BiSeNet+BiSeNetv2论文笔记
目录
- 一、BiSeNet: Bilateral Segmentation Network for Real-time Semantic Segmentation
-
- Abstract
- 1 Introduction
- 2 Related Work
- 3 双边分割网络
-
- 3.1空间路径
- 3.2 上下文路径
- 3.3网络架构
- 4 实验结果
- 二、BiSeNet V2: Bilateral Network with Guided Aggregation for Real-time Semantic Segmentation
-
- Abstract
- 2 Related Work
-
- 2.1通用语义分割
- 2.2实时语义分割
- 2.3 轻型结构
- 3 BiSeNetV2的核心概念
-
- 3.1 细节分支
- 3.2 语义分支
- 3.3 聚合层
- 4 双边分割网络
-
- 4.1 细节分支
- 4.2语义分支
-
- Stem Block
- Context Embedding Block
- Gather-and-Expansion Layer
- 4.3 双边引导聚合
- 4.4 提升培训策略
- 5 实验结果
提示:以下是本篇文章正文内容,下面案例可供参考
一、BiSeNet: Bilateral Segmentation Network for Real-time Semantic Segmentation
Abstract
语义分割既需要丰富的空间信息和相当大的接受域。然而,现代的方法通常会降低空间分辨率,以实现实时推理速度,从而导致性能较差。在本文中,我们用一种新的双边分割网络(BiSeNet)来解决这个困境。我们首先设计了一个小步幅的空间路径来保存空间信息和生成高分辨率的特征。同时,采用具有快速下采样策略的上下文路径来获得足够的接受域。在这两条路径的基础上,我们引入了一个新的特征融合模块来有效地结合特征。
1 Introduction
近年来,实时语义分割算法表明,主要有三种方法可以加速模型。1)试图通过裁剪或调整大小来限制输入的大小,以降低计算的复杂度。虽然该方法简单有效,但空间细节的丢失破坏了预测,特别是在边界周围的预测,导致度量和可视化的精度下降。2)一些工作不是调整输入图像的大小,而是对网络的通道进行修剪,以提高推理速度,特别是在基础模型的早期阶段。然而,它削弱了空间容量。3)对于最后一种情况,ENet提出放弃模型的最后一阶段,以追求一个非常紧凑的框架。然而,该方法的缺点很明显:由于ENet在最后一阶段放弃了降采样操作,模型的接受域不足以覆盖大的物体,导致识别能力较差。总的来说,上述方法都降低了精度,在实践中较差。图1(a)给出了插图。
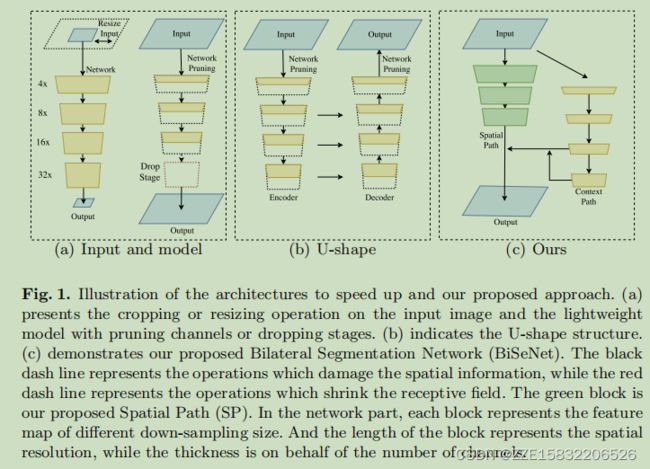
为了弥补上述空间细节的损失,研究人员广泛使用了u形结构。通过融合主干网络的层次特征,U形结构逐渐提高了空间分辨率,填补了一些缺失的细节。然而,这种技术有两个弱点。1)由于在高分辨率特征图上引入了额外的计算量,因此完整的u型结构可以降低模型的速度。2)更重要的是,在修剪或裁剪过程中丢失的大部分空间信息无法通过涉及的浅层来轻松恢复,如图1(b).所示换句话说,u型技术最好被看作是一种缓解,而不是一种基本的解决方案。
分割网络(BiSeNet),其中包括两部分:空间路径(SP)和上下文路径(CP)。正如它们的名字所暗示的那样,这两个组成部分分别是为了面对空间信息的损失和感受野的收缩。这两条道路的设计理念都很清晰。对于空间路径,我们只堆叠了3个卷积层,得到了1/8的特征图,它保留了丰富的空间细节。关于上下文路径,我们在X初始的尾部附加了一个全局平均池化层,其中接受域是主干网络的最大值。图1©显示了这两个组件的结构。
为了在不损失速度的情况下提高精度,我们还研究了两条路径的融合和最终预测的细化,并分别提出了特征融合模块(FFM)和注意细化模块(ARM)。
我们的主要贡献总结如下:
- 我们提出了一种新的方法来解耦空间信息保存和接受域提供的功能到两条路径。具体来说,我们提出了一个具有空间路径(SP)和上下文路径(CP)的双边分割网络(BiSeNet)。
- 我们设计了两个特定的模块,特征融合模块(FFM)和注意细化模块(ARM),以进一步以可接受的成本提高精度。
- 我们在城市景观、CamVid和coco东西的基准测试上取得了令人印象深刻的结果。更具体地说,我们在105FPS的速度下,在城市景观测试数据集上获得了68.4%的结果
2 Related Work
近年来,许多基于FCN的方法在语义分割任务的不同基准上取得了最先进的性能。这些方法大多是为了编码更多的空间信息或扩大接受域。
空间信息:卷积神经网络(CNN)通过连续的降采样操作对高级语义信息进行编码。然而,在语义分割任务中,图像的空间信息对于预测详细输出至关重要。现代现有的方法致力于编码丰富的空间信息。DUC、PSPNet、DeepLabv2和Deeplabv3使用扩展的卷积来保持特征图的空间大小。全局卷积网络[26]利用“大核”来扩大接受域。
U形方法:U形结构可以恢复一定程度的空间信息。原始的FCN[22]网络通过一个跳过连接的网络结构来编码不同级别的特征。一些方法将其特定的细化结构应用为u型网络结构。[1,24]使用反褶积层创建了一个u形的网络结构。U-net[27]为此任务介绍了有用的跳过连接网络结构。全局卷积网络将u型结构与“大核”相结合。LRR[10]采用了拉普拉斯金字塔重建网络。RefineNet添加了多路径细化结构来细化预测。DFN设计了一个通道注意块来实现特征选择。然而,在u型结构中,一些丢失的空间信息不能轻易恢复。
上下文信息:语义分割需要上下文信息来生成高质量的结果。大多数常见的方法都是扩大接受域或融合不同的上下文信息。[5,6,32,37]在卷积层中使用不同的膨胀速率来捕获不同的上下文信息。在图像金字塔的驱动下,在语义分割网络结构中始终采用多尺度特征集成。在[5]中,提出了一个“ASPP”模块来捕获不同接受域的上下文信息。PSPNet应用了一个“PSP”模块,它包含了几个不同规模的平均池化层。[6]设计了一个具有全局平均池化的“ASPP”模块来捕获图像的全局上下文。[38]通过尺度自适应卷积层对神经网络进行改进,以获得自适应场上下文信息。DFN在u形结构的顶部添加了全局池来编码全局上下文。
注意机制:注意机制可以利用高级信息来指导前馈网络的[23,31]。在[7]中,CNN的注意力取决于输入图像的规模。在[13]中,他们将通道注意力应用于识别任务中,达到了最先进的水平。与DFN[36]一样,它们学习全局上下文作为关注,并修改特性。
实时分割:实时语义分割算法需要快速生成高质量的预测结果。SegNet[1]利用小网络结构和跳跃连接方法实现快速速度。E-Net[25]从头开始设计了一个轻量级的网络,并提供了一个极高的速度。ICNet[39]使用图像级联来加速语义分割方法。[17]采用级联网络结构来减少“容易区域”的计算。[34]设计了一种新的双柱网络和空间稀疏性来降低计算成本。不同的是,我们提出的方法采用了一个轻量级的模型来提供足够的接受域。此外,我们设置了一个浅层但较宽的网络来捕获足够的空间信息。
3 双边分割网络
在本节中,我们首先详细说明我们提出的具有空间路径和上下文路径的双边分割网络(BiSeNet)。此外,我们还相应地阐述了这两条路径的有效性。最后演示如何将这两条路径的特性与特征融合模块和我们的BiSeNet的整个架构结合起来。
3.1空间路径
在语义分割任务中,一些现有的方法试图保持输入图像的分辨率,通过扩展卷积来编码足够的空间信息,而一些方法试图通过金字塔池模块、膨胀空间金字塔池或“大核”来捕获足够的接受域。这些方法表明,空间信息和感受野是实现高准确性的关键。然而,很难同时满足这两项要求。特别是在实时语义分割的情况下,现有的现代方法利用小输入图像或轻量级基模型来加快速度。输入图像的小尺寸丢失了原始图像的大部分空间信息,而轻量级模型通过通道剪枝损害了空间信息。
在此基础上,我们提出了一种空间路径来保持原始输入图像的空间大小,并编码丰富的空间信息。空间路径包含三个层。每一层包括与步幅=2的卷积,然后是批处理归一化[15]和ReLU[11]。因此,该路径提取的输出特征映射为原始图像的1/8。由于特征地图的空间尺寸较大,因此它编码了丰富的空间信息。图2(a)显示了该结构的细节。
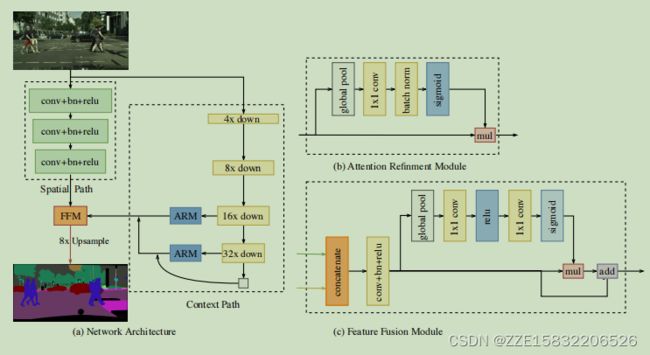
3.2 上下文路径
空间路径编码丰富的空间信息,而上下文路径被设计为提供足够的接受域。在语义分割任务中,接受域对其表现具有重要意义。为了扩大接受域,一些方法利用了金字塔池模块、无空间金字塔池或“大核”。然而,这些操作需要计算和消耗内存,这导致了速度较低。
在考虑到大的接受域和高效计算的同时,我们提出了上下文路径。上下文路径利用轻量级模型和全局平均池化来提供较大的接受域。在这项工作中,轻量级模型,如Xception,可以快速降采样特征地图,获得大的接受域,编码高级语义上下文信息。然后在我们的轻量级模型的尾部添加一个全局平均池,它可以为最大的接受域提供全局上下文信息。最后,我们结合了全局池化的上采样输出特征和轻量级模型的特征。在轻量级模型中,我们采用u型结构来融合后两个阶段的特征,这是一种不完整的u型风格。图2©显示了上下文路径的总体透视图。
注意细化模块:在上下文路径中,我们提出了一个特定的注意细化模块(ARM)来细化每个阶段的特征。如图2(b)所示,ARM使用全局平均池化来捕获全局上下文,并计算一个注意向量来指导特征学习。这种设计可以细化上下文路径中每个阶段的输出特性。它轻松地集成了全局上下文信息,而不需要进行任何上采样操作。因此,它所需要的计算成本可以忽略不计。
3.3网络架构
利用空间路径和上下文路径,我们提出了BiSeNet进行实时语义分割,如图2(a).所示。
我们使用预先训练过的前感觉模型作为上下文路径的主干,并使用以步幅作为空间路径的三个卷积层。然后,我们将这两条路径的输出特征融合起来,进行最终的预测。同时还可以实现实时性和高精度。首先,我们关注实际的计算方面。虽然空间路径有较大的空间大小,但它只有三个卷积层。因此,它不是计算密集型的。至于上下文路径,我们使用了一个轻量级的模型来快速地降采样。此外,这两条路径同时计算,大大提高了效率。其次,我们讨论了该网络的精度方面。在我们的论文中,空间路径编码了丰富的空间信息,而上下文路径提供了较大的接受域。它们相互互补以获得更高的性能。
特征融合模块:两条路径的特征在特征表示层次上有所不同。因此,我们不能简单地总结这些特征。空间路径所捕获的空间信息大多编码了丰富的细节信息。此外,上下文路径的输出特性主要是对上下文信息进行编码。也就是说,空间路径的输出特性较低,而上下文路径的输出特性高。因此,我们提出了一个特定的特征融合模块来融合这些特征。
考虑到这些特征的不同级别,我们首先将空间路径和上下文路径的输出特征连接起来。然后我们利用批处理归一化[15]来平衡特征的尺度。接下来,我们将连接的特征池到一个特征向量,并计算一个权向量,比如SENet[13]。这个权重向量可以重新加权特征,这相当于特征的选择和组合。图2©显示了这个设计的细节。
损失函数:在本文中,我们还利用辅助损失函数来监督我们所提出的方法的训练。我们使用主损失函数来监督整个BiSeNet的输出。此外,我们还添加了两个特定的辅助损失函数来监督上下文路径的输出,比如深度监督。所有的损失函数都是Softmax损失,如图1所示。此外,我们使用参数α来平衡主损失和辅助损失的权重,如方程2所示。本文中的α等于1。关节损失使优化器更舒适地优化模型。
4 实验结果
我们采用改进的感知模型来进行实时语义分割任务。我们的实现代码将被公开。我们根据城市景观、CamVid和COCO-Stuff基准来评估我们提出的BiSeNet。我们首先介绍了数据集和实现协议。接下来,我们将详细描述我们的速度策略与其他方法的比较。然后,我们研究了我们所提出的方法的每个组成部分的影响。我们评估了在城市景观验证集上的所有性能结果。最后,我们报告了城市景观、CamVid等人的准确性和速度结果。并与其他实时语义分割算法进行了比较。
城市景观:城市景观[9]是一个从汽车的角度来看的大型城市街景数据集。它包含2,975张用于训练的精细注释图像和另外500张用于验证的图像。在我们的实验中,我们只使用了精细注释的图像。对于测试,它提供了1525张没有基本事实的图像来进行公平的比较。这些图像的分辨率都为2,048×1,024,其中每个像素都被标注为预定义的19个类。
CamVid:CamVid是另一个从驾驶汽车的角度来看的街景数据集。它总共包含701张图像,其中367张用于训练,101张用于验证,233张用于测试。这些图像的分辨率为960×720和11个语义类别。
COCO-Stuff增加了流行的COCO[20]数据集的所有164,000张图像,其中118,000张图像用于训练,5,000张图像用于验证,20,000张图像用于测试开发,20,000张图像用于测试挑战。它涵盖了91个东西类和1个“未标记”类。
二、BiSeNet V2: Bilateral Network with Guided Aggregation for Real-time Semantic Segmentation
Abstract
低级细节和高级语义都是语义分割任务所必需的。然而,为了加快模型推理的速度,目前的方法几乎总是牺牲了低级别的细节,这导致了相当大的精度下降。我们提出将这些空间细节和分类语义分开处理,以实现实时语义分割的高精度和高效率。为此,我们提出了一种高效和有效的架构,具有良好的速度和准确性之间的权衡,称为双边分割网络(BiSeNetV2)。该架构包括:(i)一个细节分支,具有宽的通道和浅层来捕获低层次的细节并生成高分辨率的特征表示;(ii)一个语义分支,具有狭窄的通道和深层,以获得高级语义上下文。由于减少了信道容量和快速下采样策略,语义分支是轻量级的。此外,我们设计了一个引导聚合层来增强相互连接和融合这两种类型的特征表示。此外,还设计了一种强化训练策略来改进分割效果姿态架构的性能优于一些最先进的实时语义分割方法。
这些方法的高精度取决于其主干网络。骨干网络主要有两种架构:(i)扩张主干,去除下采样操作,对相应的滤波器内核进行上采样以保持高分辨率特征表示,如图2(a).所示(ii)编码器-解码器主干,通过自上而下和跳过连接,以恢复解码器部分的高分辨率特征表示,如图2(b).所示然而,这两种架构都是为一般的语义分割任务而设计的,而不太关心推理速度和计算成本。在扩展主干中,扩张卷积非常耗时,而去除降采样操作带来了严重的计算复杂度和内存占用。编码器-解码器架构中的许多连接对内存访问成本不太友好(Maetal.,2018)。然而,实时语义分割应用程序需要一个有效的推理速度。
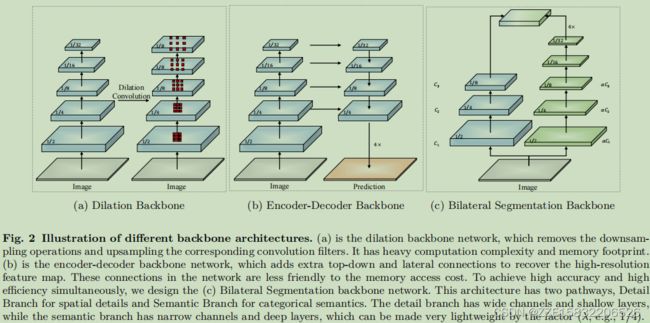
面对这一需求,基于两种骨干网络,现有方法主要采用两种方法加速模型:(i)输入限制。使用相同的网络架构,输入分辨率越小,越低,计算成本越低。为了实现实时推理速度,许多算法试图限制输入大小,以降低整个计算复杂度;(ii)通道修剪。这是一种直接的加速方法,特别是在早期阶段修剪通道以提高推理速度。虽然这两种方式都能在一定程度上提高推理速度,但它们牺牲了低层次的细节和空间容量,导致精度显著下降。因此,为了同时实现高效和高精度,开发一种特定的架构进行实时语义分割任务具有挑战性和重要意义。
我们观察到,低级的细节和高级语义对语义分割任务都是至关重要的,在一般的语义分割任务中,深度网络和宽网络同时对两种信息进行编码。然而,在实时语义分割任务中,我们可以分别处理空间细节和分类语义,以实现准确性和推理速度之间的权衡。
为此,我们提出了一种双路径体系结构,称为双边分割网络(BiSeNetV2),用于实时语义分割。其中一种路径被设计用来捕获具有宽通道和浅层的空间细节,称为细节分支。相反,引入另一种路径来提取具有窄通道和深层的分类语义,称为语义分支。语义分支只需要一个较大的接受域来捕获语义上下文,而细节信息可以由细节分支提供。因此,语义分支可以用更少的通道和快速下采样策略实现非常轻量级。两种类型的特征表示合并,构建更强更强、更全面的特征表示。这种概念设计导致了一种高效、有效的实时语义分割架构,如图2©.所示。
具体来说,在本研究中,我们设计了一个引导聚合层来有效地合并这两种类型的特征。为了在不增加推理复杂度的情况下进一步提高性能,我们提出了一种具有一系列辅助预测头的辅助训练策略,在推理阶段可以丢弃。大量的定量和定性评估表明,所提出的体系结构优于最先进的实时语义分割方法,如图1所示。
主要贡献总结如下:
- 我们提出了一种高效的双路径结构,称为双边分割网络,用于实时语义分割,它分别处理空间细节和分类语义。
- 对于语义分支,我们设计了一种新的基于深度卷积的轻量级网络,以增强接受域和捕获丰富的上下文信息。
- 引入了一种强化训练策略,在不增加推理成本的情况下进一步提高了分割性能。
(i)我们简化了原始结构,提出了一种高效、有效的实时语义分割体系结构。我们在原始版本中删除了耗时的跨层连接,以获得一个更清晰和更简单的架构。(ii)我们用更紧凑的网络结构和精心设计的组件重新设计了整体架构。具体来说,我们深化了详细路径来编码更多的细节。我们设计了基于语义路径的深度卷积的轻量级分量。同时,我们提出了一个有效的聚合层来增强两条路径之间的相互连接。(iii)我们进行了全面的消融实验,以阐述所提方法的有效性和效率。(iv)在我们之前的工作中,我们显著提高了该方法的准确性和速度,即对于2048×1024输入,在一个NVIDIA GeForce GTX1080Ti卡上以156FPS的速度在城市景观测试集上实现了72.6%的平均IoU。
2 Related Work
近年来,图像语义分割技术取得了重大进展。在本节中,我们的讨论主要关注与我们的工作最相关的三组方法,即通用的语义分割方法、实时语义分割方法和轻量级架构。
2.1通用语义分割
传统的分割方法基于阈值选择、区域增长、超像素和图算法采用手工制作的特征来解决这个问题。最近,基于FCN的新一代算法在不同的基准测试上不断提高最先进的性能。各种方法都基于两种类型的骨干网络:(i)扩展骨干网络;(ii)编码器-解码器骨干网络。
一方面,扩张主干去掉了降采样操作,并对卷积滤波器进行了上采样,以保持高分辨率的特征表示。由于膨胀卷积的简单性,各种方法开发不同的新颖有效成分。Deeplabv3设计了一个庞大的空间金字塔池来捕获多尺度环境,而PSPNet采用了扩张主干上的金字塔池模块。同时,一些方法引入了注意机制,如自我注意、空间注意和通道注意,以捕获基于扩张主干的远程情境。
另一方面,编码器-解码器骨干网络增加了额外的自上而下和横向连接,以恢复解码器部分的高分辨率特征图。FCN和超列采用跳过连接来集成底层特性。与此同时,U-net、SegNet保存池指数、RefineNet 、LRR、GCN和DFN通道注意模块合并该主干网络来恢复详细信息。HRNet采用多分支的方式来保持高分辨率。
这两种类型的主干网络与宽网络和深网络同时编码低级细节和高级语义。尽管这两种类型的主干网络都达到了最先进的性能,但大多数方法运行的推理速度都很慢。在本研究中,我们提出了一种新颖的、高效的架构来分别处理空间细节和分类语义,以实现分割精度和推理速度之间的良好转移。
2.2实时语义分割
当越来越多的实际应用需要快速交互和响应时,实时语义分割算法受到越来越多的关注。SegNe使用小型网络结构和跳过连接来实现快速速度。E-Net从零开始设计了一个轻量级的网络,并提供了极高的速度。ICNet使用图像级联加快算法,DLC采用级联网络结构来减少“容易区域”的计算。ERFNe采用残差连接和分解卷积来保持效率和准确性。同时,ESPNet设计了一种高效的空间金字塔扩张卷积方法,用于实时语义分割。GUN采用了一个引导的上采样模块来融合多分辨率输入的信息。DFANet重用了该特征,增强了特征表示,降低了复杂性。
虽然这些方法可以实现实时推理速度,但它们由于丢失了低级别的细节,而极大地牺牲了精度和效率。在这项工作中,我们同时考虑了低级的细节和高级语义,以实现高精度和高效率。
2.3 轻型结构
随着群/深度卷积和可分离卷积的开创性工作,轻量级架构设计实现了快速发展,包括Xception,MobileNet , ShuffleNet等等。这些方法在分类任务的速度和准确性之间实现了有价值的权衡。在本研究中,我们设计了一个给定计算复杂度、内存访问成本和真实推理速度的轻量级网络,用于实时语义分割。这些方法在分类任务的速度和准确性之间实现了有价值的权衡。在本研究中,我们设计了一个给定计算复杂度、内存存取成本和真实推理速度的轻量级网络,用于实时语义分割。
3 BiSeNetV2的核心概念
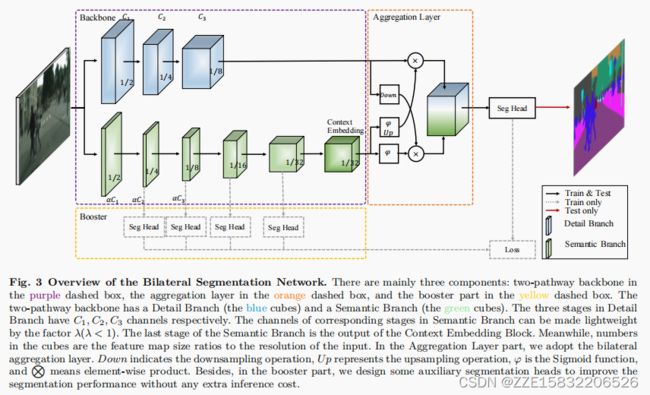
我们的体系结构由一个详细信息分支(第3.1节)和一个语义分支(第3.2节)组成,它们由一个聚合层(第3.3节)合并。在本节中,我们将演示我们的体系结构的核心概念,如图2©.所示。
3.1 细节分支
细节分支负责空间细节,这是一种低级信息。因此,该分支需要丰富的信道容量来编码丰富的空间详细信息。同时,由于细节分支只关注较低层次的细节,所以我们可以为这个分支设计一个具有较小步幅的浅层结构。总的来说,细节分支的关键概念是使用宽通道和浅层来进行空间细节。此外,该分支的特征表示具有较大的空间尺寸和较宽的通道。因此,最好不要采用剩余连接,这增加了内存访问成本,降低了速度。
3.2 语义分支
在与细节分支并行时,语义分支被设计用来捕获高级语义。该分支的通道容量较低,而空间细节可以由细节分支提供。相比之下,在我们的实验中,语义分支具有细节分支的λ(λ<1)通道的比例,这使得这个分支具有轻量级。实际上,语义分支可以是任何轻量级的卷积模型。
同时,语义分支采用了快速下采样策略,提高特征表征水平,快速扩大接受域。高级的语义需要较大的接受域。因此,语义分支使用全局平均池化来嵌入全局上下文响应。
3.3 聚合层
细节分支和语义分支的特征表示是互补的,其中一个分支不知道另一个分支的信息。因此,聚合层被设计为合并这两种类型的特征表示。由于快速下采样策略,语义分支输出的空间维数小于细节分支。我们需要对语义分支的输出特征映射进行上采样,以匹配详细信息分支的输出。
有一些融合信息的方式,例如简单的求和、连接和一些精心设计良好的操作。我们实验了不同的融合方法,考虑了融合的精度和效率。最后,我们采用了双向聚合的方法,如图3所示。
4 双边分割网络
我们的BiSeNet的概念是通用的,可以通过不同的卷积模型实现和任何具体设计。主要有三个关键概念:(i)细节分支具有高的通道容量,空间细节;(ii)语义分支的分类语义容量低,具有深层的大接受域。(iii)设计了一个有效的聚合层来融合这两种类型的表示。
在本小节中,根据所提出的概念设计,我们演示了我们对整体架构的实例化和其他一些特定的设计,如图3所示。
4.1 细节分支
表1中的Detail分支的实例化包含三个阶段,每一层都是一个卷积层,然后是批量归一化和激活函数。每个阶段的第一层有一个步幅s=2,而在同一阶段的其他层有相同数量的过滤器和输出特征图大小。因此,该分支提取了大小为原始输入的1/8的输出特征映射。由于高信道容量,这个细节分支编码了丰富的空间细节。由于高信道容量和大空间维度,残余结构将增加内存访问成本。因此,该分支主要遵循VGG网的理念来堆叠各层。
4.2语义分支
考虑到大的接受域和高效的计算,我们设计了语义分支,受轻量级识别模型理念的启发,如Xception、 MobileNet、 ShuffleNet。语义分支的一些关键特征如下。
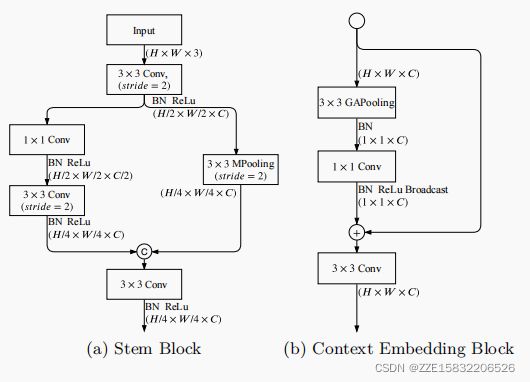
Stem Block
我们采用Stem Block作为语义分支的第一阶段,如图4所示。它使用了两种不同的降采样方式来缩小特征表示。然后将两个分支的输出特性连接为输出。该结构具有高效的计算成本和有效的特征表达能力。
Context Embedding Block
如第3.2节中所讨论的,语义分支需要较大的接受域来捕获高级语义。我们设计了上下文嵌入块。该块使用全局平均池化和残差连接来有效地嵌入全局上下文信息,如图4所示。
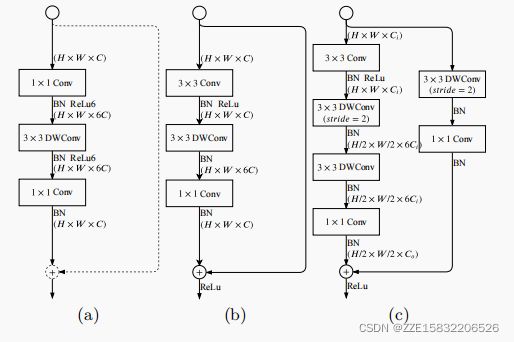
Gather-and-Expansion Layer
利用深度卷积的好处,我们提出了聚集和扩展层,如图5所示。聚集展开层包括:(i)3×3卷积,有效地聚集特征响应并扩展到高维空间;(iii)在展开层的每个输出通道上独立进行3×3深度卷积;(iv)1×1卷积作为投影层,将深度卷积的输出投影到一个低信道容量空间。当插入=2时,我们采用两个3×3深度卷积,进一步扩大了接受域,和一个3×3可分离卷积作为捷径。最近的研究大量采用5×5可分离卷积来扩大接受域,在某些条件下,它比两个3×3可分离卷积更少。在这一层中,我们用可分离卷积中的5×5深度卷积替换为两个3×3深度卷积,该卷积有更少的失败和相同的接受域。
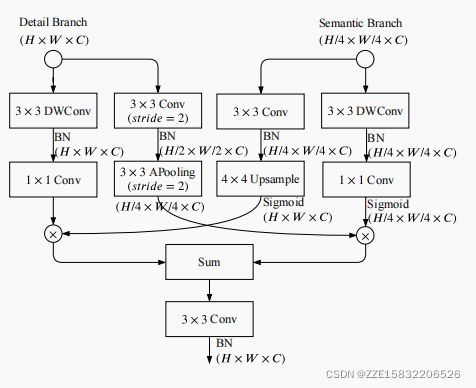
4.3 双边引导聚合
有一些不同的方式来合并两种类型的特征响应,即元素级的求和和连接。然而,这两个分支的输出都具有不同级别的特征表示。详细信息分支用于低级,而语义分支用于高级。因此,简单组合忽略了这两种类型信息的多样性,导致性能较差,优化困难。
基于观察结果,我们提出了 Bilateral Guided Aggregation Layer来融合来自两个分支的互补信息,如图6所示。该层利用语义分支的上下文信息来指导细节分支的特征响应。在不同的尺度引导下,我们可以捕获不同的尺度特征表示,这固有地编码了多尺度信息。同时,与简单的组合相比,这种引导方式使两个分支之间的通信更加有效。
4.4 提升培训策略
为了进一步提高分割精度,我们提出了一种强化训练策略。顾名思义,它类似于火箭助推器:它可以在训练阶段增强特征表示,在推理阶段可以丢弃。因此,它在推理阶段很少增加计算复杂度。如图3所示,我们可以将辅助分割头插入到语义分支的不同位置。在第5.1节中,我们分析了不同位置对插入的影响。图7说明了分割头部的细节。通过控制信道维数Ct,我们可以调整辅助分割头和主分割头的计算复杂度。
5 实验结果
在本节中,我们首先将介绍数据集和实现细节。接下来,我们研究了我们提出的方法的每个组成部分对城市景观验证集的影响。最后,我们报告了我们在不同基准上的最终精度和速度结果。
城市景观 关注于从汽车的角度对城市街景的语义理解。数据集分为训练、验证和测试集,分别有2975500张和1525张图像。在我们的实验中,我们只使用精细标注的图像来验证我们所提出的方法的有效性。该注释包括30个类,其中19个类用于语义分割任务。该数据集具有2048×1024的高分辨率,对实时语义分割具有挑战性。
COCO-Stuff 使用密集的内容注释增强了流行的COCO(Lin等人,2014)数据集的10K复杂图像。这对于实时语义分割也是一个具有挑战性的数据集,因为它有更复杂的类别,包括91件事和91个用于评估的东西类。为了进行公平的比较,我们遵循了Caesaretal的分割:9K图像用于训练,1K图像用于测试。