MATLAB环境下基于支持向量机、孤立森林和LSTM自编码器的三轴振动数据的机械异常检测
本文讲解如何使用机器学习和深度学习来检测机械振动数据中的异常,属于异常检测领域,这玩意在工业中用的更多,因为工业中毕竟还是正常样本远多于故障样本(异常样本)。
运行环境为MATLAB R2021B.
第三方面包多官网下载如下
正在为您运送作品详情
数据集

数据集包含来自工业机械臂的三轴振动测量值, 在计划维护之前和维护之后采集数据。 假定在定期维护后采集的数据代表机器的正常运行状况,维护前的数据代表正常或异常情况。 每轴的数据存储在单独的列中,每个文件包含 7000 个测量值。
trainData = 40×4 table
| ch1 | ch2 | ch3 | label | |
|---|---|---|---|---|
| 1 | 70000×1 double | 70000×1 double | 70000×1 double | Before |
| 2 | 70000×1 double | 70000×1 double | 70000×1 double | Before |
| 3 | 70000×1 double | 70000×1 double | 70000×1 double | Before |
| 4 | 70000×1 double | 70000×1 double | 70000×1 double | Before |
| 5 | 70000×1 double | 70000×1 double | 70000×1 double | Before |
| 6 | 70000×1 double | 70000×1 double | 70000×1 double | Before |
| 7 | 70000×1 double | 70000×1 double | 70000×1 double | Before |
| 8 | 70000×1 double | 70000×1 double | 70000×1 double | Before |
| 9 | 70000×1 double | 70000×1 double | 70000×1 double | Before |
| 10 | 70000×1 double | 70000×1 double | 70000×1 double | Before |
| 11 | 70000×1 double | 70000×1 double | 70000×1 double | Before |
| 12 | 70000×1 double | 70000×1 double | 70000×1 double | Before |
| 13 | 70000×1 double | 70000×1 double | 70000×1 double | Before |
| 14 | 70000×1 double | 70000×1 double | 70000×1 double | Before |
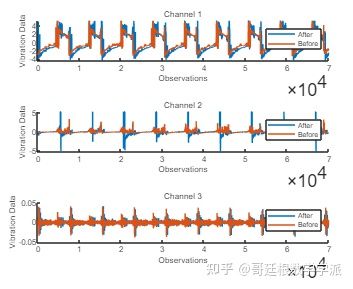
为了更好地理解数据,在维护前后对其进行部分可视化
特征提取
每通道提取的特征如下,就是些峭度,均值,RMS值,标准差,波峰因子之类的特征,在信号中都很常用
ch1 : Crest Factor, Kurtosis, RMS, Std
ch2 : Mean, RMS, Skewness, Std
ch3 : Crest Factor, SINAD, SNR, THD
从部分数据集中的每个通道中提取前 4 个相关特征,结果如下
head(trainFeatures)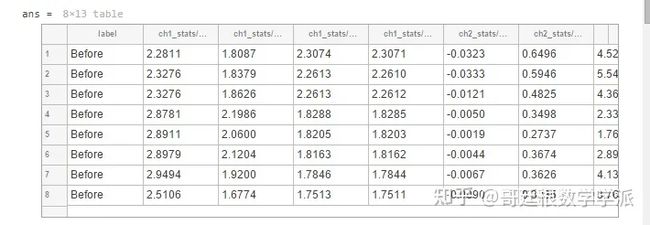
训练异常检测模型
到目前为止使用的数据集是一小部分,用于说明特征提取和选择的过程。 在所有可用数据上训练算法会产生较佳的性能, 因此,加载之前从 17,642 个信号的较大数据集中提取的 12 个特征。
head(featureAll)使用,MATLAB的cvpartition函数将数据划分为训练集和测试集
rng(0)
idx = cvpartition(featureAll.label, 'holdout', 0.1);
featureTrain = featureAll(idx.training, :);
featureTest = featureAll(idx.test, :);对于每个模型,仅对正常的维护后数据进行训练, 从 featureTrain 中提取维护后的数据
trueAnomaliesTest = featureTest.label;
featureNormal = featureTrain(featureTrain.label=='After', :);使用One-Class SVM进行异常检测
关于One-Class SVM,参考如下文章
One-Class SVM介绍 - 习翔宇的文章 - 知乎 One-Class SVM介绍 - 知乎
SVM是一种比较强大的分类器,SVM有一个变体只训练一个类别,即对正常数据进行建模。 该模型将异常识别为与正常数据“相距甚远”。 选择正常工况下的训练数据并使用 fitcsvm 函数训练 SVM 模型。
mdlSVM = fitcsvm(featureNormal, 'label', 'Standardize', true, 'OutlierFraction', 0);使用包含正常和异常数据的测试数据来验证经过训练的 SVM 模型。
featureTestNoLabels = featureTest(:, 2:end);
[~,scoreSVM] = predict(mdlSVM,featureTestNoLabels);
isanomalySVM = scoreSVM<0;
predSVM = categorical(isanomalySVM, [1, 0], ["Anomaly", "Normal"]);
trueAnomaliesTest = renamecats(trueAnomaliesTest,["After","Before"], ["Normal","Anomaly"]);
figure;
confusionchart(trueAnomaliesTest, predSVM, Title="Anomaly Detection with One-class SVM", Normalization="row-normalized");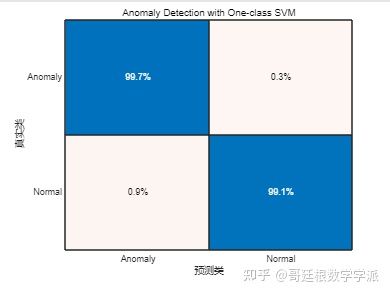
从混淆矩阵中可以看出,One-Class SVM有 0.3% 的异常样本被错误分类为正常,大约 0.9% 的正常数据被错误分类为异常。
使用孤立森林算法检测异常
有关孤立森林的相关知识,可见如下文章
iForest (Isolation Forest)孤立森林 异常检测 入门篇 - 简书 (jianshu.com)
孤立森林的决策树将每个观察值隔离在一片叶子中。 一个样本经过多少次决策才能到达它的叶子节点是衡量将其与其他样本隔离开来的复杂程度。 再次,仅在正常数据上训练孤立森林模型。
[mdlIF,~,scoreTrainIF] = iforest(featureNormal{:,2:13},'ContaminationFraction',0.09);使用包含正常和异常数据的测试数据来验证经过训练的孤立森林模型,使用混淆矩阵可视化该模型的性能。

孤立森林的表现不如One-Class SVM, 原因可能是训练数据只包含正常数据,而测试数据包含大约 30% 的异常数据。 这表明当异常和正常数据的分布更接近时,孤立森林模型更适合。
使用 LSTM 自编码器网络检测异常
LSTM 自编码器是一个变体,可以学习序列数据的压缩表示。 LSTM 自编码器将仅使用正常数据进行训练。
构建 BiLSTM 自编码器网络并设置训练选项
featureDimension = 1;定义 biLSTM 网络层
layers = [ sequenceInputLayer(featureDimension, 'Name', 'in')
bilstmLayer(16, 'Name', 'bilstm1')
reluLayer('Name', 'relu1')
bilstmLayer(32, 'Name', 'bilstm2')
reluLayer('Name', 'relu2')
bilstmLayer(16, 'Name', 'bilstm3')
reluLayer('Name', 'relu3')
fullyConnectedLayer(featureDimension, 'Name', 'fc')
regressionLayer('Name', 'out') ];设置训练参数
options = trainingOptions('adam', ...
'Plots', 'training-progress', ...
'MiniBatchSize', 500,...
'MaxEpochs',200);MaxEpochs 训练选项参数设置为 200。为了获得更高的验证准确度,可以将此参数设置为更大的数字。 但是,这可能会导致网络过拟合,开始训练模型。
net = trainNetwork(featuresAfter, featuresAfter, layers, options);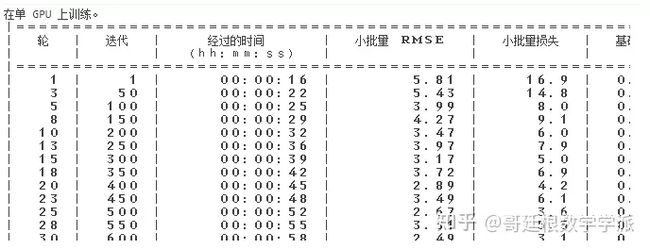
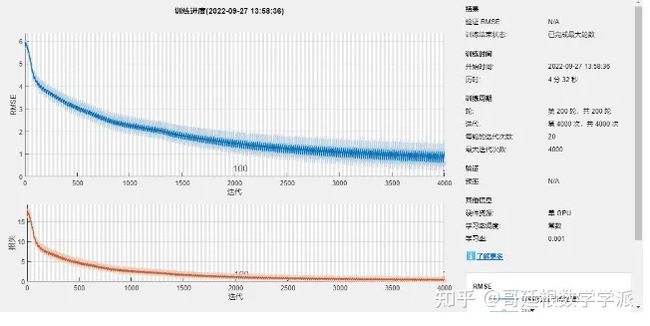
可视化验证数据上的模型的性能
从异常和正常条件中提取并可视化每个样本。 下图比较了 12 个特征中每个特征的值的误差(在 x 轴上表示)。 在这个样本中,特征 10、11 和 12 不能很好地重构异常输入,因此具有很高的误差值。
testNormal = {featureTest(1200, 2:end).Variables};
testAnomaly = {featureTest(200, 2:end).Variables};
decodedNormal = predict(net,testNormal);
decodedAnomaly = predict(net,testAnomaly);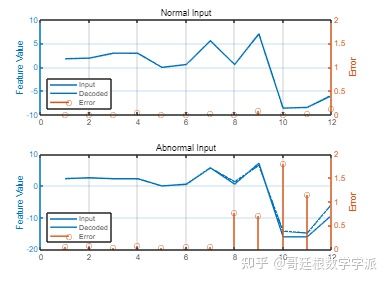
提取正常和异常数据的特征。 从图中可以看出,异常数据的重构误差明显高于正常数据,因为自动编码器是在正常数据上训练的,所以它可以更好地重建相似的信号。
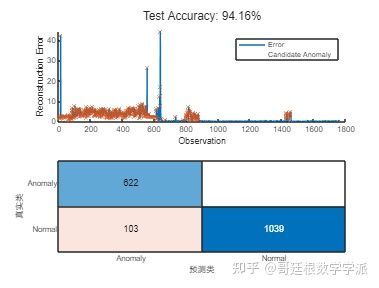
维护前预测输出并计算误差,预测维护后的输出并计算误差,如下图所示

识别异常
将异常定义为重建误差比所有观测值的平均值大 0.5 倍的点。 该阈值是通过实验确定的,可以根据需要进行更改。