考虑长短期兴趣和内外站信号的推荐
前言
最近在看一些cross-domain推荐系统的前沿论文,之前的文章也给大家介绍过一些了,感兴趣的小伙伴可以穿梭看之前的内容,比如:
https://zhuanlan.zhihu.com/p/556102767
https://zhuanlan.zhihu.com/p/560783003
今天我们继续介绍这个领域的一篇paper,全文较长,涉及的知识点也较多,对本期内容感兴趣的同学建议先收藏,慢慢消化。
一个优秀的推荐系统是要能够同时抓住用户的长期和短期兴趣的,而且能够利用好各个源的用户行为数据的,我们把目标推荐场景上的用户行为称为用户内部行为,把用户在同平台下其它场景中的行为称为用户外部行为,当然了这里可以再往大了看就是把用户在目标产品上的行为称为用户内部行为,在其他产品上的行为称为用户外部行为,也有论文叫做目标域和源域。
今天要介绍的这篇paper有两大看点,一个是同时利用内外部用户行为抽取长短期兴趣,另一个就是怎么快速实时更新用户兴趣,因为一个大型推荐系统如果基于内外行为训练的话其规模往往是亿级别的,而且外部行为数据由于各种现实系统限制,很难稳定实时更新。
基于上面两个痛点,作者分别提出了LSTTM模型结构和temporal MAML学习方法来解决,感兴趣的一起来学习下吧,其目前已经上线在微信看一看, 其中temporal MAML这里笔者的笔墨会多一点,因为这里也比较难理解。
论文链接:https://arxiv.org/pdf/2105.03686.pdf
方法
LSTTM的总框架图:

首先从宏观的角度来看一下整体框图,最下面有两个graph,一个是Global long-term graph ,该图是用了用户所有内外部行为构建的全局graph,目标是用来提取用户的长期兴趣;另外一个是Internal short-term graph ,该图只用了内部行为(目标场景的行为),其目标是用来提取用户的短期兴趣。
最后将两者融合得到一个最终的向量表示送入DeepFM 模型进行学习。
其中Global long-term graph和Internal short-term graph 的更新机制是不一样的,从框图上也可以看到一个是low-frequent global update ,一个是high-frequent temporal MAML ,后者就是实时更新的机制,也是本文提出的一个创新重点。
了解了整体的大概流程后,下面我们来详细看看一些各个细节:
- Internal Short-term Graph
这里的构图就很简单,一共有两类节点user和item,边的话就是user-item。
这里整体使用了GAT(Graph Attention Network)的网络,在聚合抽样的时候这里是采取了最近时间(就是论文中强调的短期兴趣)的topk个进行聚合,然后一共使用了2层的GAT。不熟悉GAT网络的,大家可以去看一些网上资料,其也是一种GNN网络,核心思想就是在表征当前节点的时候是通过聚合周围节点(抽样几个)+ 本身,具体的聚合就是个self-attention。
关于这里怎么更新网络也就是说loss是什么?这是本文的一个重点就是 temporal meta-learning ,这里我们留给后面单独讲。
- Global Long-term Graph
这里的构图和上面类似,只不过包含了内外部所有的行为,换句话说item是各种各样的。
关于embedding表征这里,作者同样使用了GAT网络,只不过在抽样的时候是随机抽,同样也是采用了2层GAT,同时由于item来源于各种各样的场景,特征很难对齐,所以这里没用side information作为第0层的初始化,转而使用了ID embedding。
关于这里怎么更新网络也就是说loss是什么?作者采用的方法很常规,就是直接使用了GAT的训练loss:neighbor-similarity based loss 即相近点的embedding尽可能的相似。
这里我们也稍微总结对比一下Internal Short-term Graph 和Global Long-term Graph 的不同点:
首先是初始化特征不同,前者使用了丰富的side information,后者使用了ID embeddin;其次采用的抽样算法不同,前者使用了topk最近时间的,后者是随机,当然了这也是作者基于长短兴趣点出发点设计决定的;最后就是训练策略不同,前者是 temporal meta-learning,后者是常规的 neighbor-similarity based loss 。
- Long- Short-term Preference Fusion
在得到用户长短兴趣表示后就可以送到 Fusion 网络了,其也是一个门函数,输入是用户长短兴趣和带预测的item,之后就得到了用户的最终表示,然后送到DeepFM进行下游学习,当然了这里的下游可以是任何业务指标。
- Optimization with Temporal MAML
前面基本都是很常规的做法,就是构图然后使用了常见的GAT算法,这一节要介绍的内容是本篇paper核心贡献。
这里的背景是这样的:对于一个推荐系统来说,实时更新自身的模型是很重要的,但是想要实现这一目标通常来说是非常困难的,首先是因为这个graph真的是太大了,想要实时训练真的是不现实。其次就是这里由于使用了外部行为数据,而外部行为数据由于各种现实原因通常是有时延的。
为此作者这里把Internal Short-term Graph 和Global Long-term Graph 的优化进行了解耦,各自优化各自的。具体的前者使用了temporal MAML based cross-entropy loss,后者使用了multi-hop neighbor-similarity based loss 。
在推荐系统,传统的元学习是将一个用户或者一个domain当作一个任务,这里不得不介绍一下MAML这篇新的元网络学习框架,如果大家比较熟悉可以接着往下看,如果不熟悉,可以看笔者另外一篇文章是简单介绍MAML的:
https://zhuanlan.zhihu.com/p/561067425
它的核心目标就是:只依赖少量样本使得模型能够快速适应新的任务并。说到这里是不是就很匹配上述提到的痛点:只要少量训练样本实时快速更新。
本篇具体的做法就是直接将不同时间段的推荐系统当作一个任务去学习,paper中是将每个case的前一小时看作support set,后一个小时看作query set,也就是说每两个小时为一个任务task;从这里大家也可以看到一个case可以同时横跨两个task的。作者将这种思路命名为 temporal MAML 。
为了更加凸显这里的task含义(时间维度),paper中将其命名为temporal tasks,同时我们还可以在其基础上将其进一步划分为更细粒度的任务,比如每一个task中的所有用户是来源于同一个group的(这个group的含义可以是某个大的先验兴趣点或者其他维度比如年龄,性别等等),这样的话support set和query set的用户会更加相似,进而temporal MAML 将会更加专注的去发现这个group的兴趣实时变化趋势,而不是其他的一些维度。
具体的算法流程和MAML是基本一样的(如果觉得看的吃力,建议先看上述MAML那篇文章)

实际中具体的loss就是ctr,但是需要注意其更新也就是short-term graph 的更新只在框图的左半部分进行,而long-term graph是不参与梯度更新的,它会有自己的更新(后面介绍),也就是我们前面说的长短兴趣点解藕更新。
到这里其实最重要的temporal MAML就已经讲完了,返回头来看我们的出发点就是希望模型能够快速适应捕捉到用户的兴趣变化,而MAML框架就是具备快速适应特性,而本篇基于时间专门设计的temporal MAML就能更好的快速适应时间这一维度或者说角度的变化;
- Multi-hop Neighbor-similarity Based Loss
对于长期兴趣点graph,由于其数据很大、各种时延而且我们致力于提取一个稳定的长期兴趣点,所以实效性也不需要那么高,于是这里就不采用temporal MAML ,而是采用了多跳内的节点尽可能相似。
具体的就是先DeepWalk 游走得到一条path,然后这条path里面的两个节点就应该相似作为loss,当然了这里有两类节点,一种是user一种是item,相似还是各自做即user和user,item和item,实际中进行了10-hop 跳。 这里采用相似节点loss更新的好处就是比较简单,而且可以随时引入其他异构节点进行训练,节点的表征也比较灵活。
需要注意的是:在graph中节点的表征和loss是两个事,表征这里可以是聚合也可以是ID embedding,还可以考虑融入side information。loss这里可以是有监督的比如Internal Short-term Graph 的ctr监督,也可以是无监督采用游走path相似节点loss来学习。
实验
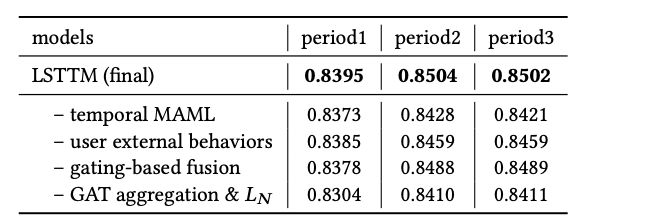
作者进行了一些实验,进行baseline对比和消融实验,可以看到各个模块是有一些收益的,感兴趣的小伙可以去看原paper

总结
(1)内外部信号的融合方式可以考虑graph形式
(2)元学习这个思路大家也可以借鉴一下
关注
欢迎关注,下期再见啦~
知乎,csdn,github,微信公众号
本文由 mdnice 多平台发布