如何利用Python进行数据分析
今天我们主要的目标是:给大家介绍在所有的编程语言里,为什么Python能被广泛使用,甚至排名第一,给那些做数据分析相关工作和转行的小伙伴介绍数据分析行业里如何使用Python。

首先介绍一下什么是编程语言。
编程语言是一个计算机的概念,在我们有了计算机以后,想让它帮助我们做事情,就要通过计算机语言和它进行对话、交互,计算机语言能够被计算机所执行,完成我们需要做的相关任务。
计算机语言有很多种,常见的有C、C++、PHP、Java,以及今天我们要讲的Python等等。
首先C语言主要用于对底层的程序进行编程,C++是在C语言之上发展起来的一个面向对象的语言,被广泛的应用于计算机软件的开发;PHP是做网页用的;Java也是一个面向对象的计算机语言,是在C++之后另一个被广泛应用的语言,可以做网页、后端、安卓开发等等。
而Python虽然出现得晚一些,但是目前使用量已经排名第一,那么Python到底是一种什么样的语言呢?

我们看计算机语言的几个类型,从最早的0和1时代就有一些很简单的计算机语言,随着计算机语言的发展,它有几种不同的类型:
-
Procedural Programming Language
-
Functional Programming Language
-
Object-oriented Programming Language
-
Scripting Programming Language
前两种其实非常老旧了,很少会用到,我们现在常用的是第三和第四种,面向对象的编程语言(比如Java、C++)。
什么是面向对象编程语言呢?比如我们要做一个和汽车有关的程序,就把车设置成一个对象,这个对象会有他的属性和功能,它的重量、颜色、马力、电池等等,人类对于这个事物都是这样理解的,所以让计算机语言也用类似的方式去理解。
面向对象的编程语言有一个优点就是可以反复使用。任何人都可以用被设计好的算法去训练自己的数据,来得出自己的模型。还有一些多样性、继承等特点,我们以后再讲。
Python这个语言本身有面向对象的属性,这是它的优点。Java、C++这种语言需要编译,然后才可以执行,会相对复杂一些。为什么需要编译呢?我们写代码用的是英文,需要一个编译器来转换语言,转换成计算机能够理解的语言,才能进行执行。
而Python是一种文本型语言,它不需要把程序写好、进行编译、再进行执行,写一行就可以执行一行,这样会更方便使用,所以它既有面向对象的优点,又比传统的语言更方便。

既然Python是一个计算机语言,就要用到一个工具叫IDE,它是一个让我们我们用来编辑使用Python语言的工具,那么别的语言需要IDE吗?
都需要。Java需要Java的IDE、C++需要C++的IDE。Python有上图的几个IDE可以使用,作为数据分析来用,我们一般推荐使用Jupyter(可以通过网站直接下载安装,它是开源的)。
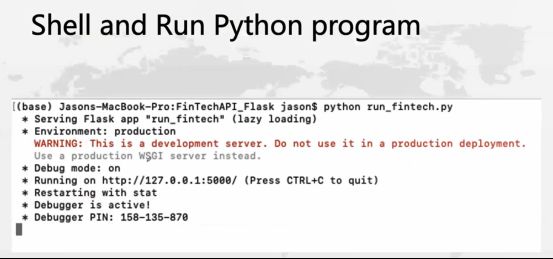
Python的执行有很多种方法,除了在IDE里执行,还可以把那些在IDE里写好的程序用Python的命令来执行。
这就是我们使用这个语言时用什么样去编辑、测试、调试以及运行它。后面将会做一个demo看一下在Jupyter Notebook中是如何执行的。

这是Python在TIOBE上的编程语言排名,评估语言是否应用广泛和受欢迎,Python在2020年第3名,2021年第1名。
编程语言包括Java、C、C++、C#,有几大阵营,一个是Lion,它的操作系统是Linux,Web服务器是Apache,语言会用Java、Python,而微软会用另一套,操作系统是Windows,Web服务器是Internet Information System(IIS)。Visual Basic是微软的,JavaScript是Apache开源阵营的语言,而Assembly language是对硬件进行编写的汇编语言,SQL是数据库语言,Swift是iPhone的编程语言。

Python为什么排第一呢?
首先,好学又好用。像Java、C++等其他语言需要编译,调试的时候需要开调试环境设置断点,但是Python是一行一行执行的,使用起来比较方便,不需要太多的计算机概念。
其次是Python Community,很多开源软件都是Python写的。
第三,大量开源的开发者,贡献了很多各种各样的Package和Libraries。Libraries其实就是一个个特别的功能而实现的一套代码。比如有关于数据处理和网站开发的Libraries,利用面向对象开发的形式,直接调用别人已经开发好的可调用的功能进行数据分析和开发网站。
第四,Python的有效性、可靠性比较好,速度也较快。
最关键的是Big Data、Machine Learning、Cloud Computing这三点。在Big Data方面,Hadoop Spark都支持Python语言,Spark大数据系统本身是用Scala写的,但是支持Java、Python。很多Machine Learning像sklearn都支持Python。Cloud Computing,像微软的Azure、谷歌的GCP、AWS都是支持Python的。这也是它为什么这么火的原因。

那么使用Python进行数据分析需要学习什么?
比如Numpy进行数据处理、Pandas进行数据处理和基本数据操作、简单的作图等,复杂的图表可以使用Matplotlib,scikit-learning包括分类、回归、聚类等机器学习算法。
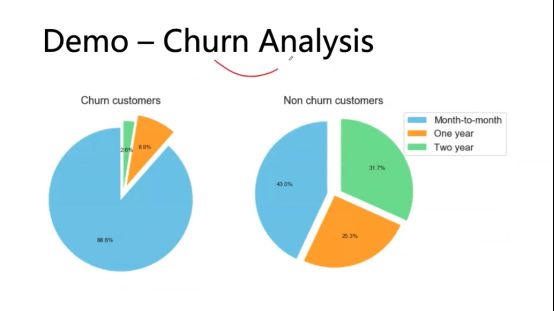
下面做一个Demo,在数据分析中有一个和产品、用户相关的话题,Churn Analysis。
比如你是Amazon online shopping的用户,以前每个星期都买东西,现在一个月也不买,这就是用户流失了。你本来有一个chase的信用卡,发现Capital One返点很不错,然后就不再使用chase了,对于chase来讲就是用户流失了。比如你是数据应用学院读书会的会员,到期后不再续订,也是用户流失。

接下来讲Churn Analysis的Demo。
首先Jupyter Notebook就是IDE,每一个代码都可以像文件一样保存、编辑、视图。在每一个cell中可以写代码并添加注释。之前讲了几个重要的Libraries,numpy、pandas、matplotlib、seaborn等,import是python语言使用之前导入程序并起一个别名,比如import pandas as pd。
df=pd.read_csv(“TelcoCustomerChurn.csv”)
pd提供了一个读取数据的功能read_csv,数据是Telco公司用户流失的数据。

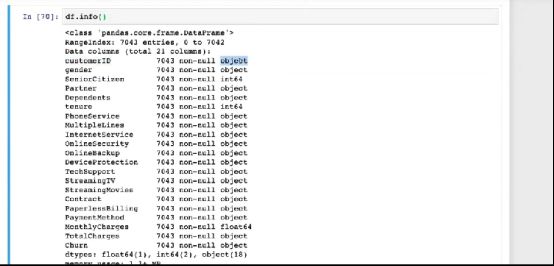
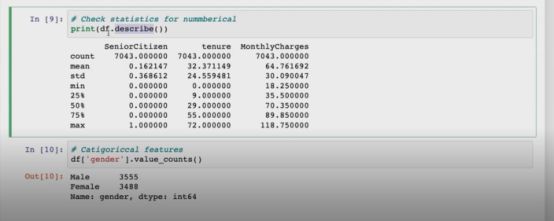
Python的pandas package还提供了非常丰富的文档,DataFrame是存储数据的对象,文档中有参数和例子。Python好学好用是因为有很多例子,文档也相对比较规范。把数据读取进来之后,使用df.info()可以查看一下数据集的基本信息。

它分为几列,第一列是customerID,数据类型object,这个object是说它不是一个简单的数,它可能是字符串这种的,就会把它做成object。这就和面向对象编程联系到一起了,这是一个对象。执行一行代码就把数据放在这里了。
Head这个功能是看看数据长什么样子数据里面都存储哪些东西,每一列都有它自己的功能。

接下来就把读进来的数据用打印的语句看一下有多少行和多少列,有哪些features。
后面就是check missing values,看看数据是否是完整的。df就是dataframe,就是你读进来的数据存在对象里面,describe是说显示它的统计数据,如最大值、最小值、中值、标准差等。
可以看到Python语言提供了很多library,每个library里面有很多function,这些function直接可以让你看到很多有意义的数据。

接下来我们来看一下画图的功能。
比如我们想看一下老年人和用户流失有什么关系,如下图左边NO代表不是老年人,蓝色是保存下来的用户,棕色是流失的用户;右边Yes代表是老年人,虽然用户比较少,但是流失的比例和不是老年人的时候还是有很大的差别。这就让我们很方便地发现一个inset,原来老年人和别的年龄段的人在用户流失这一方面是有差别的。
通过画图可以分析数据里面的特征。

Python语言在数据分析这块儿越来越好用主要包括以下几个方面:
-
它有大量开源的package,library供大家使用;
-
它不是很复杂是一种写一行可以执行一行的这种描述性的语言方式,相对简单一些;
-
它本身跨很多功能,大数据Hadoop,spark能用,数据分析也可以用,甚至可以用于开发网站。
python学习
如果你想学习Python,但是找不到学习路径和资源
欢迎加入新的交流【君羊】:905229245
一起探讨编程知识,成为大神,群里还有软件安装包,实战案例、学习资料