【笔记】基于TF-IDF 算法的文本相似度以衡量技术革新
原文名称:
Kelly, B., Papanikolaou, D., Seru, A., and Taddy, M., “Measuring Technological Innovation over the Long Run”, NBER Working Paper No. 25266, 2018
原文链接:
Measuring Technological Innovation over the Long Run | NBER
原载于:
【MLinEcon文献推送20】文本方法衡量技术革新
01 引言
背景:1.美国的人均实际产出增长超出生产投入的增长,归因于生产率的提高,然而近几十年生产率的增长似乎在放缓。同时,各企业再生产率上也存在很大而持久的差异。2.技术进步的程度难以度量,所以只能构建与之相关的指标,这些指标需要在很长一段时间中可用且可比较。3.专利统计可以是一个很好的切入点。
传统的方法是通过引文数据来确定专利的创新性,但是引文数据并不是持续可用的。所以这篇文章利用文本分析中文本相似性的测量方法,构建每个新发明的专利和与现有和后续专利之间的联系。将重要(高质量)的专利识别为其内容与之前的专利不同(是新颖的),但与未来的专利相似(是有影响的)。
全文中,首先对专利相似性和专利重要性的指标构建进行了介绍,然后对这些指标进行实证检验,包括以下三个方面:首先,确定了一份重要专利清单,并检查它们在质量指标方面的得分情况。其次,将质量衡量指标与专利引证联系起来,这是创新文献中衡量专利质量的常用指标。最后,我们检查我们的质量指标和市场价值之间的相关性。然后还进行了长期创新的衡量,以及创新和测量生产力的联系。
02 数据的来源
1、数据搜集
1976年开始的专利数据来自美国专利商标局,1976年后的数据来自谷歌。
2、文本数据转为数字数据
将专利的文本内容转换为数字数据进行统计分析。使用 NLTK Python工具包将每项专利的 "摘要"、"权利要求 "和 "描述 "部分解析为单个术语。将所有非单词文本元素,如标点符号、数字和 HTML 标签剥离出来,并将所有大写字母转换为小写字母。接下来,删除了947个 "停顿词 "的所有出现,其中包括介词、代词和其他几乎没有语义内容的词。为了减少分析的负担,降低文本数据的稀疏性。他们排除了样本中900多万件专利中出现次数少于20次的术语。这样就排除了33,954,834个术语,最终形成1,685,416个术语的词典。
将文本转换为文件术语矩阵。(DTM),记为 C。C 的列对应词,行对应专利。C 中的每一个元素,用 Cpw 表示,计算一个给定的单字短语(以 w 为索引)在一个特定的专利(以 p 为索引)中的使用次数。
03 专利相似性的定义
用 TF-IDF 算法,"词频"(TF)和"逆文档频率"(IDF),计算TF-IDF值。首先是计算词频,它计算术语w在专利p中出现的次数,并根据专利的长度进行调整。其中分子为特点数据的词频Cpw,分母为所有术语在同一专利中的加总 k Cpk 。
k Cpk 。

然后是计算术语w逆文档频率,IDF通过对许多文档中出现的常见词进行低权重来衡量术语w的信息性。

TFIDFpw的值高,说明术语w在文档p中出现的频率相对较高,但在其他大多数文档中没有出现,从而传达出词w特别能代表文档p的语义内容。(注:术语w在文档p中出现的频率相对较高TFpw值越大,w在其他大多数文档中没有出现,则IDFw中log括号里的值越大,IDFw恒为正)
对于本文分析的目的来说,这种传统的加权方案并不理想,因为它忽略专利的时间顺序。例如,考虑到尼古拉-特斯拉(Nikola Tesla)著名的1888年交流电机专利(专利号为381,968),它是最早使用 "交流电 "这一短语的专利之一,这一短语在整个20世纪被频繁使用。在代表特斯拉专利的TFIDF向量中,标准的IDF会大幅降低这个词的重要性,因为后来有很多专利都大量使用这个词。因此,TFIDF会对该专利的创新性进行误导性的、相当颠倒的描述。
对此本文重新构建了一个包含时间权重的BIDFw指标,定义为申请年t之前申请的任何专利中包含w的文件的对数频次。

于是TFBIDF就变成了

这些都被安排在一个w向量TFBIDFi,t中,其中w是对(i, j)中术语的集合联盟的大小。接下来,每个TFBIDF向量被归一化为具有单位长度。
最后,计算两个归一化向量之间的余弦相似度,作为衡量两篇文本相似性的指标。

下图展示了其中四个专利的相似性网络

04 衡量专利的重要性
本文将专利的重要性分为新颖性和影响力两部分来考虑。新颖性专利是指有别于现有技术的专利,以专利与申请时现有专利存量的相似性(倒数)来衡量专利的新颖性。将其称为 "后向相似性",并将其定义为
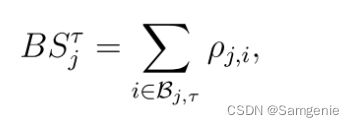
Bjτ表示在j提交之前年中提交的专利的集合。后向相似性越高,代表新颖性越低。“前向相似性”定义为,Fjτ表示在j提交之后年中提交的专利的集合。前向相似度越高,代表影响力越强。

结合这两个指标,文章构建了专利的重要性指标,指标的值越大,重要性程度越高。

05 验证
1、检验关于专利的重要性和引文

在这个回归中,只关注1945年后发布的专利样本,因为这是美国专利商标局持续记录引文的时期。衡量了专利申请后0-τ年的专利质量和引用情况。向量Zj包括控制技术等级的虚拟变量、授予年份、受让人以及受让人和年份效应的交互作用。
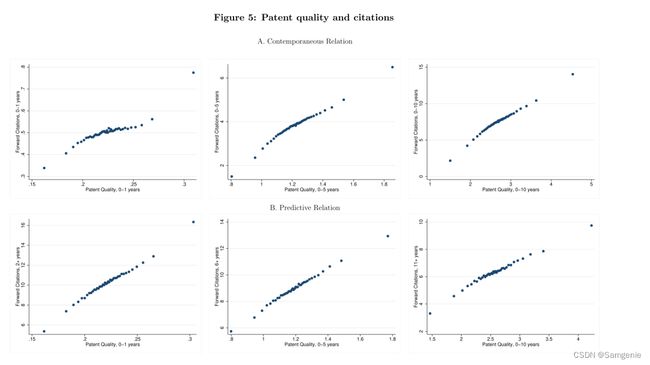
A组绘制引用和文本质量的关系,以10年为前向窗口,本文发现两者是强正相关的,我们基于文本的专利质量衡量标准与专利引用高度相关。在同一测量范围内。基于文本的质量测量对未来的引用具有预测性。
B组绘制了在申请后0-1年窗口中测量的基于文本的质量与第2年及以后的所有引文之间的预测关系。还绘制了0-5年的质量与6年以上的引文,以及0-10年的质量与11年以上的引文。在所有的情况下,发现近期的质量测量和未来长期的引文之间有明确的正相关。
这是模型(1)的回归结果

本文又进一步使用从0-τ年的引文为控制变量,预计了τ+1年及以后的引用情况。公式表达为:

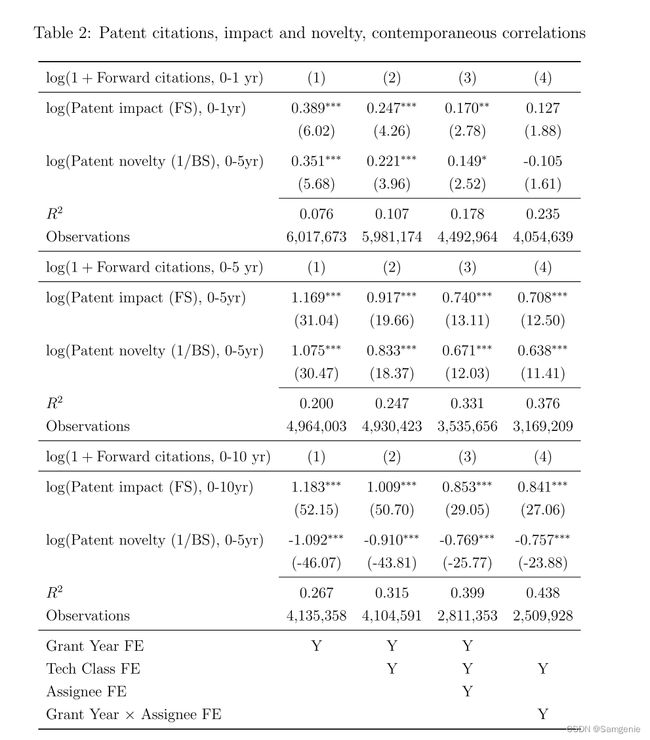
上表将质量度量分解为影响(FS)与新颖(1/BS)两部分。回归结果显示,通过专利的前向相似性来衡量,专利的影响力与同一时期被引用的次数显著成正比。而且更新颖的专利将来也更有可能被引用。同时还发现,FS与1/BS的大小相似,这说明在质量基准指标中,存在前后向相似度之间的一对一比率。
2、检验专利质量与市场价值
本文利用KPSS的测度,ˆVj表示从股票市场对专利授权的反应中推断出专利j的价值(以美元为单位)。KPSS将这一测度解释为专利私人价值的事前测度。为了研究基于文本的专利质量如何与估计的私有价值相关联,建立以下回归:
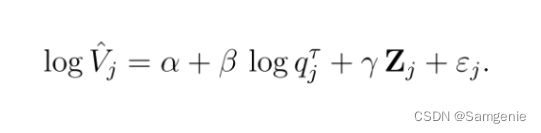
控制变量还包括产生专利的上市公司的特征,包括公司在专利授权前的对数市值(因为规模较大的公司可能会产生更有影响力的专利)和公司的对数特异性波动率(快速增长的公司有更大的收益波动,可能会产生更高质量的专利)。
06 衡量创新与生产率
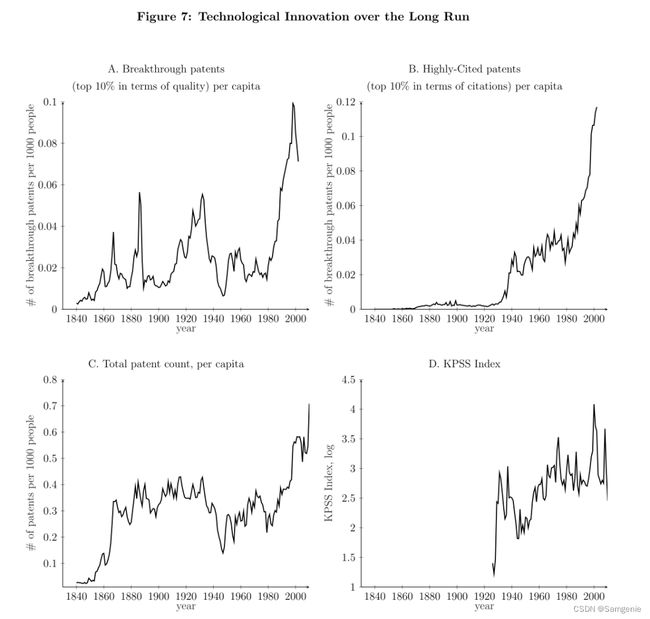
图 A 绘制了突破性专利的数量,(定义为每年属于质量衡量指标无条件分布前 10% 的专利数量),衡量 10 年前向与 5 年后向相似度的比率,并扣除年份固定效应,同时本文按美国人口进行了标准化。图B中,绘制了属于无条件分布的前10%的前向引文的专利数量, 在未来10年内测量,扣除年份固定效应,同样以美国人口为标准。图 C 绘制了专利总数,并按人口比例进行了调整,而图 D 绘制了 KPSS 指数(专利的估计市场价值之和,按股票市场的总市值进行了调整。

图中显示了这些突破性专利在技术类别上的分类。在过去的170年里,突破性发明的技术类别变化很大。与此相反,所有专利中的技术类别构成在一段时间内保持相对稳定。
07 衡量创新与生产率的关系
1、综合生产力
首先关注总生产力的增长。对于战后的样本,使用Basu等人(2006)构建的TFP衡量方法,该方法可用于1948-2018年期间。对于早期的样本,使用Kendrick(1961)收集的数据,用每小时产出来衡量生产率,该数据可用于1889年至1957年期间。根据Jorda(2005),本文估计了以下回归:

其中Xt表示全要素生产率(TFP)的对数值,BreakthroughIndex表示行业创新指数(突破专利的数量,按产业划分),并考虑τ=1,...,10年的时间范围,还研究了创新和过去生产率增长之间的关系,即为τ负值的情况。

图A给出了估计的结果 (14)为战后样本。将重点放在5到10年的视野上,本文的技术指数的标准差增长与每年0.5%的TFP增长相关联--考虑到这一时期衡量的TFP增长的标准差是1.8%,这是很可观的。重要的是,过去生产力的变化与创新指数之间没有统计学上的显著相关性。图B显示了早期样本的结果。同样关注5至10年的视野,本文的创新指数的一个标准差与劳动生产率每年约1.5-2%的增长相关--相比之下,劳动生产率增长的年标准差为5.2%。
2、行业层面的分析

图中显示了各行业的突破性专利数量。行业是根据NAICS代码定义的。突破性专利是指扣除年份固定效应后,在基线质量衡量指标(定义为10年前向与5年后向相似度之比)中排名前10%的专利。本文使用Goldschlag等人(2016)构建的CPC4到NAICS交叉通道构建行业指数。

其中,xi,t表示(对数)多因素生产率;BreakthroughIndexi,t是行业创新指数(突破性专利的计数,按人口比例缩放);Zi,t是包括时间和行业固定效应、专利总数对数、按人口比例和生产率水平的控制向量。

图中绘制了行业全要素生产率对本文技术创新指数的单位标准差冲击的反应。图A显示了86个制造业行业在NAICS 4位数水平上的结果,使用的是劳工统计局的数据。图B(Kendrick数据)的数据来自Kendrick(1961)中的表D-V,包括62个制造业行业1899年、1909年、1919年、1937年、1947年和1954年的劳动生产率水平(每工时产出)的信息。对于每个时期(t,s),本文将对数劳动生产率的年化差异回归到t±2年的累计创新水平(突破性专利数量)的对数上--控制了时期、行业假想值、同期专利数量的对数以及t时生产率的对数水平。得出行业创新指数和测算生产率:美国创新指数提高一个标准差,下期测算生产率增长率就会提高1.4%。
08 结论
本文利用对专利文件中的高维数据进行文本分析,创建新的专利质量指标。该指标赋予那些与现有知识库不同(具有新颖性)并与后续专利相关(具有影响力)的专利以更高的质量。这些对新颖性和相似性的估计是使用一种新的方法构建的,这种方法建立在文本分析的最新进展之上。同时对专利重要性的测量可以预测未来的引用,并与市场价值的测量密切相关。
本文将突破性创新确定为最重要的专利,以构建总体和部门的技术变化指数。该技术指数跨越两个世纪(1840-2010年),涵盖了私营和公共企业、非营利组织和美国政府的创新。这些指数反映了长时间内技术 浪潮的演变,是生产力的有力预测指标。