PDF的信息表达原理及特点分析
一、PDF概述
PDF(Portable Document Format)是一种结构化的文档格式。它由美国著名排版与图像处理软件Adobe公司于1993年首次发布(1.0版),并于同年推出了其相应的支持软件产品系列AdobeAcrobat1.0版;随后Adobe公司又对它进行修订和升级,于1994年发布了1.1版,并推出了支持软件产品系列Adobe Acrobat2.0及2.1版。随后的PDF1.2版又于1996年11月27日发布,相应的支持软件产品系列Adobe Acrobat也升级到3.0版。至1997年底,国际标准化组织已经开始酝酿将PDF接纳为国际标准。
1.PDF与PS的比较
PS语言(PostScript语言,即页面描述语言),也是由Adobe公司拥有的一项事实上的印刷工业标准,它能描述精美的版面,在目前的印刷领域中占据着统治地位。PDF是从PS发展而来,在对页面的描述方面它们有着几乎相同的能力和相似的描述方法。PDF采用了与PS相同的着色模型(Imaging Model)来表现文字和图形,与PS语言一样,PDF的页面描述指令也是通过将选定的区域着色来绘制页面的。着色的区域可以是字母等的轮廓、直线和曲线定义的区域以及位图,着色的颜色可以是任意的,页面上的任何图形都可以被裁剪成其他形状。页面开始时是全空的,各种指令将不同的图形绘制到页面上,并且新的图形是不透明的,它可以覆盖旧的图形。
虽然如此,PDF与PS相比,还是有很大的不同。这主要表现在以下几个方面:①PDF文件中可以包含交互对象,如超链接、交互表单等,而PS则没有。②PDF是一种文件结构,而PS则是一种编程语言,因此,PDF具有比PS更高的处理效率。③PDF的严格结构定义允许应用程度对其中的某个对象进行随机存取,而PS则只能对整体进行顺序存取。例如要访问一个PS文件中的第100页,那么就必须在先顺序解释了其前99页之后,才能找到第100页,而在PDF中对每一页的存取则都是一样快的。④PDF中还包含有字库的规格尺寸等字库描述信息,以便在字库不存在之时,可以进行字库仿真(并非简单的字库替代),保证文档显示的一致性。
2.PDF的特点
PDF的特点可以归纳如下:①可传递性。PDF文件支持7位ASCⅡ码和二进制码这两种编码方式,可以正确地在各种网络环境下进行传输。②支持交互操作。PDF包含了交互表单和超链接等交互对象。③支持声音、动画。④支持对页面内容的随机存取,提高了页面的各种操作速度。⑤支持不断追加的修改方式,以便于少量修改和提高效率。⑥支持多种压缩编码方式,文件结构更加紧凑。⑦字体无关性。PDF文件中可以自带字库描述信息,以便于在用户系统缺乏所需字体的情况下,仍然能够保证文档的正确显示。⑧平台无关性。PDF文件具有软、硬件的平台独立性。这个特点非常适合于网络传递中的信息交换,以免除乱码的苦恼。⑨安全性控制。PDF文件支持各种不同级别的安全性控制,这种安全性控制对于保护电子出版物的版权是非常重要的,我们可根据各种不同电子出版物的安全性要求来进行不同级别的安全设置。
二、PDF原理结构
1.PDF文件结构
PDF的文件结构(即物理结构)包括四个部分:文件头、文件体、交叉引用表和文件尾,可参见图一。
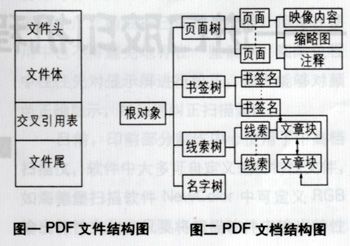
文件头指明了该文件所遵从的PDF规范的版本号,它出现在PDF文件的第一行。
文件体由一系列的PDF间接对象(IndirectObject)组成。
交叉引用表则是为了能对间接对象进行随机存取而设立的一个间接对象的地址索引表。
文件尾声明了交叉引用表的地址,即指明了文件体的根对象(Catalog),还保存了加密等安全信息。
2.PDF文档结构
PDF的文档结构即是PDF文件内容的逻辑组织结构,它反映了文件体中各间接对象间的等级层次关系。PDF的文档结构是一种树型结构,如图二所示。树的根节点也就是PDF文件的根对象,根节点下面有四个子树:页面树(Pages Tree)、书签树(Outline Tree)、线索树(ArticleThreads)和名字树(NamedDestination)。
其中,在页面树中,所有页面对象都是该树的叶子节点,它们将继承父节点的各属性值来作为其相应属性的缺省值。书签树则是按照树型层次的等级关系来将书签(Book Mark)组织起来的,书签建立了某个书签名与一个具体页面的位置关联,它使得用户可以按照书签名来访问文档的内容。线索树则将文章线索以及线索下的各文章块(Article Bead),按照树型的结构组织起来进行管理。至于名字树,它则是建立了一种字符串(即名字)和页面区域的对应关系,树中的各叶子节点保存着字符串及其相应的页面区域,而非叶子节点则只是一种索引,以便让应用程序能够对叶子节点进行快速存取。名字树的作用就是让PDF文件中的其它对象也能够用字符串名字来代表其某一个页面区域。
3.PDF中的资源
PDF中的页面内容(如文字、图形、图像等)都保存在页对象的Contents关键字所对应的流对象(以下简称内容流)中。内容流中用到了很多基本对象(如数字、字符串等),这些都是利用直接对象来表示的。但还有其它一些对象(如字体等),它们本身就是用字典对象(Dictionary)或流对象(Stream)来表示的,无法用直接对象来表示,而内容流中又不能出现有任何的间接对象(否则就无法与内容本身的数据区分),于是就将这些对象另外命名,并在内容流中用相应的名字来表示它们。这些用名字来表示的对象就称作命名资源(Named Resources)。
在页面对象中有一个资源项(Resources Key),该项列出了内容流中用到的所有资源,并且建立了一个资源名字与资源对象之间的映射表。PDF中的命名资源有:指令集(Proc Set)、字体(Font)、色彩空间(Color Space)、外部对象〔X Object(包括Image、Form和PS Segment)等〕、扩展的图形状态(Extended Graphics State)、底纹(Pattern)和用户扩展标记列表(Property List)等。
非命名资源有:Enc oding、Font De s c-riptor、Halftone、Function和C Map等。由于非命名资源都是被隐含使用的,因此就没有命名的需要。
4.PDF页面描述指令
PDF中共有60个页面描述指令,这60个页面描述指令描述了页面上的一系列的图形对象。这些图形对象大致可以分为四类,即路径对象(Path Object)、文本对象(Text Object)、图像对象(Image Object)和外部对象。它们是构成所有页面的基本元素。
三、PDF文件生成
目前PDF文件的生成有两种途径:
1. 通过打印的方式生成PDF。也就是说通过一个虚拟的PDF打印机将应用程序的文字和图形等指令(如Windows下的GDI指令、MAC下的Quick-Draw指令等)转换为PDF指令,并将其保存在相应的PDF文件中,如图三所示。在安装了AdobeAcrobat PDFWriter之后,从理论上来说,所有的只要具有打印功能的应用程序,都应该能够将待打印的内容贮存到PDF文件中。但是,目前生成中文的PDF文件尚有很多问题。
2.由PS转换到PDF。这是另一种生成PDF的方法,它是由应用程序先将待打印的内容发排到PS文件中,然后再由Adobe AcrobatDistiller将PS文件转换成PDF文件,可参见图四。

两种生成PDF的方法各有利弊。通过打印的方式生成PDF的优点就是,它和应用程序能够紧密地结合,在用户看来它是从应用程序中直接生成PDF的,但缺点是由于GDI指令集和Quick-Draw指令集本身的局限,难以生成高精度的PDF。然而从PS转换到PDF虽然多了一道工序,但是由于PS本身具有高精度的描述能力,因此生成的PDF可以达到印刷级的质量和精度。在生成了PDF文件之后,用户就可以用AcrobatReader来进行阅读和打印,而且还可以具体地使用AcrobatExchange来给PDF文件增加如页面缩略图、超链接、书签(或目录)、注释等一系列的交互属性。在采用Adobe提供的工具来生成PDF之时,目前都存在着中文支持方面的问题,如不支持中文字库的下载、中文显示依赖操作系统等等。
四、PDF在数字流程中的应用及其前景展望
正是由于PDF具有诸多适合电子出版的特性,所以目前它在现代数字化工作流程中的应用日益增多。其中,具体应用可以分为三种情况:制作CD-ROM电子出版物、与HTML混合使用来发布信息、独立采用PDF来制作主页及发布信息。
用PDF制作CD-ROM电子出版物是目前应用最多的情况,如广为流传的《黄金书屋》光盘,以及中国大百科全书出版社出版的《中国大百科全书·光盘版》等,都是采用PDF来进行光盘出版物制作的,它们都是PDF成功应用于数字流程中的例子。
由于现在只有少量的WWW服务器支持PDF,因此单独采用PDF来制作主页及发布信息在未来的一段时间内还不太现实。但是已有大量的WWW站点开始采用HTML和PDF混合的方式来进行信息发布了,如在HTML的框架中嵌入PDF,两者就可以实现无缝结合了。对于支持PDF的WWW站点,用户从上面阅读PDF和HTML是等效的,也可以来边传边读。而从那些不支持PDF的WWW站点上阅读PDF时,则只能等PDF文件完全下载到了本地之后,用户才能进行阅读。目前,已经有大量的电子杂志开始采用PDF来在因特网上发行了。
现在,爱克发又推出了兼容JDF的第三代ApogeePDF工作流程解决方案,进一步扩展和简化了整个工作流程。它拥有更高的自动化程度、可控制性、开放性和可升级性,而且也更加易用。该套ApogeePDF解决方案可以支持基于页面的工作流程和基于整个大版的工作流程,使得工作更加灵活,也满足了不同的工作方式和生产需求,真正地把自动化带到了另一个层次。通过PDF和JDF的配合,用户可以开始将商业与生产工序结合起来了,以真正做到工作流程的整合和终端至终端的自动化。JDF是一套开放的、可扩展的、以XML为基础的工作定义格式,它为客户从接到定单到最终发货的整个工作流程,提供了一个灵活而全面的解决方案,这比以前的任何一种工作形式都要更加完整和有效。
PDF的出现对传统的数字化印刷流程产生了巨大的冲击,传统的以PS为中心的印刷将面临着PDF的挑战,未来的PDF RIP(RasterImage Processor)也将会逐步地取代PS RIP,从而真正地实现“一次制作、多次使用”的思想。(作者单位:湖北武汉大学)
- VuDroid (Based on MuPDF) Review on Open-App
- APV (based on MuPDF)
- PDF-Annotation (Based on APV, MuPDF) appears to be the only OS app with annotation abilities, and they're not confirmed to work.
- Android PDF Viewer (Based on Sun's pdf-renderer)
- eBookDroid (Based on VuDroid, MuPDF))
- DroidReader (Based on MuPDF)
- APDFViewer (Based on Poppler, xpdf)
- iPDF View (Based on APV, MuPDF)
- Perfect Viewer plugin
Pdf viewer project:
http://www.mupdf.com/
https://code.google.com/p/apv/
http://code.google.com/p/vudroid/
http://code.google.com/p/droidreader/
http://code.google.com/p/apdfviewer/
http://www.jansenfelipe.com.br/android-ler-pdf-aplicativo/
https://github.com/jansenfelipe/AndroidMuPDF