基于Keras实战项目-猫狗熊猫分类大战
欢迎来到本博客
本次博客内容将继续讲解关于OpenCV的相关知识
作者简介:⭐️⭐️⭐️目前计算机研究生在读。主要研究方向是人工智能和群智能算法方向。目前熟悉深度学习(keras、pytorch、yolo),python网页爬虫、机器学习、计算机视觉(OpenCV)、群智能算法。然后正在学习深度学习的相关内容。以后可能会涉及到网络安全相关领域,毕竟这是每一个学习计算机的梦想嘛!
目前更新:目前已经更新了关于网络爬虫的相关知识、机器学习的相关知识、计算机视觉-OpenCV、目前正在更新keras的相关内容。
本文摘要
本文我们将开始讲解神经网络keras领域项目-猫狗熊猫分类大战。
文章目录
- 项目前言
- 项目详解
- ⭐️经典全连接网络
- ⭐️预测模块
- ⭐️卷积神经网络分类

项目前言
我们从上次博客当中就结束了关于OpenCV的更新,后续可能会再次更新关于计算机视觉领域的相关内容。但是现在开始更新关于神经网络keras模块下的实战项目,首节我们以一个简单的项目为开头,然后逐个分析神经网络的小模块对整体网络架构的准确性和损失函数的影响。其中包括(Drop-out,dense等等)。
项目详解
⭐️经典全连接网络
我们从训练模块开始说起,会逐行去一一的解释代码的意思是什么?并且通过绘图的方式将结果更清晰的展示出来,然后通过加入Drop-out、正则化等,然后通过对比其中的图来看看效果有什么变化。首先我们来看一下整个nn_train模块。
在train模块当中:
import matplotlib#画图
from sklearn.preprocessing import LabelBinarizer
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report#综合结果对比
from keras.models import Sequential
from keras.layers import Dropout
from keras.layers.core import Dense
from keras.optimizers import SGD
from keras import initializers#初始化权重参数
from keras import regularizers#正则化
from my_utils import utils_paths#图像路径的操作
import matplotlib.pyplot as plt
import numpy as np
import argparse
import random
import pickle
import cv2
import os
首先我们导入这些即将会用得到的第三方模块,我们简单的介绍一下这些模块!
- matplotlib:画图模块,最后我们要通过它来绘图,直观的展示train_Loss,以及train_acc的走势。
- LabelBinarizer、train_test_split、classification_report:这三个模块分别是sklearn模块下的,其中LabelBinarizer是对标签数据进行one-hot-encoding的操作,也就是说用数组的形式展示数据,方便计算机处理。train_test_split是将数据分割成训练集和测试集的,classification_report是生成最终结果报告的。
- Sequential、Dropout、Dense、SGD、initializers、utils_paths:这些模块就是keras下面的一些相关于神经网络的一些操作模块了。Sequential就是说顺序搭建神经网络架构的模块。Dropout就是说要随机的杀死一些神经元,使得这些神经元不参与参数更新。Dense表示全连接。SGD表示优化器。
- os:os模块就是路径操作模块。
ap = argparse.ArgumentParser()
ap.add_argument("-d", "--dataset", required=True,
help="path to input dataset of images")
ap.add_argument("-m", "--model", required=True,
help="path to output trained model")
ap.add_argument("-l", "--label-bin", required=True,
help="path to output label binarizer")
ap.add_argument("-p", "--plot", required=True,
help="path to output accuracy/loss plot")
args = vars(ap.parse_args())
这里是参数导入代码,可以看出我们需要导入数据,模型数据,标签数据,画输出结果图。这里我们再次介绍导入参数,如果使用pycharm,就在这里设置: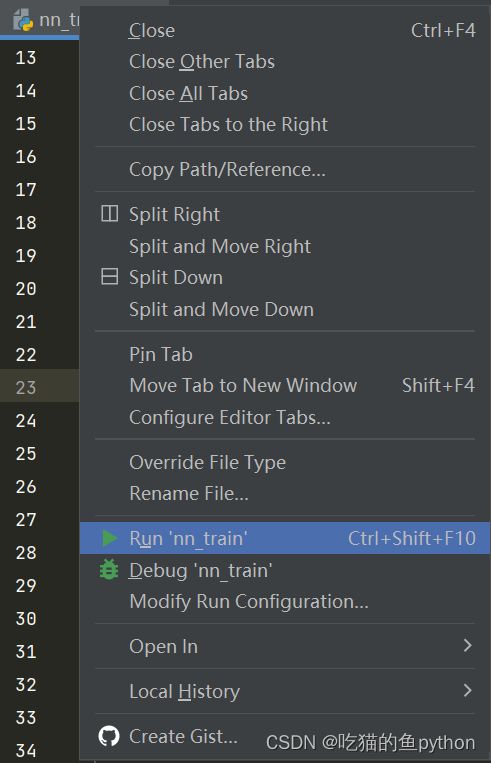
设置参数就是在Modify这里设置。
在训练模块中我们填入
–dataset ./dataset
–model ./output/simple_nn_model
–label-bin ./output/simple_nn_lb.pickle
–plot ./output/simple_nn_plot.png
然后我们就将需要导入的东西导入进去了。
print("[INFO] 开始读取数据")
data = []
labels = []
imagePaths = sorted(list(utils_paths.list_images(args["dataset"])))
random.seed(42)
random.shuffle(imagePaths)
这里我们将图像数据的路径都拿到,对于猫狗熊猫每个各有1000张图像,一共3000个路径目前我们全部都拿到手了,然后种一个随机种子,就是说我这次随机分的和下次随机分的是一模一样的,不是错乱的。然后通过random.shuffle将数据打乱,相当于一个洗牌操作。其中utils_paths这个是专门来做提取图片路径的,代码是,这段代码不仅仅适合于这里,其他地方也可以进行应用,应为三方库只有os:
import os
image_types = (".jpg", ".jpeg", ".png", ".bmp", ".tif", ".tiff")
def list_images(basePath, contains=None):
# return the set of files that are valid
return list_files(basePath, validExts=image_types, contains=contains)
def list_files(basePath, validExts=None, contains=None):
# loop over the directory structure
for (rootDir, dirNames, filenames) in os.walk(basePath):
# loop over the filenames in the current directory
for filename in filenames:
# if the contains string is not none and the filename does not contain
# the supplied string, then ignore the file
if contains is not None and filename.find(contains) == -1:
continue
# determine the file extension of the current file
ext = filename[filename.rfind("."):].lower()
# check to see if the file is an image and should be processed
if validExts is None or ext.endswith(validExts):
# construct the path to the image and yield it
imagePath = os.path.join(rootDir, filename)
yield imagePath
for imagePath in imagePaths:
image = cv2.imread(imagePath)
image = cv2.resize(image, (32, 32)).flatten()
data.append(image)
label = imagePath.split(os.path.sep)[-2]
labels.append(label)
然后遍历图像路径,然后使用cv2读入图像路径,然后使用cv2对所有读入的图像进行一个resize操作,resize成32×32大小的图,然后是一个三维的,但是传统的神经网络无法对三维数据进行操作,当前是32×32×3。所以使用flatten进行一个图像拉长操作。使用data添加数据,然后通过路径中倒数第二个得到对应图片属于的标签,并且进行添加。
data = np.array(data, dtype="float") / 255.0
labels = np.array(labels)
(trainX, testX, trainY, testY) = train_test_split(data,
labels, test_size=0.25, random_state=42)
然后对图像数据进行一个归一化的处理。因为像素值都是在0-255之间的数值,我们通过除以255,让所有数据在0-1之间。然后对数据集进行一个切分,也就是说把数据3000张的25%设置成测试集,也就是750张。2250张作为训练集,并且每次随机都是一致的。
lb = LabelBinarizer()
trainY = lb.fit_transform(trainY)
testY = lb.transform(testY)
这里对数据做一个one-hot-encoding的操作,也就是说猫假设对应001,狗对应010,熊猫对应100。对训练集和测试集都进行相同的处理。
model = Sequential()
model.add(Dense(512, input_shape=(3072,), activation="relu" ,kernel_initializer = initializers.TruncatedNormal(mean=0.0, stddev=0.05, seed=None),kernel_regularizer=regularizers.l2(0.01)))
model.add(Dropout(0.5))
model.add(Dense(256, activation="relu",kernel_initializer = initializers.TruncatedNormal(mean=0.0, stddev=0.05, seed=None),kernel_regularizer=regularizers.l2(0.01)))
model.add(Dropout(0.5))
model.add(Dense(len(lb.classes_), activation="softmax",kernel_initializer = initializers.TruncatedNormal(mean=0.0, stddev=0.05, seed=None),kernel_regularizer=regularizers.l2(0.01)))
这里就是按照顺序搭建神经网络架构,首先通过全连接输入3072×1的数据,转化成512,并且初始参数随机。然后继续将512的通过全连接变成256的,然后从256最后生成3种,因为这个项目就是3种类别,len(lb.classes_)这里用这个表示。
INIT_LR = 0.001
EPOCHS = 200
print("[INFO] 准备训练网络...")
opt = SGD(lr=INIT_LR)
model.compile(loss="categorical_crossentropy", optimizer=opt,
metrics=["accuracy"])
H = model.fit(trainX, trainY, validation_data=(testX, testY),
epochs=EPOCHS, batch_size=32)
这里我们定义学习率是0.01,然后epochs是200。对于epochs就是说我们这个模型要做多少次迭代,而一次迭代就是要迭代3000张图。对于batch呢就是说我的计算机一次需要处理多少张图像,比如batch等于32,那么就意味着我一次要处理32张图像。这里对于batch_size和epochs要分清。然后使用交叉商进行损失函数定义,然后选择优化器,以及判定标准准确率。设置完成之后我们就开始了本轮的训练。
print("[INFO] 正在评估模型")
predictions = model.predict(testX, batch_size=32)
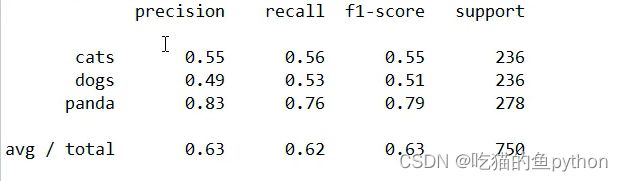
print(classification_report(testY.argmax(axis=1),
predictions.argmax(axis=1), target_names=lb.classes_))
然后使用训练集训练出来的模型对测试集也进行预测,然后看看准确率和损失数值。
N = np.arange(0, EPOCHS)
plt.style.use("ggplot")
plt.figure()
#plt.plot(N[150:], H.history["loss"][150:], label="train_loss")
#plt.plot(N[150:], H.history["val_loss"][150:], label="val_loss")
plt.plot(N[150:], H.history["accuracy"][150:], label="train_acc")
plt.plot(N[150:], H.history["val_accuracy"][150:], label="val_acc")
plt.title("Training Loss and Accuracy (Simple NN)")
plt.xlabel("Epoch #")
plt.ylabel("Loss/Accuracy")
plt.legend()
plt.savefig(args["plot"])
# 保存模型到本地
print("[INFO] 正在保存模型")
model.save(args["model"])
f = open(args["label_bin"], "wb")
f.write(pickle.dumps(lb))
f.close()
剩下的这些就是绘制结果曲线了,没什么可说的。最后一步是模型保存。
最后通过200个epochs后得到的。

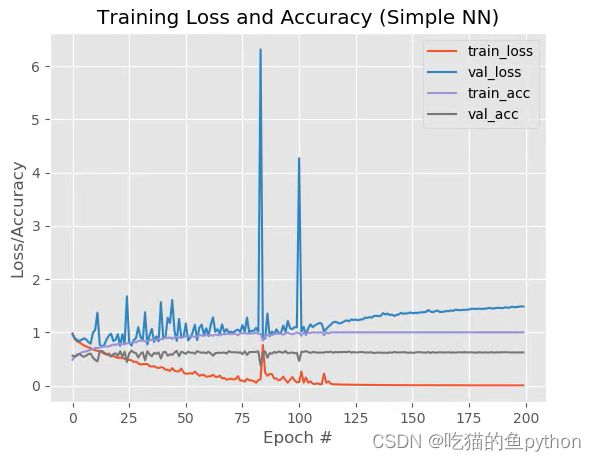
这里很明显,过拟合了!!!所以我们下面通过改变了一下学习率来继续来看一下有什么改进效果。把0.01改成0.001.我们直接来看图。
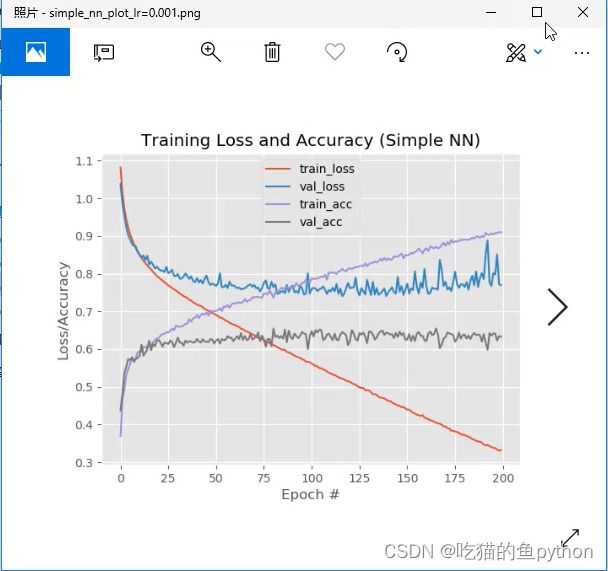
过拟合的现象还是有,但是效果要好不少。学习率对整个结果的影响还是很大的。然后我们再引入drop-out这个核心层,这个相当于是一个七伤拳的操作,为什么会出现过拟合,是因为神经元太多了,那么我们随机的去杀死一些神经元这样做会不会好一些呢。
model.add(Dropout(0.5))
加入了drop-out后的结果是
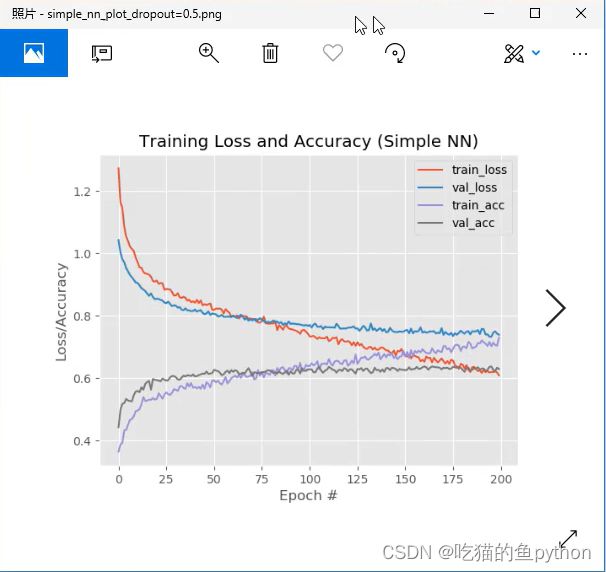
这里可以看出过拟合的趋势明显降低!!!而且也较为稳定。然后我们再看一下权重初始化的方法不同会有什么样的结果:
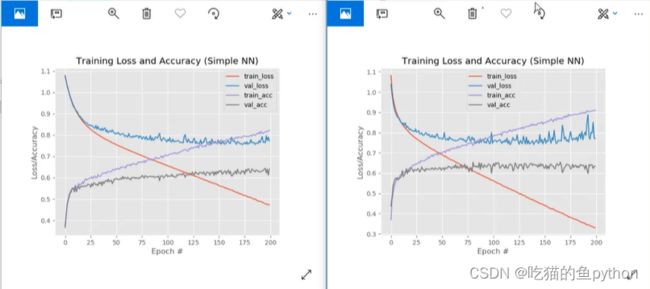
做了一个截断权重分布,另一个是均匀分布。对于过拟合现象确实有改善,并且也确实较为稳定了。对于初始化权重中,更改了一下标准差的系数。
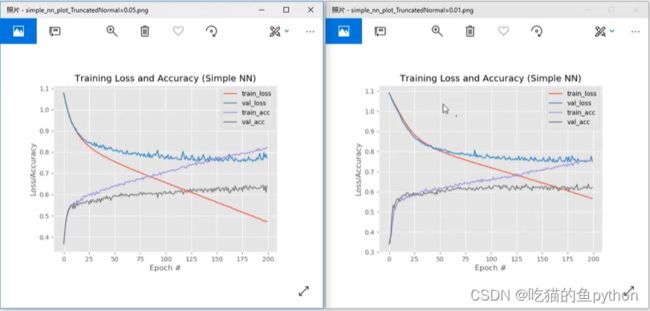
然后我们有改动了一下正则化,所谓正则化就是在计算loss的时候,不仅仅只计算loss,也要加上一个权重项,也就是Loss+λ正则项,其中λ是惩罚系数。这样我们运行之后呢,就将模型保存了下来,然后我们利用保存下来的模型来预测照片的分类。
⭐️预测模块
首先导入所需要的工具包,分别是加载模型,定义参数模块,以及cv2等
from keras.models import load_model
import argparse
import pickle
import cv2
首先定义参数:
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--image", required=True,
help="path to input image we are going to classify")
ap.add_argument("-m", "--model", required=True,
help="path to trained Keras model")
ap.add_argument("-l", "--label-bin", required=True,
help="path to label binarizer")
ap.add_argument("-w", "--width", type=int, default=28,
help="target spatial dimension width")
ap.add_argument("-e", "--height", type=int, default=28,
help="target spatial dimension height")
ap.add_argument("-f", "--flatten", type=int, default=-1,
help="whether or not we should flatten the image")
args = vars(ap.parse_args())
在参数这里我们需要输入:
–image images/dog.jpg
–model output/simple_nn.model
–label-bin output/simple_nn_lb.pickle
–width 32
–height 32
–flatten 1
输入之后我们来分析一下输入的这几个参数,首先导入一张图像,然后导入之前训练好的模型,然后定义一下参数,并且要不要进行拉长操作。
image = cv2.imread(args["image"])
output = image.copy()
image = cv2.resize(image, (args["width"], args["height"]))
image = image.astype("float") / 255.0
if args["flatten"] > 0:
image = image.flatten()
image = image.reshape((1, image.shape[0]))
else:
image = image.reshape((1, image.shape[0], image.shape[1],
image.shape[2]))
然后我们读入一张图像,并且对图像进行预处理和归一化操作,如果要进行拉伸,那么还要进行一个拉伸的操作,因为传统的神经网络不能够对三维图像进行操作。如果要做卷积,那么就不用左拉伸操作。
print("[INFO] loading network and label binarizer...")
model = load_model(args["model"])
lb = pickle.loads(open(args["label_bin"], "rb").read())
读入模型和标签。
preds = model.predict(image)
i = preds.argmax(axis=1)[0]
label = lb.classes_[i]
对图像进行预测,看看属于哪个。并且获取到所属于的标签,也就是会得到三个预测的百分数值,然后我在这三个预测数值中取一个最大的,然后利用这个最大的数值将标签拿出来。
text = "{}: {:.2f}%".format(label, preds[0][i] * 100)
cv2.putText(output, text, (10, 30), cv2.FONT_HERSHEY_SIMPLEX, 0.7,
(0, 0, 255), 2)
cv2.imshow("Image", output)
cv2.waitKey(0)
画出来结果。

这个图片就可以看得出来,预测的结果只保留预测概率最大的那一个。如果我们把epochs设置的更高的好,模型的预测效果肯定会更好。
⭐️卷积神经网络分类
我们用完经典神经网络之后,然后再用卷积神经网络去试一下做这个分类任务。
首先我们还是通过代码一步一步的去深入了解这个模型。
首先还是导入第三方库
import matplotlib
from model_name.simple_vggnet import SimpleVGGNet
from sklearn.preprocessing import LabelBinarizer
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report
from keras.optimizers import SGD
from keras.preprocessing.image import ImageDataGenerator
from my_utils import utils_paths
import matplotlib.pyplot as plt
import numpy as np
import argparse
import random
import pickle
import cv2
import os
import warnings
warnings.filterwarnings("ignore")
然后我们设置导入配置参数的函数
ap = argparse.ArgumentParser()
ap.add_argument("-d", "--dataset", required=True,
help="path to input dataset of images")
ap.add_argument("-m", "--model", required=True,
help="path to output trained model")
ap.add_argument("-l", "--label-bin", required=True,
help="path to output label binarizer")
ap.add_argument("-p", "--plot", required=True,
help="path to output accuracy/loss plot")
args = vars(ap.parse_args())
–dataset ./dataset
–model ./output_cnn/vggnet_model
–label-bin ./output_cnn/vggnet_lb.pickle
–plot ./output_cnn/vggnet_plot.png
这里设置的参数变成了vgg的模型,以及图像输出。
print("[INFO] loading images...")
data = []
labels = []
imagePaths = sorted(list(utils_paths.list_images(args["dataset"])))
random.seed(42)
random.shuffle(imagePaths)
for imagePath in imagePaths:
image = cv2.imread(imagePath)
image = cv2.resize(image, (64, 64))
data.append(image)
label = imagePath.split(os.path.sep)[-2]
labels.append(label)
这里唯一一个不同的就是将图片resize成了64×64的。
data = np.array(data, dtype="float") / 255.0
labels = np.array(labels)
(trainX, testX, trainY, testY) = train_test_split(data,
labels, test_size=0.25, random_state=42)
lb = LabelBinarizer()
trainY = lb.fit_transform(trainY)
testY = lb.transform(testY)
model = SimpleVGGNet.build(width=64, height=64, depth=3,
classes=len(lb.classes_))
这里面和之前都是一样的,包括归一化数据切分等!最后一个就是使用VGG卷积神经网络对图片进行操作。那么让我们来具体的看一下:
首先导入所需要的模块:
from keras.models import Sequential
from keras.layers.normalization.batch_normalization_v1 import BatchNormalization
from keras.layers.convolutional import Conv2D
from keras.layers.convolutional import MaxPooling2D
from keras.initializers import TruncatedNormal
from keras.layers.core import Activation
from keras.layers.core import Flatten
from keras.layers.core import Dropout
from keras.layers.core import Dense
from keras import backend as K
class SimpleVGGNet:
@staticmethod
def build(width, height, depth, classes):
# 不同工具包颜色通道位置可能不一致
model = Sequential()
inputShape = (height, width, depth)
chanDim = -1
if K.image_data_format() == "channels_first":
inputShape = (depth, height, width)
chanDim = 1
然后对于VGG需要的是wight×high×channel这个格式还是channel×wight×high这个格式,我们都先设定一下。然后就是按照顺序搭建神经网络模型了。
model.add(Conv2D(32, (3, 3), padding="same",
input_shape=inputShape))
model.add(Activation("relu"))
model.add(BatchNormalization(axis=chanDim))
model.add(MaxPooling2D(pool_size=(2, 2)))
#model.add(Dropout(0.25))
# (CONV => RELU) * 2 => POOL
model.add(Conv2D(64, (3, 3), padding="same"))
model.add(Activation("relu"))
model.add(BatchNormalization(axis=chanDim))
model.add(Conv2D(64, (3, 3), padding="same"))
model.add(Activation("relu"))
model.add(BatchNormalization(axis=chanDim))
model.add(MaxPooling2D(pool_size=(2, 2)))
#model.add(Dropout(0.25))
# (CONV => RELU) * 3 => POOL
model.add(Conv2D(128, (3, 3), padding="same"))
model.add(Activation("relu"))
model.add(BatchNormalization(axis=chanDim))
model.add(Conv2D(128, (3, 3), padding="same"))
model.add(Activation("relu"))
model.add(BatchNormalization(axis=chanDim))
model.add(Conv2D(128, (3, 3), padding="same"))
model.add(Activation("relu"))
model.add(BatchNormalization(axis=chanDim))
model.add(MaxPooling2D(pool_size=(2, 2)))
#model.add(Dropout(0.25))
# FC层
model.add(Flatten())
model.add(Dense(512))
model.add(Activation("relu"))
model.add(BatchNormalization())
#model.add(Dropout(0.6))
# softmax 分类,kernel_initializer=TruncatedNormal(mean=0.0, stddev=0.01)
model.add(Dense(classes))
model.add(Activation("softmax"))
return model
里面分别涉及到了卷积操作,卷积后需要加上relu激活函数。然后归一化处理也就是BN操作,最后进行一个pooling操作这样讲其进行卷积,最后通过全连接层来进行分类,经过softmax将图片进行分类。
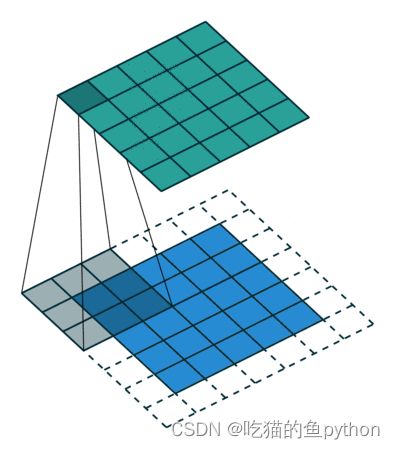
上图对应卷积操作。
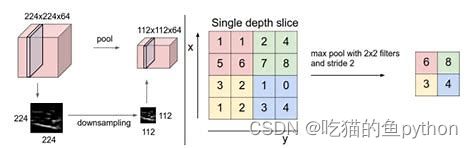
对应池化层操作。
卷积神经网络的loss和acc对比:
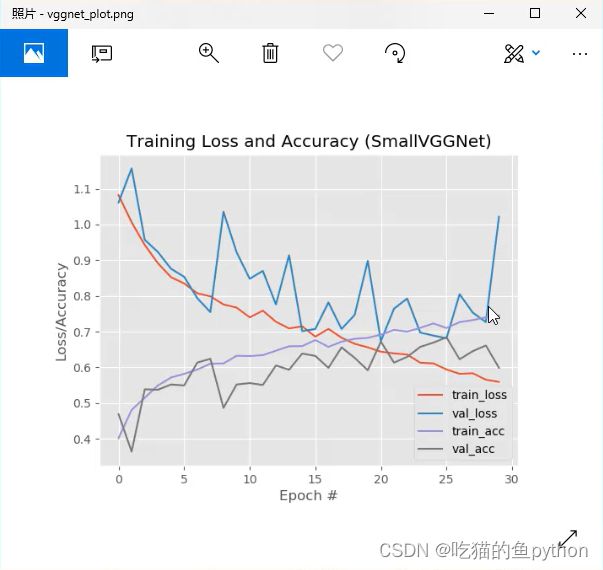
没有加入BN层。
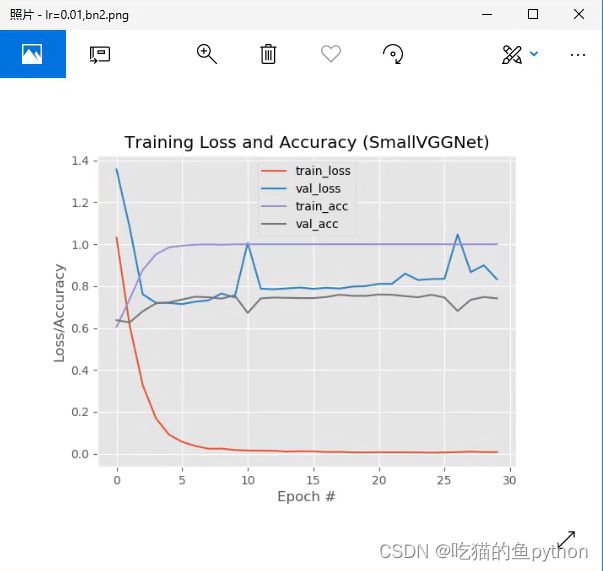
加上BN 之后的结果图。虽然都有过拟合的现象,但是这个加上了BN之后,稳定性较强。然后加入drop-out,结果是:
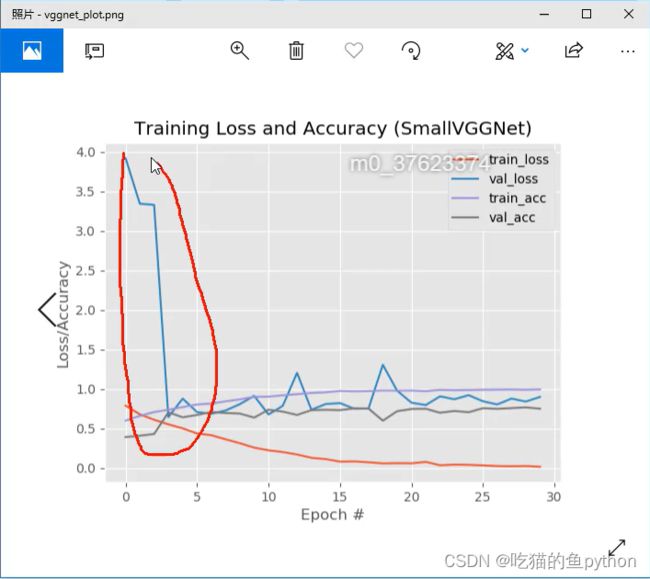
这里可以看出由于初始化参数的设置问题,可能loss值初始比较高。
然后生成模型文件之后,我们依旧使用predict进行训练参数是:
–image images/dog.jpg
–model output_cnn/vggnet.model
–label-bin output_cnn/vggnet_lb.pickle
–width 64
–height 64
最后的结果是:

使用经典的神经网络没有识别出来的猫使用卷积神经网络的准确率可以达到94%。
支持:如果觉得博主的文章还不错或者您用得到的话,可以免费的关注一下博主,如果三连收藏支持就更好啦!这就是给予我最大的支持!