主从复制 & 读写分离
问题描述:
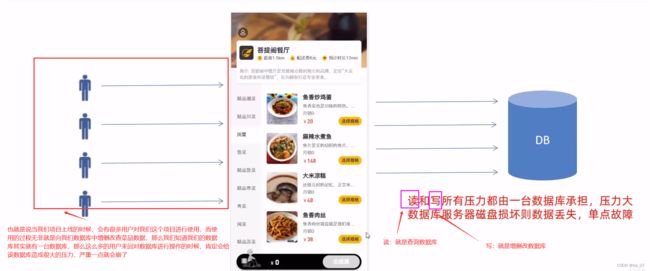
也就是说用户查询数据库数据和增删改数据库数据的时候,我们都是对一个数据库进行操作的,因为我们的项目只有一台数据库,因此这个数据库的压力是很大的。并且如果这台数据库磁盘数据丢失的话,那么数据也就丢失了。
解决问题方式:
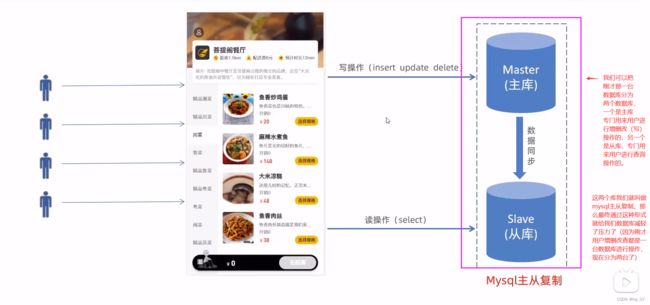
从库通过复制主库二进制日志,就能够把主库的数据复制到自己的库中,(注:主库和从库的数据都是一样的。并且从库可以有多个。)
通过上面我们就基本上知道了什么是mysql主从复制了,那么我们下面就可以用java代码进行实现了。

一、mysql主从复制

前提条件:(先开启两台安装并启动了mysql服务的服务器)

配置条件操作如下:
我们这里就用开启两台虚拟机centOS7 、CentOS7.2 作为两台服务器,然后将这两个虚拟机中都各自安装并且启动mysql数据库服务即可(命令用Shell工具操作比较方便)
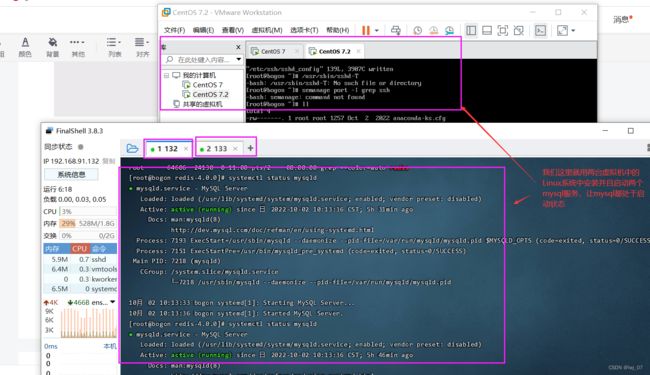
注意:一定要保证这两台虚拟机linux系统中的两个mysql是处于启动状态啊,并且一定要都有mysql服务(具体怎么在linux系统中安装mysql的就看linux的笔记一步一步操作即可,注意防火墙要开放这两个数据库的端口号)。
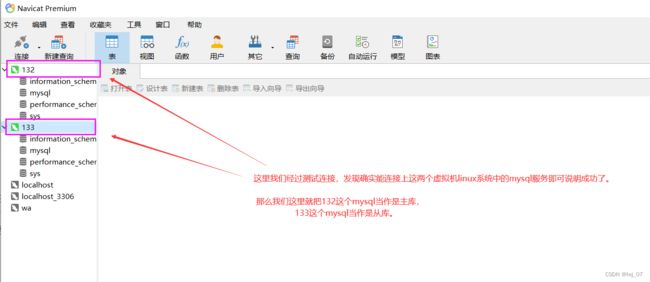
那么我们就可以将132虚拟机中的mysql数据库当作是主库,然后将133虚拟机中的mysql数据库当作是从库进行操作了(注意:从库可以是多个,做法就是再继续开启虚拟机安装启动mysql就可以了)。
上面的操作我们知道,我们只是现在成功开启了两台mysql服务器而已,我们如果将132看待成主库的话,133看作是从库的话,我们肯定要给他们两个库创建联系,并且和我们的项目也创建好联系(也就是说项目增删改的时候访问主库数据库,查的时候访问从库数据库) 这些都是需要创建好联系的,如果不创建联系也就仅仅是两个普通的数据库而已。
创建主库与从库之间联系步骤:
我们上面已经知道理论了,从库是通过复制主库的二进制日志从而得到主库中的数据的(也就是说得到主库的任何东西,从库和主库的数据库变成一样),因此这里我们需要先配置主库二进制日志,操作如下所示:
配置-主库Master
我们知道主库数据库是运行在虚拟机linux系统中的,因此我们就在主库所在的虚拟机服务器中通过命令操作主库即可。
第一步:
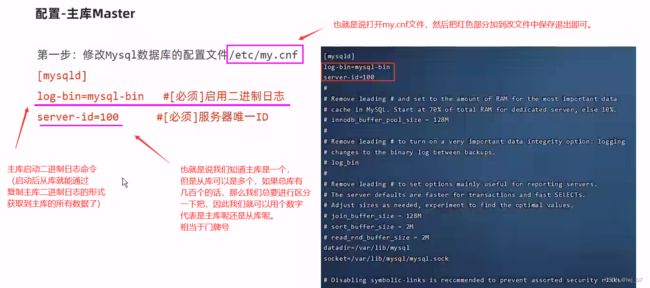
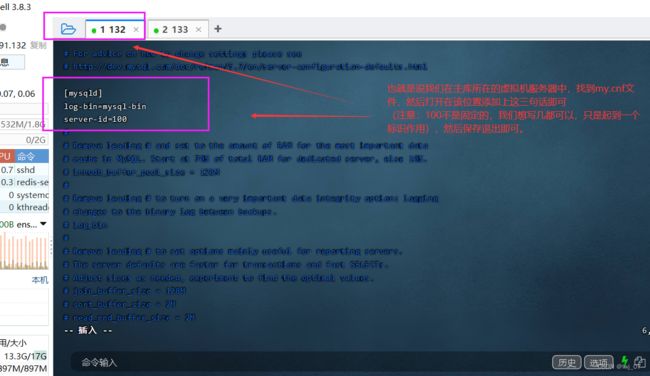
第二步:

第三步:
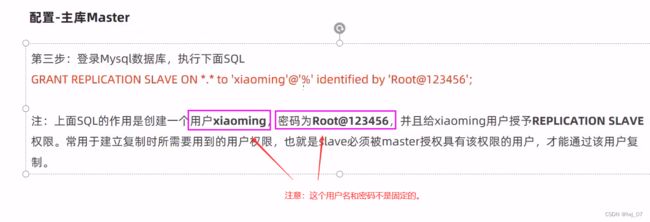
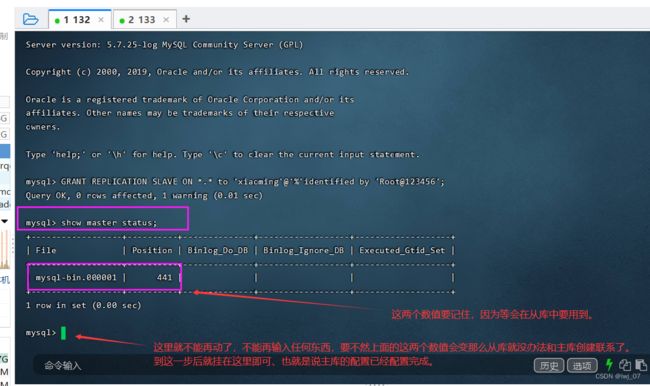
SQL:GRANT REPLICATION SLAVE ON *.* to 'xiaoming'@'%' identified by 'Root@123456';
注意:
如果我们虚拟机服务器中安装启动的mysql为mysql8版本的话,那么有可能上面的sql命令不会成功,那么就需要我们通过下面的方式输入sql命令(也就是分开写SQL,有可能是大写,就按照上面的SQL分开写成下面的形式即可,如果小写错误的话就用大写):
先输入该SQL:create user xiaoming identified by 'Root@123456';
再输入该SQL:grant replication slave on *.* to xiaoming;
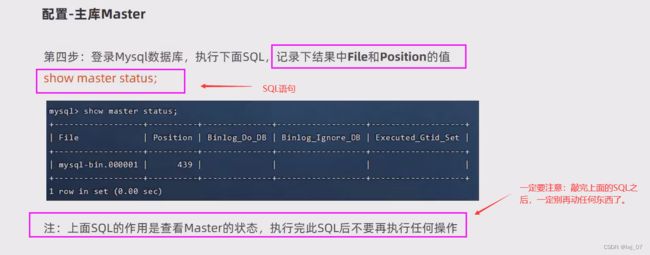
第四步:
配置-从库Slave
第一步:
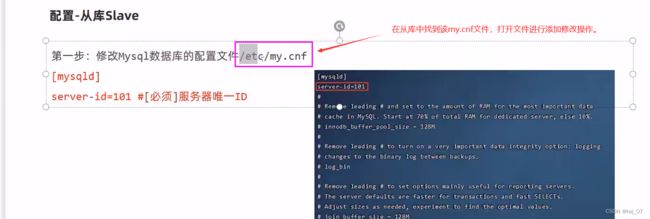
注意:刚踩的坑!!!!!!
如果使用vim打开my.cnf文件的时候,一直出现未找到该命令,那么就先用yum install vim命令安装一下vim命令,安装后才能用vim命令。
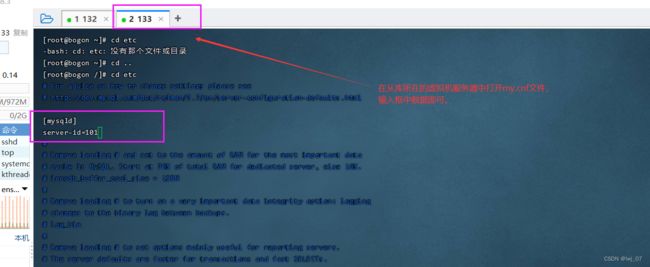
第二步:

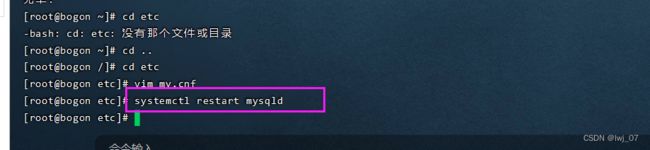
第三步:
change master to master_host='192.168.91.132',master_user='xiaoming',master_password='Root@123456',master_log_file='mysql-bin.000002',master_log_pos=441;
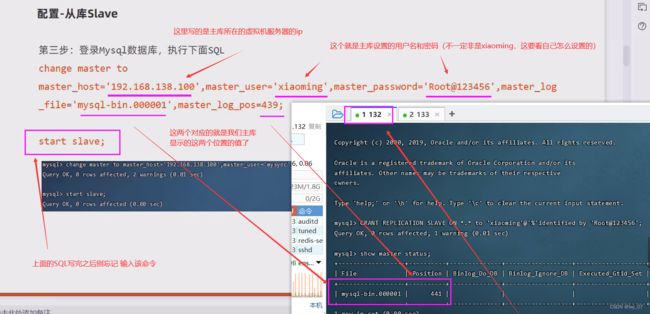
改正:我这里主库中的 master_log_file='mysql-bin.000001' 写成 master_log_file='mysql_bin.000001'了,注意要和主库中的写的一模一样。
注意:如果输入命令报错的话:

第四步:

因此我们使用 show slave status\G命令:
测试
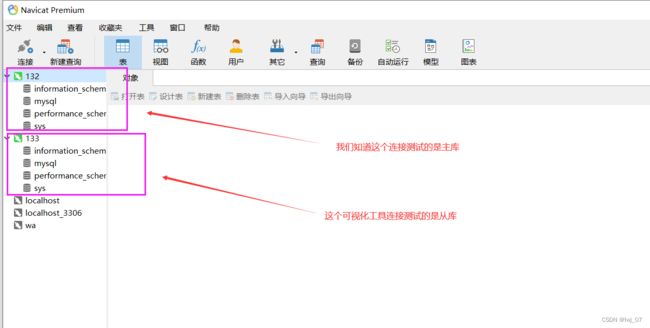
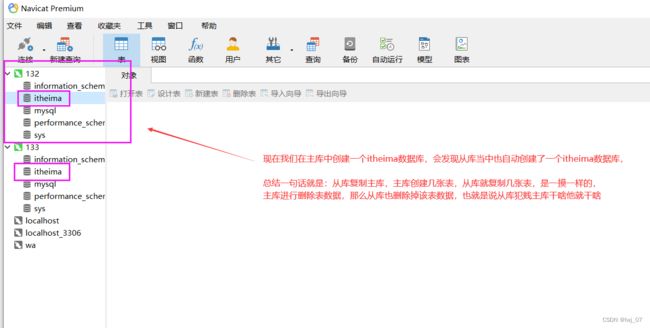
通过上面的过程,我们知道主库和从库之间建立上了联系了,那么我们就可以进行测试了:
二、读写分离

2.1、背景
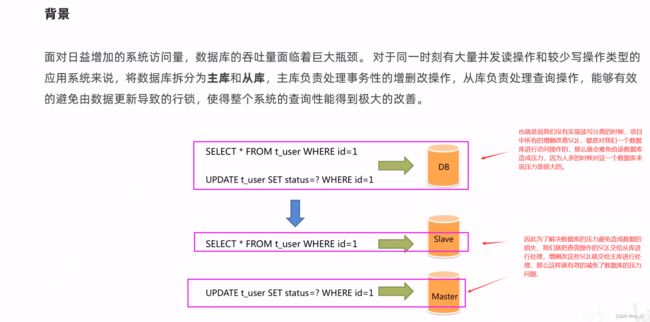
那么在java项目代码中,如何实现上面的读写分离操作呢,也就是说当对项目进行查询操作的时候,就访问从库,当进行增删改操作的时候就访问主库,但是到底该如何实现这种读写分离呢,就需要我们用到Sharding-jdbc框架。
2.2、Sharding-jdbc

2.3、使用Sharding-jdbc实现读写分离演示
注: 使用Sharding-jdbc实现读写分离之前,我们要保证主库和从库之间建立好了联系了,毕竟读的时候访问的是从库,写的时候访问的是主库,如果主库和从库都没有建立好联系,那么人家怎么访问相对应的库中的数据啊。
实现读写分离之前,我们先把数据库建立起来:
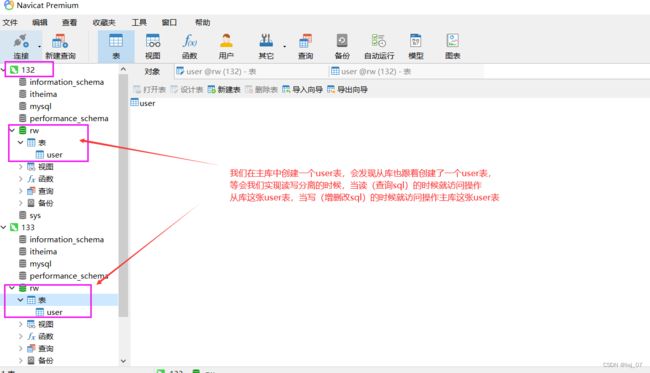
数据库搭建之后,我们就可以使用Sharding-jdbc实现读写分离了:

第一步:

第二步:

我们知道我们现在上面只有一个主库和一个从库(注:从库可以是多个)
把下面的这些信息配置到项目的priperties.yml属性文件中即可:
spring:
shardingsphere:
datasource:
names:
master,slave # 这个master我们就可以当作是主库名,slave可以当作是从库名(名字可以随便起,不过下面的主数据源、从数据源要保证和起的这名字一致)
# 我们知道主库是一个从库可以是多个,当从库有多个的时候我们可以这样写 master,slave1,slave2...... 不过多个从库的时候下面的从数据源也要配置好
# 主数据源
master: # 这个名字要保证和上面起的名字一致
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://192.168.91.132:3306/rw?characterEncoding=utf-8&useSSL=false # 这个我们知道主库对应的ip是192.168.91.132因此写这个ip,主库默认端口号3306,然后rw就是对应的该主库中的rw数据库
username: root # 然后这就是主库的用户名和密码, 如果主库没有配置用户名和密码的话可以不用写
password: root
# 从数据源
slave: # 这个名字要保证和上面起的名字一致
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://192.168.91.133:3306/rw?characterEncoding=utf-8&useSSL=false # 同理这里对应的是从库的ip值和端口号还有从库的rw数据库,就是说等会操作的就是rw数据库中的表(上面主库也是一样)
username: root
password: root
#### 如果有多个从库的话,这里可以继续配置从数据源
# slave1: # 这个名字要保证和上面起的名字一致
# type: com.alibaba.druid.pool.DruidDataSource
# driver-class-name: com.mysql.cj.jdbc.Driver
# url: jdbc:mysql://...../rw?characterEncoding=utf-8&useSSL=false # 同理这里对应的是从库的ip值和端口号还有从库的rw数据库,就是说等会操作的就是rw数据库中的表(上面主库也是一样)
# username: root
# password: root
masterslave:
# 读写分离配置
load-balance-algorithm-type: round_robin #轮询
# 最终的数据源名称
name: dataSource
# 主库数据源名称
master-data-source-name: master # 这里我们知道上面的配置的主数据源配置好主库的ip值等操作后,name为master,所以这里也写master
# 从库数据源名称列表,多个逗号分隔
slave-data-source-names: slave # 同理这里写上面我们配置的从库的名
props:
sql:
show: true #开启SQL显示,默认false到了这一步配置好之后,那么读写分离就完成了,也就是说当用户访问我们这个项目的时候,假如访问的是查询功能,那么就调用访问的是我们配置的从库(从数据库)了,如果访问请求的增删改功能,那么就调用访问的是我们上面配置的主库(主数据库了),也就是说实现了读写分离了,缓解了用户访问增删改查功能时只访问一台数据库服务器的压力问题了。
因此我们的读写分离基本上就完成了,就可以开启项目服务器,让用户进行资源访问了:
但是这里还有一个小问题就是我们开启项目服务器的时候,会报下面的错误:
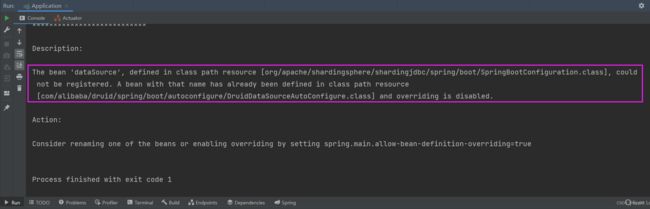
因此我们需要把这个问题给解决掉,要不然项目启动不了,那么解决这个问题就需要我们第三步了:在配置文件中配置允许bean定义覆盖配置项
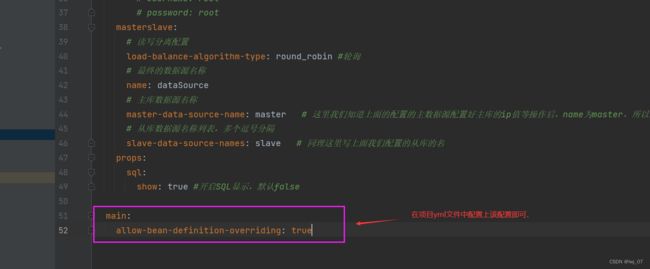
配置好之后,我们从日志中就会发现我们的项目能够启动成功了:
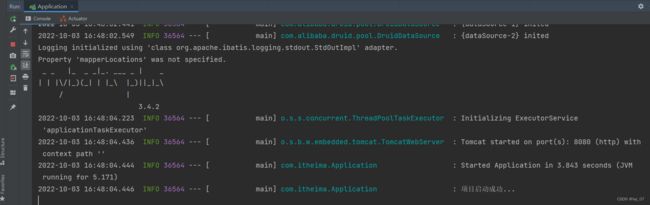
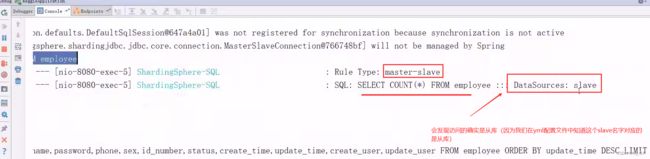
接下来我们就能够进行测试了,我们知道读写分离我们通过sharding-jdbc框架完成了读写分离,那么我们就可以开启服务器让客户端访问资源进行测试了,测试一下看看是不是真正的当客户端访问项目的读(查询)功能操作的时候是不是就访问我们配置的那个从库(从数据库),当访问项目的写(增删改)功能操作的时候,看看是不是就访问调用的是主库(主数据库):
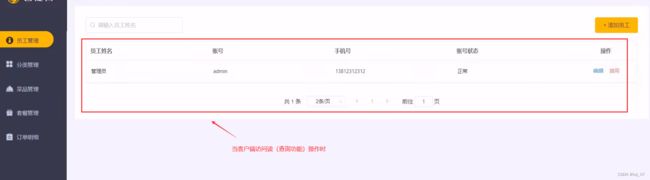
当客户端访问项目读功能时(查询功能):

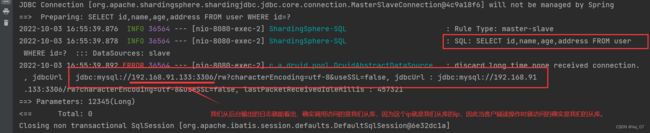
当客户端访问写项目功能时(增删改功能):
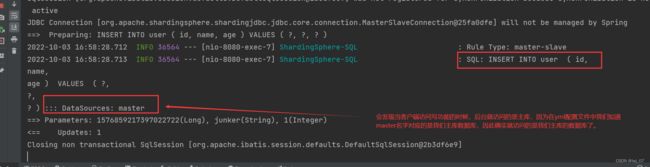
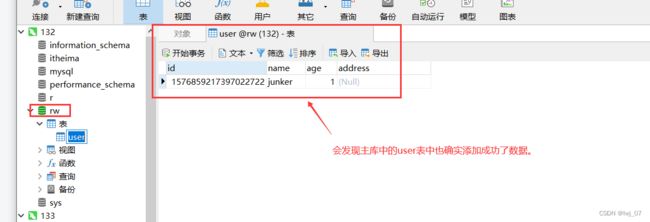
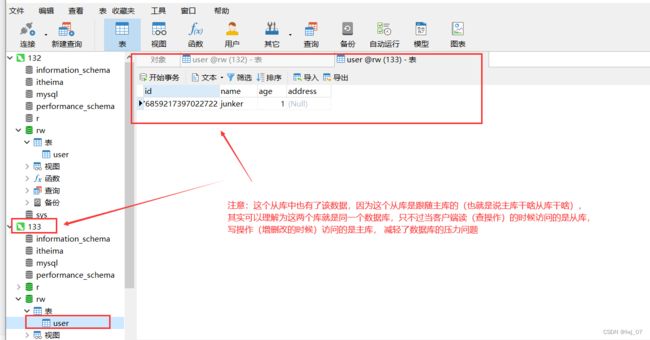
通过上面的测试,我们知道读写分离确实成功了,当客户端请求读操作(查询功能资源)的时候,确实调用访问的就是从库数据库,当客户端请求写操作(增删改功能资源)的时候,确实调用访问的是主库数据库,成功解决减轻了我们客户端增删改查功能只调用访问一台数据库的压力问题。
三、项目实现读写分离
首先我们知道,通过上面的操作,我们已经完成了主从复制了,也就是说主库和从库已经建立好联系了,那么现在我们就把项目中所用到的所有表添加到主库当中去即可(从库也会复制成功一份):
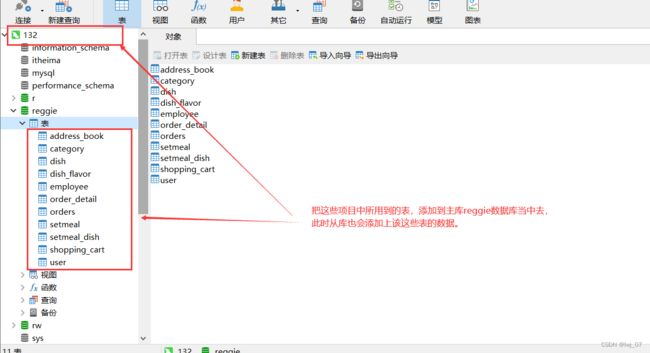
然后我们就在项目中通过Sharding-jdbc框架实现读写分离即可,步骤和上面的是一样的:
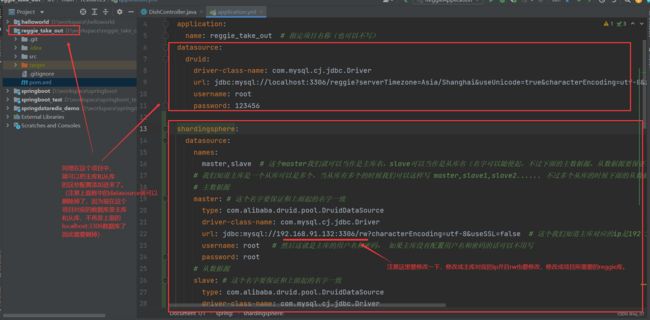
通过上面的配置后,我们知道我们这个项目已经配置了读写分离了,当客户端请求读操作(查询功能资源)的时候,访问的就是从库了,当客户端请求写操作(增删改功能资源)的时候,确实调用访问的是主库数据库,成功解决减轻了我们客户端增删改查功能只调用访问一台数据库的压力问题。