第二个机器学习算法:基于SVM的猫咪图片识别器
一、知识点补充:
from glob import *

![]()
import cv2
OpenCV中文教程:http://www.opencv.org.cn/opencvdoc/2.3.2/html/doc/tutorials/tutorials.html
OpenCV官网:https://opencv.org/
Python OpenCV官网教程:https://docs.opencv.org/3.0-beta/doc/py_tutorials/py_tutorials.html
摘自:https://blog.csdn.net/qq_31136635/article/details/58587219
官方文档:http://opencv-python-tutroals.readthedocs.io/en/latest/py_tutorials/py_tutorials.html
https://docs.opencv.org/3.0-beta/modules/highgui/doc/user_interface.html#waitkey
cv2.imread():
这个函数用来读取一副图像,第一个参数(必须传)可以是图片的相对路径或者绝对路径(如果你第一个参数传错,程序不会报错,但是函数的返回值会是None),第二个参数(可选)指定你要以何种方式读取图片,第二参数是个枚举值它可以是:
- cv2.IMREAD_COLOR:加载一张彩色图片,忽略它的透明度,在不传第二个参数时,它也是默认值。
- cv2.IMREAD_GRAYSCALE:加载灰度图。
- cv2.IMREAD_UNCHANGED:加载一张图片包含它的alpha通道(透明度),就是原图像不做改变的加载。
提示:如果你觉得上面三个枚举值很难记你可以简单的用1,0,-1代替。
具体请看下面的代码
import numpy as np
import cv2
#加载一张彩色图片不包含alpha通道
img = cv2.imread('demo.jpg',1)cv2.imshow():
这个函数用来在一个窗口中显示一幅图片,窗口自动适配图片的大小。
这个函数也接收两个参数,第一个参数是要承载图片的窗口名(字符串类型),第二个参数就是我们要显示的图片。只要每个窗口的名字不重复,我们可以创建多个窗口。
请看下面的代码片段
cv2.imshow('image',img)
cv2.waitKey(0)
cv2.destroyAllWindows()cv2.waitKey() :
是一个键盘绑定函数。它的参数是一个毫秒数。这个函数等待特定的毫秒,如果在这个时间之内有按键按下,它就会返回相应按键的 ASCII 码(int 类型),然后程序继续运行,如果在给定的时间内没有任何按键按下它会返回 255(int 类型),然后程序继续运行。特别的,如果你传递一个0(或者一个负数)给这个函数,那么它会一直等待,直到有任何按键按下,然后程序继续运行。我们也可以只监视某些按键的按下而不是任意按键,这个我们在后面讨论。但是有一点必须注意,cv2.imshow()函数后面必须有cv2.waitKey()函数,否则图片不会显示。
cv2.destroyAllWindows():
将我们创建的所有窗口全部销毁。如果你想销毁任何特定的窗口,请使用 cv2.destroyWindow() 函数并将特定窗口的名字作为参数传递进去。
提示:有时候你可以事先创建好一个窗口后面再载入图片。在这种情况下你可以指定窗口是否可以调整大小,这要用到函数 cv2.namedWindow() 函数。默认状态下标志位是 cv2.WINDOW_AUTOSIZE 。但是你可以指定标志位为 cv2.WINDOW_NORMAL ,这样你就可以调整窗口的大小了。下表显示都有哪些标志位可供我们选择。
| 枚举值 | 表示的意思 |
|---|---|
| WINDOW_NORMAL | 用户可以调整窗口的大小,也可以将一个窗口从全屏窗口切换到普通窗口 |
| WINDOW_AUTOSIZE | 用户不能改变窗口的大小,窗口的大小被所展示的图片所约束 |
| WINDOW_OPENGL | opengl支持的窗口 |
| WINDOW_FULLSCREEN | 将窗口设置为全屏 |
| WINDOW_FREERATIO | 扩展图片不考虑图片的分辨率 |
| WINDOW_KEEPRATIO | 扩展图片但考虑图片的分辨率 |
| WINDOW_GUI_EXPANDED | 带进度条和工具条 |
| WINDOW_GUI_NORMAL | 旧方法 |
解释:经测试之后发现,第三个枚举值需要安装OPENGL的支持,后5个枚举值在效果上与WINDOW_NORMAL没有什么区别,如果有朋友对这个特别了解,欢迎讨论。
请看下面的代码
cv2.namedWindow('window_name',cv2.WINDOW_NORMAL)
cv2.imshow('window_name',img)
cv2.waitKey(0)
cv2.destroyAllWindows()cv2.imwrite()
这个函数用来保存一张图片。
第一个参数是保存之后文件的文件名(可以包含文件路径),第二个参数是你想要保存的图片。
cv2.imwrite('copy.png',img)这样会保存一张 PNG 格式的图片在你的工作目录(就是跟你的.py文件在一个目录下)。
cv2.imwrite('..\copy.jpg',img)这样会保存一张 JPG 格式的图片在你工作目录的上一级目录
或者你可以直接这样写
cv2.imwrite('C:\Program Files\opencv\copy.bmp',img)这样就会在指定的位置保存一张 BMP 图片
注意:你总是需要指定文件的扩展名,虽然官方文档中说不写扩展名就会保存一张 PNG 文件在指定目录,但是实际测试这么做会报 (could not find a writer for the specified extension) 这个错误,告诉你指定的扩展名没有 writer 可以写出来,经测试主流的几种图片格式 (jpg,png,bmp) 都是支持的。第二点就是在你写文件路径的时候注意斜线的方向。
现在我们把之前的代码统一起来,下面这段代码首先以彩色忽略透明度的模式加载一张图片,然后显示图片,如果你按下 ‘s’ 键它会保存图片到指定位置后程序退出,如果按下 ‘esc’ 键那么不保存直接退出,如果按了别的键它会提示你,然后程序退出。
import numpy as np
import cv2
img = cv2.imread('demo.jpg',1)
cv2.imshow('image',img)
k = cv2.waitKey(0)
if( k== 27):
cv2.destroyAllWindows()
elif( k==ord('s')):
cv2.imwrite('copy.png',img)
cv2.destroyAllWindows()
else:
print('你没有按下S或者ESC,程序退出')
cv2.destroyAllWindows()提示:官方文档中说如果你使用64位的机器,你必须将 k=cv2.waitKey(0) 改为k=cv2.waitKey(0) & 0xFF,但是经过我的测试不修改程序仍然可以正常运行。
cv2.resize():(摘自:https://blog.csdn.net/JNingWei/article/details/78218837)
cv2.resize(src, dsize[, dst[, fx[, fy[, interpolation]]]]) → dst
| interpolation 选项 | 所用的插值方法 |
|---|---|
| INTER_NEAREST | 最近邻插值 |
| INTER_LINEAR | 双线性插值(默认设置) |
| INTER_AREA | 使用像素区域关系进行重采样。 它可能是图像抽取的首选方法,因为它会产生无云纹理的结果。 但是当图像缩放时,它类似于INTER_NEAREST方法。 |
| INTER_CUBIC | 4x4像素邻域的双三次插值 |
| INTER_LANCZOS4 | 8x8像素邻域的Lanczos插值 |
具体示例:
原图像:

缩放后的图像: 
code:
附上自己写的实验代码:
import cv2
pic = cv2.imread('./Elegent_Girl.jpg')
pic = cv2.resize(pic, (400, 400), interpolation=cv2.INTER_CUBIC)
cv2.imshow('', pic)
cv2.waitKey(0)
cv2.destroyAllWindows()Note:
使用cv2.resize时,参数输入是 宽×高×通道 ,与以往操作不同,需要注意。具体参见opencv: cv2.resize 探究(源码)。
Numpy:

zip():
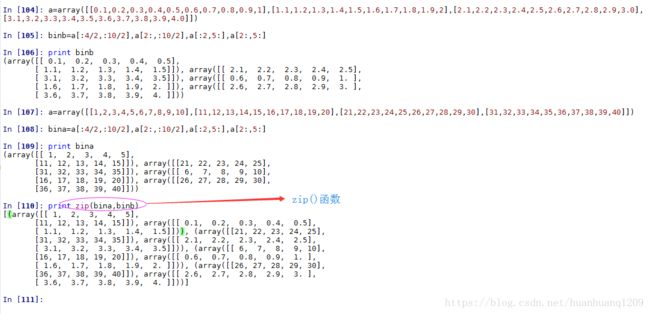
numpy.ravel() vs numpy.flatten():
参考自:https://blog.csdn.net/lanchunhui/article/details/50354978
首先声明两者所要实现的功能是一致的(将多维数组降位一维),两者的区别在于返回拷贝(copy)还是返回视图(view),numpy.flatten()返回一份拷贝,对拷贝所做的修改不会影响(reflects)原始矩阵,而numpy.ravel()返回的是视图(view,也颇有几分C/C++引用reference的意味),会影响(reflects)原始矩阵。
1. 两者的功能
>>> x = np.array([[1, 2], [3, 4]])
>>> x
array([[1, 2],
[3, 4]])
>>> x.flatten()
array([1, 2, 3, 4])
>>> x.ravel()
array([1, 2, 3, 4])
两者默认均是行序优先
>>> x.flatten('F')
array([1, 3, 2, 4])
>>> x.ravel('F')
array([1, 3, 2, 4])
>>> x.reshape(-1)
array([1, 2, 3, 4])
>>> x.T.reshape(-1)
array([1, 3, 2, 4])2. 两者的区别
>>> x = np.array([[1, 2], [3, 4]])
>>> x.flatten()[1] = 100
>>> x
array([[1, 2],
[3, 4]]) # flatten:返回的是拷贝
>>> x.ravel()[1] = 100
>>> x
array([[ 1, 100],
[ 3, 4]])References
[1] What is the difference between flatten and ravel functions in numpy?
下面是自己做的实验:
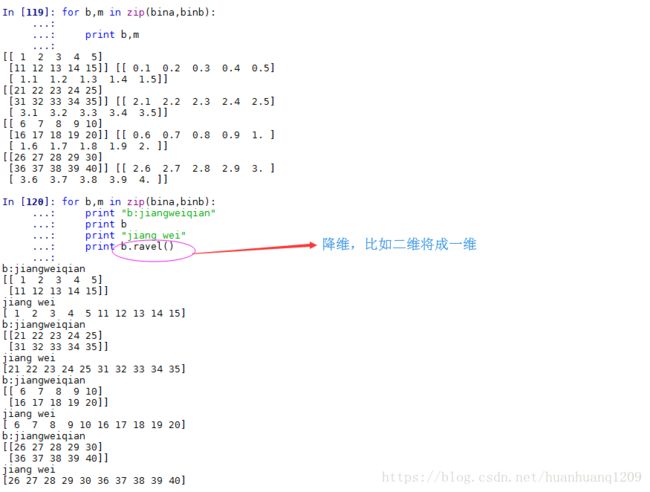
numpy.bincount详解:
摘自:https://blog.csdn.net/xlinsist/article/details/51346523
引言
对于中国的编程人员来说,其实真的挺困难的。比如说,youtube上有很多优秀的一些资源 1、我们的网不能看2、我们的英语不够好,确实听不明白老外在讲什么,这个对于不是native speaker的人说,真的是很困难的。因此,我们中国的编程人员要比一个外国的编程人员克服的困难多很多。
因此,我的建议是如果大家有时间,还是要把英语练好。学好英语以后你会得到更加优秀的资源并能很好地吸收这些资源,你会少碰到一些困难。好了,闲话不说了,既然今天碰到了这个事情,我觉得还是应该把这个api写一下吧,尽自己的努力让一些初学者少走一些弯路。
numpy.bincount详解
下面,是我Zeal上的官方文档,我截图下来,我会按照这个文档一步一步给大家解释的。
numpy.bincount详解
它大致说bin的数量比x中的最大值大1,每个bin给出了它的索引值在x中出现的次数。下面,我举个例子让大家更好的理解一下:
# 我们可以看到x中最大的数为7,因此bin的数量为8,那么它的索引值为0->7
x = np.array([0, 1, 1, 3, 2, 1, 7])
# 索引0出现了1次,索引1出现了3次......索引5出现了0次......
np.bincount(x)
#因此,输出结果为:array([1, 3, 1, 1, 0, 0, 0, 1])
# 我们可以看到x中最大的数为7,因此bin的数量为8,那么它的索引值为0->7
x = np.array([7, 6, 2, 1, 4])
# 索引0出现了0次,索引1出现了1次......索引5出现了0次......
np.bincount(x)
#输出结果为:array([0, 1, 1, 0, 1, 0, 1, 1])下面,我来解释一下weights这个参数。文档说,如果weights参数被指定,那么x会被它加权,也就是说,如果值n发现在位置i,那么out[n] += weight[i]而不是out[n] += 1.因此,我们weights的大小必须与x相同,否则报错。下面,我举个例子让大家更好的理解一下:
w = np.array([0.3, 0.5, 0.2, 0.7, 1., -0.6])
# 我们可以看到x中最大的数为4,因此bin的数量为5,那么它的索引值为0->4
x = np.array([2, 1, 3, 4, 4, 3])
# 索引0 -> 0
# 索引1 -> w[1] = 0.5
# 索引2 -> w[0] = 0.3
# 索引3 -> w[2] + w[5] = 0.2 - 0.6 = -0.4
# 索引4 -> w[3] + w[4] = 0.7 + 1 = 1.7
np.bincount(x, weights=w)
# 因此,输出结果为:array([ 0. , 0.5, 0.3, -0.4, 1.7])最后,我们来看一下minlength这个参数。文档说,如果minlength被指定,那么输出数组中bin的数量至少为它指定的数(如果必要的话,bin的数量会更大,这取决于x)。下面,我举个例子让大家更好的理解一下:
# 我们可以看到x中最大的数为3,因此bin的数量为4,那么它的索引值为0->3
x = np.array([3, 2, 1, 3, 1])
# 本来bin的数量为4,现在我们指定了参数为7,因此现在bin的数量为7,所以现在它的索引值为0->6
np.bincount(x, minlength=7)
# 因此,输出结果为:array([0, 2, 1, 2, 0, 0, 0])
# 我们可以看到x中最大的数为3,因此bin的数量为4,那么它的索引值为0->3
x = np.array([3, 2, 1, 3, 1])
# 本来bin的数量为4,现在我们指定了参数为1,那么它指定的数量小于原本的数量,因此这个参数失去了作用,索引值还是0->3
np.bincount(x, minlength=1)
# 因此,输出结果为:array([0, 2, 1, 2])
hstack()函数
函数原型:hstack(tup) ,参数tup可以是元组,列表,或者numpy数组,返回结果为numpy的数组。看下面的代码体会它的含义import numpy as np
a=[1,2,3]
b=[4,5,6]
print(np.hstack((a,b)))
输出:[1 2 3 4 5 6 ]import numpy as np
a=[[1],[2],[3]]
b=[[1],[2],[3]]
c=[[1],[2],[3]]
d=[[1],[2],[3]]
print(np.hstack((a,b,c,d)))
输出:
[[1 1 1 1]
[2 2 2 2]
[3 3 3 3]]它其实就是水平(按列顺序)把数组给堆叠起来,vstack()函数正好和它相反。

总结:
我们可以看到b.ravel()中最大的数为x,因此bin的数量为x+1,那么它的索引值为0->x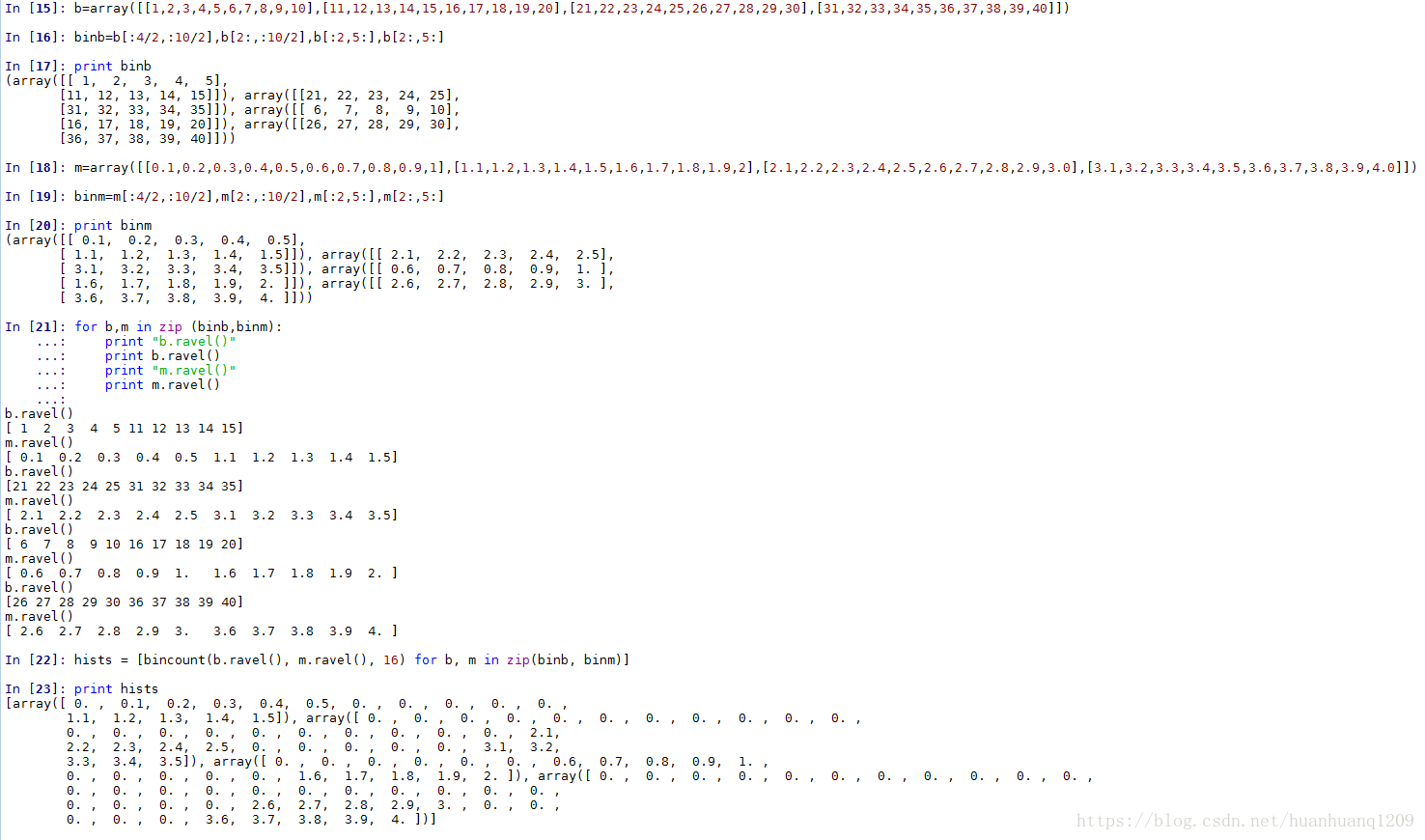
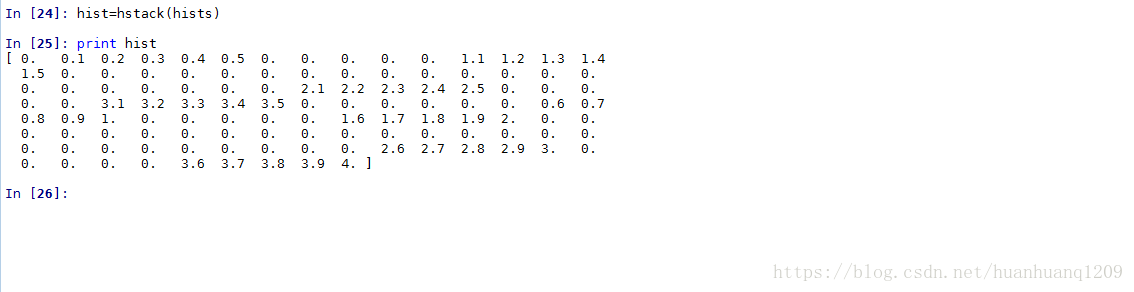
注意:bincount中minlength=16和不写 的时候的区别:如果minlength被指定,那么输出数组中bin的数量至少为它指定的数(如果必要的话,bin的数量会更大,这取决于x),它指定的数量小于原本的数量,因此这个参数失去了作用。

二、代码:
1、OpenCV对图片的处理:
使用OpenCV读取图片数据,并按照指定的大小进行缩放,将缩放后的结果写入到指定目录下的指定图片中。
# -*- coding: utf-8 -*-
'''
os.path.dirname(__file__) 获取当前文件的所在路径
os.path.dirname(os.path.dirname(__file__)) 获取当前文件的所在目录的上级路径
'''
import numpy as np
import cv2
from os.path import dirname, join, basename
from glob import glob
num=0
for fn in glob(join(dirname(__file__)+'\other', '*.jpg')):
img = cv2.imread(fn)
res=cv2.resize(img,(64,128),interpolation=cv2.INTER_AREA)
cv2.imwrite(r'E:\shiyanlou\SVM\test\my_opencv\my_opencv'+str(num)+'.jpg',res)
num=num+1
print 'all done!'
cv2.waitKey(0)
cv2.destroyAllWindows()
2、sober边缘检测算子:
摘自:https://baike.baidu.com/item/Sobel%E7%AE%97%E5%AD%90
-
2.1、Sobel算子
x和y两个方向的sobel算子模板:
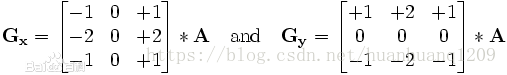
图1
核心公式
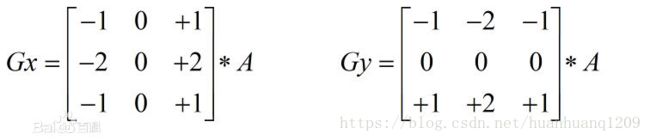
算子描述
2.2、梯度:
梯度简单来说就是求导,在图像上表现出来的就是提取图像的边缘(不管是横向的、纵向的、斜方向的等等),所需要的无非也是一个核模板,模板的不同结果也不同。所以可以看到,所有的这些个算子函数,归结到底都可以用函数cv2.filter2D()来表示,不同的方法给予不同的核模板,然后演化为不同的算子而已。并且这只是这类滤波函数的一个用途,曾经写过一个关于matlab下滤波函数imfilter()的扩展应用(等同于opencv的cv2.filter2D函数):
http://www.aiuxian.com/article/p-2667955.html
就是很多复杂的计算都是可以通过这个滤波函数组合实现,这样的话速度快。
2.2.1关于Sobel算子与Scharr算子
Sobel算子是高斯平滑与微分操作的结合体,所以其抗噪能力很强,用途较多。一般的sobel算子包括x与y两个方向,算子模板为:
在opencv函数中,还可以设置卷积核(ksize)的大小,如果ksize=-1,就演变为3*3的Scharr算子,模板无非变了个数字:
贴一个相关详细参考:
http://www.aiuxian.com/article/p-523537.html
2.3、HOG特征提取:
(摘自:http://baijiahao.baidu.com/s?id=1576070679552775&wfr=spider&for=pc)
学习链接:OpenCV-Python机器学习部分:https://www.cnblogs.com/Undo-self-blog/p/8449393.html
http://www.sohu.com/a/217441961_100085759
怎么计算方向梯度直方图呢?
我们会先用图像的一个patch来解释。
第一步:预处理
Patch可以是任意的尺寸,但是有一个固定的比例,比如当patch长宽比1:2,那patch大小可以是100*200, 128*256或者1000*2000但不可以是101*205。
这里有张图是720*475的,我们选100*200大小的patch来计算HOG特征,把这个patch从图片里面抠出来,然后再把大小调整成64*128。
第二步:计算梯度图像
首先我们计算水平和垂直方向的梯度,再来计算梯度的直方图。可以用下面的两个kernel来计算,也可以直接用OpenCV里面的kernel大小为1的Sobel算子来计算。
# Python gradient calculation(Python的梯度计算)#Read image
im = cv2.imread('bolt.png')
im = np.float32(im) / 255.0
# Calculate gradient
gx = cv2.Sobel(img, cv2.CV_32F, 1, 0, ksize=1)
gy = cv2.Sobel(img, cv2.CV_32F, 0, 1, ksize=1)接着,用下面的公式来计算梯度的幅值g和方向theta:
gradient_direction_formula(梯度方向公式:)
可以用OpenCV的cartToPolar函数来计算:
# Python Calculate gradient magnitude and direction ( in degrees )mag, angle = cv2.cartToPolar(gx, gy, angleInDegrees=True)x轴方向的梯度主要凸显了垂直方向的线条,y轴方向的梯度凸显了水平方向的梯度,梯度幅值凸显了像素值有剧烈变化的地方。(注意:图像的原点是图片的左上角,x轴是水平的,y轴是垂直的)
图像的梯度去掉了很多不必要的信息(比如不变的背景色),加重了轮廓。换句话说,你可以从梯度的图像中轻而易举的发现有个人。
在每个像素点,都有一个幅值(magnitude)和方向,对于有颜色的图片,会在三个channel上都计算梯度。那么相应的幅值就是三个channel上最大的幅值,角度(方向)是最大幅值所对应的角。
第三步:在8*8的网格中计算梯度直方图
第四步: 16*16块归一化
第五步:计算HOG特征向量
三、遇到pip 或者conda 安装库不成功时:
此时应去网站上下载库了,https://www.lfd.uci.edu/~gohlke/pythonlibs/#opencv
下载下来后安装:
pip install D:\Downloads\opencv_python-3.1.0-cp35-cp35m-win_amd64.whl
四、别人的一些建议:
想简单一点的同学可以使用封装程度更高的skimage和sklearn,根据文档的代码我把代码改写成了下面这样。
有几点要说明的是:
1.数据集实在太小了2.没有教如何调参
3.示例代码不够规范
4.我只是给出一种简单的实现而已,SVM的参数是需要tunning的,根据作者给出的参数看上去分类效果还行,而事实是你不知道这个参数是怎么来的。
#-- coding:utf-8 --
import os
import cv2
import numpy as np
from skimage.feature import hog
from sklearn.svm import SVC
img = []
num = 0
# positive
for pic in os.listdir(os.getcwd() + '\cat\cat'):
pic = cv2.imread(os.getcwd() + '\cat\cat\'+ pic, 0)
img.append(pic)
num = num + 1
positive = num
print "positive: {}".format(positive)
# nagetive
for pic in os.listdir(os.getcwd() + '\other\other_194_259'):
pic = cv2.imread(os.getcwd() + '\other\other_194_259\'+ pic, 0)
img.append(pic)
num = num + 1
negative = num - positive
print "negative: {}".format(negative)
# predict
predict_img = []
for pic in os.listdir(os.getcwd() + '\predict\predict'):
pic = cv2.imread(os.getcwd() + '\predict\predict\'+ pic, 0)
predict_img.append(pic)
def HOG(img):
feature = hog(img, orientations=8, pixels_per_cell=(16,16), cells_per_block=(1,1))
return feature
HOG_feature = map(HOG, img)
predict_feature = map(HOG, predict_img)
predict_vector = np.asarray(predict_feature)
vector = np.asarray(HOG_feature)
label = np.array(np.repeat(1, vector.shape[0]))
label[positive:] = 0
clf = SVC(kernel='linear', C=2.67, gamma=5.383)
clf.fit(vector, label)
print clf.predict(predict_vector)