蚂蚁变大象:浅谈常规网站是如何从小变大的(二)
原文:http://blog.sina.com.cn/s/blog_6203dcd60100xokd.html
【第四阶段 : 第一次服务多机化】
当 IO 性能得到解决以后,我们可能就会面临 CPU 瓶颈,即程序处理不过来了。那这个时候,最好的方式,就是优化程序。从整体架构和具体业务逻辑上去分析并做优化(可以借助一些性能分析工具,如 gprof , xprof 等)。根据之前的经验,反射、正则表达式、字符串拼接、内存拷贝等是吃 CPU 的大户,所以优化上可以重点考虑。通过性能优化,一般可以将性能提升 30-40 个百分点。如果性能优化后,都还不能满足需求,那可以考虑更换更好的服务器。随着时间的推移,硬件发展极为迅速,且成本下降非常明显。可以考虑双核、4核等多核服务器。这样是提升服务性能最快的方式。
如果这样都还不能满足需求,那么,恭喜你,说明你的网站流量已经有一定规模了。接下来,就是——多机。
多机是小网站从技术架构上要迈出的第一步,也是一个质的飞跃的阶段(想当年,我还利用JAVA提供的库做了一个可多机的网站,不过一直没用上,哈哈)。这个阶段,最简单的就是将WebServer、数据库和cache这两个东东移动到另外的机器上去,利用WebServer、数据库和cache的网络协议对其进行访问。这样就能将原本被他们占用的cpu给我们的逻辑程序使用。
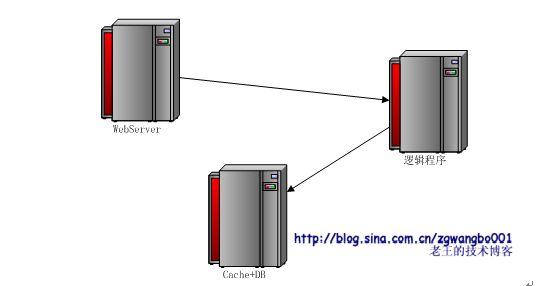
通过这样的拆分后,我们就迈出了多机的第一步。虽然看起来比较简单和容易,但是这也是非常具有里程碑意义的。这样的优化,可能会提升20-30%左右的一个CPU idle。能够使得我们的网站能够经受更大的压力。
――――――――――――― 休息一下的分割线 ―――――――――――――
昨天在济南玩了一天,去了传说中的大明湖畔,虽然没有看到夏雨荷,不过却领略了春意的盎然,各种花争奇斗艳。看了趵突泉,对泉没啥感觉,不过对泉里的鱼到是很深的印象——太肥了。
另外还吃了一个比较有特点的早餐——甏肉米饭。早上起来吃硕大一块五花肉。现在想起来都觉得有点腻。
今天去青岛,现在正在高速上。待会儿该我开车了,先上图,必须有图有真像。







――――――――――――― 技术继续开始的分割线 ―――――――――――――
【第五阶段 : 逻辑程序的多机化】
当我们的访问量持续增加的时候,我们承受这成长的快乐和痛苦。流量刷刷往上涨,高兴!但是呢,服务器叫苦不绝,我们的程序已经快到不能服务的边缘了。怎么办?
“快使用分布式,哼哼哈嘿”J
这个时候,我们就需要针对CPU瓶颈,将我们的程序分别放在多台服务器上,让他们同时提供服务,将用户请求分摊到多个提供服务的机器。
好,如果提供这样的服务,我们会遇到什么样的问题?怎么样来解决?
我们一个个的来分析:
一、WebServer怎么样来分流用户请求?That’s a good question!
在考虑这个问题的时候,我们常见的WebServer早已给我们想好了解决方案。现在主流的WebServer几乎都提供一个叫“Load Balance”的功能,翻译过来就是负载均衡。我们可以在WebServer上配置一组机器列表,当请求来临的时候,WebServer会根据一定的规则选取某一台机器,将请求转发到对应的逻辑处理程序上。
有同学马上就会问了,“一定的规则”是怎么样的规则?他能解决什么样的问题?如果机器宕了怎么办?……
哈哈,这里的一定规则就是“Load Balance”。负载均衡其实是分布式计算和存储中最基础的算法,他的好坏,直接决定了服务的稳定性。我曾经设计和开发了一个负载均衡算法(现在正在大规模使用),有一次就因为一个很小的case,导致服务大面积出现问题。
负载均衡要解决的就是,上游程序如何在我们提供的一堆机器列表中,找到合适的机器来提供下游的服务。因此,我们可以将负载均衡分成两个方向来看:第一,根据怎样的规则来选机器;第二,符合规则的机器中,哪些是能提供服务的。对于第一个问题,我们通常使用随机、轮询、一致Hash等算法;对于第二个问题,我们要使用心跳、服务响应判定等方法检测机器的健康状态。关于负载均衡,要谈的话点其实很多,我之前也写过专门的一篇文章来介绍,后续有空了,我再详细的描述。
总之,分流的问题,我们可以通过负载均衡来比较轻松的解决了。
二、用户的session如何来同步?That’s a good question,TOO!
虽然HTTP协议是一个无状态的服务协议,但是,用户的基本信息是要求能够保证的。比如:登录信息。原来在单机的时候,我们可以很简单的使用类似setSession(“user”, ”XXX”)的函数来解决。当使用多机的时候,该怎么样来解决呢?
其实这个问题也是当年困扰我很久的一个问题。如果用setSession,用户在某一台机器上登录了,当下次请求来的时候,到其他机器了,就变成未登录了。Oh,My God!
Ok,让我们一个个的来看:
1、一台机器登录,其他机器不知道;
2、用户请求可能到多台机器。
对于第一个问题,如果我们在一台机器的登录信息让其他机器知道,不就OK了嘛。或者,大家都在一台机器上登录,不就可以了嘛。 对于第二个问题,如果我们让同一个用户的请求,只落在同一台机器上,不就OK了嘛。因此,我们可以提出三种解决方案:
1、提供session同步机制;
2、提供统一session服务;
3、将同一用户分流到同一机器。
嗯,这三种方式,你会选哪个呢?如果是我,我就选最后一个。因为我是一个懒虫,我会选最简单的一个,我信奉的一个原则既是:简单粗暴有效!哈哈。在WebServer层使用一致Hash算法,按session_id进行分流(如果WebServer没有提供该功能,可以简单写一个扩展,或者干脆在WebServer后面做一个代理即可)。但是这种方案有一个致命的问题,当一台机器宕机了以后,该机器上的所有用户的session信息即会丢失,即使是做了磁盘备份,也会有一段时间出现session失效。
好,那看看第一种方案。其实现在有一些框架已经提供了这样的服务机制。比如Tomcat就提供session同步机制。利用自有的协议,将一台机器上的session数据同步到其他的机器上。这样就有一个问题,我需要在所有的机器上配置需要同步的机器,机器的耦合度瞬间就增加了,烦啊!而且,如果session量比较大的话,同步的实效性还是一个问题。
那再来看看第二种方案,提供统一session服务。这个就是单独再写一个逻辑程序,来管理session,并且以网络服务的方式提供查询和更新。对于这样的一个阶段的服务来讲,显得重了一些。因为,我们如果这样做,又会面临一堆其他的问题,比如:这个服务是否存在单点(一台服务器,如果宕机服务就停止),使用什么样的协议来进行交互等等。这些问题在我们这个阶段都还得不到解决。所以,看起来这个方案也不是很完美。
好吧,三种方案选其一,如果是你,你会选哪一种呢?或者还有更好的方案?如果我没钱没实力(传说中的“屌丝”,哈哈),我就可能牺牲一下服务的稳定性,采用代价最低的。
三、数据访问同步问题。
当多个请求同时到达,并且竞争同一资源的时候(比如:秒杀,或是定火车票),我们怎么来解决呢?
这个时候,因为我们用到了单机数据库,可以很好的利用数据库的“锁”功能来解决这个问题。一般的数据库都提供事务的功能。事务的级别分多种,比如可重复读、串行化等,根据不同的业务需求,可能会选择不同的事务级别。我们可以在需要竞争的资源上加上锁,用于同步资源的请求。但是,这个东东也不是万能的,锁会极大的影响效率,所以尽量的减少锁的使用,并且已经使用锁的地方尽量的优化,并检查是否可能出现死锁。
cache也有对应的解决方案,比如延迟删除或者冻结时间等技术,就是让资源在一段时间处于不可读状态,用户直接从数据库查询,这样保证数据的有效性。
好了,上述三个问题,应该涵盖了我们在这个阶段遇到的大部分问题。那么,我们现在可以把整体的架构图画出来看看。

这样的结构,足够我们撑一段时间了,并且因为逻辑程序的无状态性,可以通过增加机器来扩展。而接下来我们要面对的,就是提交增长和查询量增加带来的存储性能的瓶颈。
(今天就先写到这儿,早点洗洗睡了,明天还要去爬崂山。)
【第六阶段 : 读写分离,提升IO性能】
好了,到现在这个阶段,我们的单机数据库可能已经逐步成为瓶颈,数据库出现比较严重的读写冲突(即:多个线程或进程因为读写需要,争抢磁盘,使得磁盘的磁头不断变换磁道或盘片,造成读写都很缓慢)。
那我们针对这样的问题,看看有哪些方法来解决。
一、减少读取量。我们所有的问题来源就是因为读写量增加,所以看起来这个是最直接最根源的解决办法。不过,用户有那么大请求量我们怎么可能减少呢?其实,对于越后端的系统,这是越可能的事情。我们可以在每一层都减少一部分往后传输的请求。具体到数据库的话,我们可以考虑通过增加cache命中率,减少数据库压力。增加cache命中率有很多中方法,比如对业务访问模式进行优化、多级cache模式、增加内存容量等等。业务模式的修改不是太好通用,因此这里我们考虑如何通过增加内存容量来解决问题。
对于单机,现在通用的cache服务一般都可以配置内存大小,这个只需要很简单的配置即可。另外,我们也可以考虑多机cache的方案,通过增加机器来扩充内存容量。因此,我们就引入了分布式cache,现在常用的cache(如:memcache),都带有这样的功能,支持多机cache服务,可以通过负载均衡算法,将请求分散到多台不同的机器上,从而扩充内存容量。
这里要强调一点。在我们选择均衡算法的时候,是有考虑的。这个时候,常常选贼一致Hash算法,将某一系列ID分配到固定的机器,这样的话,能放的KV对基本等于所有机器相加。否则,如果不做这样的分配,所有机器内存里面的内容会有大量重复,内存并没有很好的利用。另外,因为采用一致Hash,即使一台机器宕掉,也会比较均匀的分散到其他机器,不会造成瞬间其他机器cache大量失效或不命中的问题。
二、减少写入量。要减少用户的提交,这个看起来是不太现实的。确实,我们要减少写入的量似乎是很难的一件事。不过也不是完全不可能。这里我们会提到一个思想:合并写入。就是将有可能的写入在内存里进行合并,到一定时间或是一定条件后,再一起写入。其实,在mysql等存储引擎内部,都是有这样的机制的。打个比方,比如有一个逻辑是修改用户购买物品的数量,每次用户购买物品后,计数都加一。如果我们现在不是每次都去实时写磁盘,而是到一定的时间或一定次数后,再写入,这样就可以减少大量的写入操作。但是,这里需要考虑,如果服务器宕掉以后,内存数据的恢复问题(这一部分会在后面来描述)。因此,如果想简单的使用数据合并,最好是针对数据重要性不是很强的业务,即使丢掉一部分数据,也没有关系。
三、多机承担请求,分散压力。如果我们能将原来单机的服务,扩充成多机,这样我们就能很好的将处理能力在一定限度内很好的扩展。那怎么来做呢?其实有多种方法,我们常用的有数据同步和数据订阅。
数据同步,我们将所有的更新数据发送到一台固定的数据服务器上,由数据服务程序处理后,通过日志等方式,同步到其他机器的数据服务程序上。如下图:

这种结构的好处就是,我们的数据基本能保证最终一致性(即:数据可能在短暂时间内出现不一致,但最后的数据能达到一致),而且结构比较简单,扩展性较好。另外,如果我们需要实时数据,我们可以通过查询Master就行。但是,问题也比较明显,如果负责处理和分发的机器挂掉了,我们就需要考虑单点备份和切换方案。
数据订阅,我们也可以通过这样的方式来解决数据多机更新的问题。这种模式既是在存储逻辑和数据系统前,增加一个叫做Message Queue(消息队列,简称MQ)的东东,前端业务逻辑将数据直接提交到MQ,MQ将数据做排队等操作,各个存储系统订阅自己想要的数据,然后让MQ推送或自己拉取需要的数据。

MQ不带任何业务处理逻辑,他的作用就是数据转发,将数据转发给需要的系统。其他系统拿到数据后,自行处理。
这样的结构,好处是扩展比较方便,数据分发效率很高。但是问题也比较明显,因为处理逻辑分散在各个机器,所以数据的一致性难以得到保证。另外,因为这种模式看起来就是一个异步提交的模式,如果想得到同步的更新结果,要做很多附加的工作,成本很高且耦合度很大。还有,需要考虑MQ的单点备份和切换问题。
因为现在数据库(如 Mysql )基本带有数据同步功能,因此我们在这个阶段比较推荐数据同步的方法。至于第二种方式,其实是很好的一种思想,后续我们会有着重的提及。那再来看我们的架构,就应该演变成这样的结构。

到目前这个阶段,我们基本上就实现了从单机到多机的转变。数据的多机化,必然带来的问题:一致性!这个是否有解决方案?这个时候我们需要引入一个著名的理论:CAP原理。
CAP原理包含了三个要素:一致性(Consistency)、可用性(Availability)、分区容忍性(Partition tolerance)。三个要素中,最多只能保证两个要素同时满足,不能三者兼顾。架构设计时,要根据业务需要进行取舍。比如,我们为了保证可用性和分区容忍性,可能会舍去一致性。
我们将数据分成多机,提高了系统的可用性,因此,一致性的保证很难做到强一致性。有可能做到最终一致性。这也是分布式引入以后的烦恼。
这样的一个系统,也是后续我们分布式架构的一个雏形,虽然比较粗糙,但是他还是比较简单实用,对于一般中型网站,已经能很好的解决问题。
―――――――――――――开始休息的分割线 ―――――――――――――
山东的城市真是不错,昨天去了淄博,城市很干净,路很宽敞,人少,较之青岛,感觉要舒服很多。去年骑车环这山东北面也去了烟台、蓬莱、威海等几个城市,整体感觉非常不错。很喜欢山东这个地方。
而且,山东人的实诚也给我留下了很好的印象。
刚刚过了河北收费站,下午就要回到帝都了。