机器学习是人工智能的一个分支领域,致力于构建自动学习和自适应的系统,它利用统计模型来可视化、分析和预测数据。一个通用的机器学习模型包括一个数据集(用于训练模型)和一个算法(从数据学习)。但是有些模型的准确性通常很低产生的结果也不太准确,克服这个问题的最简单的解决方案之一是在机器学习模型上使用集成学习。
集成学习是一种元方法,通过组合多个机器学习模型来产生一个优化的模型,从而提高模型的性能。集成学习可以很容易地减少过拟合,避免模型在训练时表现更好,而在测试时不能产生良好的结果。
总结起来,集成学习有以下的优点:
- 增加模型的性能
- 减少过拟合
- 降低方差
- 与单个模型相比,提供更高的预测精度。
- 可以处理线性和非线性数据。
- 集成技术可以用来解决回归和分类问题
下面我们将介绍各种集成学习的方法:
Voting
Voting是一种集成学习,它将来自多个机器学习模型的预测结合起来产生结果。在整个数据集上训练多个基础模型来进行预测。每个模型预测被认为是一个“投票”。得到多数选票的预测将被选为最终预测。
有两种类型的投票用于汇总基础预测-硬投票和软投票。

硬投票选择投票数最高的预测作为最终预测,而软投票将每个模型中每个类的概率结合起来,选择概率最高的类作为最终预测。
在回归问题中,它的工作方式有些不同,因为我们不是寻找频率最高的类,而是采用每个模型的预测并计算它们的平均值,从而得出最终的预测。
from sklearn.ensemble import VotingClassifier
## Base Models
from sklearn.tree import DecisionTreeClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.naive_bayes import GaussianNB
from sklearn.neighbors import KNeighborsClassifier
from sklearn.svm import SVC
ensemble_voting = VotingClassifier(
estimators = [('dtc',DecisionTreeClassifier(random_state=42)),
('lr', LogisticRegression()),
('gnb', GaussianNB()),
('knn',KNeighborsClassifier()),
('svc',SVC())],
voting='hard')
ensemble_voting.fit(X_train,y_train)Bagging
Bagging是采用几个弱机器学习模型,并将它们的预测聚合在一起,以产生最佳的预测。它基于bootstrap aggregation,bootstrap 是一种使用替换方法从集合中抽取随机样本的抽样技术。aggregation则是利用将几个预测结合起来产生最终预测的过程。
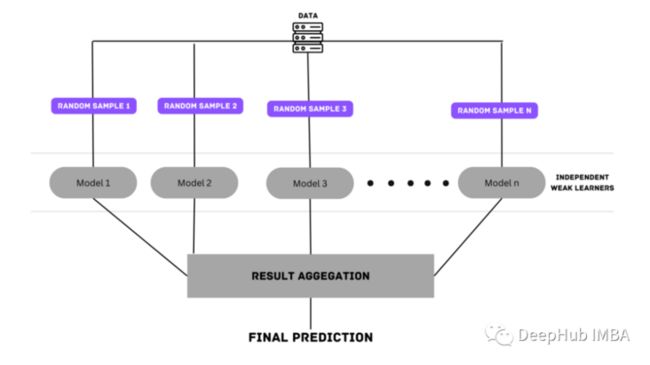
随机森林是利用Bagging的最著名和最常用的模型之一。它由大量的决策树组成,这些决策树作为一个整体运行。它使用Bagging和特征随机性的概念来创建每棵独立的树。每棵决策树都是从数据中随机抽取样本进行训练。在随机森林中,我们最终得到的树不仅接受不同数据集的训练,而且使用不同的特征来预测结果。
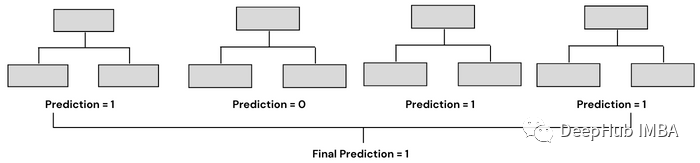
Bagging通常有两种类型——决策树的集合(称为随机森林)和决策树以外的模型的集合。两者的工作原理相似,都使用聚合方法生成最终预测,唯一的区别是它们所基于的模型。在sklearn中,我们有一个BaggingClassifier类,用于创建除决策树以外的模型。
## Bagging Ensemble of Same Classifiers (Decision Trees)
from sklearn.ensemble import RandomForestClassifier
classifier= RandomForestClassifier(n_estimators= 10, criterion="entropy")
classifier.fit(x_train, y_train)
## Bagging Ensemble of Different Classifiers
from sklearn.ensemble import BaggingClassifier
from sklearn.svm import SVC
clf = BaggingClassifier(base_estimator=SVC(),
n_estimators=10, random_state=0)
clf.fit(X_train,y_train)Boosting
增强集成方法通过重视先前模型的错误,将弱学习者转化为强学习者。Boosting以顺序的方式实现同构ML算法,每个模型都试图通过减少前一个模型的误差来提高整个过程的稳定性。

在训练n+1模型时,数据集中的每个数据点都被赋予了相等的权重,这样被模型n错误分类的样本就能被赋予更多的权重(重要性)。误差从n个学习者传递给n+1个学习者,每个学习者都试图减少误差。
ADA Boost是使用Boost生成预测的最基本模型之一。ADA boost创建一个决策树桩森林(一个树桩是一个只有一个节点和两个叶子的决策树),不像随机森林创建整个决策树森林。它给分类错误的样本分配更高的权重,并继续训练模型,直到得到较低的错误率。
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import AdaBoostClassifier
dt = DecisionTreeClassifier(max_depth=2, random_state=0)
adc = AdaBoostClassifier(base_estimator=dt, n_estimators=7, learning_rate=0.1, random_state=0)
adc.fit(x_train, y_train)Stacking
Stacking也被称为叠加泛化,是David H. Wolpert在1992年提出的集成技术的一种形式,目的是通过使用不同的泛化器来减少错误。
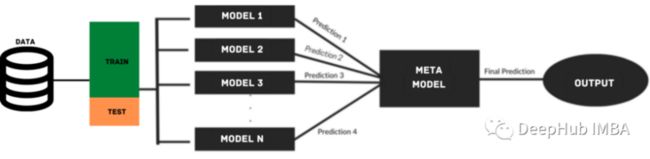
叠加模型利用来自多个基础模型的预测来构建元模型,用于生成最终的预测。堆叠模型由多层组成,其中每一层由几个机器学习模型组成,这些模型的预测用于训练下一层模型。
在叠加过程中,将数据分为训练集和测试集两部分。训练集会被进一步划分为k-fold。基础模型在k-1部分进行训练,在kᵗʰ部分进行预测。这个过程被反复迭代,直到每一折都被预测出来。然后将基本模型拟合到整个数据集,并计算性能。这个过程也适用于其他基本模型。
来自训练集的预测被用作构建第二层或元模型的特征。这个第二级模型用于预测测试集。
from sklearn.neighbors import KNeighborsClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.svm import SVC
from sklearn.linear_model import LogisticRegression
from sklearn.ensemble import StackingClassifier
base_learners = [
('l1', KNeighborsClassifier()),
('l2', DecisionTreeClassifier()),
('l3',SVC(gamma=2, C=1)))
]
model = StackingClassifier(estimators=base_learners, final_estimator=LogisticRegression(),cv=5)
model.fit(X_train, y_train)Blending
Blending是从Stacking派生出来另一种形式的集成学习技术,两者之间的唯一区别是它使用来自一个训练集的保留(验证)集来进行预测。简单地说,预测只针对保留得数据集。保留得数据集和预测用于构建第二级模型。

import numpy as np
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
## Base Models
from sklearn.neighbors import KNeighborsClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.svm import SVC
## Meta Learner
from sklearn.linear_model import LogisticRegression
## Creating Sample Data
X,y = make_classification(n_samples=10000, n_features=20, n_informative=15, n_redundant=5, random_state=42)
## Training a Individual Logistic Regression Model
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=1)
logrec = LogisticRegression()
logrec.fit(X_train,y_train)
pred = logrec.predict(X_test)
score = accuracy_score(y_test, pred)
print('Base Model Accuracy: %.3f' % (score*100))
## Defining Base Models
def base_models():
models = list()
models.append(('knn', KNeighborsClassifier()))
models.append(('dt', DecisionTreeClassifier()))
models.append(('svm', SVC(probability=True)))
return models
## Fitting Ensemble Blending Model
## Step 1:Splitting Data Into Train, Holdout(Validation) and Test Sets
X_train_full, X_test, y_train_full, y_test = train_test_split(X, y, test_size=0.3, random_state=1)
X_train, X_val, y_train, y_val = train_test_split(X_train_full, y_train_full, test_size=0.33, random_state=1)
## Step 2: train base models on train set and make predictions on validation set
models = base_models()
meta_X = list()
for name, model in models:
# training base models on train set
model.fit(X_train, y_train)
# predict on hold out set
yhat = model.predict_proba(X_val)
# storing predictions
meta_X.append(yhat)
# horizontal stacking predictions
meta_X = np.hstack(meta_X)
## Step 3: Creating Blending Meta Learner
blender = LogisticRegression()
## training on base model predictions
blender.fit(meta_X, y_val)
## Step 4: Making predictions using blending meta learner
meta_X = list()
for name, model in models:
yhat = model.predict_proba(X_test)
meta_X.append(yhat)
meta_X = np.hstack(meta_X)
y_pred = blender.predict(meta_X)
# Evaluate predictions
score = accuracy_score(y_test, y_pred)
print('Blending Accuracy: %.3f' % (score*100))
---------------------------------
Base Model Accuracy: 82.367
Blending Accuracy: 96.733总结
在阅读完本文之后,您可能想知道是否有选择一个更好的模型最好得方法或者如果需要的话,使用哪种集成技术呢?
在这个问题时,我们总是建议从一个简单的个体模型开始,然后使用不同的建模技术(如集成学习)对其进行测试。在某些情况下,单个模型可能比集成模型表现得更好,甚至好很多好。
需要说明并且需要注意的一点是:集成学习绝不应该是第一选择,而应该是最后一个选择。原因很简单:训练一个集成模型将花费很多时间,并且需要大量的处理能力。
回到我们的问题,集成模型旨在通过组合同一类别的几个基本模型来提高模型的可预测性。每种集成技术都是最好的,有助于提高模型性能。
如果你正在寻找一种简单且易于实现的集成方法,那么应该使用Voting。如果你的数据有很高的方差,那么你应该尝试Bagging。如果训练的基础模型在模型预测中有很高的偏差,那么可以尝试不同的Boosting技术来提高准确性。如果有多个基础模型在数据上表现都很好好,并且不知道选择哪一个作为最终模型,那么可以使用Stacking 或Blending的方法。当然具体那种方法表现得最好还是要取决于数据和特征分布。
最后集成学习技术是提高模型精度和性能的强大工具,它们很容易减少数据过拟合和欠拟合的机会,尤其在参加比赛时这是提分的关键。
https://avoid.overfit.cn/post/f815d35fd51d44de8a17a3a5e609dfa6
作者:Abhay Parashar