【复盘比赛】SDP 2021@NAACL LongSumm 科学论⽂⻓摘要生成任务 第一名
SDP 2021@NAACL LongSumm 科学论⽂⻓摘要生成任务 第一名
- 前言
- 任务介绍
-
- 问题描述
- 数据展示
- 模型尝试
-
- 抽取模型尝试
-
- DGCNN抽取模型
- BertSumm
- 生成模型尝试
-
- End2end [PEGASUS + BIGBIRD]
-
- PEGASUS:专注于摘要生成的预训练模型
- BIGBIRD:线性复杂度的self-attention机制
- 结果:重复解码严重,模型无法输出长摘要
- UniLM 抽取+生成 [2048-1024]
- SBAS (session based automatic summarization model)
-
- Session based 生成模型
- 抽取模型
- Ensemble Method
- 测试结果
-
- 部分摘要样例
- 部分参考文献
前言

失踪人口回归!
因为期末 + 春节的原因,断更了好久。2月份去了网易的人工智能实验室实习,做的自然语言处理实习生。因为之后有个项目是和文本生成相关,老板让我去参加个学术会议比赛熟悉下。然后就选了SDP 2021@NAACL Longsumm Task,我和另一个实习生一起奋战了一个月最后成功代表网易人工智能实验室拿到排行榜第一名的成绩。我们的SBAS模型比第二名各项指标都高出了0.02。
任务介绍
问题描述
- Most of the work on scientific document summarization focuses on generating relatively short summaries. Such a length constraint might be appropriate when summarizing news articles but it is less adequate for scientific work. In fact, such a short summary resembles an abstract and cannot cover all the salient information conveyed in a given scientific text. Writing longer summaries requires expertise and a deep understanding in a scientific domain, as can be found in some researchers blogs.
- To address this point, the LongSumm task opted to leverage blog posts created by researchers in the NLP and Machine learning communities that summarize scientific articles and use these posts as reference summaries.
- 简单来说就是给长论文生成类似于博客的长摘要,我们可以将其归结为长输入长输出的摘要任务,这个任务的难点就在于与我们平时接触的新闻摘要等摘要任务不同,科学论文博客摘要的字数更长而且有一定结构化,并且要求模型对文章进行充分的理解。
数据展示
- Abstractive Summaries: The corpus for this task includes a training set that consists of 1705 extractive summaries, and 531 abstractive summaries of NLP and Machine Learning scientific papers.
- 生成摘要数据来自于网络上一些研究人员针对某篇科学论文的博客内容共531个样本,文章长度在3000-12000字,摘要长度在200-1500字。
{
"id": "79792577",
"blog_id": "4d803bc021f579d4aa3b24cec5b994",
"summary": [
"Task of translating natural language queries into regular expressions ...",
"Proposes a methodology for collecting a large corpus of regular expressions ...",
"Reports performance gain of 19.6% over state-of-the-art models.",
"Architecture LSTM based sequence to sequence neural network (with attention) Six layers ...",
"Attention over encoder layer.",
"...."
],
"author_id": "shugan",
"pdf_url": "http://arxiv.org/pdf/1608.03000v1",
"author_full_name": "Shagun Sodhani",
"source_website": "https://github.com/shagunsodhani/papers-I-read"
}
- Extractive summaries: The extractive summaries are based on video talks from associated conferences (Lev et al. 2019 TalkSumm) while the abstractive summaries are blog posts created by NLP and ML researchers.
- 抽取摘要数据来自于学术会议中的video talks,每篇文章提供前30句摘要,平均990字。
Title: A Binarized Neural Network Joint Model for Machine Translation
Url: https://doi.org/10.18653/v1/d15-1250
Extractive summaries:
0 23 Supertagging in lexicalized grammar parsing is known as almost parsing (Bangalore and Joshi, 1999), in that each supertag is syntactically informative and most ambiguities are resolved once a correct supertag is assigned to every word.
16 22 Our model does not resort to the recursive networks while modeling tree structures via dependencies.
23 19 CCG has a nice property that since every category is highly informative about attachment decisions, assigning it to every word (supertagging) resolves most of its syntactic structure.
24 14 Lewis and Steedman (2014) utilize this characteristics of the grammar.
27 16 Their model looks for the most probable y given a sentence x of length N from the set Y (x) of possible CCG trees under the model of Eq.
28 38 Since this score is factored into each supertag, they call the model a supertag-factored model.
30 58 ci,j is the sequence of categories on such Viterbi parse, and thus b is called the Viterbi inside score, while a is the approximation (upper bound) of the Viterbi outside score.
31 19 A* parsing is a kind of CKY chart parsing augmented with an agenda, a priority queue that keeps the edges to be explored.
48 37 As we will see this keeps our joint model still locally factored and A* search tractable.
50 11 We define a CCG tree y for a sentence x = ⟨xi, .
… …
模型尝试
这篇博客重点阐述模型迭代过程以及最终解决方案,对于数据的转换、处理,模型尝试与对比实验等方法可以在之后的论文中获取。
抽取模型尝试
DGCNN抽取模型
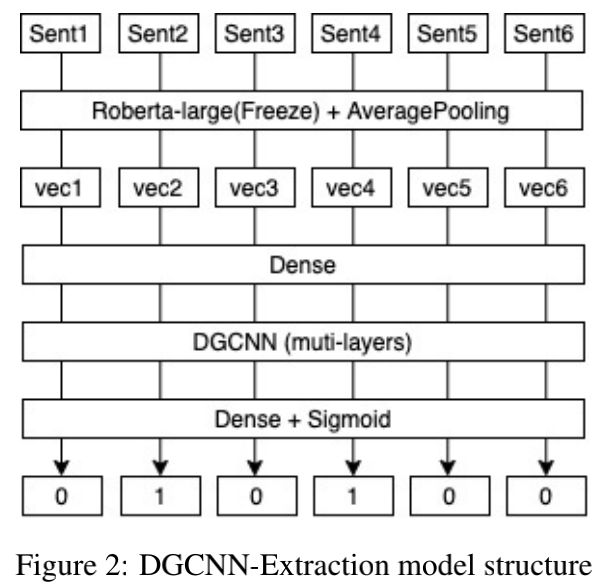
- DGCNN模型大家应该比较熟悉,灵感来自苏神。我们利用Roberta-large作为句子的特征提取器,将论文分句后进行特征转换,每篇论文截取前400个句子。之后我们通过DGCNN对句子之间的特征进行提取,对每个句子作一个二分类来判断该句子是否为重要摘要。DGCNN的优势在于能同时处理文章的全部句子,通过句子之间的关系以及位置来辅助判断该句子的重要性。
- 模型融合:除了K-fold或许我们还可以换底,值得一提的是在比赛结束后被腾讯一位可爱的小姐姐询问道我们是否有进行模型融合,我表示只进行了特征提取器之间的比较(bert,roberta等)然后作了K-fold。小姐姐提示我可以通过更换不同的特征提取器来训练多个抽取模型,最后将这些模型的结果进行融合,我认为这非常有道理,不同的预训练语料、不同的模型结构只要是encoder都可以作为特征提取器进行尝试,这也许能带来不错的提升。
- 模型训练时,我们以 0.2Rough1-f + 0.4Rough2-f + 0.4RoughL-f 作为评价指标,这也与最终的评估指标相近,最终模型在抽取数据的验证集上能达到0.55的分数。
BertSumm
Fine-tune BERT for Extractive Summarization
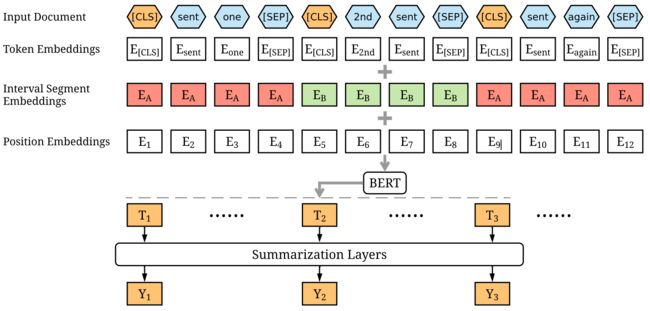
- As illustrated in Figure 1, we insert a [CLS] token before each sentence and a [SEP] token after each sentence. In vanilla BERT, The [CLS] is used as a symbol to aggregate features from one sentence or a pair of sentences. We modify the model by using multiple [CLS] symbols to get features for sentences ascending the symbol.
- 受到bert输入长度的限制,我们将文章按section进行拆分后,以section为单位对摘要句进行抽取。虽然这样作我们变相地增加了训练样本(1600->17720),但需要机遇摘要句子对于section来说是相互独立的,也就是一篇文章的摘要是可以通过独立地处理section来得到。但这显然是不合理的假设,同样在训练阶段显示,模型过拟合严重,在验证集上效果较差,F1-score仅0.3左右。
生成模型尝试
End2end [PEGASUS + BIGBIRD]
PEGASUS:专注于摘要生成的预训练模型
PEGASUS: Pre-training with Extracted Gap-sentences for Abstractive Summarization
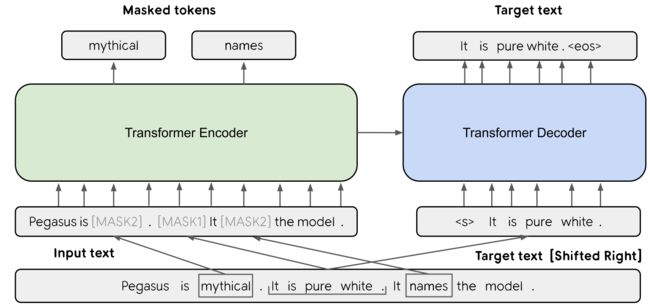
- PEGASUS在Transformer框架下,在MLM预训练任务的基础上,加入Gap Sentences Generation (GSG) 的预训练任务,使得模型在预训练阶段就更接近摘要生成的下有任务,可以说是专门为摘要生成任务服务的预训练Seq2Seq模型。
- Gap Sentences Generation (GSG) 句子MASK方案: (1) Random Uniformly select m sentences at random. (2) Lead Select the first m sentences. (3) Principal Select top-m scored sentences according to importance. As a proxy for importance we compute ROUGE1-F1 (Lin, 2004) between the sentence and the rest of the document, si=rouge(xi, D \ {xi}), ∀i. 通过对比实验发现以方案三作为筛选Target text效果最优。

BIGBIRD:线性复杂度的self-attention机制
Big Bird: Transformers for Longer Sequences
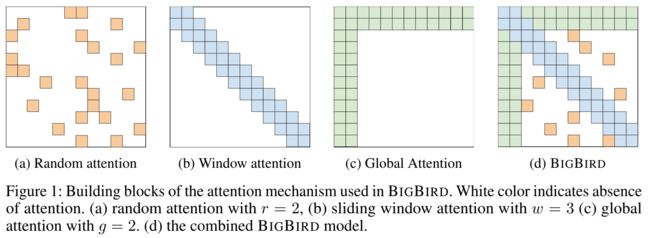
- BIGBIRD是Google2021年提出的一种新的self-attention框架,目的在于降低self-attention的二次计算复杂度让模型在计算资源有限的前提下能处理更长的输入,在以往研究的基础上BIGBRID融合了Random attention、Window attention、Global Attention,将self-attention的计算复杂度降低至线性,并证明了其仍然保持饿了图灵完整性。
- We focus on introducing the sparse attention mechanism of BIGBIRD only at
the encoder side. This is because, in practical generative applications, the length of output sequence is typically small as compared to the input. 在计算Seq2Seq模型的self-attention计算复杂度时,我们应该将encoder和decoder分开看,对于摘要生成任务,其输入往往较长输出往往较短,因此BIGBIRD的开源代码中只在encoder模块使用了sparse attention,decoder部分仍保持原先的full-attention。
结果:重复解码严重,模型无法输出长摘要
- 经过我们对源码的调试,在24G的GPU上模型能轻松计算input为4096长度的文本。我们参考论文中的做法,直接对训练集中的论文进行截断,并将所有的摘要作为output-target。此外我们使用了PEGASUS-arXiv预训练权重,即在arXiv摘要数据集进行预训练的模型权重。我们认为论文的语言结构和专业术语与普通的新闻等摘要数据集有较大差别。使用PEGASUS-arXiv预训练权重有助于在训练样本有限的情况下(500+)让模型更快收敛。
- 我们将模型在训练集上进行充分训练后(4096-1024),在验证集上进行预测,结果模型生成的摘要仅有较短长度的可读部分,之后要么重复解码严重,要么过早截停。我们理解在原本的预训练任务上的输出文本较短且对于本任务的长摘要生成来说,让模型直接生成一篇有结构的博客摘要是比较困难的。
UniLM 抽取+生成 [2048-1024]
- 我们以DGCNN作为抽取模型对生成数据集的文章进行关键句提取,再利用Unilm进行摘要生成,结果更离谱,重复解码非常严重,而且抽取模型的抽取的数据无法完全覆盖生成数据所需要的信息。
SBAS (session based automatic summarization model)
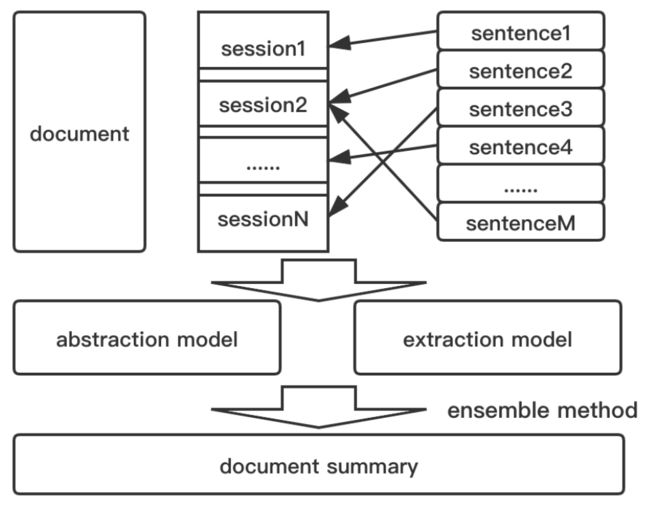
Session based 生成模型
- 数据理解:通过对生成数据的摘要进行分析,我们发现论文博客其实可以归结为结构化的摘要,与普通的总结性摘要不同,博客大多数关注于对文章的每一个重要子结构进行总结和分析,因为我们提出了Session based的摘要处理方法。
- 我们按固定大小的session窗口对文章进行切分,得到多组独立样本。具体方法为,现将文章按section切分后,合并同首序号的section如(4.1,4.2,4.3)至字数不超过1024的session。
- 将ground truth摘要进行分句,分句后与文章的句子进行相似度匹配(也可以尝试和session计算最长公共子序列),按rough召回率找到最相近的文中句子,将该摘要句作为该session的target摘要。至此原本500+个样本被我们拆分成了8000+个训练样本。
- Session based的方法不仅符合段落独立性假设的同时还增加了样本数量,减小模型的训练压力。
- 尝试将抽取数据的ground-truth在对应session中去除作为该段落的target加入到生成数据中去,以此增加训练样本,但是没有得到提升。
- 我们将这8000个训练样本在PEGASUS-arXiv预训练预训练模型上进行fine-tune(1024-128)20轮,学习率为2e-5,batch_size为8。
抽取模型
- 抽取模型我们在之前训练的DGCNN模型的基础上按一定长度上限根据预测得分对全文的关键句进行召回。最终实验表明在测试集上以900字为长度上限效果最佳。
Ensemble Method
- 尽管此时我们的生成模型和抽取模型在测试集上已经获得了较高的成绩(单抽取模型结果甚至一度达到第二名的水平),但我们仍在思考如何能将这两个模型进行融合。这也是SBAS最大的创新点之一,不同于分类任务:可以将不同模型最后的预测结果进行加权平均后得到最终预测结果。生成任务的解码本身就存在随机性,且生成模型和抽取模型的摘要模式完全不同,无法在模型层面进行直接融合。
- 而我们相信融合能得到提升的原因是:1. 生成模型和抽取模型各有优缺点。生成模型的优点是可以产生与原文不同的表达方式,可以对原文进行总结,而且生成的摘要比抽取出来的摘要更流畅。然而,这种模型的缺点是生成的内容不能被控制,不能保证模型能够预测出原文所有关键点。而抽取模型可以直接从原句子的得分中提取出大部分重要信息。2. 观察生成模型的预测结果,大部分结果仍然较短,其在测试集上的召回率较低。
- 我们按session为单位将生成模型的预测结果与抽取模型的抽取结果进行拼接 (sess1: abs11, …, abs1n1, ext11, …, ext1m1; sess2: abs21, …, abs2n2, ext21, …, ext2m2 ; …; sessm.) 对拼接结果分句后按rough的召回率建立句子相似度矩阵,如果si对s(i+1),s(i+2)…的rough召回率大于某一阈值时,我们认为si的句意覆盖了后者,并删去后者。
- 通过这样的方法我们对合并后的摘要进行句子去重,删去了生成和抽取的冗余、句意重复的句子的同时,最大程度保留了1-gram和2-gram的多样性。并且session拼接方法符合一般研究人员根据文章不同部分进行总结摘要的逻辑(总结这个part然后罗列这个part中的关键点)。
- 这个方法使得我们最终在测试集上各项指标都提升了0.02,成功超越了原来的第一名。
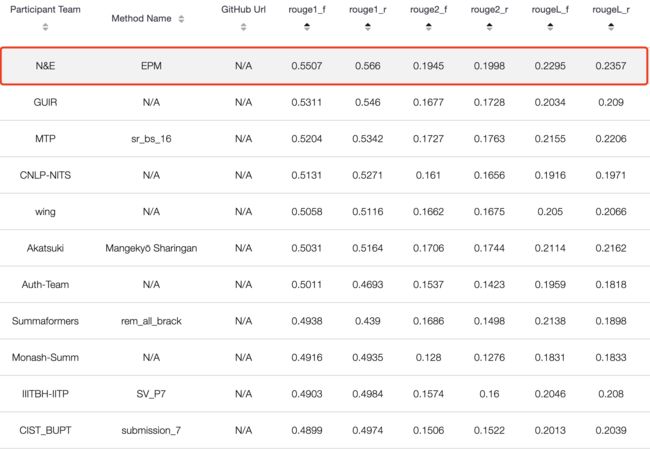
测试结果
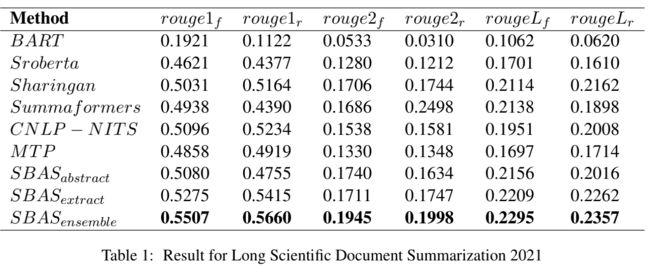
其中SBAS为这次我们设计的模型结构,其余为部分其他参赛者的结果
部分摘要样例
"1005": "to make the architecture task adaptive , the paper proposes the concept of met-adapt controller modules these modules are added to the model and are meta-trained to predict the optimal network connections for a given novel task a few-shot classification (fsc) is a popular method for approaching fsc . in meta-learning , the inputs to both train and test phases are not images but instead a set of few-shot tasks ti each k-shot / n-way task containing a small amount of k (usually) of labeled support images and some amount of unlabeled query images for each of the n categories of the task the goal of meta-learning is to find a base model that is easily adapted to the specific task at hand so that it will generalize well to tasks built from novel unseen categories and fulfill the goal of fsc it seems that larger architectures increase fsc performance up to a certain size where performance seems to saturate or even degrade this happens since bigger backbones carry higher risk of over-fitting it seems the overall performance of the fsc techniques cannot continue to grow by simply expanding the backbone size in light of the above set to explore methods for architecture search their meta-adaptation and optimization for fsc a few-shot learning problem is one where you train a model on a small number of examples , and you try to classify the new examples according to their proximity to the ones that have already been trained on the previous task . sub-models metadapt controllers predict the change in connectivity that is needed in the learned graph as a function of the current task replacing simple sequence of convolutional layers with the suggested dag , with its many layers and parameters in conventional gradient descent training will result in a larger over-fitting . this is even worse for fsl where it is harder to achieve generalization due to scarcity of the data and the domain differences between the training and test sets the weights are optimized using sgd optimizer with learning rate 0 . tldr; the authors propose met modifiers , a few-shot learning approach that enables meta-learned network architecture that is adaptive to novel few-shot tasks . the goal of meta-learning is to find a base model that is easily adapted to the specific task at hand, so that it will generalize well to tasks built from novel unseen categories and fulfill the goal of fsc (see section for further review). one of such major factors is the cnn backbone architecture at the basis of all the modern fsc methods. to summarize, our contributions in this work are as follows: (1) show that darts-like bi-level iterative optimization of layer weights and network connections performs well for few-shot classification without suffering from overfitting due to over-parameterization; (2) show that adding small neural networks, metadapt controllers, that adapt the connections in the main network according to the given task further (and significantly) improves performance; (3) using the proposed method, obtain improvements over fsc state-of-the-art on two popular fsc benchmarks: miniimagenet and fc100 these approaches include: (i) semi-supervised approaches using additional unlabeled data 9,14; (ii) fine tuning from pre-trained models 31,62,63; (iii) applying domain transfer by borrowing examples from relevant categories or using semantic vocabularies 3,15; (iv) rendering synthetic examples 42,10,56; (v) augmenting the training examples using geometric and photometric transformations or learning adaptive augmentation strategies 21; (vi) example synthesis using generative adversarial networks (gans) 69,25,20,48,45,35,11,23,2. in 22,54 additional examples are synthesized via extracting, encoding, and transferring to the novel category instances, of the intra-class relations between pairs of instances of reference categories. the list of search space operations used in our experiments is provided in table this list includes the zero-operation and identity-operation that can fully or partially (depending on the corresponding (i,j) o ) cut the connection or make it a residual one (skip-connection). darts, at search time the training is done on the full model at each iteration where each edge is a weighted-sum of its operations according to i,j contrarily, in snas i,j are treated as probabilities of a multinomial distribution and at each iteration a single operation is sampled accordingly. (9) here i,j are after softmax normalization and summed to at test time, rather than the one-hot approximation, use the operation with the top probability zi,jk 1, if k argmax(i,j) 0, otherwise (10) using this method get better results for fc100 1-shot and comparable results for 5-shot, compared to vanilla metaoptnet. the proposed approach effectively applies tools from the neural architecture search (nas) literature, extended with the concept of metadapt controllers’, in order to learn adaptive architectures. these tools help mitigate over-fitting to the extremely small data of the few-shot tasks and domain shift between the training set and the test set. demonstrate that the proposed approach successfully improves state-of-the-art results on two popular few-shot benchmarks, miniimagenet and fc100, and carefully ablate the different optimization steps and design choices of the proposed approach. some interesting future work directions include extending the proposed approach to progressively searching the full network architecture (instead of just the last block), applying the approach to other few-shot tasks such as detection and segmentation, and researching into different variants of task-adaptivity including global connections modifiers and inter block adaptive wiring.",
"1002": "in this paper , propose a novel method that automatically generates summaries for scientific papers by utilizing videos of talks at scientific conferences . hypothesize that such talks constitute a coherent and concise description of the papers content and can form the basis for good summaries collected papers and their corresponding videos and created a dataset of paper summaries a model trained on this dataset achieves similar performance as models trained on a dataset of summaries created manually in addition validated the quality of our summaries by human experts the rate of publications of scientific papers is increasing and it is almost impossible for researchers to keep up with relevant research . the paper proposes talksumm (acronym for talk-based summarization) , a method to automatically generate extractive content-based summaries for scientific papers based on video talks the approach utilizes the transcripts of video conference talks and treat them as spoken summaries of pa-s then for summaries using unsupervised alignment rithms map the transcripts to the corresponding text and create extractive summaries alignment between text and videos was studied by bojanowski et al . downloaded the 4www cleo org igem org/videos/videos extracted the speech data then via a publicly available asr service extracted transcripts of the speech and based on the video metadata (e g title) retrieved the corresponding paper (in pdf format) used science parse7 to extract the text of the paper and applied a simple processing in order to filter out some noise (e starting with the word copyright) at the end of this process the text of each paper is associated with the corresponding transcript of the corresponding talk during the talk , the speaker generates words for describing ver-vite sentences from the paper one word at each time step . thus at each time step the speaker has a single sentence from the paper in mind and produces a word that constitutes a part of its ver-vite description then at the next time-step the speaker either stays with the same sentence or moves on to describing another sentence and so on given the transcript aim to retrieve those source sentences and use them as the summary the number of words uttered to describe each sentence can serve as importance score in dicating the amount of time the speaker spent describing the sentence this enables to control the summary length by considering the only the most important sentences up to some threshold use an hmm to model the assumed stay-tive process each hidden state of the hmm corresponds to a single sentence each hidden state of the hmm is conditioned over the sentences appearing in the start of the paper and the average value of the hmm over all papers is 0 5 where s is the average value of the sentences appearing in the start of the paper the model is evaluated on clsm , scisumm talksum and evalnet . automatic summarization is studied exhaustively for the news domain (cheng and lapata, 2016; see et al., 2017), while summarization of scientific papers is less studied, mainly due to the lack of large-scale training data. in such talks, the presenter (usually a co-author) must describe their paper coherently and concisely (since there is a time limit), providing a good basis for generating summaries. table gives an example of an alignment between 1vimeo.com/aclweb icml.cc/conferences/2017/videos a paper and its talk transcript (see table in the appendix for a complete example). summaries generated with our approach can then be used to train more complex and data- demanding summarization models. our main contributions are as follows: (1) propose a new approach to automatically generate summaries for scientific papers based on video talks; (2) create a new dataset, that contains summaries for papers from several computer science conferences, that can be used as training data; (3) show both automatic and human evaluations for our approach. the transcript itself cannot serve as a good summary for the corresponding paper, as it constitutes only one modality of the talk (which also consists of slides, for example), and hence cannot stand by itself and form a coherent written text. thus, to create an extractive paper summary based on the transcript, model the alignment between spoken words and sentences in the paper, assuming the following generative process: during the talk, the speaker generates words for describing verbally sentences from the paper, one word at each time step. training data using the hmm importance scores, create four training sets, two with fixed-length summaries (150 and words), and two with fixed ratio between summary and paper lengths (0.3 and 0.4). automatic evaluation table summarizes the results: both gcn cited text spans and talksumm-only models, are not able to obtain better performance than abstract8 however, for the hybrid approach, where the abstract is augmented with sentences from the summaries emitted by the models, our talksumm-hybrid outperforms both gcn hybrid and abstract. randomly selected presenters from our corpus and asked them to perform two tasks, given the generated summary of their paper: (1) for each sentence in the summary, asked them to indicate whether they considered it when preparing the talk (yes/no question); (2) asked them to globally evaluate the quality of the summary (1-5 scale, ranging from very bad to excellent, means good).",
部分参考文献
Yang Liu. 2019. Fine-tune bert for extractive summarization. arXiv preprint arXiv:1903.10318.
Jingqing Zhang, Yao Zhao, Mohammad Saleh, and Peter Liu. 2020. Pegasus: Pre-training with extracted gap-sentences for abstractive summarization. In International Conference on Machine Learning, pages 11328–11339. PMLR.
Manzil Zaheer, Guru Guruganesh, Avinava Dubey, Joshua Ainslie, Chris Alberti, Santiago Ontanon, Philip Pham, Anirudh Ravula, Qifan Wang, Li Yang, et al. 2020. Big bird: Transformers for longer sequences. arXiv preprint arXiv:2007.14062.
苏剑林. (Jan. 01, 2021). 《SPACES:“抽取-生成”式长文本摘要(法研杯总结) 》[Blog post]. Retrieved from https://kexue.fm/archives/8046