大数据学习之Flink——14Time详解
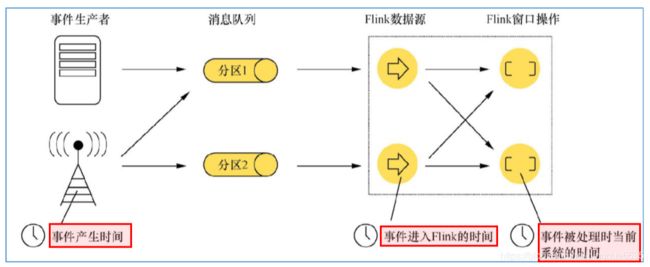
对于流式数据处理,最大的特点是数据上具有时间的属性特征,Flimk 根据时间产生的位置不同,将时间区分为三种时间语义,分别为事件生成时间(Event Time)、事件接入时 间(Ingestion Time)和事件处理时间(Processing Time)。
- Event Time:事件产生的时间,它通常由事件中的时间戳描述。
- Ingestion Time:事件进入 Flink 的时间。
- Processing Time:事件被处理时当前系统的时间。
一. 时间语义 Time
1. 分类
1. Processing Time
- **是指事件被处理时机器的系统时间。
- 当流程序在 Processing Time 上运**行时,所有基于时间的操作(如时间窗口)将使用当时机器的系统时间。每小时 Processing Time 窗口将包括在系统时钟指示整个小时之间到达特定操作的所有事件。
- Processing Time 是最简单的 “Time” 概念,不需要流和机器之间的协调,它提供了最好的性能和最低的延迟。但是,在分布式和异步的环境下,Processing Time 不能提供确定性,因为它容易受到事件到达系统的速度(例如从消息队列)、事件在系统内操作流动的速度以及中断的影响。
2. Event Time
-
Event Time 是事件发生的时间,一般就是数据本身携带的时间。这个时间通常是在事件到达 Flink 之前就确定的,并且可以从每个事件中获取到事件时间戳。在 Event Time 中,时间取决于数据,而跟其他没什么关系。Event Time 程序必须指定如何生成 Event Time 水印,这是表示 Event Time 进度的机制。
-
无论事件什么时候到达或者其怎么排序,最后处理 Event Time 将产生完全一致和确定的结果。但是,除非事件按照已知顺序(按照事件的时间)到达,否则处理 Event Time 时将会因为要等待一些无序事件而产生一些延迟。由于只能等待一段有限的时间,因此就难以保证处理 Event Time 将产生完全一致和确定的结果。
-
假设所有数据都已到达, Event Time 操作将按照预期运行,即使在处理无序事件、延迟事件、重新处理历史数据时也会产生正确且一致的结果。 例如,每小时事件时间窗口将包含带有落入该小时的事件时间戳的所有记录,无论它们到达的顺序如何。
-
有时当 Event Time 程序实时处理实时数据时,它们将使用一些 Processing Time 操作,以确保它们及时进行。
3. Ingestion Time
- Ingestion Time 是事件进入 Flink 的时间。 在源操作处,每个事件将源的当前时间作为时间戳,并且基于时间的操作(如时间窗口)会利用这个时间戳。
- Ingestion Time 在概念上位于 Event Time 和 Processing Time 之间。 与 Processing Time 相比,它稍微贵一些,但结果更可预测。因为 Ingestion Time 使用稳定的时间戳(在源处分配一次),所以对事件的不同窗口操作将引用相同的时间戳,而在 Processing Time 中,每个窗口操作符可以将事件分配给不同的窗口(基于机器系统时间和到达延迟)。
- 与 Event Time 相比,Ingestion Time 程序无法处理任何无序事件或延迟数据,但程序不必指定如何生成水印。
- 在 Flink 中,Ingestion Time 与 Event Time 非常相似,但 Ingestion Time 具有自动分配时间戳和自动生成水印功能。
2. 设置时间语义
-
在 Flink 中默认情况下使用是 Process Time 时间语义, 如果用户选择使用 Event Time 或者 Ingestion Time 语义, 则需要在创建的 StreamExecutionEnvironment 中调用 setStreamTimeCharacteristic() 方法设定系统的时间概念 , 如下 代码使用TimeCharacteristic.EventTime 作为系统的时间语义:
// 设置ProcessingTime时间语义[默认] streamEnv.setStreamTimeCharacteristic(TimeCharacteristic.ProcessingTime) // 设置EventTime时间语义[最常见] streamEnv.setStreamTimeCharacteristic(TimeCharacteristic.EventTime) // 设置IngestionTime时间语义 streamEnv.setStreamTimeCharacteristic(TimeCharacteristic.IngestionTime)
二. WaterMark 水位线
- 在使用 EventTime 处理 Stream 数据的时候会遇到数据乱序的问题, 流处理从 Event(事件)产生, 流经 Source, 再到 Operator, 这中间需要一定的时间. 虽然大部分情况下, 传输到 Operator 的数据都是按照事件产生的时间顺序来的, 但是也不排除由于网络延迟等原因而导致乱序的产生, 特别是使用 Kafka 的时候, 多个分区之间的数据无法保证有序. 因此, 在进行 Window 计算的时候, 不能无限期地等下去, 必须要有个机制来保证在特定的时间后, 必须触发 Window 进行计算, 这个特别的机制就是 Watermark(水位线). Watermark 是用于处理乱序事件的
1. Watermark 原理
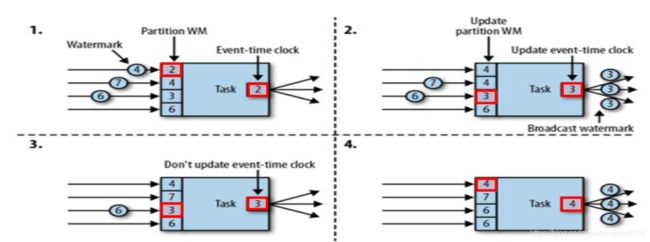
- 在 Flink 的窗口处理过程中, 如果确定全部数据到达, 就可以对 Window 的所有数据做窗口计算操作(如汇总、分组等), 如果数据没有全部到达, 则继续等待该窗口中的数据全部到达才开始处理. 这种情况下就需要用到水位线(WaterMarks)机制, 它能够衡量数据处理进度(表达数据到达的完整性), 保证事件数据(全部) 到达 Flink 系统, 或者在乱序及延迟到达时, 也能够像预期一样计算出正确并且连续的结果. 当任何 Event 进入到 Flink系统时, 会根据当前最大事件时间产生 Watermarks 时间戳。
- 计算 Watermak 的值:
Watermark = 进入 Flink 的最大的事件时间(mxtEventTime)— 指定的延迟时间(t) - 触发有 Watermark 的 Window 的函数
如果有窗口的停止时间等于或者小于 maxEventTime – t(当时的 warkmark),那么 这个窗口被触发执行。
当有新的时间进入Flink, 并且Watermark不变, 那么窗口会再触发
注意:Watermark 本质可以理解成一个延迟触发机制。
2. Watermark的使用情况
-
本来有序的Stream中的watermark
如果数据元素的事件时间是有序的, Watermark 时间戳会随着数据元素的事件时间按顺序生成, 此时水位线的变化和事件时间保持一直(因为既然是有序的时间,就不需要设置延 迟了,那么 t 就是 0。所以 watermark=maxtime-0 = maxtime),也就是理想状态下的水位 线。当 Watermark 时间大于 Windows 结束时间就会触发对 Windows 的数据计算,以此类推,下一个 Window 也是一样。

-
乱序事件中的 Watermark
现实情况下数据元素往往并不是按照其产生顺序接入到 Flink 系统中进行处理,而频繁出现乱序或迟到的情况,这种情况就需要使用 Watermarks 来应对。比如下图,设置延迟时间 t 为 2

-
并行数据流中的 Watermark
在多并行度的情况下, Watermark 会有一个对齐机制, 这个对齐机制会取所有 Channel 中最小的Watermark。
3. 引入Watermark 和 EventTime
1. 有序数据流中引入 Watermark 和 EventTime
-
对于有序的数据,代码比较简洁,主要需要从源 Event 中抽取 EventTime。
package com.hjf.time import com.hjf.dataSource.StationLog import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment object TestWatermark1 { def main(args: Array[String]): Unit = { val streamEnv: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment streamEnv.setParallelism(1) import org.apache.flink.streaming.api.scala._ val stream: DataStream[String] = streamEnv.socketTextStream("node01", 8888) stream.map(one => { val arr: Array[String] = one.split(",") new StationLog(arr(0).trim, arr(1).trim, arr(2).trim, arr(3).trim, arr(4).trim.toLong, arr(5).trim.toLong) }) // 指定表示EvenTime的字段 .assignAscendingTimestamps(_.callTime) .print() streamEnv.execute() } }
2. 乱序序数据流中引入 Watermark 和 EventTime
-
With Periodic(周期性的)Watermark
周期性地生成 Watermark 的生成, 默认是 100ms。每隔 N 毫秒自动向流里注入一个 Watermark,时间间隔由 streamEnv.getConfig.setAutoWatermarkInterval()决定 -
With Punctuated(间断性的)Watermark
间断性的生成 Watermark 一般是基于某些事件触发 Watermark 的生成和发送,比如:在我们的基站数据中,有一个基站的 CallTime 总是没有按照顺序传入,其他基站的时间都是正常的,那我们需要对这个基站来专门生成 Watermark。
4. 案例
-
需求:
每隔5秒中统计一下最近10秒内每个基站中通话时间最长的一次通话发生的呼叫时间, 主叫号码, 被叫号码, 通话时长. 并且还得告诉我到底是哪个时间范围(10 秒)内的 -
注意:
基站日志数据传入的时候是无序的, 通过观察发现时间最多延迟了3秒 -
代码
package com.hjf.time import com.hjf.dataSource.StationLog import org.apache.flink.api.common.functions.ReduceFunction import org.apache.flink.streaming.api.TimeCharacteristic import org.apache.flink.streaming.api.functions.timestamps.BoundedOutOfOrdernessTimestampExtractor import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment import org.apache.flink.streaming.api.scala.function.WindowFunction import org.apache.flink.streaming.api.windowing.time.Time import org.apache.flink.streaming.api.windowing.windows.TimeWindow import org.apache.flink.util.Collector /** * @author Jiang锋时刻 * @create 2020-07-13 17:19 */ object MaxLongCallTime { def main(args: Array[String]): Unit = { val streamEnv: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment streamEnv.setParallelism(1) import org.apache.flink.streaming.api.scala._ streamEnv.setStreamTimeCharacteristic(TimeCharacteristic.EventTime) val stream: DataStream[String] = streamEnv.socketTextStream("node01", 8888) val data: DataStream[StationLog] = stream.map(one => { val arr: Array[String] = one.split(",") new StationLog(arr(0).trim, arr(1).trim, arr(2).trim, arr(3).trim, arr(4).trim.toLong, arr(5).trim.toLong) }) // 指定表示EvenTime的字段. 延迟3s .assignTimestampsAndWatermarks(new BoundedOutOfOrdernessTimestampExtractor[StationLog](Time.seconds(3)) { override def extractTimestamp(t: StationLog): Long = { t.callTime } }) data.keyBy(_.sid) .timeWindow(Time.seconds(10), Time.seconds(5)) .reduce(new MaxTimeReduce, new ReturnMaxTime) .print() streamEnv.execute() } class MaxTimeReduce extends ReduceFunction[StationLog] { override def reduce(t: StationLog, t1: StationLog): StationLog = { if (t.duration > t1.duration) t else t1 } } class ReturnMaxTime extends WindowFunction[StationLog, String, String, TimeWindow] { override def apply(key: String, window: TimeWindow, input: Iterable[StationLog], out: Collector[String]): Unit = { var sb: StringBuilder = new StringBuilder sb.append("窗口的范围是: ").append(window.getStart).append("----").append(window.getEnd).append("\n") .append("通话日志: ").append(input.iterator.next()) out.collect(sb.toString()) } } }
三. Window的 allowedLateness
1. 背景
-
基于 Event-Time 的窗口处理流式数据, 虽然提供了 Watermark 机制, 却只能在一定程度上解决了数据乱序的问题。但在某些情况下数据可能延时会非常严重,即使通过 Watermark 机制也无法等到数据全部进入窗口再进行处理。
-
Flink 中默认会将这些迟到的数据做丢弃处理, 但是有些时候用户希望即使数据延迟到达的情况下, 也能够正常按照流程处理并输出结果, 此时就需要使用 Allowed Lateness 机制来对迟到的数据进行额外的处理。
-
通常情况下用户虽然希望对迟到的数据进行窗口计算, 但并不想将结果混入正常的计算流程中, 例如用户大屏数据展示系统, 即使正常的窗口中没有将迟到的数据进行统计, 但为了保证页面数据显示的连续性, 后来接入到系统中迟到数据所统计出来的结果不希望显示在屏幕上, 而是将延时数据和结果存储到数据库中, 便于后期对延时数据进行分析。
-
对于这种情况需要借助 Side Output 来处理,通过使用 sideOutputLateData(OutputTag)来标记迟到数据计算的结果, 然后使用 getSideOutput(lateOutputTag)从窗口结果中获取 lateOutputTag 标签对应的数据,之后转成独立的 DataStream 数据集进行处理,创建late-data 的 OutputTag,再通过该标签从窗口结果中将迟到数据筛选出来
-
注意:如果有 Watermark 同时也有 Allowed Lateness。那么窗口函数再次触发的条件 是:watermark < end-of-window + allowedLateness
2. 案例
-
每隔 5 秒统计最近 10 秒, 每个基站的呼叫数量。要求:
- 每个基站的数据会存在乱序
- 大多数数据延迟 2 秒到, 但是有些数据迟到时间比较长
- 迟到时间超过两秒的数据不能丢弃, 放入侧流
-
代码
package com.hjf.time import com.hjf.dataSource.StationLog import org.apache.flink.api.common.functions.AggregateFunction import org.apache.flink.streaming.api.TimeCharacteristic import org.apache.flink.streaming.api.functions.timestamps.BoundedOutOfOrdernessTimestampExtractor import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment import org.apache.flink.streaming.api.scala.function.WindowFunction import org.apache.flink.streaming.api.windowing.time.Time import org.apache.flink.streaming.api.windowing.windows.TimeWindow import org.apache.flink.util.Collector /** * @author Jiang锋时刻 * @create 2020-07-13 21:38 */ object LateDataOnWindow { def main(args: Array[String]): Unit = { val streamEnv: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment streamEnv.setParallelism(1) import org.apache.flink.streaming.api.scala._ // 设置时间语义 streamEnv.setStreamTimeCharacteristic(TimeCharacteristic.EventTime) val stream: DataStream[StationLog] = streamEnv.socketTextStream("node01", 8888) .map(one => { val arr: Array[String] = one.split(",") new StationLog(arr(0).trim, arr(1).trim, arr(2).trim, arr(3).trim, arr(4).trim.toLong, arr(5).trim.toLong) }).assignTimestampsAndWatermarks(new BoundedOutOfOrdernessTimestampExtractor[StationLog](Time.seconds(2)) { override def extractTimestamp(t: StationLog): Long = { t.callTime } }) // 定义侧输出流的标签 val lateTag: OutputTag[StationLog] = new OutputTag[StationLog]("late") val result: DataStream[String] = stream.keyBy(_.sid) .timeWindow(Time.seconds(10), Time.seconds(5)) .allowedLateness(Time.seconds(5)) .sideOutputLateData(lateTag) .aggregate(new AggregateCount, new OutputResult) result.getSideOutput(lateTag).print("late") result.print() streamEnv.execute() } class AggregateCount extends AggregateFunction[StationLog, Long, Long] { override def createAccumulator(): Long = 0 override def add(in: StationLog, acc: Long): Long = acc + 1 override def getResult(acc: Long): Long = acc override def merge(acc: Long, acc1: Long): Long = acc + acc1 } class OutputResult extends WindowFunction[Long, String, String, TimeWindow] { override def apply(key: String, window: TimeWindow, input: Iterable[Long], out: Collector[String]): Unit = { var value: Long = input.iterator.next() var sb = new StringBuilder sb.append("窗口的范围: ").append(window.getStart).append("---").append(window.getEnd).append("\n") .append("当前的基站ID是: ").append(key) .append(", 呼叫的数量是: ").append(value) out.collect(sb.toString()) } } } -
数据集
需要一条一条的输入才能正确显示出效果
station_0,18600003612,18900004575,barring,1577080450000,11 station_0,18600003612,18900004575,barring,1577080457000,12 station_0,18600003612,18900004575,barring,1577080459000,13 station_0,18600003612,18900004575,barring,1577080456000,15 station_0,18600003612,18900004575,barring,1577080468000,16 station_0,18600003612,18900004575,barring,1577080460000,17 station_0,18600003612,18900004575,barring,1577080458000,18 station_0,18600003612,18900004575,barring,1577080440000,19 station_0,18600003612,18900004575,barring,1577080456000,20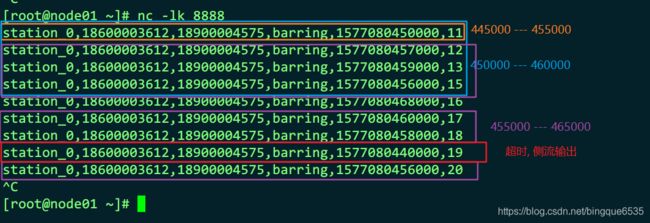
-
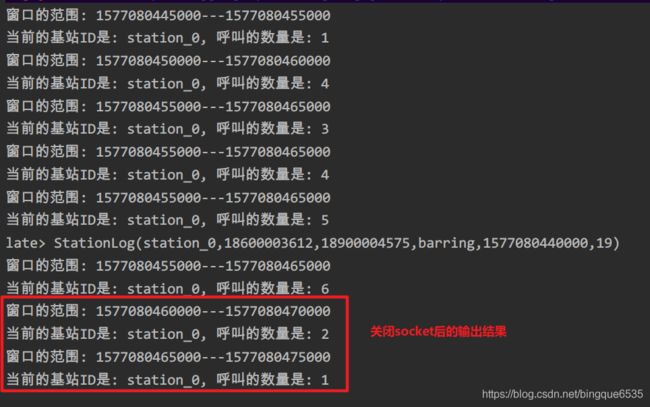
运行结果
声明:
- 本文参考了尚学堂Flink课程的课件
- 本文参考了博客: Flink 从 0 到 1 学习 —— Flink 中几种 Time 详解