这里开始我们就需要将以下所有的函数放在with strategy.scope():我个人理解是在TPU内存中开辟一个模块用于存储训练模型所必需的,所以我们这里需要在所有有关训练模型的参数定义上都添加这个with strategy.scope():具体代码如下:
with strategy.scope():
def gen_loss(d_gen_output, gen_output, target):
g_loss=keras.losses.BinaryCrossentropy(from_logits=True,reduction=tf.keras.losses.Reduction.NONE)(tf.ones_like(d_gen_output),d_gen_output)#reduction是一定要加的不然会报错
l1_loss=tf.reduce_mean(tf.abs(gen_output-target))
#这里作者认为我们在生成器这里还要加一个l1loss计算生成图与目标图的损失
return g_loss+10*l1_loss#控制l1损失所占的比重
with strategy.scope():
def disc_loss1(d_real_output, d_gen_output):
real_loss=keras.losses.BinaryCrossentropy(from_logits=True,reduction=tf.keras.losses.Reduction.NONE)(tf.ones_like(d_real_output),d_real_output)
gen_loss=keras.losses.BinaryCrossentropy(from_logits=True,reduction=tf.keras.losses.Reduction.NONE)(tf.zeros_like(d_gen_output),d_gen_output)
return real_loss+gen_loss#判别器的损失和经典GAN没有多差
#定义生成器和判别器的优化器
with strategy.scope():
generator_optimizer = tf.keras.optimizers.Adam(2e-4, beta_1=0.5)
discriminator_optimizer = tf.keras.optimizers.Adam(2e-4, beta_1=0.5)
损失函数和优化器这些都定义完了,那么接下来我们就开始组装我们整个的模型
2.4整个模型的组件
这里我查阅资料发现如果使用TPU,一般做法是构造一个模型将模型训练的整个过程自定义进模型的,train_step函数,所以这里我也照猫画虎如此采用
class CycleGan(keras.Model):
def __init__(
self,
generator,
discriminator,
lambda_cycle=10,
):
super(CycleGan, self).__init__()
self.gen = generator
self.disc = discriminator
self.lambda_cycle = lambda_cycle
def compile(
self,
gen_optimizer,
disc_optimizer,
gen_loss_fn,
disc_loss_fn,
):
super(CycleGan, self).compile()
self.gen_optimizer = gen_optimizer
self.disc_optimizer = disc_optimizer
self.gen_loss_fn = gen_loss_fn
self.disc_loss_fn = disc_loss_fn
def train_step(self, batch_data):
input_image, target = batch_data
with tf.GradientTape(persistent=True) as tape:
# photo to monet back to photo
gen_output= self.gen(input_image, training=True)
disc_real_output = disc([input_image, target], training=True)
disc_generated_output = disc([input_image, gen_output], training=True)
#计算损失
gen_total_loss = self.gen_loss_fn(disc_generated_output, gen_output, target)
disc_loss = self.disc_loss_fn(disc_real_output, disc_generated_output)
# Calculate the gradients for generator and discriminator
#求解梯度
generator_gradients = tape.gradient(gen_total_loss,
self.gen.trainable_variables)
discriminator_gradients = tape.gradient(disc_loss,
self.disc.trainable_variables)
# Apply the gradients to the optimizer
self.gen_optimizer.apply_gradients(zip(generator_gradients,
self.gen.trainable_variables))
self.disc_optimizer.apply_gradients(zip(discriminator_gradients,
self.disc.trainable_variables))
return {
"gen_loss": gen_total_loss,
"disc_loss": disc_loss
}
with strategy.scope():
generator=Generator()
disc=discriminator_model()
with strategy.scope():
cycle_gan_model = CycleGan(
generator,disc
)
cycle_gan_model.compile(
gen_optimizer = generator_optimizer,
disc_optimizer = discriminator_optimizer,
gen_loss_fn = gen_loss,
disc_loss_fn = disc_loss1,
)
至此整个模型的组件就完成了,我们在创建过程中同时也完成了在TPU上面的整个模型的搭建,同时因为我们的模型是继承子keras.model方法,我们重写了train_step函数,所以我们可以直接model.fit
EPOCHS = 150
cycle_gan_model.fit(
data,
epochs=EPOCHS,
steps_per_epoch=length//BATCH_SIZE
)
3.结果评估
但是在训练后我却发现为什么TPU的性能比GPU要好然而消耗时间却还是很长,以下面的这个为例,几乎比在GPU上面还慢,
![]()
于是,在我查找资料的时候得知TPU的大多数时候都花在了等待数据传输,也就是普通的Dataset数据读取并不适合TPU,会导致CPU读取时间跟不上TPU处理数据时间,TPU空闲时间过长,所以一般的解决办法是使用TFrecords数据格式,来加快数据读取,但这种我还不是很会(菜鸡落泪)。。,所以这里我使用一个非常简单的方法,这里用到一些计算计组成原理知识:我们制作好的输入数据管道相当于主存,GPU/TPU相当于运算器,当处理器速度远快于存储器读取数据的速度,运算器可能会大部分时间处于闲置状态,计算机组成原理中说明有种解决办法是将要处理的数据提前存入数据传输速度较快的缓存,然后运算器直接读取缓存中的数据,从而加速计算。一般的数据输入管道例如tf. data,他们的速度只跟的上GPU,但根本跟不上TPU,所以导致TPU空闲时间长,影响整个模型训练时间。所以这里我们的解决办法就是加缓存,这样的话我们的数据在第一次训练的时候会将数据逐渐存入缓存中,之后再第二次之后计算机就会直接从缓存读取数据,从而加速TPU的训练,我们用代码的话,只需要写这一行
data=data.cache()
这里我个人实践了一下,14000张图片150次只需三十分钟,相比GPU训练了七个小时可谓大大加快
在第一次训练完成后我们的数据的效果是

这里我们对比GPU第十次训练效果,可以看到在生成图像上色均匀程度美观方面都是TPU,效果更好

那么最终我的效果是这样的,可以看到效果是非常的不错了并且在细节上由于我们添加的Dropout层会在细节方面产生差别,比如这个人的眼睛颜色和原图有差别



4.结语
在本篇博客中,我介绍了如何搭建PIX2PIXGAN并在TPU上训练,并且在素描图上很好的解决了上色问题,限于博主水平有限希望大家如果有错误或者建议欢迎评论区交流,如果本篇文章对你有帮助麻烦点个赞,稍后我会将本次训练的模型权重上传到CSDN上同学们可以试一下,谢谢!