广州大学学生实验报告,进程控制与进程通信
广州大学学生实验报告
开课学院及实验室: 计算机科学与网络工程学院 电子楼418B 2022年9月 26日
| 学院 |
计算机科学与网络工程学院 |
年级/专业/班 |
计科 |
姓名 |
Great Macro |
学号 |
|
| 实验课程名称 |
Unix/Linux 操作系统分析实验 |
成绩 |
|||||
| 实验项目名称 |
进程控制与进程通信 |
指导 老师 |
张*玲 |
||||
实验一 进程控制与进程通信(2)
一、实验目的
1、了解什么是管道
2、熟悉UNIX/LINUX支持的管道通信方式
3、理解内核模块的编写和装载方法
二、实验内容
1、编写程序实现进程的管道通信。用系统调用pipe( )建立一管道,二个子进程P1和P2分别向管道各写一句话:
Child 1 is sending a message!
Child 2 is sending a message!
父进程从管道中读出二个来自子进程的信息并显示(要求先接收P1,后P2)。
2、编写一个HelloWorld内核模块,并进行装载和卸载操作
三、实验指导
(一)管道通信
1、什么是管道
UNIX系统在OS的发展上,最重要的贡献之一便是该系统首创了管道(pipe)。这也是UNIX系统的一大特色。
所谓管道,是指能够连接一个写进程和一个读进程的、并允许它们以生产者—消费者方式进行通信的一个共享文件,又称为pipe文件。由写进程从管道的写入端(句柄1)将数据写入管道,而读进程则从管道的读出端(句柄0)读出数据。


2、管道的类型:
(1)有名管道
一个可以在文件系统中长期存在的、具有路径名的文件。用系统调用mknod( )建立。它克服无名管道使用上的局限性,可让更多的进程也能利用管道进行通信。因而其它进程可以知道它的存在,并能利用路径名来访问该文件。对有名管道的访问方式与访问其他文件一样,需先用open( )打开。
(2)无名管道
一个临时文件。利用pipe( )建立起来的无名文件(无路径名)。只用该系统调用所返回的文件描述符来标识该文件,故只有调用pipe( )的进程及其子孙进程才能识别此文件描述符,才能利用该文件(管道)进行通信。当这些进程不再使用此管道时,核心收回其索引结点。
二种管道的读写方式是相同的,本文只讲无名管道。
(3)pipe文件的建立
分配磁盘和内存索引结点、为读进程分配文件表项、为写进程分配文件表项、分配用户文件描述符
(4)读/写进程互斥
内核为地址设置一个读指针和一个写指针,按先进先出顺序读、写。
为使读、写进程互斥地访问pipe文件,需使各进程互斥地访问pipe文件索引结点中的直接地址项。因此,每次进程在访问pipe文件前,都需检查该索引文件是否已被上锁。若是,进程便睡眠等待,否则,将其上锁,进行读/写。操作结束后解锁,并唤醒因该索引结点上锁而睡眠的进程。
3、所涉及的系统调用
(1)pipe( )
建立一无名管道。
系统调用格式
pipe(filedes)
参数定义
int pipe(filedes);
int filedes[2];
其中,filedes[1]是写入端,filedes[0]是读出端。
该函数使用头文件如下:
#include
#inlcude
#include
(2)read( )
系统调用格式
read(fd,buf,nbyte)
功能:从fd所指示的文件中读出nbyte个字节的数据,并将它们送至由指针buf所指示的缓冲区中。如该文件被加锁,等待,直到锁打开为止。
参数定义
int read(fd,buf,nbyte);
int fd;
char *buf;
unsigned nbyte;
(3)write( )
系统调用格式
read(fd,buf,nbyte)
功能:把nbyte 个字节的数据,从buf所指向的缓冲区写到由fd所指向的文件中。如文件加锁,暂停写入,直至开锁。
参数定义同read( )。
四、参考程序
#include#include #include #include #include #include int pid1,pid2; int main(void) { int fd[2]; char outpipe[100],inpipe[100]; pipe(fd); /*创建一个管道*/ while ((pid1 = fork())== -1); if(pid1 == 0 ) { lockf(fd[1],1,0); sprintf(outpipe,"child 1 process is sending message!"); /*把串放入数组outpipe中*/ write(fd[1],outpipe,50); /*向管道写长为50字节的串*/ sleep(5); /*自我阻塞5秒*/ lockf(fd[1],0,0); exit(0); } else { while((pid2 = fork())== -1); if(pid2 == 0) { sleep(1); /*先睡眠1秒,保证子进程一先往管道里写入信息*/ lockf(fd[1],1,0); /*互斥*/ sprintf(outpipe,"child 2 process is sending message!"); write(fd[1],outpipe,50); sleep(5); lockf(fd[1],0,0); exit(0); } else { wait(0); /*同步*/ read(fd[0],inpipe,50); /*从管道中读长为50字节的串*/ printf("%s\n",inpipe); wait(0); read(fd[0],inpipe,50); printf("%s\n",inpipe); exit(0); } } return 0; }
4、运行结果
延迟5秒后显示
child 1 process is sending message!
再延迟5+1秒
child 2 process is sending message!

结果分析:
为使读、写进程互斥地访问pipe文件,需使各进程互斥地访问pipe文件索引结点中的直接地址项。因此,每次进程在访问pipe文件前,都需检查该索引文件是否已被上锁。若是,进程便睡眠等待,否则,将其上锁,进行读/写。操作结束后解锁,并唤醒因该索引结点上锁而睡眠的进程。
同时为了保证先接受子进程一的信息,后在接受子进程二的信息,可以在子进程二的语句中加入sleep(1)。
(二)内核模块的编写
1、认识内核模块
内核模块是linux内核向外部提供的一个插口,是内核的一部分,但是并没有被编译到内核里面去,其全称为动态可加载内核模块(Loadable Kernel Module,LKM),简称模块。
linux内核之所以提供模块机制,是因为它本身是一个单内核。而单内核的最大优点就是效率高,因为所有的内容都集成在一起,但其缺点是可扩展性和可维护性相对较差,模块机制就是为了弥补这一缺陷。
2、模块的定义
模块是具有独立功能的程序,它可以被单独编译,但不能独立运行。它在运行时被链接到内核作为内核的一部分在内核空间运行,这与运行在用户空间的进程是不同的。模块通常由一组函数和数据结构组成,用来实现一种文件系统、一个驱动程序或者其他内核上层的功能。
3、编写简单的内核模块
模块和内核都在内核空间运行,模块编程在一定意义上说就是内核编程。一个内核模块应该至少有两个函数,第一个为module_init(),是模块加载函数,当模块被插入到内核时调用它;第二个为module_exit(),是模块卸载函数,当模块从内核移走时调用它。
(1)任何模块都要包含的三个头文件:
#include
#include
#incldue
说明:module.h头文件包含了对模块的版本控制;kernel.h包含了常用的内核函数;init.h包含了宏__init和__exit,宏__init告诉编译程序相关的函数和变量仅用于初始化,编译程序将标有__init的所有代码存储到特殊的内存段中,初始化结束就释放这段内存。
(2)printk()函数
该函数是由内核定义的,功能和C库中的printf()类似,它把要打印的日志输
出到终端或系统日志。字符串中的<1>是输出的级别,表示立即在终端输出。
(3)内核模块的入口函数和出口函数
内核模块的入口函数和出口函数是模块编程中最基本的也是必须的两个函数。入口函数向内核注册模块所提供的新功能;出口函数负责注销所有由模块注册的功能。例如;
Static int _init lkm_init(void)
{
printk(KERN_INFO “Hello World!\n”);
return 0;
}
Static void _exit lkm_exit(void)
{
printk(KERN_INFO “Goodbye!\n”);
}
(4)加载模块、卸载模块和声明许可证
module_init和module_exit,这两个函数分别在加载和卸载模块时被调用。例如
module_init(lkm_init);
module_exit(lkm_exit);
声明许可证:
MODULE_LICENSE(“GPL”);
(5)内核模块的Makefile文件
内核模块不是独立的可执行文件,但在运行时其目标文件被链接到内核中。只有超级用户才能加载和卸载模块。
Makefile文件的基本内容如下:
obj-m := hellomod.o # 产生hellomod 模块的目标文件 CURRENT_PATH := $(shell pwd) # 模块所在的当前路径 LINUX_KERNEL := $(shell uname -r) # Linux 内核源代码的当前版本 LINUX_KERNEL_PATH := /usr/src/linux-headers-$(LINUX_KERNEL) #Linux内核源代码的绝地路径 all: make -C $(LINUX_KERNEL_PATH) M=$(CURRENT_PATH) modules clean: make -C $(LINUX_KERNEL_PATH) M=$(CURRENT_PATH) clean
obj-m :=这个赋值语句的含义是说明要使用目标文件hellomod.o建立一个模块,最后生成的模块名为hellomod.o.ko。.o文件是经过编译和汇编,而没有经过链接的中间文件。
注:makefile文件中,若某一行是命令,则它必须以一个Tab键开头。
(6)装载模块
当编译好模块,就可以用insmod命令将新的模块插入到内核中,如:
insmod hellomod.o.ko
然后,可以用lsmod命令查看模块是否正确地插入到了内核中。模块的输出由printk()产生。该函数默认打印系统文件/var/log/messages的内容。

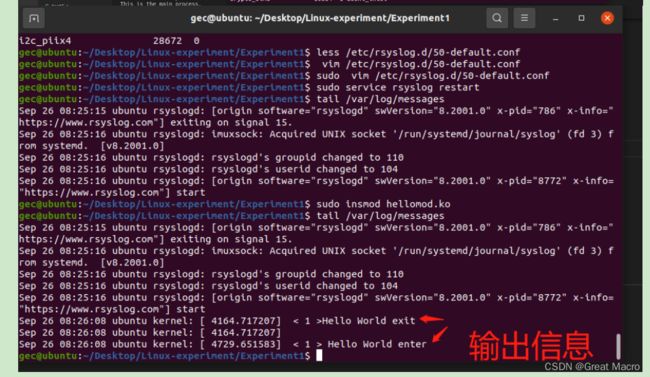
(7)卸载模块
使用rmmod命令加上在insmod中看到的模块名,就可以从内核中移除该模块:
rmmod hellomod.o
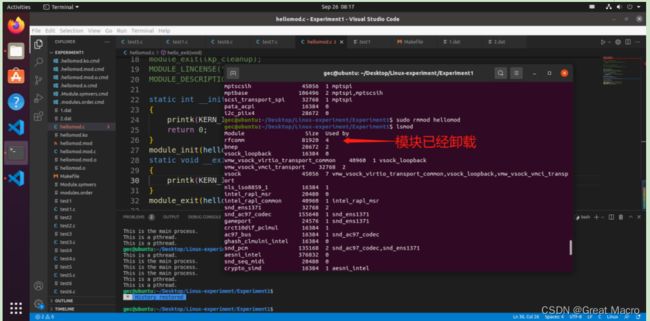
四、思考题
1、程序中的sleep(5)起什么作用?
自我阻塞,给子进程足够多的时间往管道上写入信息,同时防止管道文件被频繁进行读写操作,即子进程一写一点,后到子进程二写一点,如此循环,直到分别都写完为止。
2、子进程1和2为什么也能对管道进行操作?
利用pipe( )建立起来的无名文件(无路径名),即一个无名管道。只能用该系统调用所返回的文件描述符来标识该文件,故只有调用pipe( )的进程及其子孙进程才能识别此文件描述符,才能利用该文件(管道)进行通信。
3、一个内核模块必须具备哪些内容?
模块通常由一组函数和数据结构组成,用来实现一种文件系统、一个驱动程序或者其他内核上层的功能。
模块和内核都在内核空间运行,模块编程在一定意义上说就是内核编程。一个内核模块应该至少有两个函数,第一个为module_init(),是模块加载函数,当模块被插入到内核时调用它;第二个为module_exit(),是模块卸载函数,当模块从内核移走时调用它。
(1)任何模块都要包含的三个头文件:
#include
#include
#incldue
说明:module.h头文件包含了对模块的版本控制;kernel.h包含了常用的内核函数;init.h包含了宏__init和__exit,宏__init告诉编译程序相关的函数和变量仅用于初始化,编译程序将标有__init的所有代码存储到特殊的内存段中,初始化结束就释放这段内存。
(2)printk()函数
该函数是由内核定义的,功能和C库中的printf()类似,它把要打印的日志输
出到终端或系统日志。字符串中的<1>是输出的级别,表示立即在终端输出。
(3)内核模块的入口函数和出口函数
内核模块的入口函数和出口函数是模块编程中最基本的也是必须的两个函数。入口函数向内核注册模块所提供的新功能;出口函数负责注销所有由模块注册的功能。例如;
Static int _init lkm_init(void)
{
printk(KERN_INFO “Hello World!\n”);
return 0;
}
Static void _exit lkm_exit(void)
{
printk(KERN_INFO “Goodbye!\n”);
}
(4)加载模块、卸载模块和声明许可证
module_init和module_exit,这两个函数分别在加载和卸载模块时被调用。例如
module_init(lkm_init);
module_exit(lkm_exit);
声明许可证:
MODULE_LICENSE(“GPL”);
(5)内核模块的Makefile文件
内核模块不是独立的可执行文件,但在运行时其目标文件被链接到内核中。只有超级用户才能加载和卸载模块。