【数据挖掘与分析】python网络爬虫学习及实践记录 | part 04-数据存储 【json vs CSV vs excel】
经历了一个星期的实习和半个星期的休假,回复到正常的云胡实验室生活来。每日学习才是正常的作息,前面每天下班回家后还是有练习代码,虽然博文更新的慢,而且没有开新的帖子,有每天坚持在GitHub上更新练习情况。之前卡在数据解析部分,前十个,从跟随式,到自己思考,爬取老师示范讲解的不同部分的内容,再到拿到先自己分析,在思考方式上有比较大的进步。花费的时间也有些长了,好在,回归实验室生活后。解析老师的任务,能够在比较短的时间爬到目标内容,这个开新帖分析,不在这里说了。主要就是指这段时间学习没有中断,零零散散的,好在一直都有坚持,也有一点点成果。
昨天爬到两个市的内容后在思考一个问题,手动替换爬取条件还是不行,需要自动爬,研究了一下代码发现,在存储方面的内容知识点在第四部分,所以这里就开了新篇,先把第四部分学完再倒头来跟part3,后面内容不复杂的话会直接把学记补充在part3的那帖上面,有额外需要注意或者练习讲解部分再开新文,这是后话。
不得不说,实习和工作、放假真的会影响进度,而且没有任务驱动的情况下,学习速度非常慢。这里part3才学了10番,加速度啊,九月份前,这个需要完全刷完的!!!
以上部分是前言。
下面把这部分需要学习的内容贴出来:相较于前三部分真的算很少了,最好一天搞定。
1.json字符串介绍
JSON(JavaScript Object Notation,JS对象标记)
轻量级的数据交换格式 基于ECMAScript(w3c制定)子集
易解析生成、利于传输
支持数据格式:
- 对象(字典)-花括号{};
- 列表(数组)-方括号[];
- 整形、浮点型、布尔类型 NULL;
- 字符串类型(双引号,不能单引号)
注明:多个数据之间使用逗号分开,json本质上就是一个字符串
补充:json.cn 解析好帮手

2-dump成json字符串以及编码问题
这段老师主要用代码来解释:废话不多说,上代码
#encoding:utf-8
import json
# 将python对象转换为json字符串
persons = [
{
'username':'ruby',
'age':'18',
'country':'china'
},
{
'username':'camily',
'age':'20',
'country':'india'
}
]
json_str = json.dumps(persons)
print(type(json_str))
print(json_str)
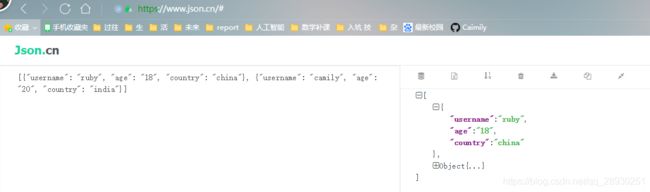
确实是转成了json格式 接着走
转中文的时候需要把默认的打开的ensure_ascii关掉,置False
注:在python中,只有基本数据类型才能转换成json格式的字符串,也就是:int float str list dict tuple
#encoding:utf-8
#from Ruby in 20190816 15:15
import json
# 将python对象转换为json字符串
persons = [
{
'username':'ruby',
'age':'18',
'country':'china'
},
{
'username':'张三',
'age':'20',
'country':'india'
}
]
json_str = json.dumps(persons)
# print(type(json_str))
# print(json_str)
with open('persons.json','w',encoding='utf-8') as fp:
# fp.write(json_str) 第一种存储方法
json.dump(persons,fp,ensure_ascii=False) #第二种方法 注意与dumps的区别 写入中文的时候Unicode 默认是打开ASCII 需要关闭下面再示范一下,只有基本数据类型才能转换成json格式的字符串的反例:以下代码报错
class Person(object):
country = 'china'
a = {
'person' : Person()
}
json.dump(a)3-load成Python对象
这里主要讲解的是“json数据加载成python对象”,示例代码如下:
#encoding:utf-8
#from ruby in 2019/8/16 17:03
import json
# 用python结构读取json数据 load&loads的区别在于 load针对文件
# json_str = '[{"username":"ruby","age":"18","country":"china"},{"username":"张三","age":"20","country":"India"}]'
# persons = json.loads(json_str)
# print(type(persons))
# for person in persons:
# print(person)
with open('person.json','r',encoding='utf-8') as f:
persons = json.load(f)
print(type(persons))
for person in persons:
print(person)4-读取csv文件的两种方式
CSV文件 通用文件格式 相对简单 用于商业科学 在程序间转移表格数据
纯文本(字符集)| 记录组成 行一条记录 | 分隔符隔离着字段(逗号 分号 或制表符 可选空格) | 记录相同字段序列
两种获取方式及区别见代码及注释:
#encoding:utf-8
#from ruby in 2019/8/16 17:28
import csv
# 第一种读取CSV文件的方法,使用reader 读取的结果是列表
def read_CSV_demo1():
with open('F:\DemoProject\mapforGPS\j_str.csv','r') as f:
# reader是个迭代器
reader = csv.reader(f)
# next(reader) #对迭代器+1 去表头
for x in reader:
name = x[0]
loc = x[2]
print({'name':name,'loc':loc})
# 第二种读取方式 字典方式
def read_CSV_demo2():
with open('F:\DemoProject\mapforGPS\j_str.csv','r') as f:
# 使用DictReader创建的reader对象不含标题
# reader充当迭代器,遍历reader,返回字典 通过key的方式获取值
reader = csv.DictReader(f)
for x in reader:
value = {"name":x['湖北省荆州市洪湖市洪湖市第一中学'],"loc":x['29.836666']}
print(value)
if __name__ == '__main__':
read_CSV_demo2()
出门一趟回来刚好这部分代码跟完,今天这部分代码完成。
# encoding:utf-8
# from ruby in 2019/8/16 22:00
import csv
# 第一种写入方法
def write_csv_demo1():
headers = ['username', 'age', 'height']
values = [
('张三', 18, 180),
('李四', 20, 182),
('王五', 19, 190),
]
with open('classroom.csv', 'w', encoding='utf-8', newline='') as f: # newline默认的为‘/n’,为了解决空行问题
writer = csv.writer(f)
writer.writerow(headers) # 写入单行
writer.writerows(values) # 写入多行记录
# 第二种写入方法
def write_csv_demo2():
headers = ['username', 'age', 'height']
values = [
{'username': '张三', 'age': 18, 'height': 180},
{'username': '李四', 'age': 18, 'height': 150},
{'username': '王五', 'age': 22, 'height': 198},
]
with open('classroom1.csv', 'w', encoding='utf-8', newline='') as f:
writer = csv.DictWriter(f, headers)
# 写入表头数据的时候,需要调用writeheader方法
writer.writeheader()
writer.writerows(values)
if __name__ == '__main__':
write_csv_demo2()
晚安~