YOLOv5的Tricks | 【Trick1】关于激活函数Activation的改进汇总
如有错误,恳请指出。
文章目录
- 1. ReLU
- 2. Swish
- 3. Mish
- 4. FReLU
- 5. AconC/MetaAconC
- 6. Dynamic ReLU
在yolov5模型搭建的过程实现中,额外实现了很多非常新奇有趣的激活函数,不再是的简单nn.ReLU等,所以这里使用这篇笔记来对这一些列的激活函数进行总结归纳。
关于激活函数,在很早之前我写过一篇笔记介绍,笔记链接:激活函数与Loss函数求导,在这里主要介绍的是目标检测yolov5算法中实现的一些的激活函数,主要设计ReLU函数及其变体,包含ReLU,PReLU,RReLU,FReLU,Swish,Mish,Acon系列,Dynamic ReLU系列。
1. ReLU
ReLU相比之前的 Sigmoid/tanh 的优点有:
- 1)不会发生梯度消失问题。Sigmoid函数在 x>0 会发生梯度消失问题,造成信息损失,从而无法完成深度网络的训练。而 ReLU 函数当 x>0 为线性结构,有固定的梯度,不会消失。
- 2)ReLU激活函数在 x<0 时会输出为0(失活),这可以造成网络的稀疏性。这样可以很好的模拟人脑神经元工作的原理,且可以减少参数间的相互依赖,缓解了过拟合问题的发生。
- 3)Sigmoid函数复杂,计算量大(前向传播+反向传播求导),速度慢;而ReLU函数简单,计算量小,速度快。
缺点:
- 1)由于激活函数是没有上界的,有可能出现神经网络输出为NaN的情况
- 2)(重要)ReLU在训练的时候很”脆弱”,很可能产生 Dead ReLU Problem(神经元坏死现象):某些神经元可能永远不会被激活,导致相应参数永远不会被更新(在负数部分,梯度为0)。举个例子:由于ReLU在x<0时梯度为0,这样就导致负的梯度在这个ReLU被置零,而且这个神经元有可能再也不会被任何数据激活。如果这个情况发生了,那么这个神经元之后的梯度就永远是0了,也就是ReLU神经元坏死了,不再对任何数据有所响应。
- 3)ReLU不会对数据做幅度压缩,所以数据的幅度会随着模型层数的增加不断扩张。
- 4)ReLU的输出不是zero-centered;
其中,ReLU激活函数比较优越的成功之处是因为其具有稀疏性特征,总结起来稀疏性大概有以下四个方面的优点(有点抽象):
- 1)信息分离(Information disentangling):当前,深度学习一个明确的目标是从数据变量中解离出关键因子。原始数据(以自然数据为主)中通常缠绕着高度密集的特征。原因是这些特征向量是相互关联的,一个小小的关键因子可能牵扰着一堆特征,有点像蝴蝶效应,牵一发而动全身。基于数学原理的传统机器学习手段在解离这些关联特征方面具有致命弱点。然而,如果能够解开特征间缠绕的复杂关系,转换为稀疏特征,那么特征就有了鲁棒性(去掉了无关的噪声)。
- 2)有效的可变大小的表达(Efficient variable-size representation):不同的输入蕴含的信息不同,如果我们想用一个数据结构去表示信息,则这种数据结构的大小应该是可变的,否则对于某些输入就无法进行表示,如果一个神经网络是稀疏的,我们就可以通过激活的神经元数量来表示不同大小的信息
- 3)线性可分性(Linear separability):稀疏特征有更大可能线性可分,或者对非线性映射机制有更小的依赖。因为稀疏特征处于高维的特征空间上(被自动映射了)从流形学习观点来看(参见降噪自动编码器),稀疏特征被移到了一个较为纯净的低维流形面上。线性可分性亦可参照天然稀疏的文本型数据,即便没有隐层结构,仍然可以被分离的很好。
- 4)稠密分布但是稀疏(Distributed but sparse):稠密分布着的特征是信息最富集的特征,从潜在性角度,往往比局部少数点携带的特征成倍的有效。而稀疏特征,正是从稠密缠绕区解离出来的,潜在价值巨大。对于神经网络而言,不论是稀疏亦或是稠密,模型都具有一定的复杂度,仍然可以拟合复杂的数据,但过分稀疏会导致模型的复杂度下降,模型的拟合能力大大下降。
ReLU激活函数家族的示意图:
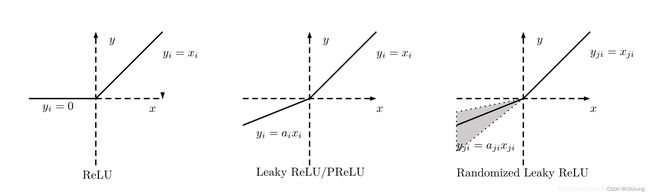
说明:
- Leaky Relu与PRelu有点像,不过leaky relu是手动设置x<0时的斜率(一般a设为0.01,最好小于0.01),而prelu的a是可以通过反向传播学习到的,也就是一个可学习的参数
- RReLU全称为Randomized Leaky ReLU,如其名一样,其斜率a是随机的,训练时期随机斜率服从一个均匀分布U(l, u),但是测试是将训练的所有随机斜率a取平均值
在 《Empirical Evaluation of Rectified Activations in Convolution Network》 论文中的小数据集上的实验证明,Leaky ReLU、PReLU、RReLU的表现都要优于当前使用最多的激活函数ReLU。但这仅仅是在小数据集上的表现,更大的数据集更复杂的任务的情况下,还需要更多的实验。其中,RReLU的效果是最好的。
2. Swish
Swish是使用自动搜索技术搜索出的一个激活函数,其中原论文中终结了几个设计激活函数的准则,也可以所是搜索过程中所得出的经验:
- 1)复杂的激活函数性能始终低于更简单的激活功能,可能是由于优化的难度增加。性能最佳的激活功能可以由1或2个核心单元表示。
- 2)性能最优的激活函数共有的一个共同结构是使用原始预激活x作为最终二元函数的一个输入:
b(x, g(x))。ReLU函数也遵循这种结构,其中b(x1, x2) = max(x1, x2),其中x2为0,x1为x - 3)搜索发现了使用周期函数的激活函数,例如sin和cos。周期函数的最常见用途是通过使用原始预激活x(或线性缩放的x)进行加法或减法。在激活函数中使用周期函数只是在先前的工作中进行了简要探讨,因此这些发现的函数为进一步研究提供了一条富有成效的途径。
- 4)使用除法的函数往往表现不佳,因为当分母接近0时输出会爆炸。只有当分母中的函数要么偏离0时才会成功,例如
cosh(x),或者仅当分子也接近0时才成功 接近0,产生1的输出。
总之,搜索处理的Swish在ImageNet上比ReLU是有提升的,其优点有:
像ReLU一样,Swish在上界是无限的,下界是有限的。与ReLU不同的是,Swish是平滑且非单调的( non-monotonic)
Swish激活函数的数学表示为:f(x) = x·sigmoid(βx) = x·σ(βx)。当β为1时,Swish激活函数简化为:f(x) = x·σ(x)
Swish激活函数的导数推导过程:
所以,最后Swish的导数:f'(x) = σ(βx)[1 + xβ(1 - σ(βx))],当β为1时,Swish的导数简化为:f'(x) = σ(x)[1 + x(1 - σ(x))]
主要,这里的Swish导数重新构建成与σ(x)有关的形式是非常重要的,因为在Pytorch中可以直接设置一种高效的激活函数实现方式,而且不是简答的掉包nn.Swish实现(这里只是打比方,因为pytorch现在还没有实现Swish函数,不过其实现了Hardswish函数)。也就是需要自己实现前向传播与方向传播的过程。
其对比如下所示:
# 普通的Swish实现方式
class Swish(nn.Module):
def __init__(self, beta=1.):
super().__init__()
self.beta = beta
def forward(self, x):
if self.beta == 1.:
return x * torch.sigmoid(x) # 默认参数beta = 1
else:
return x * torch.sigmoid(self.beta * x) # 当beta != 1时
更普通的方式是使用:nn.SiLU()来实现。
高效的Swish实现方式,集成torch.autograd.Function,自定义实现前向传播与方向传播
class MemoryEfficientSwish(nn.Module):
class F(torch.autograd.Function):
@staticmethod
def forward(ctx, x):
# save_for_backward会保留x的全部信息(一个完整的外挂Autograd Function的Variable),
# 表示forward()的结果要存起来,以后给backward()
ctx.save_for_backward(x)
# 前向传播的数学表达式:f(x) = x·sigmoid(βx) = x·σ(βx)
# 当β = 1时, f(x) = x·σ(x)
return x * torch.sigmoid(x)
@staticmethod
def backward(ctx, grad_output): # grad_output是最终object对的forward()输出的导数
# ctx.saved_tensors得到之前forward()存的结果
x = ctx.saved_tensors[0]
sx = torch.sigmoid(x)
# 这里默认是beta=1的情况:f'(x) = σ(x)[1 + x(1 - σ(x))]
# 当beta不等与1的情况: f(x)=σ(βx)[1 + xβ(1 - σ(βx))]
return grad_output * (sx * (1 + x * (1 - sx)))
def forward(self, x): # 应用前向传播方法
return self.F.apply(x)
但是假如我想在MemoryEfficientSwish中动态设置beta的数值,这需要如何把参数传进去呢?以下我是稍微更该的代码,在前向传播是可以正常运行的,但是反向传播的时候会报错,如有具体的解决方法希望可以在评论区告诉我(在其他的博客中没有找到我这需求的解决方法)。此外,关于torch.autograd.Function的使用,到时再用一篇博客来记录一下学习笔记。
# 高效的Swish实现方式
# 优点:节省内存,而且不采用自动求导(自己写前向传播与方向传播),更加高效
class MemoryEfficientSwish(nn.Module):
# 可以传入参数beta,默认为1,也就是简化的版本
def __init__(self, beta=1.):
super().__init__()
self.beta = beta
class F(torch.autograd.Function):
@staticmethod
def forward(ctx, x, beta=1.0):
# save_for_backward会保留x的全部信息(一个完整的外挂Autograd Function的Variable),
# 并提供避免in-place操作导致的input在backward被修改的情况.
# in-place操作指不通过中间变量计算的变量间的操作。
ctx.save_for_backward(x)
# 前向传播的公式为:f(x) = x·σ(βx)
if beta == 1.:
return x * torch.sigmoid(x) # 默认参数beta = 1
else:
return x * torch.sigmoid(beta * x) # 当beta != 1时
@staticmethod
def backward(ctx, grad_output, beta=1.0):
# 此处saved_tensors[0] 作用同上文 save_for_backward
x = ctx.saved_tensors[0]
# 返回该激活函数求导之后的结果
# 反向传播的公式为:f'(x) = σ(βx)[1 + xβ(1 - σ(βx))]
if beta == 1.:
sx = torch.sigmoid(x)
return grad_output * (sx * (1 + x * (1 - sx)))
else:
sx = torch.sigmoid(beta * x)
return grad_output * (sx * (1 + x * beta * (1 - sx)))
# 应用前向传播方法
# 由于Function没有self这个类,只能通过apply传入父类MemoryEfficientSwish定义的self.beta参数
def forward(self, x):
return self.F.apply(x, self.beta)
以上代码在前向传播是可以实现的,但是方向传播会出现问题,我已经提了一个问题了:(使用torch.autograd.Function自定义激活函数时,如何在父类中对子类传入参数?)[https://ask.csdn.net/questions/7727734],请大佬指教指教。
3. Mish
激活函数在神经网络中的意义主要是为模型引入非线性,而当前广泛使用的激活函数主要就是以上两种:ReLU和Swish。其中ReLU作为激活函数主要是有无上界和有下界的特点,而Swish相比ReLU又增加了平滑和非单调的特点。同样的,Mish激活函数同样拥有无上界(unbounded above)、有下界(bounded below)、平滑(smooth)和非单调(nonmonotonic)四个优点。其在ImageNet上的效果比ReLU和Swish都要好。
Mish的数学表示为:f(x) = x ⋅ tanh(softplus(x)) = x ⋅ tanh(ln(1 + exp(x)))
Mish的导数表示为:f'(x) = f(x) + x * σ(x) * (1 - f(x) * f(x))
代码实现在yolov5中如下所示:
# 普通实现,或者直接调用nn.Mish()
class Mish(nn.Module):
@staticmethod
def forward(x):
return x * F.softplus(x).tanh() # softplus(x) = ln(1 + exp(x)
# 高效实现,自定义前向传播forward与反向传播backward
class MemoryEfficientMish(nn.Module):
class F(torch.autograd.Function):
@staticmethod
def forward(ctx, x):
ctx.save_for_backward(x) # 表示forward()的结果要存起来,以后给backward()
return x.mul(torch.tanh(F.softplus(x))) # x * tanh(ln(1 + exp(x)))
# grad_output是最终object对的forward()输出的导数, 也就是理解为上一层求导的结果
# ctx是一个元祖
@staticmethod
def backward(ctx, grad_output): # grad_output上一层求导的结果
x = ctx.saved_tensors[0] # ctx.saved_tensors得到之前forward()存的结果
sx = torch.sigmoid(x)
fx = F.softplus(x).tanh()
return grad_output * (fx + x * sx * (1 - fx * fx))
def forward(self, x):
return self.F.apply(x)
图像绘制出来都是类似的,只有小幅度的区别:
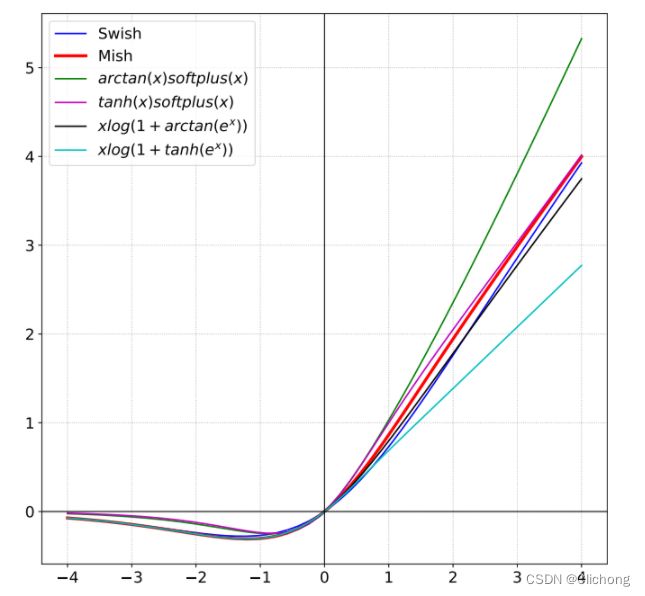
4. FReLU
接下来就是在yolov5代码中看见的一些没见过的激活函数,且pytorch中也还没有实现:FReLU、AconC、MetaAconC。
首先从FReLU开始了解。
简单来说,FReLU(Funnel ReLU 漏斗ReLU)非线性激活函数通过对局部卷积后的输出与原始数据进行一个max的比对,将ReLU与PReLU扩展成2D的激活函数。如下图所示:
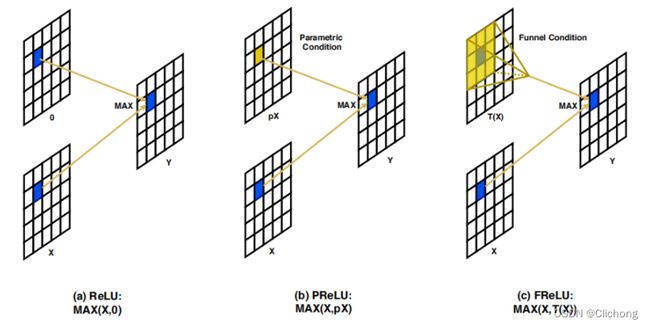
这里的卷积处理是一个可分离卷积,其实也就是对每一层的channel分别进行一个非线性处理,然后对特征层进行一个归一化,这里的输入和输出的保持不变的。然后对输出的特征图与原始的输入x来进行max处理,这样做解决了激活函数中的空间不敏感问题,使规则(普通)的卷积也具备捕获复杂的视觉布局能力,使模型具备像素级建模的能力。
实践如下所示:
channels = 4
conv_bn = nn.Sequential(
nn.Conv2d(channels, channels, kernel_size=3, stride=1, padding=1, groups=channels, bias=False),
nn.BatchNorm2d(channels)
)
image = torch.rand([1, channels, 32, 32])
torch.max(image, conv_bn(image)) # 输出
作者认为激活函数中的空间不敏感性是阻碍视觉任务实现显著改善的主要原因,提出FReLU激活函数的出发点有两个:
- 1)近年来也有很多的的研究工作是针对卷积层的改进,使卷积层具有了自适应获取图像局部上下文(获取空间依赖关系)的能力,大大提高了网络模型的精度。但是这些新设计的卷积一般都是非常复杂的卷积层。那么能否让普通(规则)的卷积也具有这种自适应获取图像局部上下文的能力,来抓取具有挑战性的复杂图像信息呢?
- 2)卷积处理过程是在卷积层线性捕捉空间依赖性后,再由激活层进行非线性变换。激活函数在卷积神经网络中起到了非常重要的作用,既然卷积层想要起到获取空间依赖关系的作用很困难(需要将简单卷积改成复杂卷积),那么是否可以设计一种专门针对视觉任务的简单激活函数(具有了自适应获取图像局部上下文能力且形式又简单的激活函数)?
这个出发点其实还挺有启发性的,故事的起因很完善。FReLU在产生微不足道的内存开销的情况下,性能都是优于ReLU、PReLU和Swish等激活函数的,说明其可以更好地捕捉不规则和详细的对象布局(空间信息)
在YOLOv5中FReLU的实现:
# 原理:对局部卷积后的输出与原始数据进行一个max的比对
class FReLU(nn.Module):
def __init__(self, c1, k=3): # ch_in, kernel
super().__init__()
# 可分离卷积,不改变hw与channels
self.conv = nn.Conv2d(c1, c1, k, 1, 1, groups=c1, bias=False)
self.bn = nn.BatchNorm2d(c1)
def forward(self, x):
# 卷积处理后的特征图与原来的x是相同的shape的
return torch.max(x, self.bn(self.conv(x)))
5. AconC/MetaAconC
paper:https://arxiv.org/pdf/2009.04759.pdf
刚刚提到的FReLU激活函数关于与激活函数也可以关注与捕获空域讯息,对感受野有所增加,与卷积捕获空域信息相互促进,使其同样可以达到复杂卷积的效果的。
而现在介绍的AconC激活函数则是对ReLU函数的归纳总结,用数学的方法解释了搜索出来的Swish激活函数是ReLU的一个平滑近视(Smoth maximum),进而提出了Maxout系列的泛化形式。这里论文进行了详细的数学证明发现,ReLU的平滑近似就是Swish。这也给Swish的高效性提供了一个全新的解释。由于比较复杂,这里就直接给出利用平滑近视Smoth maximum公式求它的平滑近似函数的数学公式为:

这里对Maxout进行一个介绍补充:
Maxout是很多激活函数的通用公式,f(x) = max(a(x), b(x)),常见的如ReLU: f(x) = max(x, 0),PReLU:f(x) = max(x, px)等,这里的AconC激活函数就是拓展Maxout为更一般的形式:f(x) = max(p1(x), p2(x))。以下就是通过近似平滑Maxout系列函数而得到的Acon系列激活函数:

论文贡献:
- 1)提出一种新颖的Swish函数解释(Swish不再是一个黑盒):Swish函数是ReLU函数的平滑近似(Smoth maximum)。
- 2)基于这个发现,论文进一步分析ReLU的一般形式Maxout系列激活函数,再次利用Smoth maximum将Maxout系列扩展得到简单且有效的ACON系列激活函数:ACON-A、ACON-B、ACON-C;
- 3)提出meta-ACON,动态的学习(自适应)激活函数的线性/非线性,显著提高了表现。另外还证明了ACON的参数P1和P2
负责控制函数的上下限(ACON-C的一阶导数的上下界也是通过p1和p2两个参数来共同决定的,这个对最终效果由很大的意义);参数β负责动态的控制激活函数的线性/非线性(β趋于正无穷时,函数是非线性的;β趋于0时,函数是线性的)。
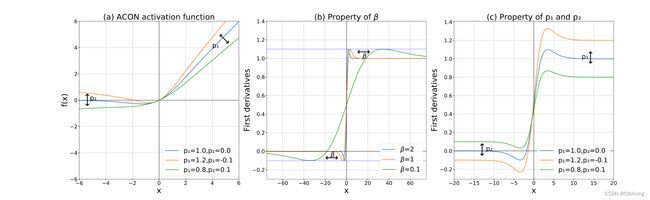
所以,由于参数β可以控制激活的线性与非线性,也就是允许神经元自适应激活或者不激活。所以其实Acon系列激活函数的全称就是:Activate Or Not,是否选择激活神经元
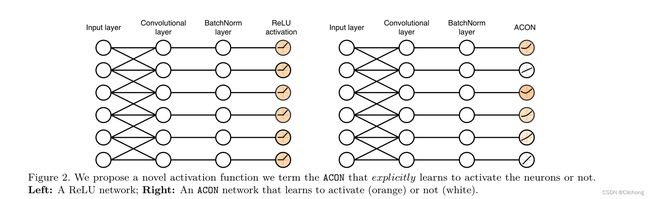
那么,这个动态控制函数线性与非线性能力的参数就可以进行一个自适应学习,一般自适应学习有3种设置方案:
- 1)layer-wise:对一个channels层hw进行自适应学习
- 2)channel-wise:对整条channels进行自适应学习
- 3)pixcel-wise:对整个特征图hwc,也就是每一个像素点进行自适应学习
这里论文选择的是第二种,也就是通过也SE自注意力机制来动态学习,顺便减少参数
参考代码:(其中AconA与AconB是自己写的,AconC与MetaAcon是yolov5提供的代码)
class AconA(nn.Module):
r""" ACON activation (activate or not).
AconC: x * sigmoid(beta*x)
according to "Activate or Not: Learning Customized Activation" .
"""
def __init__(self, beta = 1.0):
super().__init__()
self.beta = beta
def forward(self, x):
return x * torch.sigmoid(self.beta * x)
class AconB(nn.Module):
r""" ACON activation (activate or not).
AconC: (x-p*x) * sigmoid(beta*(x-p*x)) + p*x
according to "Activate or Not: Learning Customized Activation" .
"""
def __init__(self):
super().__init__()
self.p = nn.Parameter(torch.randn(1))
self.beta = nn.Parameter(torch.ones(1))
def forward(self, x):
dpx = (1 - self.p) * x
return dpx * torch.sigmoid(self.beta * dpx) + self.p * x
class AconC(nn.Module):
r""" ACON activation (activate or not).
AconC: (p1*x-p2*x) * sigmoid(beta*(p1*x-p2*x)) + p2*x, beta is a learnable parameter
according to "Activate or Not: Learning Customized Activation" .
"""
def __init__(self, c1):
super().__init__()
self.p1 = nn.Parameter(torch.randn(1, c1, 1, 1))
self.p2 = nn.Parameter(torch.randn(1, c1, 1, 1))
self.beta = nn.Parameter(torch.ones(1, c1, 1, 1))
def forward(self, x):
dpx = (self.p1 - self.p2) * x
return dpx * torch.sigmoid(self.beta * dpx) + self.p2 * x
class MetaAconC(nn.Module):
r""" ACON activation (activate or not).
MetaAconC: (p1*x-p2*x) * sigmoid(beta*(p1*x-p2*x)) + p2*x, beta is generated by a small network
according to "Activate or Not: Learning Customized Activation" .
"""
def __init__(self, c1, k=1, s=1, r=16): # ch_in, kernel, stride, r
super().__init__()
c2 = max(r, c1 // r)
self.p1 = nn.Parameter(torch.randn(1, c1, 1, 1))
self.p2 = nn.Parameter(torch.randn(1, c1, 1, 1))
self.fc1 = nn.Conv2d(c1, c2, k, s, bias=True)
self.fc2 = nn.Conv2d(c2, c1, k, s, bias=True)
# self.bn1 = nn.BatchNorm2d(c2)
# self.bn2 = nn.BatchNorm2d(c1)
def forward(self, x):
# (b, c, h, w) -> (b, c, 1, 1)
y = x.mean(dim=2, keepdims=True).mean(dim=3, keepdims=True)
# batch-size 1 bug/instabilities https://github.com/ultralytics/yolov5/issues/2891
# beta = torch.sigmoid(self.bn2(self.fc2(self.bn1(self.fc1(y))))) # bug/unstable
# 先降维再升维,一个类似AE的操作
beta = torch.sigmoid(self.fc2(self.fc1(y))) # bug patch BN layers removed
dpx = (self.p1 - self.p2) * x
return dpx * torch.sigmoid(beta * dpx) + self.p2 * x
简要分析:
可以发现Acon激活函数训练了3组可学习参数来对每个channel进行处理;而MetaAconC则是使用了类似SE的通道注意力机制,另外实现了beta的自适应学习。总之,meta-ACON激活函数无论在分类(甚至是很深的网络)和目标检测领域的性能都要优于ReLU和Swish(且参数量和FLOPs几乎一样的情况下)。ACON-C的性能要差meta-ACON一点,但也很不错。
总之,这篇论文系统的对Maxout系列进行近似平滑的研究拓展,得到了一个比较泛化的激活函数。而通过注意力机制自适应学习beta可以获得更好的效果(直接看代码可能会更容易理解一点,也更加的主观的了解具体在做什么)。
6. Dynamic ReLU
paper: https://arxiv.org/pdf/2003.10027.pdf
这个激活函数是看一个博主了解到的,下面的参考资料基本都是来自于他的博客。
这里直接看图就可以清晰的知道Dynamic ReLU这个激活函数在做什么东西了:
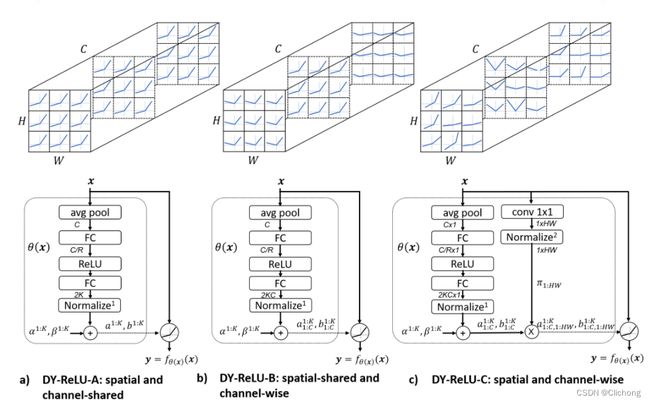
简要分析:
- DY-ReLU-A(spatial and channel-shared):图a表示对特征图的所有神经元使用相同的Maxout参数控制(性能没有太大的提升,因为和PReLU激活系列类似)
- DY-ReLU-B(spatial-shared and channel-wise):图b表示对特征图的每个channel层使用不同的Maxout参数控制(提升了性能,且参数量增加不大,一般用这个)
- DY-ReLU-C(spatial and channel-wise):图c表示对特征图的每个channel层上的每一个特征点都使用不同的Maxout参数控制(参数量太大,少用)
可以看见,这里的核心思想就是动态的控制神经元的Maxout设置。假如以ReLU为例,yc = max(x, 0),可以统一表示为带参分段函数:yc = max(ac*xc + bc),当x>0时,若a=1,b=0; 当x<时,若a=b=0,就是ReLU。也就是DY-ReLU可以根据输入x的变化,自动变化几个关键参数,自适应的更换更高效的激活函数,所以才称其为动态神经网络。
参考代码(DY-ReLU具体实现思想可以看注释):
class DyReLU(nn.Module):
def __init__(self, channels, reduction=4, k=2, conv_type='2d'):
super(DyReLU, self).__init__()
self.channels = channels
self.k = k
self.conv_type = conv_type
assert self.conv_type in ['1d', '2d']
# 这里降维1/4,然后再重新升维
self.fc1 = nn.Linear(channels, channels // reduction)
self.relu = nn.ReLU(inplace=True)
self.fc2 = nn.Linear(channels // reduction, 2*k)
self.sigmoid = nn.Sigmoid()
self.register_buffer('lambdas', torch.Tensor([1.]*k + [0.5]*k).float())
self.register_buffer('init_v', torch.Tensor([1.] + [0.]*(2*k - 1)).float())
def get_relu_coefs(self, x):
theta = torch.mean(x, dim=-1)
if self.conv_type == '2d':
theta = torch.mean(theta, dim=-1)
theta = self.fc1(theta)
theta = self.relu(theta)
theta = self.fc2(theta)
# 归一化层(normalization layer)将输出限定在 (-1, 1)之间(采用2 * Sigmoid - 1函数就可以做到)
theta = 2 * self.sigmoid(theta) - 1
return theta
def forward(self, x):
raise NotImplementedError
class DyReLUA(DyReLU):
def __init__(self, channels, reduction=4, k=2, conv_type='2d'):
super(DyReLUA, self).__init__(channels, reduction, k, conv_type)
self.fc2 = nn.Linear(channels // reduction, 2*k)
def forward(self, x):
assert x.shape[1] == self.channels
# 对全部channel分别分配两组参数a, b(这两个组的函数个数都是2, 所以也就是2*2=4个参数)
# 所以这里theta.shape = [b, 2*2]
theta = self.get_relu_coefs(x) # 这里是执行到normalize
# 再经过一个初始值和残差的加权和得到最终输出(lambdas为一个控制标量, 也是一个超参数)
relu_coefs = theta.view(-1, 2*self.k) * self.lambdas + self.init_v # 这里是执行完 theta(x)
# BxCxL -> LxCxBx1
# b,c,h,w -> w,c,h,b,1
# 维度置换的原因是需要一个矩阵相乘的数学处理
x_perm = x.transpose(0, -1).unsqueeze(-1)
# a^k_c=relu_coefs[:, :self.k] b^k_c=relu_coefs[:, self.k:]
# a^k_c(x) * x_c + b^k_c(x) -> ax + b
# (w,c,h,b,1) * [b, 2] + [b, 2] -> (w,c,h,b,2)
output = x_perm * relu_coefs[:, :self.k] + relu_coefs[:, self.k:]
# LxCxBx2 -> BxCxL
# y_c = max{a^k_c(x) * x_c + b^k_c(x)}
# (w,c,h,b,2) -> (w,c,h,b) -> (b,c,h,w) 不改变特征图维度
result = torch.max(output, dim=-1)[0].transpose(0, -1)
return result
class DyReLUB(DyReLU):
def __init__(self, channels, reduction=4, k=2, conv_type='2d'):
super(DyReLUB, self).__init__(channels, reduction, k, conv_type)
self.fc2 = nn.Linear(channels // reduction, 2*k*channels)
def forward(self, x):
assert x.shape[1] == self.channels
# 对每组channel分别分配两组参数a, b(这两个组的函数个数都是2, 所以也就是2*2=4个参数)
# 所以这里theta.shape = [b, 2*2*channels]
theta = self.get_relu_coefs(x)
# 再经过一个初始值和残差的加权和得到最终输出 shape: [b, channels, 4]
relu_coefs = theta.view(-1, self.channels, 2*self.k) * self.lambdas + self.init_v
if self.conv_type == '1d':
# BxCxL -> LxBxCx1
x_perm = x.permute(2, 0, 1).unsqueeze(-1)
output = x_perm * relu_coefs[:, :, :self.k] + relu_coefs[:, :, self.k:]
# LxBxCx2 -> BxCxL
result = torch.max(output, dim=-1)[0].permute(1, 2, 0)
elif self.conv_type == '2d':
# BxCxHxW -> HxWxBxCx1
x_perm = x.permute(2, 3, 0, 1).unsqueeze(-1)
# 每组channel都有两组参数, 来对channels进行非线性操作, 维度置换的原因是需要一个矩阵相乘的数学处理
# [h, w, b, c, 1] * [b, channels, 2] + [b, channels, 2]
output = x_perm * relu_coefs[:, :, :self.k] + relu_coefs[:, :, self.k:]
# 最后的maxout处理: HxWxBxCx2 -> BxCxHxW
result = torch.max(output, dim=-1)[0].permute(2, 3, 0, 1)
return result
分析:
从代码层面来分析,以DyReLU-B为例,其通过将输入x编码为一个自适应的动态参数theta(theta可以看成是两组a,b的函数参数,这里的函数个数k设置为2)。为了让每组通道都有自己的动态控制能力也就是自适应性,所以这里为每一组通道都分配了一组theta参数,一组theta参数为[2 * 2](因为函数个数为2,分为a,b两组),接着假设有32个channels,那么全部的theta参数就是[2 * 2 * 32]。这一组参数就是控制每层channel的激活函数变化(具体来说是控制每个channel的maxout激活公式)。
其中,这里的theta参数还受两组超参数lambda与v的加权处理,其实也就是theta * lambda + v(ax + b)的一个简单的线性处理形式。加权处理后的theta参数就可以与输入x进行一个maxout形式的处理了。不过这里由于需要对channel进行控制操作,所以涉及一下矩阵的变换以实现矩阵乘法。最后maxout(ax + b)就实现了所有channel的自适应调整了。一句话概括,就是将x编码获取参数theta再来动态处理x。
后续,最后总感觉Meta AconC和Dymaic的部分存在相似,beta与theta都是想突出一个自适应调整的环节,前者是使用了SE自注意机制,后者则用了编码加权和获取调整的参数。
参考资料:
1. ReLU、Leaky ReLU、PReLU、RReLU实验对比
2.ReLU Activation
3. Swish-Activation
4. SEARCHING FOR ACTIVATION FUNCTIONS翻译
5. 自定义操作torch.autograd.Function
6. 玩转Pytorch的Function类
7. pytorch中的grad求导说明以及利用backward获取梯度信息
8. Mish: A Self Regularized Non-Monotonic Neural Activation Function论文笔记
9. FReLU Activation
10. 【YOLOV5-5.x 源码解读】activations.py
11. 激活函数与Loss函数求导
12. ACON Activation(2021)
13. Dynamic ReLU(2020)