大数据学习之Flink——13Window详解
Windows 计算是流式计算中非常常用的数据计算方式之一, 通过按照固定时间或长度将数据流切分成不同的窗口, 然后对数据进行相应的聚合运算, 从而得到一定时间范围内的统计结果。
一. Window分类
1. Global Window 和 Keyed Window
在运用窗口计算时,Flink根据上游数据集是否为KeyedStream类型,对应的Windows 也 会有所不同。
- Keyed Window: 上游数据集如果是KeyedStream类型, 则调用 DataStream API的 window() 方法, 数据会根据 Key在不同的Task实例中并行分别计算, 最后得出针对每个Key统计的结果。
- Global Window: 如果是Non-Keyed类型, 则调用WindowsAll()方法, 所有的数据都会在窗口算子中由到一个Task中计算, 并得到全局统计结果。
2. Time Window(时间窗口)
根据不同的业务场景, Time Window也可以分为三种类型, 分别是滚动窗口(Tumbling Window)、滑动窗口(Sliding Window)和会话窗口(Session Window)
1. 滚动窗口(Tumbling Window)
-
滚动窗口是根据固定时间进行切分,且窗口和窗口之间的元素互不重叠。这种类型的窗 口的最大特点是比较简单。只需要指定一个窗口长度(window size).

-
问题: 每隔10s统计每个基站的日志数量
package com.hjf.window import com.hjf.dataSource.{CustomerSource, StationLog} import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment import org.apache.flink.streaming.api.windowing.assigners.TumblingEventTimeWindows import org.apache.flink.streaming.api.windowing.time.Time object TestTumblingWindow { def main(args: Array[String]): Unit = { val streamEnv: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment streamEnv.setParallelism(1) import org.apache.flink.streaming.api.scala._ val stream: DataStream[StationLog] = streamEnv.addSource(new CustomerSource) stream.map(log => (log.sid, 1)).keyBy(_._1) // 指定时间窗口的大小 // .timeWindow(Time.seconds(10)) .window(TumblingEventTimeWindows.of(Time.seconds(10))) .sum(1).print() streamEnv.execute() } }
2. 滑动窗口(Sliding Window)
-
滑动窗口也是一种比较常见的窗口类型, 其特点是在滚动窗口基础之上增加了窗口滑动时间(Slide Time), 且允许窗口数据发生重叠。当Windows size固定之后, 窗口并不像滚动窗口按照Windows Size向前移动, 而是根据设定的 Slide Time向前滑动. 窗口之间的 数据重叠大小根据Windows size和Slide time决定, 当Slide time小于Windows size便会发生窗口重叠, Slide size大于 Windows size就会出现窗口不连续, 数据可能不能在 任何一个窗口内计算, Slide size和Windows size相等时, Sliding Windows其实就是Tumbling Windows。

-
问题: 每隔5秒计算最近10秒内,每个基站的日志数量
package com.hjf.window import com.hjf.dataSource.{CustomerSource, StationLog} import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment import org.apache.flink.streaming.api.windowing.time.Time object TestSlidingWindow { def main(args: Array[String]): Unit = { val streamEnv: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment streamEnv.setParallelism(1) import org.apache.flink.streaming.api.scala._ val stream: DataStream[StationLog] = streamEnv.addSource(new CustomerSource) stream.map(log => (log.sid, 1)).keyBy(_._1) // 时间窗口为10s, 滑动步长为5s .timeWindow(Time.seconds(10), Time.seconds(5)) .sum(1).print() streamEnv.execute() } }
3. 会话窗口(Session Window)
- 会话窗口(Session Windows)主要是将某段时间内活跃度较高的数据聚合成一个窗口进行计算, 窗口的触发的条件是Session Gap, 是指在规定的时间内如果没有数据活跃接入, 则认为窗口结束, 然后触发窗口计算结果. 需要注意的是如果数据一直不间断地进入窗口, 也会导致窗口始终不触发的情况. 与滑动窗口、滚动窗口不同的是, Session Windows不需要有固定windows size和 slide time, 只需要定义session gap, 来规定不活跃数据的时间上限即可。
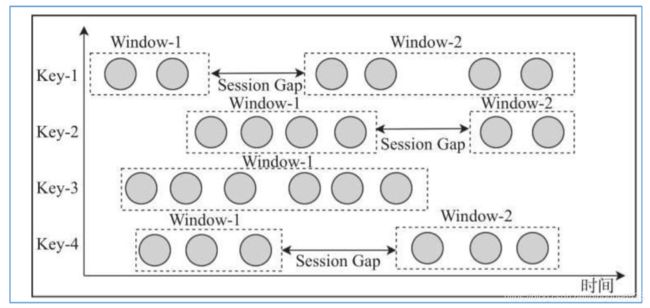
3. Count Window
基于基于输入数据数量的窗口
-
问题1: 每2个数据计算一次累加
package com.hjf.window import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment object TestCountWindow { def main(args: Array[String]): Unit = { val streamEnv: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment streamEnv.setParallelism(1) import org.apache.flink.streaming.api.scala._ val data: DataStream[(Int, Int)] = streamEnv.fromElements( (1, 2), (1, 3), (1, 7), (1, 2), (2, 4), (2, 6), (2, 3), (3, 4), (3, 1), (3, 3)) // 每2个数据计算一次累加 data.keyBy(_._1).countWindow(2).sum(1).print() streamEnv.execute() } }
-
问题2: 步长为3条数据, 窗口为2条数据,
package com.hjf.window import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment object TestCountWindow { def main(args: Array[String]): Unit = { val streamEnv: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment streamEnv.setParallelism(1) import org.apache.flink.streaming.api.scala._ val data: DataStream[(Int, Int)] = streamEnv.fromElements( (1, 2), (1, 3), (1, 7), (1, 2), (2, 4), (2, 6), (2, 3), (3, 4), (3, 1), (3, 3)) // 每2个数据计算一次累加 data.keyBy(_._1).countWindow(2, 3).sum(1).print() streamEnv.execute() } }
二. Window的API
Keyed Window 的算子:
在每个窗口算子中包含了 Windows Assigner、Windows Trigger(窗口触发器)、Evictor (数据剔除器)、Lateness(时延设定)、Output Tag(输出标签)以及 Windows Funciton 等组成部分,其中 Windows Assigner 和 Windows Funciton 是所有窗口算子必须指定的属性,其余的属性都是根据实际情况选择指定。
stream.keyBy(...) // 是Keyed类型数据集
.window(...) //指定窗口分配器类型
[.trigger(...)] //指定触发器类型(可选)
[.evictor(...)] //指定evictor或者不指定(可选)
[.allowedLateness(...)] //指定是否延迟处理数据(可选)
[.sideOutputLateData(...)] //指定Output Lag(可选)
.reduce/aggregate/fold/apply() //指定窗口计算函数
[.getSideOutput(...)] //根据Tag输出数据(可选)
- Windows Assigner:指定窗口的类型,定义如何将数据流分配到一个或多个窗口
- Windows Trigger:指定窗口触发的时机,定义窗口满足什么样的条件触发计算
- Evictor:用于数据剔除
- allowedLateness:标记是否处理迟到数据,当迟到数据到达窗口中是否触发计算
- Output Tag:标记输出标签,然后在通过 getSideOutput 将窗口中的数据根据标签输出
- Windows Funciton:定义窗口上数据处理的逻辑,例如对数据进行 sum 操作
三. 窗口聚合函数
1. 说明
- 如果定义了 Window Assigner 之后,下一步就可以定义窗口内数据的计算逻辑,这也就是 Window Function 的定义。Flink 中提供了四种类型的 Window Function,分别为 ReduceFunction、AggregateFunction 以及 ProcessWindowFunction,(sum 和 max)等
- 分类:
- 增量聚合函数:对应有 ReduceFunction、AggregateFunction
- 对应有 ProcessWindowFunction(还有 WindowFunction)
2. ReduceFunction
ReduceFunction 定义了对输入的两个相同类型的数据元素按照指定的计算方法进行聚合的逻辑,然后输出类型相同的一个结果元素。
- 每隔5秒统计每个基站的日志数量
package com.hjf.window import com.hjf.dataSource.{CustomerSource, StationLog} import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment import org.apache.flink.streaming.api.windowing.time.Time object TestReduceFunction { def main(args: Array[String]): Unit = { val streamEnv: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment streamEnv.setParallelism(1) import org.apache.flink.streaming.api.scala._ val stream: DataStream[StationLog] = streamEnv.addSource(new CustomerSource) stream.map(one => (one.sid, 1)).keyBy(_._1) // 每隔5秒统计每个基站的日志数量 .timeWindow(Time.seconds(5)) // 每隔3秒计算最近5秒内,每个基站的日志数量 //.timeWindow(Time.seconds(5), Time.seconds(3)) .reduce((v1, v2) => (v1._1, v1._2 + v2._2)) .print() streamEnv.execute() } }
3. AggregateFunction
和 ReduceFunction 相似,AggregateFunction 也是基于中间状态计算结果的增量计算函数,但 AggregateFunction 在窗口计算上更加通用。AggregateFunction 接口相对 ReduceFunction 更加灵活,实现复杂度也相对较高。AggregateFunction 接口中定义了三个需要复写的方法,其中 add()定义数据的添加逻辑,getResult 定义了根据 accumulator 计算结果的逻辑,merge 方法定义合并 accumulator 的逻辑。
- 每隔3秒计算最近5秒内,每个基站的日志数量
package com.hjf.window import com.hjf.dataSource.{CustomerSource, StationLog} import org.apache.flink.api.common.functions.AggregateFunction import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment import org.apache.flink.streaming.api.windowing.time.Time object TestAggregateFunction { def main(args: Array[String]): Unit = { val streamEnv: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment streamEnv.setParallelism(1) import org.apache.flink.streaming.api.scala._ val stream: DataStream[StationLog] = streamEnv.addSource(new CustomerSource) stream.map(one => (one.sid, 1)).keyBy(_._1) // 每隔5秒统计每个基站的日志数量 // .timeWindow(Time.seconds(5)) // 每隔3秒计算最近5秒内,每个基站的日志数量 .timeWindow(Time.seconds(5), Time.seconds(3)) .aggregate(new AggregateFunction[(String, Int), (String, Long), (String, Long)] { override def createAccumulator(): (String, Long) = ("", 0) override def add(in: (String, Int), acc: (String, Long)): (String, Long) = { (in._1, in._2 + acc._2) } override def getResult(acc: (String, Long)): (String, Long) = acc override def merge(acc: (String, Long), acc1: (String, Long)): (String, Long) = { (acc._1, acc._2 + acc1._2) } }).print() streamEnv.execute() } }
4. ProcessWindowFunction
前面提到的 ReduceFunction 和 AggregateFunction 都是基于中间状态实现增量计算的窗口函数,虽然已经满足绝大多数场景,但在某些情况下,统计更复杂的指标可能需要依赖于窗口中所有的数据元素,或需要操作窗口中的状态数据和窗口元数据,这时就需要使用到 ProcessWindowsFunction,ProcessWindowsFunction 能够更加灵活地支持基于窗口全部数据元素的结果计算
-
每隔5秒统计每个基站的日志数量
把5s内的数据存起来, 时间到了再统一计算
package com.hjf.window import com.hjf.dataSource.{CustomerSource, StationLog} import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment import org.apache.flink.streaming.api.scala.function.ProcessWindowFunction import org.apache.flink.streaming.api.windowing.time.Time import org.apache.flink.streaming.api.windowing.windows.TimeWindow import org.apache.flink.util.Collector object TestProcessWindowFunction { def main(args: Array[String]): Unit = { val streamEnv: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment streamEnv.setParallelism(1) import org.apache.flink.streaming.api.scala._ val stream: DataStream[StationLog] = streamEnv.addSource(new CustomerSource) stream.map(one => (one.sid, 1)).keyBy(_._1) // 每隔5秒统计每个基站的日志数量 .timeWindow(Time.seconds(5)) .process(new ProcessWindowFunction[(String, Int), (String, Int), String, TimeWindow] { // 一次窗口结束的时候调用一次 override def process(key: String, context: Context, elements: Iterable[(String, Int)], out: Collector[(String, Int)]): Unit = { // 整个窗口的数据保存到Iterable, 里面有很多数据 // Iterable的size就是数据的条数 out.collect(key, elements.size) } }).print() streamEnv.execute() } }
本文参考了尚学堂Flink的课件
侵权删