SAFE: Similarity-Aware Multi-Modal Fake News Detection-学习笔记
SAFE: Similarity-Aware Multi-Modal Fake News Detection
- 假新闻检测方法通常可以分为(I)基于内容的方法和(II)基于社交上下文的方法。
- PolitiFact(politifact.com)是美国著名的非盈利性的政治陈述和报告真相检查网站。 GossipCop(gossipcop.com)是一个网站,用于检查杂志和报纸上发布的名人报道和娱乐故事。
- LIWC是一个广泛接受的心理语言词典。给定一个新闻故事,LIWC可以对文本中的单词进行计数,这些单词属于80多种语言,心理和主题类别中的一个或多个。
- VGG-19是一种广泛使用的CNN,具有19层图像分类。
- att-RNN是适用于多模式假新闻检测的深度神经网络模型。它采用具有关注机制的LSTM和VGG-19来融合新闻文章的文本,视觉和社交上下文功能。
- 对于一些虚构的故事,文本和视觉信息之间存在差距,一般出于两个原因。首先,很难通过非操纵的图像来支持这样的故事。其次,使用“吸引力”但不密切相关的图像可以帮助增加新闻流量。
PPT
提高对话系统数据质量和多样性的离群点检测
Fake news detection methods
假新闻检测方法通常可以分为(I)基于内容的方法和(II)基于社交上下文的方法。
一:基于内容的虚假新闻检测,通过利用新闻内容(即新闻内容内的文本信息和/或视觉信息)来检测假新闻。
二:基于社交上下文的方法通过调查与新闻文章相关的社交上下文信息(即新闻文章如何在社交媒体上传播)来检测虚假新闻。
SAFE Methodology


1.多模式特征提取。SAFE的多模式特征提取模块旨在分别在d维空间中表示给定新闻文章的(I)文本信息和(II)视觉信息。
文本通过引入附加的完全连接层来扩展Text-CNN,以自动提取每篇新闻文章的文本特征。
图2提供了Text-CNN的体系结构,其中包含卷积层和最大池。
每个本地输入是一组h个连续字。

给定一条包含n个词的内容,每个词首先被嵌入为(1)。
卷积层用于根据局部输入xi的序列生成特征图,表示为ct,通过过滤器wt。
每个本地输入是一组h个连续字。
⊕是串联运算符,σ是ReLU函数。
然后,最大时间池化操作应用于获得的特征图以进行降维,即ˆ ct = max {ci t} n-h + 1 i = 1。
最后,可以通过t = Wt tct + bt获得新闻文本的表示形式,其中wherect∈Rg,g是选择的不同窗口大小数;

为了表示新闻图像,使用Text-CNN和附加的完全连接层,同时首先使用预先训练的image2句子模型处理新闻内容中的视觉信息。
新闻视觉信息的最终表示:

2.模态独立的假新闻预测
正确地将新闻内容的提取的文本和视觉特征映射到其被伪造的可能性.
为了让计算出来的假新闻可能性接近其真实标签,定义了基于交叉熵的损失函数.

3.跨模式相似性提取
通过稍微修改余弦相似度来定义新闻文本信息和视觉信息之间的相关性,可以保证Ms(t,v)为正且∈[0,1]。
然后,可以按如下定义基于交叉熵的损失函数,即假设从纯相似性进行分析时,与文本和图像信息匹配的新闻相比,文本和视觉信息不匹配的新闻更容易被伪造。

4.模型整合与联合学习
当检测到虚假新闻时,主要是在正确识别虚假的新闻,这些虚假的新闻在文本和/或视觉信息中,或者它们之间的关系中。 为了涉及这两种情况,将最终损失函数指定为.
α和β用于分配提取的多峰特征(α)和跨峰相似度(β)之间的相对重要性。

4.优化过程以学习模型参数

更新θp,其中γ为学习率,即L w.r.t的偏导数。
更新θp等效于每次迭代中更新Wp和bp

Wp,L表示Wp的前d列,
Dt是一个入口值为 的对角矩阵。
Experiments
 实验是在两个公认的假新闻检测公共基准数据集上进行的,分别来自PolitiFact和GossipCop,PolitiFact(politifact.com)是美国著名的非盈利性的政治陈述和报告真相检查网站。 GossipCop(gossipcop.com)是一个网站,用于检查杂志和报纸上发布的名人报道和娱乐故事。
实验是在两个公认的假新闻检测公共基准数据集上进行的,分别来自PolitiFact和GossipCop,PolitiFact(politifact.com)是美国著名的非盈利性的政治陈述和报告真相检查网站。 GossipCop(gossipcop.com)是一个网站,用于检查杂志和报纸上发布的名人报道和娱乐故事。

LIWC是一个广泛接受的心理语言词典。 给定一个新闻故事,LIWC可以对文本中的单词进行计数,这些单词属于80多种语言,心理和主题类别中的一个或多个。
VGG-19是一种广泛使用的CNN,具有19层图像分类。
att-RNN是适用于多模式假新闻检测的深度神经网络模型。它采用具有关注机制的LSTM和VGG-19来融合新闻文章的文本,视觉和社交上下文功能。
– SAFE \ T:不使用文本信息;
– SAFE \ V:不使用视觉信息;
– SAFE \ S:不捕获新闻文本和视觉信息之间的关系(相似性)。在这种情况下,通过将每个新闻文章的提取的多模式特征进行合并来融合它们;
– SAFE \ W:仅评估文本和视觉信息之间的关系时的建议方法。在这种情况下,分类器与交叉模态相似性提取模块的输出直接相连。
将学习率设为10−4,将迭代次数设为100,并将步幅(H)设为{3,4}。
使用准确性,准确性,召回率和F1分数来评估表示和预测的效果。在预测假新闻时,基于两个数据集的准确性值和F1分数,SAFE的表现可超过所有基线。

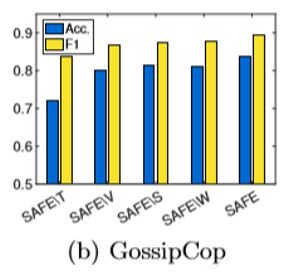
模块分析表中列出了SAFE及其变体的性能。在预测假新闻时;整合新闻文本信息,视觉信息及其关系(SAFE)在所有变体中效果最好;使用多模式信息(SAFE \ S或SAFE \ W)比使用单模式信息(SAFE \ T或SAFE \ V)要好。

将α和β的值分别从0更改为1,步长为0.2。对于两个数据集,各种参数值都导致SAFE的准确性(或F1score)介于0.75至0.85(或0.8至0.9)之间。当PolitiFact中的α:β= 0.4:0.6和GossipCop中的α:β= 0.6:0.4时,所提出的方法表现最佳。

对于一些虚构的故事,文本和视觉信息之间存在差距,一般出于两个原因。
首先,很难通过非操纵的图像来支持这样的故事。图5(a)中是一个示例,其中实际上没有与投票和票据相关的图像。
与具有真正亲密关系的夫妻相比(见图6(c)),假冒的夫妻通常拥有稀有的集体照或使用拼贴画(见图5(c))。
其次,使用“吸引力”但不密切相关的图像可以帮助增加新闻流量。例如,图5(b)中的虚假新闻包括带有笑容的个体与死亡故事相冲突的图像。