PyTorch基础
PyTorch文档:https://pytorch.org/docs/stable/index.html
PyTorch常用代码段:PyTorch 52.PyTorch常用代码段合集 - 知乎
Pytorch历史版本下载:https://pytorch.org/get-started/previous-versions
目录
一、基础知识
二、基本配置
三、张量处理
1.张量数据类型
2.张量性质
3.创建张量/数据类型转换
4.随机张量
5.张量操作
6.张量运算
四、torch.nn
1.torch.nn
2.torch.nn.functional
3.torch.utils.data.Dataset
4.torch.utils.data.Dataloader
5.loss
6.torch.optim、torch.optim.scheduler
7.torch.save()、torch.load()
8.torch.distributed、torch.nn.parallel.DistributedDateParallel
五、torch.nn.Module
1.model.train()、model.eval()、torch.no_grad()
2.model.modules()、model.children()
3.model.parameters()、model.named_parameters()、model.state_dict()
4.model.parameters()、model.buffers()
六、其他
1.freeze parameters 冻结参数
2.reproducibility 可复现性
一、基础知识
1.Pytorch和Tensorflow的数据格式
- Pytorch: N * Channels * Height * Width, NCHW
- Tensorflow: N * Height * Width * Channels, NHWC
2.自动求导(autograd)机制
所谓自动求导,是为了方便用户通过简单的几行代码就能得到所求变量的梯度。具体是是通过反向传播算法实现的,本质上是链式法则。
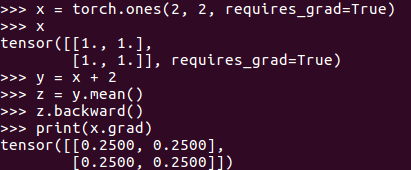
注:tensor必须是float型才有requires_grad属性
二、基本配置
1.版本信息
| 方法 | 描述 |
|---|---|
| torch.__version__ | 查询torch版本 |
| torch.version.cuda | 查询cuda版本 |
| torch.backends.cudnn.version() | 查询cudnn版本 |
2.显卡设置
| 方法 | 描述 |
|---|---|
| torch.cuda.device_count() | 查询显卡数量 |
| torch.cuda.get_device_name() | 查询显卡版本 |
| torch.cuda.is_available() | cuda是否可用 |
| torch.device('cuda:0') <=> torch.device('cuda, 0') <=> torch.device(0) | 指定显卡 |
| torch.device('cuda', if torch.cuda.is_available else 'cpu') | |
| os.environ['CUDA_VISIBLE_DEVICES']='0,1' | 指定可见的显卡,‘-1’表示显卡不可见 |
三、张量处理
1.张量数据类型
| 数据类型 | 类 |
|---|---|
| torch.float() / torch.float32() | torch.FloatTensor() <=> torch.Tensor() |
| torch.long() / torch.float64() | torch.LongTensor() |
| torch.half() / torch.float16() | torch.HalfTensor() |
| torch.uint8() | torch.ByteTensor() |
| torch.int8() | torch.CharTensor() |
| torch.int16() | torch.ShortTensor() |
| torch.int32() | torch.IntTensor() |
| torch.int64() | torch.LongTensor() |
| torch.bool() | torch.BoolTensor() |
2.张量性质
| 方法 | 描述 |
|---|---|
| tensor.size() <=> tensor.shape | 返回张量形状 |
| tensor.dtype | 返回张量数据类型 |
| tensor.dim() | 返回张量维数 |
3.创建张量/数据类型转换
| 方法 | 描述 |
|---|---|
| torch.type() <=> torch.type_as() | 张量类型转换 |
| torch.from_numpy(ndarray) | 数组转张量 |
| torch.tensor(array_like) | torch.tensor是一个函数 |
| torch.Tensor(ndarray) | 数组转张量 |
| tensor.numpy() | CPU张量转数组 |
| tensor.cpu().numpy() | GPU张量转数组 |
| tensor.detach().numpy() | 返回一个新tensor,新tensor和原tensor共享数据内存,但requires_grad=False |
4.随机张量
| 方法 | 描述 |
|---|---|
| torch.rand(*size) | 生成在区间[0, 1)内均匀分布的张量 |
| torch.randn(*size) | 生成服从标准正态分布的张量 |
| torch.randint(low, high, size) | 生成服从均匀分布的整型张量 |
| torch.normal(mean, std, size) | 生成服从离散正态分布的张量 |
5.张量操作
| 方法 | 描述 |
|---|---|
| tensor.cuda(device) <=> tensor.to(device) | 将CPU张量转换为GPU张量 |
| tensor.contiguous() | 使张量在内存中连续存储,返回副本 |
| tensor.permute() | 返回张量改变维度顺序后的视图 |
| tensor.transpose() | 相较于permute,transpose只能转置张量的两个维度 |
| tensor.view(*size) | 改变连续的张量的形状,返回视图。permute、transpose方法返回的是视图,虽然没有改变张量存储顺序,但是改变了索引方式,所以在使用view之前要先加contiguous 参考:PyTorch:view() 与 reshape() 区别详解_Flag_ing的博客-CSDN博客 |
| tensor.reshape(*size) | 改变张量的形状,张量可以不是连续存储的(经过tanspose、permute、narrow、expand等操作得到的张量与原张量共享内存,但原来在内存中相邻的元素在执行这样的操作后,在内存中不相邻了,即不连续了)。当张量连续时返回视图;否则返回副本 |
| tensor.flatten(start_dim, end_dim) | 改变张量的形状,返回原数据或视图或副本。torch.flatten — PyTorch 1.9.1 documentation |
| tensor.clone() | 复制张量,开辟一段新的内存,返回值仍在计算图中 |
| tensor.detach() | 将张量从当前计算图中分离,返回一个新的张量,仍指向原张量的存储位置,requires_grad为false,得到的这个张量永远不需要计算其梯度,不具有grad,即使之后将requires_grad设为true,也不会具有grad |
| tensor.detach().clone() | 将张量从当前计算图中分离并复制 |
| tensor.expand(*sizes) | 扩展张量 |
| tensor.expand_as(array_like) <=> tensor.expand(array_like.size()) | 扩展张量 |
| tensor.repeat(*sizes) | 复制并扩展张量,expand不复制张量 |
6.张量运算
| 方法 | 描述 |
|---|---|
| tensor.backward(retain_graph=False) | Pytorch默认一个计算图(一次前向传播)只计算一次反向传播,计算完成后计算图就会被释放,因此如果后续还要用到计算图的话需要设retain_graph=true |
| tensor.clamp(min, max) | 将张量的值截取在[min, max]之间 |
| tensor.clamp_(min, max) | 将张量的值截取在[min, max]之间并返回给原张量 |
| tensor.max(dim, keepdim) <=> torch.max(tensor, dim, keepdim) | 求张量最大值, 返回一个元组,元组第一个元素是求得的最大值,第二个元素是最大值的索引 |
| tensor.min(dim, keepdim) <=> torch.min(tensor, dim, keepdim) | 求张量最小值, 返回一个元组,元组第一个元素是求得的最小值,第二个元素是最小值的索引 |
| tensor.mean(dim) | 求张量均值 |
| torch.maximun(tensor1, tensor2) | 计算两个张量对应元素的最大值 |
| torch.minimun(tensor1, tensor2) | 计算两个张量对应元素的最小值 |
| torch.pow(tensor, exponent) | 求张量各个元素的幂次方 |
| torch.eq、torch.lt、torch.le、torch.ge、torch.gt | 比较两个张量对应元素的大小 |
四、torch.nn
1.torch.nn
| 类型 | 类名 | 描述 |
|---|---|---|
| Containers | nn.Module(object) | 所有neural network modules的基类 |
| nn.Sequential(nn.Module) | nn.Sequential(*args),不需要重写forward方法,按照传入参数的顺序进行forward | |
| nn.ModueList(nn.Module) | nn.ModuleList(iterable),需要重写forward方法 | |
| DataParallel Layers | nn.DataParallel <=> nn.parallel.DataParallel | model=nn.DataParallel(model),返回的model已经不是原始的model了,而是一个DataParallel对象,原始的model保存在DataParallel的module变量里 |
| nn.parallel.DistributedDataParallel |
2.torch.nn.functional
- torch.nn后大写的是类,可以放入container中
- torch.nn.functional是函数
3.torch.utils.data.Dataset
from torch.utils.data import Dataset
class CustomDataset(Dataset):
def __int__(self, *args):
def __len__ (self):
def __getitem__(self, idx):
dataset = CustomDataset(*args)- map-style dataset:
Map-style datasets
A map-style dataset is one that implements the
__getitem__()and__len__()protocols, and represents a map from (possibly non-integral) indices/keys to data samples.For example, such a dataset, when accessed with
dataset[idx], could read theidx-th image and its corresponding label from a folder on the disk.
- iterable-style dataset:
Iterable-style datasets
An iterable-style dataset is an instance of a subclass of IterableDataset that implements the
__iter__()protocol, and represents an iterable over data samples. This type of datasets is particularly suitable for cases where random reads are expensive or even improbable, and where the batch size depends on the fetched data.For example, such a dataset, when called
iter(dataset), could return a stream of data reading from a database, a remote server, or even logs generated in real time.
4.torch.utils.data.Dataloader
torch.utils.data.DataLoader(dataset,
batch_size=1,
shuffle=False,
sampler=None,
batch_sampler=None,
num_workers=0,
collate_fn=None,
pin_memory=False,
drop_last=False)
from torch.utils.data.sampler import SequentialSampler, RandomSampler, BatchSampler
print(list(SequentialSampler(range(5, 15))))
print(list(RandomSampler(range(5, 15))))
print(list(BatchSampler(RandomSampler(range(5, 15)), batch_size=3, drop_last=False)))
>>>[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
>>>[6, 1, 5, 3, 8, 0, 2, 7, 4, 9]
>>>[[6, 4, 8], [3, 2, 1], [9, 0, 7], [5]]| 参数 | 描述 | 默认值 |
|---|---|---|
| batch_size | 一个batch的大小 | 1 |
| shuffle | 每个epoch让数据shuffle一次 | False |
| sampler | 定义从dataset中获取样本的策略 | None |
| batch_sampler | 每次返回一个batch的indices | None |
| num_workers | 用于载入数据的子进程数 | 0 |
| collate_fn | 用于合并一个batch的数据。如果dataset只返回img、label,collate_fn可以为默认值;如果返回更多项,就需要自定义collate_fn | None |
| pin_memory | pin_memory=True时cuda直接从锁页(内存)中读取数据,读取速度快;否则数据需要先从虚拟内存(磁盘)传入,再传入cuda | False |
| drop_last | 当数据总数不能被batch size整除时,抛弃最后一个batch | False |
初始化参数之间的关系 :
- 如果dataset是iterable-style的,则shuffle、sampler、batch_sampler必须为False、None、None,因为iterable-style的数据集不需要索引
- 如果batch_sampler不为None,则batch_size、shuffle、sampler、drop_last必须为1、False、None、False,batch_size赋值为None、drop_last赋值为False,即:
# auto_collation with custom batch_sampler
- 如果batch_size、batch_sampler都为None,则drop_last为False,因为此时无collation操作,每个样本即为1个batch,即:
# no auto_collation
- 如果batch_size不为None、batch_sampler为None,则batch_sampler使用PyTorch已经实现好的BatchSampler,即:
# auto_collation without custom batch_sampler / with default batch_sampler
- 如果sampler不为None,则shuffle必须为False
- 如果sampler为None,shuffle=False时sampler为SequentialSampler;shuffle=True时sampler为RandomSampler
参考:一文弄懂Pytorch的DataLoader, Dataset, Sampler之间的关系 - marsggbo - 博客园
5.loss
logits指网络最后一层位于激活函数之前的张量。
- nn.BCELoss(): 逐元素计算交叉熵并取平均。输入值必须在0~1区间内,因此需要先对logits进行sigmoid处理,target必须是one-hot形式
- nn.BCEWithLogitsLoss(): 包含了sigmoid层,除此之外都与nn.BCELoss()相同
import torch
import torch.nn.functional as F
n = 2 # batch_size
c = 2 # num_cls
pred = torch.randn(n, c)
print(pred)
pred = pred.sigmoid()
print(pred)
target = torch.randint(0, c + 1, (n,))
target = F.one_hot(target, num_classes=c + 1)
target = target[:, :c]
target = target.type_as(pred)
print(target)
loss1 = torch.nn.BCELoss()(pred, target)
print(loss1)
loss2 = (- target * torch.log(pred) - (1 - target) * torch.log(1 - pred)).mean() # element-wise
print(loss2)- nn.CrossEntropyLoss():LogSoftmax and NLLLoss的组合,注意target并不是one-hot形式
import torch
import torch.nn.functional as F
n = 2 # batch_size
c = 2 # num_cls
pred = torch.randn(n, c)
pred_s = F.softmax(pred, dim=1)
print(pred_s)
pred_l = torch.log(pred_s)
print(pred_l)
target = torch.randint(0, c, (n, ))
print(target)
loss1 = torch.nn.NLLLoss()(pred_l, target)
print(loss1)
loss2 = torch.nn.CrossEntropyLoss()(pred, target)
print(loss2)
loss3 = []
for b in range(n):
loss3.append(-pred_l[b, target[b]]) # NLLLoss
loss3 = torch.mean(torch.Tensor(loss3))
print(loss3)6.torch.optim、torch.optim.scheduler
import torch.optim as optim
import torch.optim.lr_scheduler as lr_scheduler
optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.9, nesterov=True)
optimizer = optim.Adam(model.parameters(), lr=0.01, betas=(0.9, 0.999))
scheduler = lr_scheduler.ReduceLROnPlateau(optimizer, patience=3, verbose=True)
# every iteration
optimizer.zero_grad()
loss.backward()
optimizer.step()
# every epoch
scheduler.step()
7.torch.save()、torch.load()
一般保存为.pkl或者.pth文件
# 只保存参数、加载参数
torch.save(model.state_dict(), 'checkpoint.pkl')
model.load_state_dict(torch.load('checkpoint.pkl'))
# 保存、加载整个网络
torch.save(model, 'model.pkl')
model = torch.load('model.pkl')
# 保存、加载更多信息
torch.save({'epoch': epoch,
'state_dict': model.state_dict(),
'optimizer': optimizer.state_dict()}, PATH)
checkpoint = torch.load(PATH)
epoch = checkpoint['epoch']
model.load_state_dict(checkpoint['state_dict'])
optimizer.load_state_dict(checkpoint['optimizer'])
# 加载预训练模型中的部分参数
model=resnet()
model_dict = model.state_dict()
pretrained_dict = torch.load(PATH)
new_dict = {k: v for k, v in pretrained_dict.items() if k in model_dict}
model_dict.update(new_dict) # 更新参数的值
model.load_state_dict(model_dict)8.torch.distributed、torch.nn.parallel.DistributedDateParallel
DP和DDP的区别:DDP 比 DP 快几倍的原因_blueblood7的专栏-CSDN博客
DP模式下,GPU0(master)从锁页内存中读取mini-batch,将数据分发(scatter)给其他GPU并复制模型(其他GPU内的是未更新的旧模型);每个GPU前向传播得到输出,汇总(gather)给GPU0计算loss;GPU0分发给其他GPU反向传播计算梯度,在GPU0中进行reduce操作并更新模型参数
DDP模式下,每个GPU直接从锁页内存中读取sub mini-bacth,并且都复制了模型;每个GPU各自进行前向和反向传播,梯度进行all-reduce操作,更新给每个模型
import torch.distributed as dist
torch.distributed.init_process_group(backend,
init_method=None,
timeout=datetime.timedelta(0, 1800),
world_size=-1,
rank=-1,
store=None,
group_name='')| 参数 | 描述 |
|---|---|
| backend | gpu使用'nccl'后端 |
| init_method | 这个URL指定了如何初始化互相通信的进程。默认值'env://',和store互斥 |
| world_size | 总进程数 |
| rank | 进程号 |
- 分布式训练(摘自PyTorch文档torch.distributed.launch):
1. This utility and multi-process distributed (single-node or multi-node) GPU training currently only achieves the best performance using the NCCL distributed backend. Thus NCCL backend is the recommended backend to use for GPU training.
2. In your training program, you must parse the command-line argument:
--local_rank=LOCAL_PROCESS_RANK, which will be provided by this module. If your training program uses GPUs, you should ensure that your code only runs on the GPU device of LOCAL_PROCESS_RANK. This can be done by:Parsing the local_rank argument
>>> import argparse >>> parser = argparse.ArgumentParser() >>> parser.add_argument("--local_rank", type=int) >>> args = parser.parse_args()Set your device to local rank using either
>>> torch.cuda.set_device(args.local_rank) # before your code runsor
>>> with torch.cuda.device(args.local_rank): >>> # your code to run3. In your training program, you are supposed to call the following function at the beginning to start the distributed backend. You need to make sure that the init_method uses
env://, which is the only supportedinit_methodby this module.torch.distributed.init_process_group(backend='YOUR BACKEND', init_method='env://')4. In your training program, you can either use regular distributed functions or use torch.nn.parallel.DistributedDataParallel() module. If your training program uses GPUs for training and you would like to use torch.nn.parallel.DistributedDataParallel() module, here is how to configure it.
model = torch.nn.parallel.DistributedDataParallel(model, device_ids=[args.local_rank], output_device=args.local_rank)Please ensure that
device_idsargument is set to be the only GPU device id that your code will be operating on. This is generally the local rank of the process. In other words, thedevice_idsneeds to be[args.local_rank], andoutput_deviceneeds to beargs.local_rankin order to use this utility5. Another way to pass
local_rankto the subprocesses via environment variableLOCAL_RANK. This behavior is enabled when you launch the script with--use_env=True. You must adjust the subprocess example above to replaceargs.local_rankwithos.environ['LOCAL_RANK']; the launcher will not pass--local_rankwhen you specify this flag.
- 分布式训练代码段
import argparse
import torch.distributed as dist
import torch.nn.parallel.DistributedDataParallel as DDP
# 添加命令行变量local_rank
parser = argparse.ArgumentParser()
parser.add_argument('--local_rank', type=int)
args = parser.parse_args()
# 初始化进程组
torch.distributed.init_process_group(backend='nccl', init_method='env://')
# train
# 分布式模型
model = DDP(model, device_ids=device_ids)
# 分布式sampler
sampler = torch.utils.data.distributed.DistributedSampler(dataset)
dataloader = torch.utils.data.DataLoader(dataset, batch_size, num_workers, sampler=sampler)
# 销毁进程组
dist.destroy_process_group()#!/usr/bin/bash
# 训练脚本通过torch.distributed.launch来启动
python -m torch.distributed.launch --nproc_per_node=NUM_GPUS train.py 注:分布式训练时的learning rate应根据每个gpu的batch_size数和gpu数作相应的调整,即lr和samples_per_gpu*num_gpus呈线性相关
五、torch.nn.Module
class model(nn.Module):
pass1.model.train()、model.eval()、torch.no_grad()
(1)train和eval()模式的区别在于Dropout层和BN层的表现:
- Dropout层在train模式下会丢失一部分连接;在eval模式下会关闭
- BN层在train模式下使用当前batch的mean、var,同时计算running_mean和running_var(全局mean和var);在eval模式下使用训练时的running_mean和running_var。
BatchNorm2d — PyTorch 1.9.1 documentation https://pytorch.org/docs/stable/generated/torch.nn.BatchNorm2d.html?highlight=batchnorm#torch.nn.BatchNorm2d
https://pytorch.org/docs/stable/generated/torch.nn.BatchNorm2d.html?highlight=batchnorm#torch.nn.BatchNorm2d
(2)torch.no_grad()用于停止梯度计算,作用类似于detach()。被torch.no_grad()包裹的变量requres_grad为False、grad_fn为None,即grad_fn不再记录相应的反向梯度函数。一般用于测试或推理(无loss.backward()),可以节省GPU资源
import torch
a = torch.tensor([[1., 2.], [3., 4.]], requires_grad=True)
b = a * 2
with torch.no_grad():
c = a * 2
# or
@torch.no_grad()
def mul(x):
return x * 2
c = mul(a)
>>>b
tensor([[2., 4.],
[6., 8.]], grad_fn=)
>>>c
tensor([[2., 4.],
[6., 8.]]) 2.model.modules()、model.children()
- model.modules()遍历所有的子模块(包括自身),即递归遍历
- model.children()只遍历一层
3.model.parameters()、model.named_parameters()、model.state_dict()
for param in model.parameters():
print(param)
for name, param in model.named_parameters():
print(name, param)
# state_dict是一个有序字典,param.requires_grad=False,且无法改变,要想设置只能通过前两种方式
for name, param in model.state_dict().items():
print(name, param)4.model.parameters()、model.buffers()
- parameters:通过optimizer更新的参数(tensor)
self.param = nn.Parameter(torch.randn(3, 3))
# or
self.register_parameter('param', torch.randn(3, 3))- buffers:不通过optimizer更新的参数(tensor)
self.register_buffer('buffer', torch.randn(3, 3))
self.attribute = torch.randn(3, 3)注意buffer和attribute的区别:attribute无法被state_dict()访问,而buffer可以
六、其他
1.freeze parameters 冻结参数
BN层的weight(gamma)和bias(beta)通过requires_grad = False来冻结;running_mean和running_var是buffer类型的参数,通过m.eval()来冻结
# 固定参数
for name, param in model.named_parameters():
if 'conv' in name:
params.requires_grad = False
# 冻结BN层
for m in model.modules():
if isinstance(m, nn.BatchNorm2d):
m.eval()
for p in m.parameters():
p.requires_grad = False
# 或者
def freeze_bn(m):
if isinstance(m, nn.BatchNorm2d):
m.eval()
for p in m.parameters():
p.requires_grad = False
model.apply(freeze_bn)
# 过滤掉不需要更新的参数
optimizer = optim.SGD(filter(lambda p: p.requires_grad, model.parameters()), lr=0.0001)2.reproducibility 可复现性
如果不固定随机数种子,网络每次的初始化参数会不同,每次得到的结果也会不同。
| 方法 | 描述 |
|---|---|
| random.seed(0) | random随机数种子 |
| np.random.seed(0) | numpy随机数种子 |
| torch.manual_seed(0) | cpu随机数种子 |
| torch.cuda.manual_seed(0) | 为当前gpu设置随机数种子 |
| torch.cuda.manual_seed_all(0) | 为所有gpu设置随机数种 |
def set_random_seed(seed, deterministic=False):
"""Set random seed.
Args:
seed (int): Seed to be used.
deterministic (bool): Whether to set the deterministic option for
CUDNN backend, i.e., set `torch.backends.cudnn.deterministic`
to True and `torch.backends.cudnn.benchmark` to False.
Default: False.
"""
random.seed(seed)
np.random.seed(seed)
torch.manual_seed(seed)
torch.cuda.manual_seed_all(seed)
if deterministic:
torch.backends.cudnn.deterministic = True
torch.backends.cudnn.benchmark = Falsetorch.backends.cudnn.deteministic: 设为True时,cuDNN会使用固定的卷积算法
torch.backends.cudnn.benchmark: 当不需要复现时,设为True,cuDNN会选择最优的算法来提升性能;反之cuDNN会选择固定的算法