学习weka(7):weka数据预处理方法
1、前言
weka 数据预处理阶段全部在 filter 上:

下面把一些常见的机器学习数据与处理方法处理说一下(下面所有实例都是在 Explorer 模块上进行的)。

2、数据预处理方法
可以看到其 filters 可以分为五类,重点是画红框的部分:supervised 是有监督的,unsupervised 是无监督的;每一种往下分,又分为基于 attribute(属性列)和 instance(实例),基于属性列是按照列来进行操作的,基于实例是按照数据行进行操作的。
2.1 常见机器学习预处理方法
常见的机器学习预处理方法一般有缺失值处理、标准化、规范化、正则化和离散化,下面针对这几项一一记录一下。
2.1.1 缺失值处理
缺失值处理函数:weka.filters.unsupervised.attribute.ReplaceMissingValues,按照顺序可以在 filters 中找到,具体如下图:
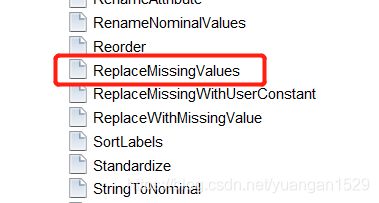
其参数如下:
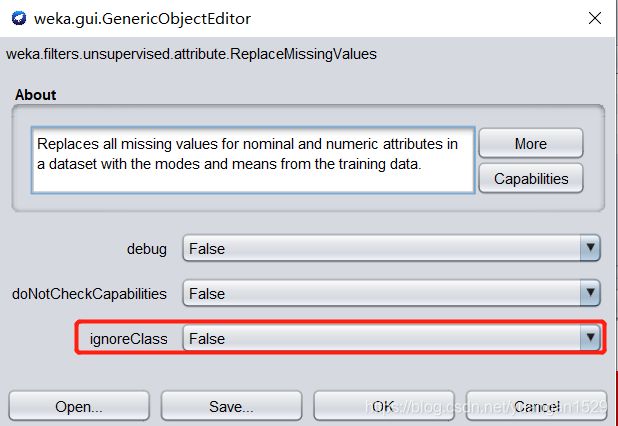
三个参数重点在 ignoreClass 上,这个是判断是否要对标签进行缺失值处理的参数。
实例
加载 weka 自带数据集:weather.nominal.arff,将其两个属性外加标签(默认最后一列为标签)编辑(在菜单中寻找 Edit…)为缺失值:
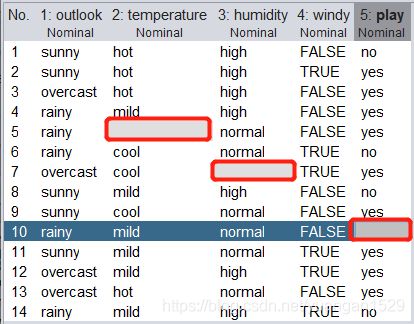
对其进行缺失值处理(使用默认参数):

可以看到,第 2 和 3 列属性缺失值都被填充完毕,而第 5 列则没有,这是为什么呢,来看一下官方解释:
Replaces all missing values for nominal and numeric attributes in a dataset with the modes and means from the training data. The class attribute is skipped by default.
翻译过来:是使用均值(数值型)和模式(我认为对于非数值则是数量最多的属性值填充)填充缺失值,默认跳过标签列(其中 ignoreClass 参数默认为 False)。
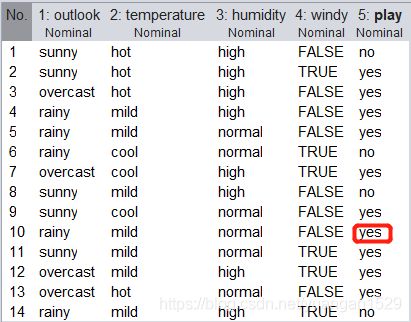
OK 了,将 ignoreClass 设置为 True,再进行一下缺失值处理:
2.1.2 标准化(standardize)
weka 中的类:weka.filters.unsupervised.attribute.Standardize
标准化给定数据集中所有数值属性的值到一个 0 均值和单位方差的正态分布。根据类包依赖顺序,在 filters 中找到其位置,查看一下参数:
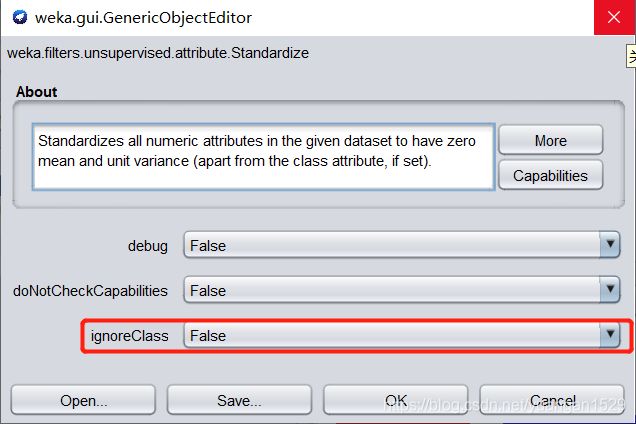
和缺失值处理参数一样,不再细说。
实例
加载 weka 自带数据集:cpu.arff,处理之前原数据(参数为默认,一般标签数据是不会被标准化的):
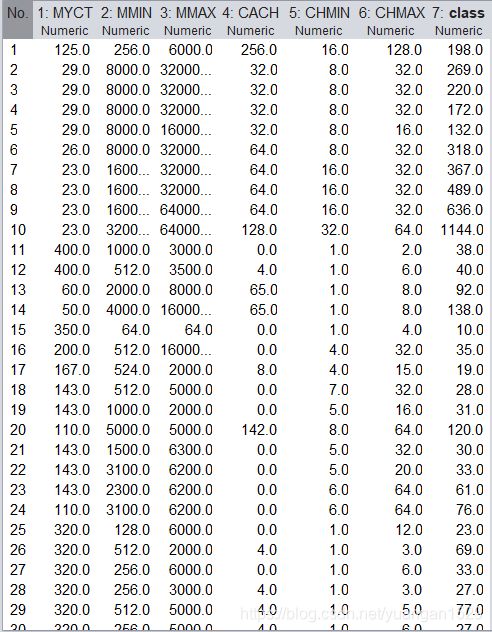
处理之后:

2.1.3 规范化(normalize)
规范化所在类:weka.filters.unsupervised.attribute.Normalize。
数据规范化,可以将所有数据通过数据变换,转换到指定范围内。来看一下其参数:
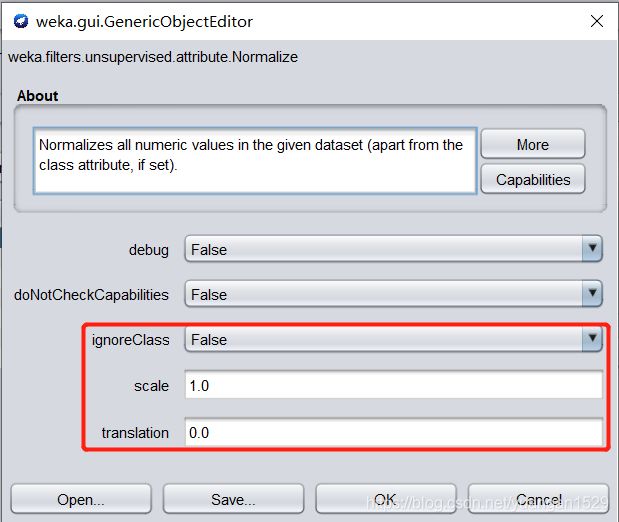
除了 ignoreClass,重要参数为 scale 和 translation,这两个参数指定了转换范围,转换公式为:[translation,translation+scale]。比如,scale=2,translation 为-1,那么转换后的数据范围为:[-1,1]
需要注意的是:无论是规范化还是标准化都是以列为单位。
实例
加载 weka 自带数据集:cpu.arff,处理前数据集为:
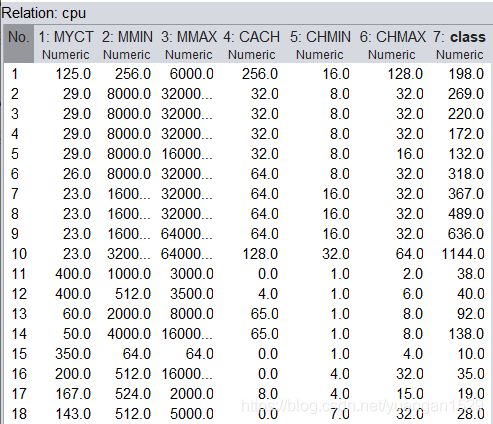
规范化处理之后(默认参数):

2.1.4 离散化处理(discretize)
离散化所在类:weka.filters.supervised.attribute.Discretize 和 weka.filters.unsupervised.attribute.Discretize
分别是监督和无监督的数值属性的离散化,用来离散数据集中的一些数值属性到分类属性。
无监督离散化处理参数:
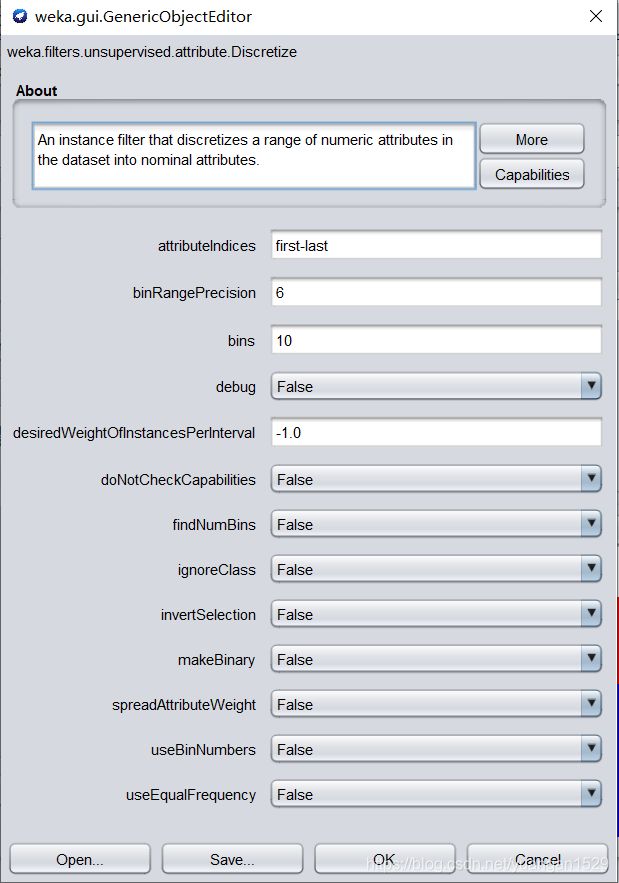
这里参数比较多,简要叙述一下:
- attributeIndices:属性索引,指定要执行的属性的范围,默认参数为“first-last”,表示所有列中离散列都会被选中,如果只是想选择某一列,直接输入数字即可,多列用逗号隔开。
- binRangePrecision:在生成 bin 标签时用于切割点的小数位数;
- bins:分段数,离散化后会将连续数据分为多段;
- debug:调试,如果设置为真,过滤器可以输出附加信息到控制台
- desiredWeightOfInstancesPerInterval:在每个间隔中等频绑定设置所需的实例权重
- doNotCheckCapabilities:如果设置为 true,则过滤器的功能在构建之前不会被检查(小心使用,以减少运行时间)
- findNumBins:使用 leave-one-out 优化等宽容器的数量,不适合于等频
- ignoreClass:是否忽略类标签索引
- invertSelection:反向选择,设置属性选择模式,如果是 false 则在范围内仅选择数值属性离散,如果是 true 则只有非选择的属性将被离散化
- makeBinary:生成二进制属性
- spreadAttributeWeight:生成二进制属性时,将旧属性的权重分散到新属性中。 不要为每个新属性赋予旧的权重。
- useBinNumbers:使用 bin 编号(如 BXofY),而不是使用范围
- useEqualFrequency:等频离散化,如果设置为真,则将使用等频而不是等宽
上面标黑的是需要注意的参数。
实例
加载 weka 自带数据集 weather.numeric.arff,原数据如下:
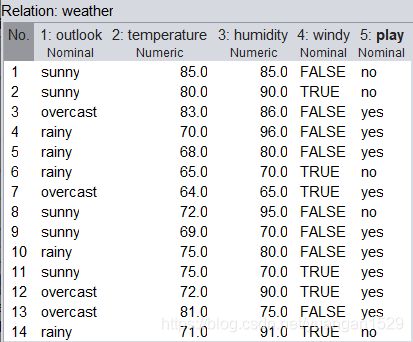
可以看到其连续属性只有两列,下面修改参数如下:
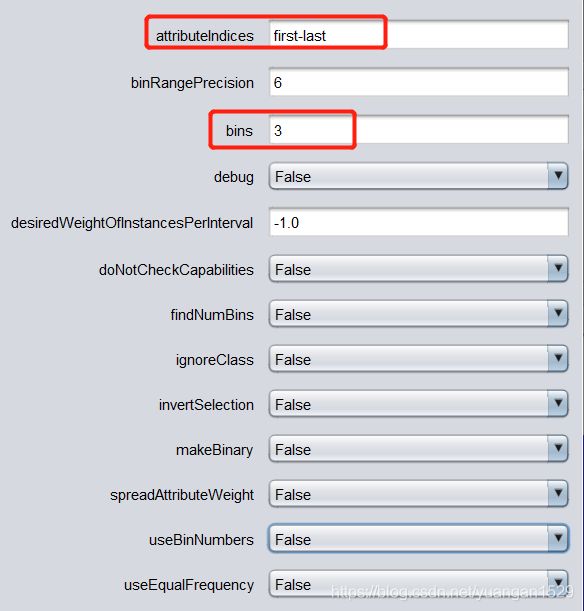
只修改了一项 bins,将其改为了 3,其他都是默认项,看一下离散化结果:
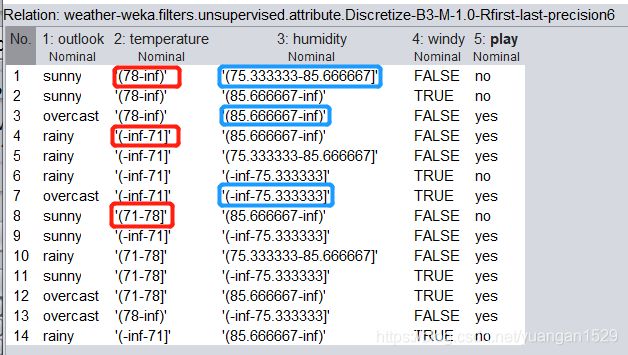
可以看到,两列连续性数据已经被离散化了(注意 attributeIndices 参数为所有,但是离散化只会选择连续性数据列),而且离散结果是 3 个——对应 bins
通过这个结果,可以看到离散化原理就是将连续数据分段,以分段范围定义为离散属性值,而连续值在哪个分段内就赋予那个分段范围值,比如 72,在 71-78 内,则其离散化后就成了 71-78。
我们更改一下 useBinNumbers 参数,再运行一遍(注意要加载原数据,当前数据已经不存在连续属性列,即便更参数运行,当前数据集也不会再发生变化):
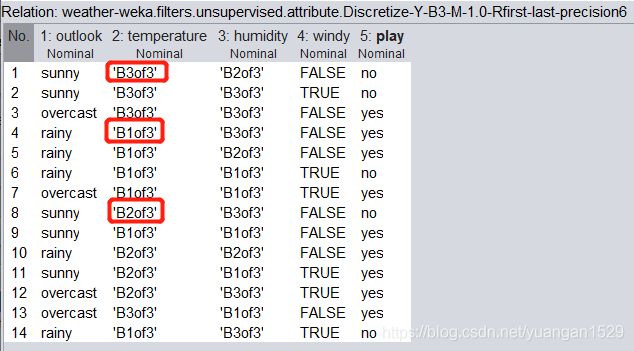
可以看到其更改了名称,但是本质还是一样的,这个有一点不好的就是两列离散值是重复的,都是 B1of3,B2of3 和 B3of3。
OK,今天就到这里,更多精彩内容关注我的个人网站:蓝亚之舟博客。