【前端升全栈】五分钟了解项目开发的登录部分
目录
1.登录开始
5.session介绍
6.session演示
7.从session到Redis
8.Redis
9.nodejs链接Redis的demo
10.node.js链接Redis封装工具函数
11.session存入Redis
12.完成server端登录代码
13. 联调-html界面
14.Nginx配置
1.登录开始
登录:
- 核心:登录校验&登录信息存储
- 为何只讲登录,不讲注册?
Mysql 是硬盘数据库,redis 是内存数据库。
目录:
- cookie和session
- session写入 redis
- 开发登录功能,和前端联调(用到 nainy后向代THP
2.cookie简介
主要了解什么?
- 什么是cookie
- javascript操作cookie ,浏览器中查看cookie
- server端操作cookie ,实现登录验证
跨域不共享就是说淘宝和百度的 cookie 是不一样的,各自有各自的 cookie。
什么是cookie?
- 存储在浏览器的一段字符串(最大5kb )
- 跨域不共享
- 格式如k1=v1; k2=v2; k3=v3;因此可以存储结构化数据
请求域的 cookie 就是说请求什么如请求百度的 xx 文件就是请求百度的 cookie(不管是在什么页面请求,主要看的是请求的是谁而不是看在什么页面)。
cookie:
- 每次发送http请求,会将请求域的cookie一起发送给server
- server可以修改cookie并返回给浏览器
- 浏览器中也可以通过javascript修改cookie(有限制)
客户端JavaScript操作cookie:
- 客户端查看cookie ,三种方式
- javascript查看、修改cookie(有限制)
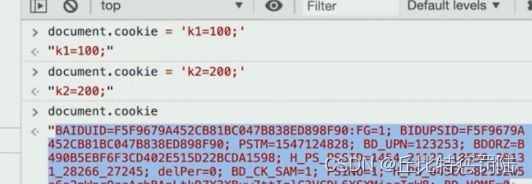
3.cookie用于登录验证
server端Nodejs操作cookie:
- 查看cookie
- 修改cookie
- 实现登录验证
回到 app.js,我们来解析 cookie,查看请求的 headers 就可以拿到 cookie,没有就返回空字符串,需要注意的是由于返回的是字符串,使用不是很方便,所以这里还需要解析成对象。 通过split先拆分;拿到每一组,再通过=拆分拿到key和value。我们尝试一下,要是想删除 cookie 的话可以前往 application删。
/解析cookie
req.cookie=//定文一个存放cookie的对象
const cookiestr = req.headers.cookie |l"//拿到cookie字符串或者空字符串cookiestr.split('; ').forEach(item => {//通过;分割出一组cookie
if (litem){
return
const arr = item.split('=')1/通过-分割每一组cookie的key和vaLueconst key = arr[o]
const value = arr[1]req.cookie[key] = value))
console.log(req.cookie)//到此各地皆可以使用req.cookie来获取已经解析完成的cookie了
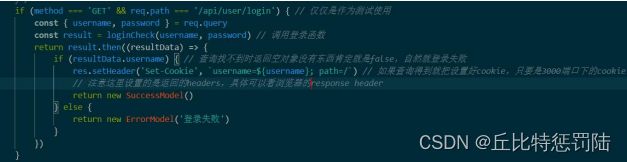
if (method === 'GET' &8 req.path === '/api/user/login-test') {
if (req.cookie.username){//通过查看cookie里面有没有username这个key判断是否登录成功(注意有个
return Promise.resolve(new successMode1('登录成功'))
return Promise.resolve(new ErrorModel(尚未登录'))
}
在上面的验证可以生效后我们就可以使用了,在用户登录的 时候同时设置好 cookie,且设置为根路径方便 3000 端口下的都可以访问到,这一步的话由于改成 GET,需要在路径加上密码用户名,访问后就设置好了 cookie,再回 test 测试是否可以成功验证.
4.cookie做限制

5.session介绍
session:
- 上—节的问题:会暴露username ,很危险
- 如何解决:cookie中存储userid , server 端对应username
- 解决方案:session ,即server端存储用户信息
 session
session
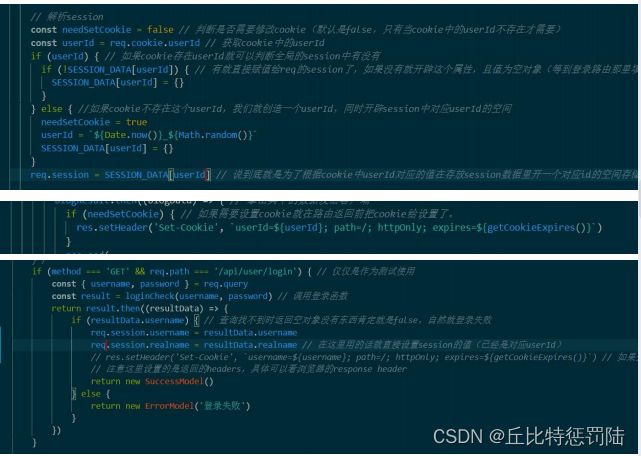
如上图,浏览器中 cookie 提供了 id,传到服务端,服务端可 以有 xxx 对应什么内容,yyy 对应什么内容的约定等等。 回到 app.js 定义一个 SESSION_DATA 的常量,在解析 cookie 后就可以来解析这个 session,判断 cookie 是否有 userId,有 则判断常量里面是否存在 userId,如果不存在则将常量的userId 属性设置为空对象,再赋值给我们的 req.session。如果 cookie 没有 userId 我们就随便定义一个时间戳再去赋值给常量里面的 userId 最后再赋值给我们的 req.session。
这个还是加多一个判断,定义一个 needSetCookie 状态,看看是否需要设置 cookie(cookie 不存在 userId 的时候就要), 实现在 blogs 和 users 的路由,把 userId 设置到 cookie 上。 那么怎么使用呢?这个就需要到登录那里原本设置cookie的可以去掉了,改为设置 session,同时验证登录的时候也改成判断 session。
6.session演示
总计:
- 知道session解决什么问题;
- 如何实现session
所以说 cookie 中 userId 只是为了给我这个专属的 userId 开辟 一个独特的存放 session 的空间,而 session 则是保存了实际的信息。
7.从session到Redis
session的问题:
- 目前session直接是js 变量,放在nodejs进程内存中
- 第一,进程内存有限,访问量过大,内存暴增怎么办?
- 第二,正式线上运行是多进程,进程之间内存无法共享
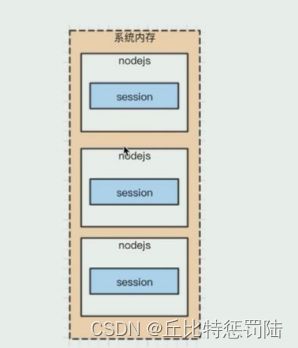
如图就是进程的内存模型,其中 0x1000 是起始地址,0x8000 是结束地址,stack 储存的是程序运行的基础变量(js 的基础 变量),heap 存的是程序运行的引用变量(js 的数组对象什么的,session 也放在这里),存的越多,占的就越多(越高) 如果上下接起来那就崩了。
 进程内存模型
进程内存模型
操作系统会限制一个进程的最大可用内存(大概是 3G),而 session 是存在一个 node.js 进程的,不可能无限储存,一旦存的太多,撑爆 node.js 进程就 GG。
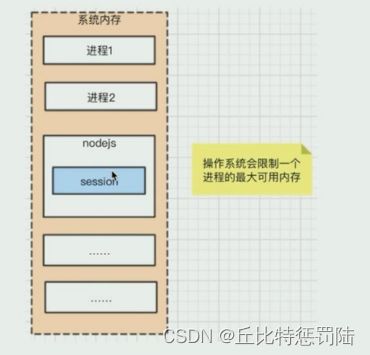
上线的时候每个 node.js 程序都是分多个进程来跑的,因为 单个进程占的内存有限,也浪费其它的内存。而且多核的处 理器可以处理多个进程。这是符合内存与 cpu 的实际情况。 当然进程之间是不能互相访问的,不能共享数据什么的(你 个 QQ 进程总不能去访问我微信进程的数据吧)。回到 node.js,其实每次访问的进程是不一定的(PM2 分配进程, 都挤一个迟早升天),这就导致我在其中一个进程有数据, 到另一个就没有数据了。
存放内存中意味着读取很快但是也比较昂贵,空间少,一断电就没了(易丢失)
解决方案Redis:
- web server最常用的缓存数据库,数据存放在内存中
- 相比于mysql,访问速度快(内存和硬盘不是一个数量级的)
- 但是成本更高,可存储的数据量更小(内存的硬伤)
也就是说 redis(内存数据库)和 mysql(硬盘数据库)都是储存数据的;
 解决方案Redis
解决方案Redis
解决方案Redis:
- 将web server和redis 拆分为两个单独的服务
- 双方都是独立的,都是可扩展的(例如都扩展成集群)
- (包括mysql ,也是一个单独的服务,也可扩展)
解决问题就是将session存放到redis中就行(之前是存在web server)。而既然分开了,redis 储存多少就不管 node.js 进程的事情了(因为分开了啊,变成两个东西),再说访问,因 为就是这一个 redis,不管谁访问还是访问这一个,也就一份数据,不管是哪个进程访问都给一样的数据。就像是一个独立的仓库。就算是太多了,redis 也可以拆分成集群/机房什么的,不需要我们关心。不考虑丢失数据的意思是重新登录即可。
为何session适合用Redis?
- session访问频繁,对性能要求极高
- session可不考虑断电丢失数据的问题(内存的硬伤)
- session数据量不会太大(相比于mysql 中存储的数据)
为何网站数据不适合使用Redis?
- 操作频率不是太高(相比于session操作)
- 断电不能丢失,必须保留
- 数据量太大,内存成本太高
8.Redis

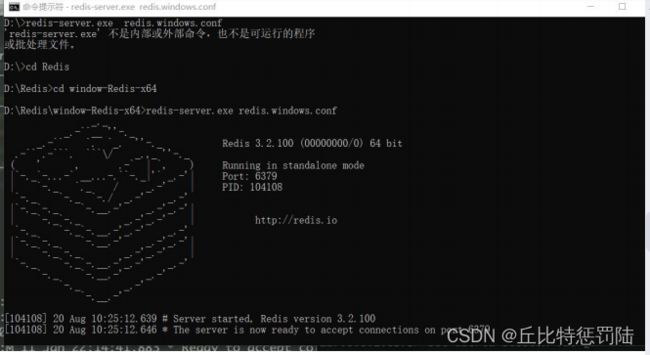
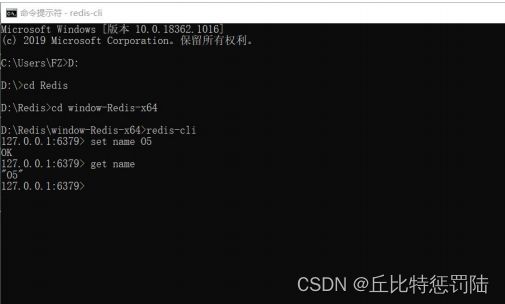
9.nodejs链接Redis的demo
用Redis存储session:
- nodejs连接redis的demo
- 封装成工具函数,可供API使用
新建一个 redis-test 的目录,然后 npm 初始化,新建一个 index.js,安装 redis(npm 安装),引入 redis。创建客户端, 需要使用 createClient 方法,传入端口号(默认 6379),主 机名。调用 on 监听 error。接下来就可以通过 set 方法设置 key 了(可以加多一给 redis.print 的属性,完成会打印出来成功的提示)。
get 方法需要传入一个回调函数监听 err 和真正的值(异步), 获取完成就调用 quit 方法退出。Shutdown 就是关闭 redis。
const redis =require(" redis")引入redis
const redisclient = redis.createclient(6379,'127.0.0.1')1/创建客户端
redisclient.on( 'error' , err =>{//监听错误
console.log(err)
}
redisclient.set('myname' , 'xiangbei' , redis.print)//设置键值且打印成功提示
redisclient.get('myname' , (err,val)=>{1/获取犍值且获取完成关闭客户端
if (err){
console.log(err)
return
console.log('val:' , val)redisclient.quit()
})
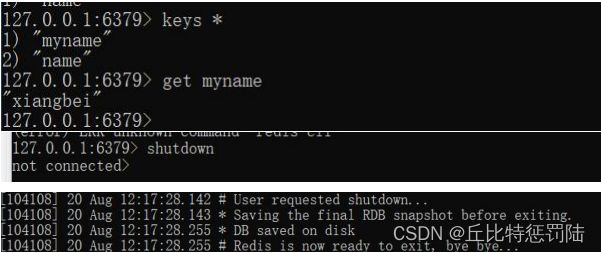
10.node.js链接Redis封装工具函数
接下来就可以把 redis 给封装起来,注意我们回到 blog 重启的话会让我们处于未登录状态,原因也很简单,因为设置session 数据是写在 app.js 中,默认是空对象,这个问题可以通过引入 redis 解决(再重启就是重启 blog 了,与 redis 没有关系,不会丢失登录)。
REDIS CONF ={
port: 6379,
host: '127.0.8.1'
}
const redis =require( 'redis')
const { REDIS_CONF} = require( '../conf/db')
//创建一个客户端
const redisclient = redis.createclient(REDIS_CONF.portm,REDIS_CONF.host)
redisclient.on( 'error', err =>{
console.log(err)
))
//定义设置redis的方法
function set (key, val){
if (typeof val === 'object') {//如果值是对象则转换为json字符串
val = JSoN.stringify(val)
}
redisClient.set(key, val,redis.print)
}
11.session存入Redis
let needsetcookie = false
let userId = req.cookie.userIdif (l userId){
needsetcookie = true
userId =“s{Date.nok(]${Math.random(1
//设置redis中的session(不要管是userid还是sessionId,反正就是同一个时间戳而已2)set(userId,0)
//i27.0.0.1;6379get i59791251814I_8.7153950171260812“”
获取session
req.sessionId = userId //同一个时网戳换个表达而已,才能让各地使用
get(req.sessionTd) then((sessionData) ={/这里的sessionData就是根操key lblsessionId拿到对应的值《可能找不到即为nutL)if (sessionData -- null) {
lset(req, sessionId,(H)1/似乎没有必要,之前已经设置过时何戢为空对象,但是!!那是因为不存在userId才建的! !req.session - o再把当前session票空(开辟空向)
else (
req.session = sessionbatal
应值给’127.0.0.1:6379 get 1597912518141_0.7153950171260812 "“(1"usernamel" l "qibin ", "reaLnamel"; ["lxe)xaalxe1 xe5l:85luxb国
console.log( sessionbata)return getPostData(req))
12.完成server端登录代码
//登录验证函数
const LoginCheck = (req) => {
if ( req . sessi son. username) {
return Promi se.resolve(
new ErrorModel(”尚未登录”)
}
}
}

13. 联调-html界面
和前端联调:
- 登录功能依赖cookie , 必须用浏览器来联调
- cookie跨域不共享的,前端和server端必须同域
- 需要用到nignx做代理,让前后端端同域
有关的 html 已经写好了,比较简单这里直接用就行。安装 http-server,启动 http-serve -p 8001,这个时候启动浏览器,它请求的诸如博客 list 什么的都是以 8001 开头的,自然是找
14.Nginx配置
Nginx介绍:
- 高性能的web服务器,开源免费
- 一般用于做静态服务、 负载均衡(本课用不到)
- 还有反向代理(本课用到)
如下图所示,先经过 nginx,再由 nginx 根据路径(带有 api 的走 8000 的 node.js,其余的走 8001 的 html 界面)。
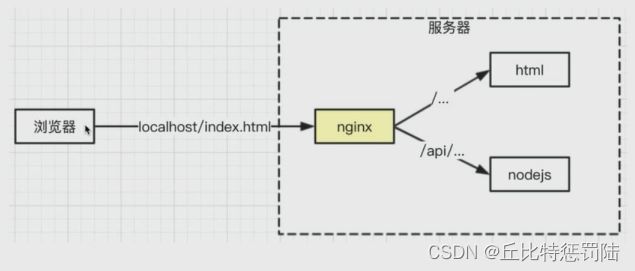 Nginx反向代理
Nginx反向代理
反向代理就是对客户端不可见(就不看调试里面发送的请求是不知道我的实际地址什么的)的代理(只能由服务端控制),相反的是正向代理,由客户端来控制的代理。
Nginx命令:
- 测试配置文件格式是否正确nginx -t
- 启动nginx;重启 nginx -S reload
- 停止nginx -S stop
接下来我们就来配置一下 nginx,打开配置文件,可以在第 3 行加上 worker_processes 2;(cpu 有几核就写多少,就可以启动多少个 nginx 进程,性能也就越高,只不过这个一般是运维的人管的,我们不写也行)。 来到 35 行第一个 server,改成 8080 端口,43 行找到 location 这个是我们不用,用#将它们注释掉,写自己的代理,代理分为两个,一个是/即根目录开始的(html)走 8001,一个是 api 开始的(node.js)走 8000(这个还需要把 host 传过去)。
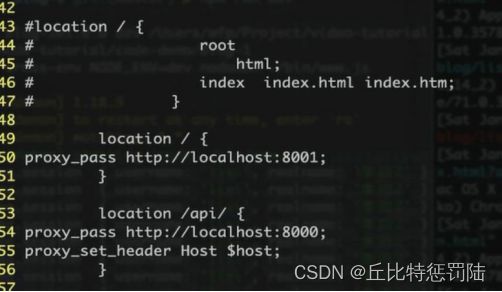
保存完成我们利用 nginx -t 测试一下,成功的话则启动 nginx发现可以访问了。