基于python实现TF-IDF算法
标签:2021.09.27工作内容
参考资料:TF-IDF算法介绍及实现
声明:本文中大量内容转载至参考资料,仅归纳整理和加入部分个人观点心得,侵删
概念
- 定义
TF-IDF(term frequency-inverse document frequency)是一种用于信息检索与数据挖掘的常用加权技术,常用于挖掘文章中的关键词。 - 特点:简单高效,用于最开始的文本数据清洗。
- TF-IDF
(1)TF:词频
可以统计到停用词,并把它们过滤,避免对结果造成影响。
e.g.:“的”、“了”、“是”等等
(2)IDF:逆文档频率
在词的频率相同时,不同词的重要性却不同。IDF会给常见的词较小的权重。
e.g.:假设“量化”和“系统”的词频相同,则重要性:“量化” > “系统” - 实现方法
当有TF和IDF后,将其相乘,能够得到一个词的TF-IDF的值。某个词在文章中的TF-IDF越大,那么它在文章中的重要性越高。
算法步骤
- 计算词频
词频 = 某个词在文章中出现的次数 / 文章的总次数 - 计算逆文档的频率
需要一个语料库(corpus)来模拟语言的使用环境。
逆文档频率 = log(语料库的文档总数 / (包含该词的文档数 + 1)) - 计算TF-IDF
TF-IDF= TF × IDF
与一个词在文档中出现的次数成正比。
与该词在整个语言中出现的次数成反比。
优缺点
- 优点
简单高效,容易理解。 - 缺点
(1)词频衡量此的重要性不够全面,有时重要的词出现得不多
(2)无法体现位置信息=>无法体现该词在上下文中的重要性=>用word2vec算法来支持
python实现TF-IDF算法
- 自己构建语料库
这个例子比较特殊,dataset既是语料库,可是我们要统计核心词的对象。
# -*- coding: utf-8 -*-
from collections import defaultdict
import math
import operator
"""
函数说明:创建数据样本
Returns:
dataset - 实验样本切分的词条
classVec - 类别标签向量
"""
def loadDataSet():
dataset = [['my', 'dog', 'has', 'flea', 'problems', 'help', 'please'], # 切分的词条
['maybe', 'not', 'take', 'him', 'to', 'dog', 'park', 'stupid'],
['my', 'dalmation', 'is', 'so', 'cute', 'I', 'love', 'my'],
['stop', 'posting', 'stupid', 'worthless', 'garbage'],
['mr', 'licks', 'ate', 'my', 'steak', 'how', 'to', 'stop', 'him'],
['quit', 'buying', 'worthless', 'dog', 'food', 'stupid']]
classVec = [0, 1, 0, 1, 0, 1] # 类别标签向量,1代表好,0代表不好
return dataset, classVec
"""
函数说明:特征选择TF-IDF算法
Parameters:
list_words:词列表
Returns:
dict_feature_select:特征选择词字典
"""
#dataset:文件夹,word_list:某一个文件,word某个词
def feature_select(dataset):
# 总词频统计
doc_frequency = defaultdict(int) #记录每个词出现的次数,可以把它理解成一个可变长度的list,只要你索引它,它就自动扩列
for file in dataset:
for word in file:
doc_frequency[word] += 1
# 计算每个词的TF值
word_tf = {} # 存储没个词的tf值
for i in doc_frequency:
word_tf[i] = doc_frequency[i] / sum(doc_frequency.values()) #sum(doc.frequency.values)
# 计算每个词的IDF值
doc_num = len(dataset)
word_idf = {} # 存储每个词的idf值
word_doc = defaultdict(int) # 存储包含该词的文档数
for word in doc_frequency:
for file in dataset:
if word in file:
word_doc[word] += 1
#word_doc和doc_frequency的区别是word_doc存储的是包含这个词的文档数,即如果一个文档里有重复出现一个词则word_doc < doc_frequency
for word in doc_frequency:
word_idf[word] = math.log(doc_num / (word_doc[word] + 1))
# 计算每个词的TF*IDF的值
word_tf_idf = {}
for word in doc_frequency:
word_tf_idf[word] = word_tf[word] * word_idf[word]
# 对字典按值由大到小排序
dict_feature_select = sorted(word_tf_idf.items(), key=operator.itemgetter(1), reverse=True)
return dict_feature_select
if __name__ == '__main__':
data_list, label_list = loadDataSet() # 加载数据
features = feature_select(data_list) # 所有词的TF-IDF值
print(features)
运算结果:
![]()
2. NLTK实现TF-IDF算法
由于我的电脑安装了本地代理所以不能下载nltk的语料库,这里只贴代码供大家参考
from nltk.text import TextCollection
from nltk.tokenize import word_tokenize
#首先,构建语料库corpus
sents=['this is sentence one','this is sentence two','this is sentence three']
sents=[word_tokenize(sent) for sent in sents] #对每个句子进行分词
print(sents) #输出分词后的结果
corpus=TextCollection(sents) #构建语料库
print(corpus) #输出语料库
#计算语料库中"one"的tf值
tf=corpus.tf('one',corpus) # 1/12
print(tf)
#计算语料库中"one"的idf值
idf=corpus.idf('one') #log(3/1)
print(idf)
#计算语料库中"one"的tf-idf值
tf_idf=corpus.tf_idf('one',corpus)
print(tf_idf)
- 利用sklearn做tf-idf
import sklearn
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.feature_extraction.text import TfidfTransformer
x_train = ['TF-IDF 主要 思想 是', '算法 一个 重要 特点 可以 脱离 语料库 背景',
'如果 一个 网页 被 很多 其他 网页 链接 说明 网页 重要']
x_test = ['原始 文本 进行 标记', '主要 思想']
# 该类会将文本中的词语转换为词频矩阵,矩阵元素a[i][j] 表示j词在i类文本下的词频
vectorizer = CountVectorizer(max_features=10) #列数为10
# 该类会统计每个词语的tf-idf权值
tf_idf_transformer = TfidfTransformer()
# 将文本转为词频矩阵并计算tf-idf
tf_idf = tf_idf_transformer.fit_transform(vectorizer.fit_transform(x_train))
# 将tf-idf矩阵抽取出来,元素a[i][j]表示j词在i类文本中的tf-idf权重
x_train_weight = tf_idf.toarray()
# 对测试集进行tf-idf权重计算
tf_idf = tf_idf_transformer.transform(vectorizer.transform(x_test))
x_test_weight = tf_idf.toarray() # 测试集TF-IDF权重矩阵
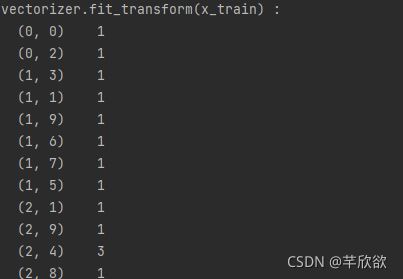
print('vectorizer.fit_transform(x_train) : ')
print(vectorizer.fit_transform(x_train))
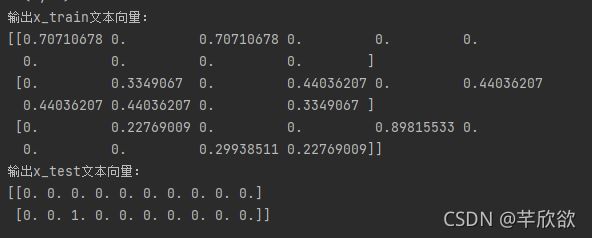
print('输出x_train文本向量:')
print(x_train_weight)
print('输出x_test文本向量:')
print(x_test_weight)
4. 利用Jieba实现tf-idf
import jieba.analyse
text='关键词是能够表达文档中心内容的词语,常用于计算机系统标引论文内容特征、
信息检索、系统汇集以供读者检阅。关键词提取是文本挖掘领域的一个分支,是文本检索、
文档比较、摘要生成、文档分类和聚类等文本挖掘研究的基础性工作'
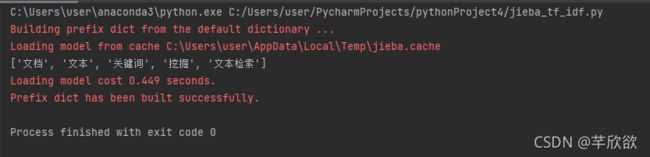
keywords=jieba.analyse.extract_tags(text, topK=5, withWeight=False, allowPOS=())
print(keywords)
注:
jieba.analyse.extract_tags(sentence, topK=20, withWeight=False, allowPOS=())
sentence 为待提取的文本
topK 为返回几个 TF/IDF 权重最大的关键词,默认值为 20
withWeight 为是否一并返回关键词权重值,默认值为 False
allowPOS 仅包括指定词性的词,默认值为空,即不筛选
运行结果:
(安装不了就pip install jieba; conda install jieba; pip3 install jieba;都尝试一边,我用pip3安装才成功的,如果还不成功可以去jieba官网手动下载后自行配置到anaconda环境)