SCS【5】单细胞转录组数据可视化分析 (scater)

点击关注,桓峰基因
桓峰基因公众号推出单细胞系列教程,有需要生信的老师可以联系我们!首选看下转录分析教程整理如下:
Topic 6. 克隆进化之 Canopy
Topic 7. 克隆进化之 Cardelino
Topic 8. 克隆进化之 RobustClone
SCS【1】今天开启单细胞之旅,述说单细胞测序的前世今生
SCS【2】单细胞转录组 之 cellranger
SCS【3】单细胞转录组数据 GEO 下载及读取
SCS【4】单细胞转录组数据可视化分析 (Seurat 4.0)
SCS【5】单细胞转录组数据可视化分析 (scater)
今天来说说单细胞转录组数据的分析细节,学会这些分析结果,距离发文章就只差样本的选择了,有创新性的样本将成为文章的亮点,并不是分析内容了!
前言
动机: 单细胞RNA测序(scRNA-seq)越来越多地被用于研究单个细胞水平上的基因表达。然而,为进一步分析准备原始序列数据并不是一个简单的过程。来源存在于数据中的偏差、实验室错误和其他不必要的问题,需要在预处理、质量控制(QC)和标准化上花费大量的时间和精力。
结果: 开发了 R 软件包 scater,以促进scRNA-seq数据的严格预处理、质量控制、规范化和可视化。该软件包提供了一个方便、灵活的工作流程,将原始测序数据处理到高质量的表达式数据集,为下游分析做好准备。Scater为单细胞数据提供了丰富的绘图模块,以及与现有软件包兼容的灵活的数据结构,可以用作未来软件开发的基础工具。
软件安装
scater 提供单细胞转录组数据可视化工具。基于 SingleCellExperiment类(来自singlecelexperiment 包),因此可以与许多其他的Bioconductor包互操作,安装如下:
if(!require(devtools))
install.packages("devtools")
if(!require(scater))
devtools::install_github("davismcc/scater", build_vignettes = TRUE)
if(!require(scRNAseq))
BiocManager::install(c( 'scRNAseq'),ask = F,update = T)
数据读取
小鼠大脑单细胞RNA-seq数据集,说明如下:
Obtain the Zeisel brain data Description Obtain the mouse brain single-cell RNA-seq dataset from Zeisel et al. (2015). Usage ZeiselBrainData(ensembl = FALSE, location = TRUE)
library(scRNAseq)
example_sce <- ZeiselBrainData()
example_sce
## class: SingleCellExperiment
## dim: 20006 3005
## metadata(0):
## assays(1): counts
## rownames(20006): Tspan12 Tshz1 ... mt-Rnr1 mt-Nd4l
## rowData names(1): featureType
## colnames(3005): 1772071015_C02 1772071017_G12 ... 1772066098_A12
## 1772058148_F03
## colData names(10): tissue group # ... level1class level2class
## reducedDimNames(0):
## mainExpName: endogenous
## altExpNames(2): ERCC repeat
例子操作
1. 绘制QC分布图
在单细胞分析流程中,质控是一个常见的步骤包括去除受损细胞和低质量文库。
library(scater)
example_sce <- addPerCellQC(example_sce, subsets = list(Mito = grep("mt-", rownames(example_sce))))
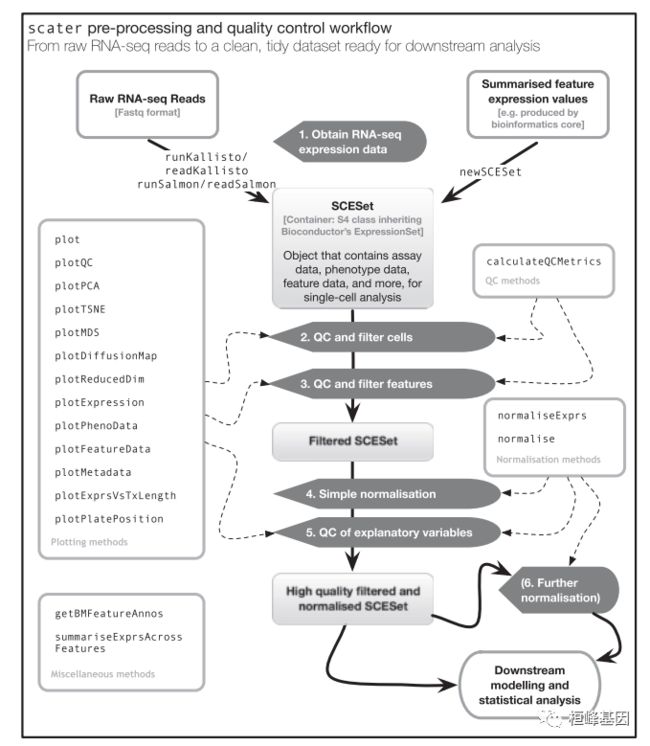
可以使用plotColData()函数相互绘制源数据变量,看到检测到的基因数量随着总计数的增加而增加。每个点代表一个细胞,根据细胞的起源组织着色。
plotColData(example_sce, x = "sum", y = "detected", colour_by = "tissue")
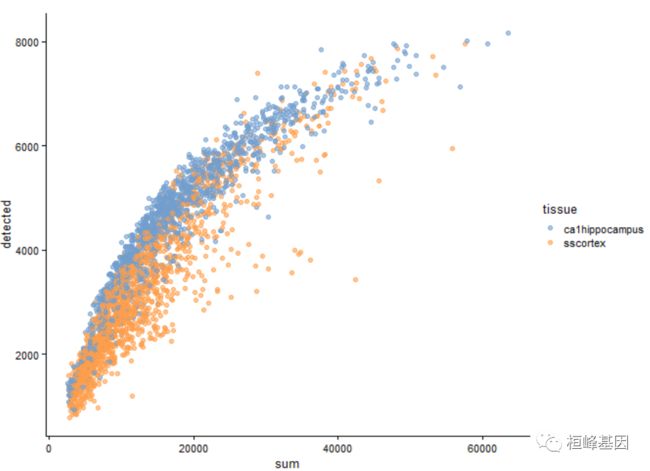
我们根据线粒体含量绘制了每个细胞的总计数。表现良好的细胞应该具有大量表达的特征,并且特征控件的表达比例较低。特征控件的高表达率和很少表达的特征表明空白和失败的细胞。对于某些种类,我们根据起源的组织而定。
plotColData(example_sce, x = "sum", y = "subsets_Mito_percent", other_fields = "tissue") +
facet_wrap(~tissue)
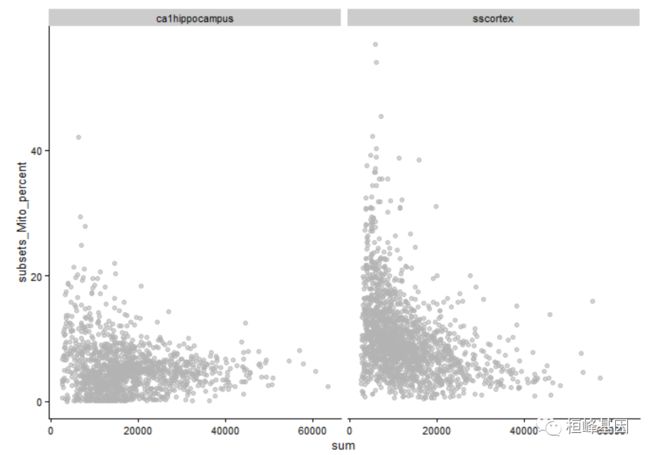
在基因层面,我们可以看一图,显示了前50个(默认)表达最多的特征。图中的每一行对应一个基因;每个条对应一个单细胞中一个基因的表达;圆圈表示每个基因表达的中位数,以此来排序基因。我们希望看到“常见的问题”,即线粒体基因、肌动蛋白、核糖体蛋白、MALAT1。一些 spike-in 转录也可能出现在这里,尽管如果所有 spike-in 转录都在前50名,这表明添加了太多的 spike-in RNA。大量的伪基因或预测基因可能表明比对存在问题。
plotHighestExprs(example_sce, exprs_values = "counts")
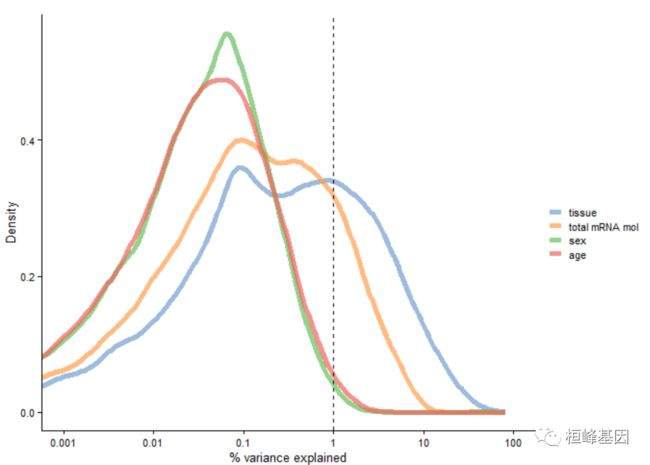
变量级度量由 getVarianceExplained() 函数计算。这将计算由 SingleCellExperiment 对象的 colData 中的每个变量解释的每个基因表达的方差百分比。然后我们可以用这个来确定哪些实验因素对表达的方差贡献最大。这对于诊断批量效应或快速验证治疗是否有效果是有用的。
计算方差对log(counts)进行解释,使统计数据反映相对表达式的变化。
example_sce <- logNormCounts(example_sce)
vars <- getVarianceExplained(example_sce, variables = c("tissue", "total mRNA mol",
"sex", "age"))
head(vars)
## tissue total mRNA mol sex age
## Tspan12 0.02207262 0.074086504 0.146344996 0.09472155
## Tshz1 3.36083014 0.003846487 0.001079356 0.31262288
## Fnbp1l 0.43597185 0.421086301 0.003071630 0.64964174
## Adamts15 0.54233888 0.005348505 0.030821621 0.01393787
## Cldn12 0.03506751 0.309128294 0.008341408 0.02363737
## Rxfp1 0.18559637 0.016290703 0.055646799 0.02128006
plotExplanatoryVariables(vars)
2.表达数据可视化
plotExpression()函数使绘制基因或特性子集的表达式值变得很容易。这对于从差异表达测试、假时间分析或其他分析中确定的特征的进一步检查特别有用。默认情况下,它在“logcounts”测试中使用表达式值,但这可以通过exprs_values参数进行更改。
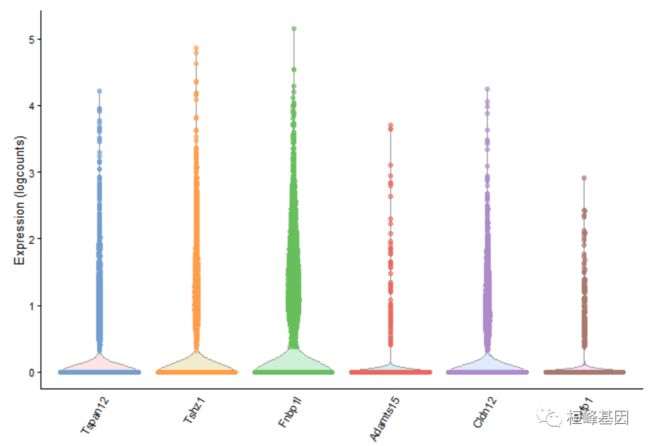
plotExpression(example_sce, rownames(example_sce)[1:6], x = "level1class")
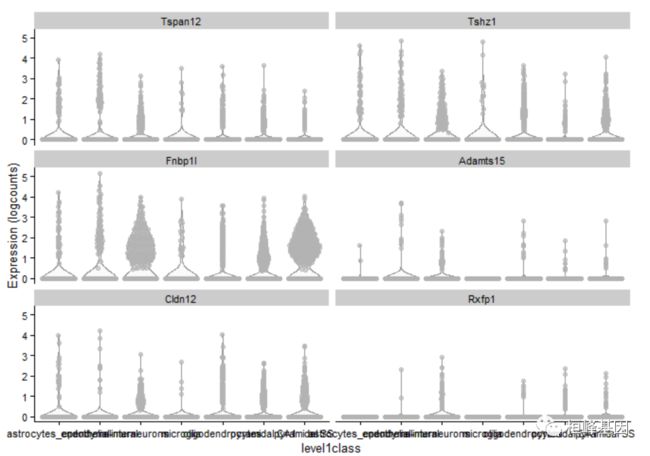
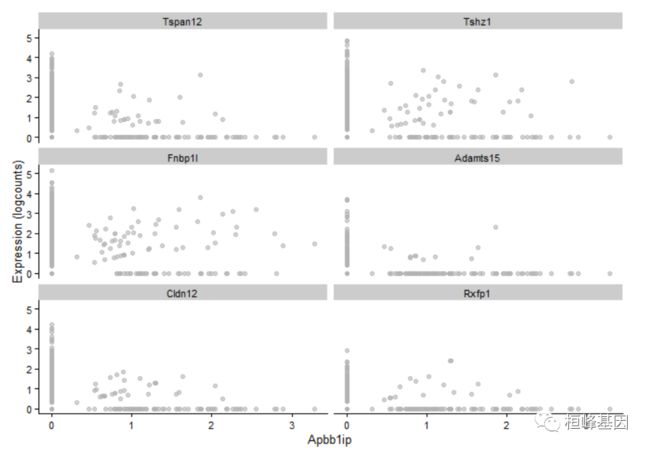
设置x将决定在x轴上显示的协变量。这可以是列元数据中的一个字段或特性的名称(以获得跨单细胞的表达式配置文件)。分类协变量将产生如上所示的分组小提琴,每个特征有一个面板。相比之下,连续协变量将在每个面板中生成散点图,如下图所示:
plotExpression(example_sce, rownames(example_sce)[1:6], x = rownames(example_sce)[10])
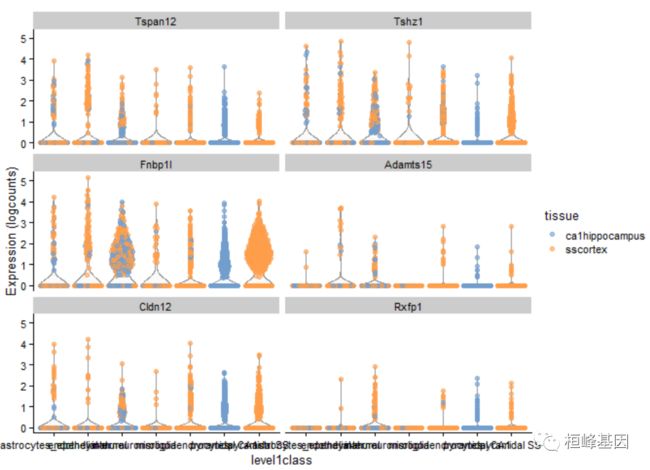
还可以根据列元数据或表达式值对点进行着色、塑形或调整大小:
plotExpression(example_sce, rownames(example_sce)[1:6], x = "level1class", colour_by = "tissue")
不需要任何x或其他视觉参数,直接绘制基因表达图,就会生成一组分组的小提琴图,并以一种赏心悦目的方式着色。
plotExpression(example_sce, rownames(example_sce)[1:6])
3. 降维
这里面降维方法包括三种PCA,t-SNE, UMAP, 后面的两种方法我们在机器学习中都有介绍。
1. PCA 降维
主成分分析(PCA)通常在下游分析之前进行去噪和压缩数据。runPCA()函数为r Biocpkg(“BiocSingular”)中的基本机制提供了一个简单的包装,用于从经过对数转换的表达式值计算pc。这将输出存储在singlecelexperiment的reduceddimms插槽中,可以很容易地检索(以及每台PC解释的方差百分比),如下所示:
example_sce <- runPCA(example_sce)
str(reducedDim(example_sce, "PCA"))
## num [1:3005, 1:50] 15.4 15 17.2 16.9 18.4 ...
## - attr(*, "dimnames")=List of 2
## ..$ : chr [1:3005] "1772071015_C02" "1772071017_G12" "1772071017_A05" "1772071014_B06" ...
## ..$ : chr [1:50] "PC1" "PC2" "PC3" "PC4" ...
## - attr(*, "varExplained")= num [1:50] 478 112.8 51.1 47 33.2 ...
## - attr(*, "percentVar")= num [1:50] 39.72 9.38 4.25 3.9 2.76 ...
## - attr(*, "rotation")= num [1:500, 1:50] -0.1471 -0.1146 -0.1084 -0.0958 -0.0953 ...
## ..- attr(*, "dimnames")=List of 2
## .. ..$ : chr [1:500] "Plp1" "Trf" "Mal" "Apod" ...
## .. ..$ : chr [1:50] "PC1" "PC2" "PC3" "PC4" ...
默认情况下,runPCA()使用方差最高的前500个基因来计算第一个pc。这可以通过指定subset_row来传递一组显式的感兴趣的基因,并通过使用ncomponents来确定要计算的组件数量来进行调优。name参数还可用于更改reduceddim插槽中的结果名称。
example_sce <- runPCA(example_sce, name = "PCA2", subset_row = rownames(example_sce)[1:1000],
ncomponents = 25)
str(reducedDim(example_sce, "PCA2"))
## num [1:3005, 1:25] 20 21 23 23.7 21.5 ...
## - attr(*, "dimnames")=List of 2
## ..$ : chr [1:3005] "1772071015_C02" "1772071017_G12" "1772071017_A05" "1772071014_B06" ...
## ..$ : chr [1:25] "PC1" "PC2" "PC3" "PC4" ...
## - attr(*, "varExplained")= num [1:25] 153 35 23.5 11.6 10.8 ...
## - attr(*, "percentVar")= num [1:25] 22.3 5.11 3.42 1.69 1.58 ...
## - attr(*, "rotation")= num [1:1000, 1:25] 2.24e-04 8.52e-05 2.43e-02 5.92e-04 6.35e-03 ...
## ..- attr(*, "dimnames")=List of 2
## .. ..$ : chr [1:1000] "Tspan12" "Tshz1" "Fnbp1l" "Adamts15" ...
## .. ..$ : chr [1:25] "PC1" "PC2" "PC3" "PC4" ...
2. t-SNE 降维
t-SNE广泛用于复杂单细胞数据集的可视化。对PCA图描述的相同程序可以应用于使用plotTSNE生成t-SNE图,通过r CRANpkg(“Rtsne”)包使用runTSNE获得坐标。我们强烈建议生成不同随机种子和困惑度值的地块,以确保任何结论都不适合不同的可视化。
set.seed(1000)
example_sce <- runTSNE(example_sce, perplexity = 10)
head(reducedDim(example_sce, "TSNE"))
## [,1] [,2]
## 1772071015_C02 -52.64155 -12.74189
## 1772071017_G12 -56.19082 -11.91368
## 1772071017_A05 -52.27747 -12.67960
## 1772071014_B06 -55.85604 -11.55292
## 1772067065_H06 -55.55389 -10.98767
## 1772071017_E02 -56.46232 -11.45086
更常见的模式包括使用预先存在的PCA结果作为t-SNE算法的输入。这是有用的,因为它通过使用表达式矩阵的低秩逼近提高了速度;并通过关注变异的主要因素来减少随机噪声。下面的代码使用之前计算的PCA结果的前10个维度来执行t-SNE。
set.seed(1000)
example_sce <- runTSNE(example_sce, perplexity = 50, dimred = "PCA", n_dimred = 10)
head(reducedDim(example_sce, "TSNE"))
## [,1] [,2]
## 1772071015_C02 -37.80993 0.7202884
## 1772071017_G12 -35.66210 -0.1025141
## 1772071017_A05 -38.20864 1.1509523
## 1772071014_B06 -38.20916 -0.5252747
## 1772067065_H06 -40.56988 -1.2929735
## 1772071017_E02 -38.47282 2.3718553
3. UMAP 降维
example_sce <- runUMAP(example_sce)
head(reducedDim(example_sce, "UMAP"))
## [,1] [,2]
## 1772071015_C02 12.30272 -4.936290
## 1772071017_G12 12.23251 -5.022809
## 1772071017_A05 12.30187 -4.904101
## 1772071014_B06 12.26755 -4.976097
## 1772067065_H06 12.21509 -5.026264
## 1772071017_E02 12.23191 -5.024976
4. 降维可视化
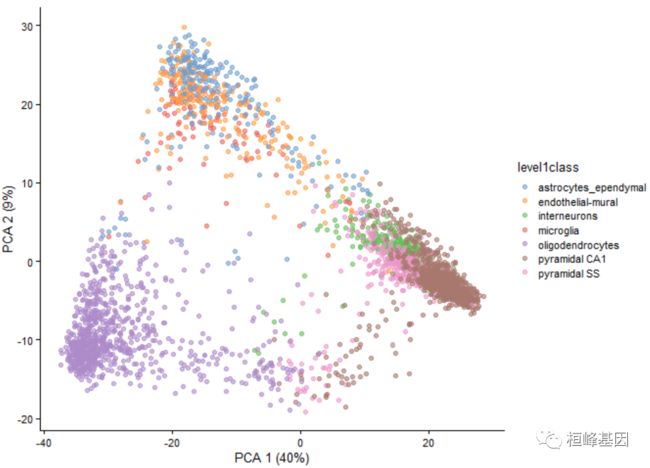
可以使用plotReducedDim函数绘制任何降维结果。在这里,每个点代表一个单细胞,并根据单细胞类型标签着色。
1. PCA 降维结果
plotReducedDim(example_sce, dimred = "PCA", colour_by = "level1class")
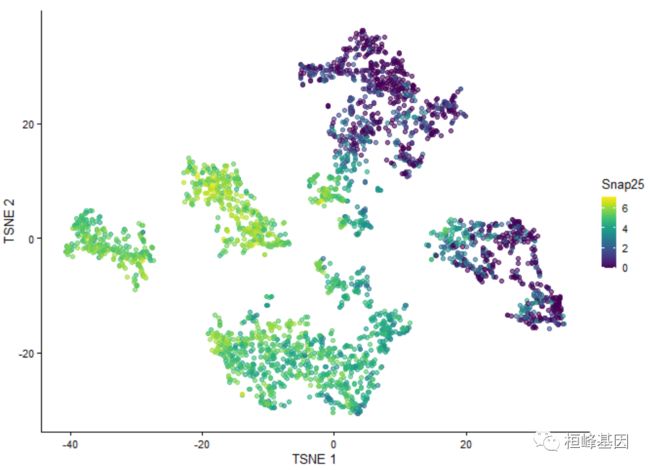
2. t-SNE 降维结果
为了方便起见一些结果类型有专门的包装器,例如,plotTSNE()用于t-SNE结果:
plotTSNE(example_sce, colour_by = "Snap25")
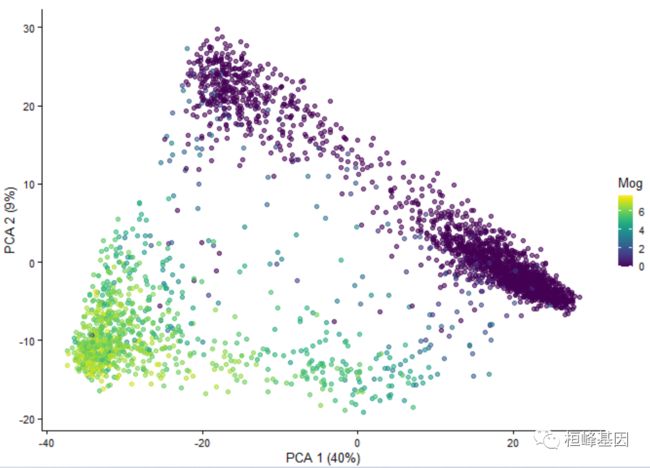
3. 方差百分比添加到坐标轴
专用的plotPCA()函数还将方差百分比添加到坐标轴:
plotPCA(example_sce, colour_by = "Mog")
4. 绘制多个分量
可以在一系列成对图中绘制多个分量。当绘制超过两个分量时,散点图矩阵中的对角线方框显示每个分量的密度。
example_sce <- runPCA(example_sce, ncomponents = 20)
plotPCA(example_sce, ncomponents = 4, colour_by = "level1class")
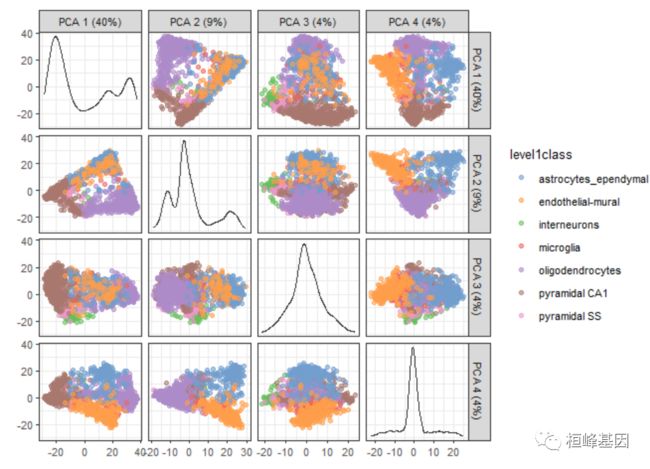
我们将这些函数的执行从绘图中分离出来,以便在多个绘图中重用相同的坐标。这避免了为了改变不同情节的美感而重复地重新计算这些坐标。
5. 定制可视化的实用工具
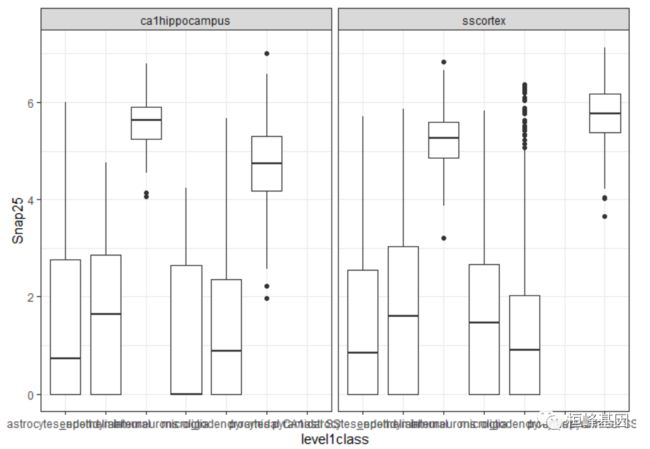
该软件包提供了一些辅助函数轻松地将 SingleCellExperiment 对象转换为data.frame,以用于ggplot2 函数。这允许用户创建现有的 scater 功能没有覆盖的高度定制模块。ggcells()函数将智能地从colData()、assays()、altExps()、reducedDim()中检索字段,以创建一个单独的数据帧以供立即使用。在下面的例子中,我们创建了按细胞类型和起源组织分层的Snap25表达的箱线图:
ggcells(example_sce, mapping = aes(x = level1class, y = Snap25)) + geom_boxplot() +
theme(axis.text.x = element_text(angle = 90)) + facet_wrap(~tissue) + theme_bw()
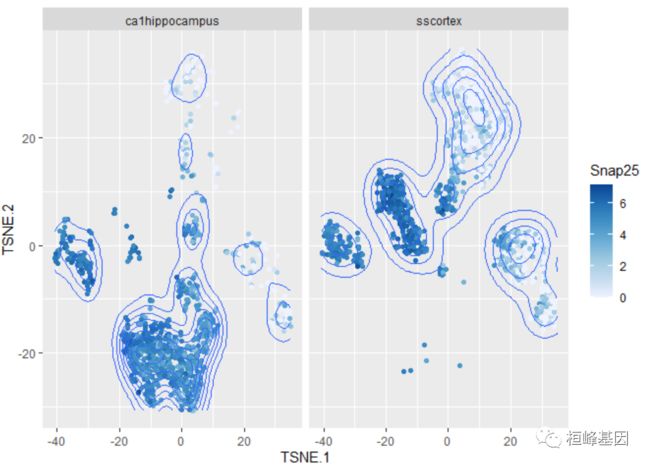
可以很容易地拉入降低维度的结果,以创建plotReducedDim()输出的定制等效物。在这个例子中,我们创建了一个t-SNE,由Snap25表达式着色:
ggcells(example_sce, mapping = aes(x = TSNE.1, y = TSNE.2, colour = Snap25)) + geom_point() +
stat_density_2d() + facet_wrap(~tissue) + scale_colour_distiller(direction = 1)
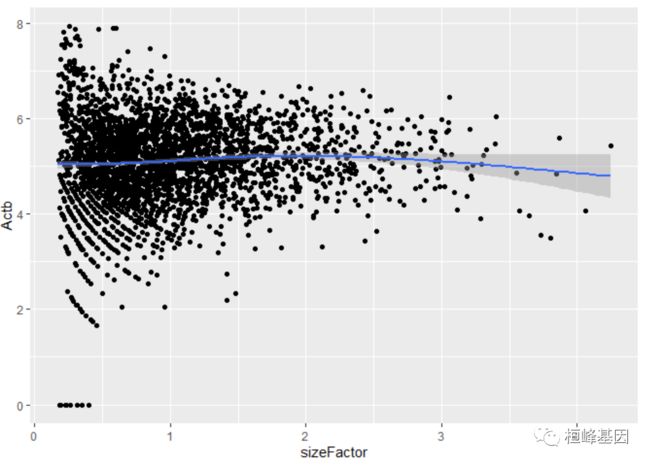
检验尺寸因素与归一化基因表达之间的关系也很直接:
ggcells(example_sce, mapping = aes(x = sizeFactor, y = Actb)) + geom_point() + geom_smooth()
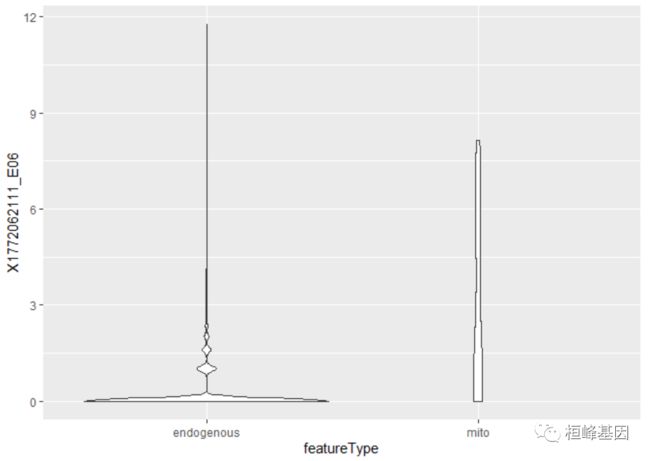
可以使用ggfeatures()函数对特性执行类似的操作,该函数将从rowData或分析的列中检索值。在这里,我们检查了特征类型和给定单元格内表达式之间的关系;注意重命名语法上无效的细胞名称。
colnames(example_sce) <- make.names(colnames(example_sce))
ggfeatures(example_sce, mapping = aes(x = featureType, y = X1772062111_E06)) + geom_violin()
所有的可视化分析就基本完成了,学会了单细胞分析就非常简单了,目前测序的费用也在降低,单细胞系列可算是目前的测序神器,有这方面需求的老师,联系桓峰基因,提供最高端的科研服务!
桓峰基因,铸造成功的您!
未来桓峰基因公众号将不间断的推出单细胞系列生信分析教程,
敬请期待!!
有想进生信交流群的老师可以扫最后一个二维码加微信,备注“单位+姓名+目的”,有些想发广告的就免打扰吧,还得费力气把你踢出去!
References:
-
Davis J McCarthy, Kieran R Campbell, Aaron T L Lun, Quin F Wills, Scater: pre-processing, quality control, normalization and visualization of single-cell RNA-seq data in R, Bioinformatics, Volume 33, Issue 8, 15 April 2017, Pages 1179–1186,
-
Zeisel A et al. (2015). Brain structure. Cell types in the mouse cortex and hippocampus revealed by single-cell RNA-seq. Science 347(6226), 1138-42.