aws服务器
The whitepaper on AWS Serverless Application Lens is a treasure trove of information on how to correctly design a serverless application on AWS. However, if you are short on time and want a gist of the whitepaper, this article aims to provide that for you. Although in order to become an AWS serverless ninja, the whitepaper, especially the links included in it are highly recommended.
关于AWS无服务器应用程序的白皮书是关于如何在AWS上正确设计无服务器应用程序的信息宝库。 但是,如果您时间紧缺并且想要白皮书的要旨,那么本文旨在为您提供该白皮书。 尽管为了成为AWS无服务器忍者,还是强烈建议白皮书,尤其是其中包含的链接。
总览 (Overview)
Following is an overview of all the services that are generally included in a serverless architecture. It is assumed that the reader knows the general functionality of each of these services.
以下是无服务器体系结构中通常包含的所有服务的概述。 假定读者了解这些服务中每一项的一般功能 。
设计原则 (Design Principles)

无服务器架构 (Serverless Architectures)
RESTful微服务 (RESTful Microservices)
Here API Gateway provides built-in authorization, throttling, security, fault tolerance, request/response mapping, and performance optimizations by using features like caching. Lambda provides the business logic and DynamoDB serves as a scalable data storage. In case there is no business logic, for e.g. CRUD Operations, Lambda could / should be omitted from this architecture allowing API Gateway to connect directly to DynamoDB. Use the API Gateway logging to understand consumer access patterns / behaviors.
API网关通过使用诸如缓存之类的功能提供内置的授权 , 限制 , 安全性 , 容错 , 请求/响应映射以及性能优化。 Lambda提供业务逻辑,而DynamoDB充当可伸缩数据存储 。 如果没有业务逻辑,例如CRUD Operations ,则可以/应该从此体系结构中省略Lambda,以允许API网关直接连接到DynamoDB。 使用API网关日志记录来了解使用者访问模式/行为。

网络应用 (Web Applications)
This architecture is very similar to the RESTful microservices architecture. The extra elements here are S3, Cloudfront and Cognito. Cognito is used for authentication and as a directory service. Cloudfront is used for secure and fast delivery of the static content stored on S3.
该体系结构与RESTful微服务体系结构非常相似。 这里的额外元素是S3 , Cloudfront和Cognito 。 Cognito用于身份验证和目录服务。 Cloudfront用于安全,快速地交付存储在S3上的静态内容 。

行动后端 (Mobile Backend)
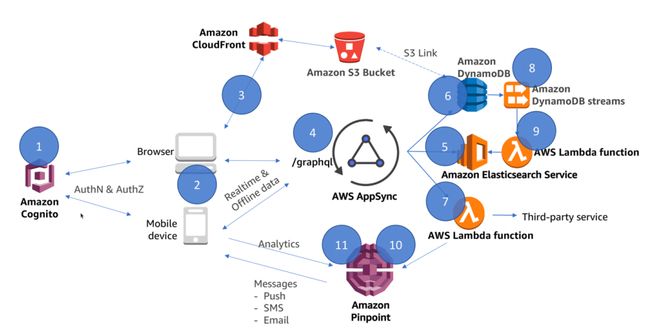
Amazon Cognito is used for user management and as an identity provider for your mobile application. Amazon S3 stores static assets that are served securely via CloudFront. AWS AppSync hosts GraphQL HTTP requests and responses to mobile users. Here the data from AWS AppSync is real-time when devices are connected, and data is available offline as well. Data sources for this scenario are DynamoDB, Elasticsearch and Lambda. DynamoDB provides persistent storage for your mobile application, including mechanisms to expire unwanted data from inactive mobile users through a Time to Live (TTL) feature. The Lambda function handles interaction with other third-party services, or calling other AWS services for custom flows. Amazon Pinpoint captures analytics from clients and is used as a customer engagement tool.
Amazon Cognito用于用户管理,并用作您的移动应用程序的身份提供者。 Amazon S3存储可通过CloudFront安全提供服务的静态资产。 AWS AppSync托管GraphQL HTTP请求和对移动用户的响应。 在这里,连接设备后,来自AWS AppSync的数据是实时的,数据也可以脱机使用。 此方案的数据源是DynamoDB , Elasticsearch和Lambda 。 DynamoDB为您的移动应用程序提供持久存储,包括通过生存时间 (TTL)功能使非活动移动用户的不需要的数据过期的机制。 Lambda函数处理与其他第三方服务的交互,或为自定义流调用其他AWS服务 。 Amazon Pinpoint会从客户那里捕获分析数据,并用作客户参与工具。
流处理 (Stream Processing)
Data producers use the Amazon Kinesis Producer Library (KPL) to send streaming data to a Kinesis stream. Amazon Kinesis Agent and custom data producers that leverage the Kinesis API can also be used. Lambda acts as a consumer of the stream that receives an array of the ingested data as a single event/invocation. Further processing is carried out by the Lambda function. The transformed data is then stored in a persistent storage, which, in this case, is DynamoDB.
数据生产者使用Amazon Kinesis生产者库 (KPL)将流数据发送到Kinesis流。 也可以使用利用Kinesis API的 Amazon Kinesis Agent和自定义数据生产者。 Lambda充当流的使用者,该流接收作为单个事件/调用的摄取数据数组。 Lambda函数执行进一步的处理。 然后,将转换后的数据存储在持久性存储中,在这种情况下,该存储为DynamoDB 。

无服务器数据处理 (Serverless Data Processing)
Certain transformations can be done in directly in Firehose, for e.g Apache Log/System logs to CSV, JSON; JSON to Parquet or ORC. For other transformations, use lambda.
某些转换可以直接在Firehose中完成,例如将Apache Log / System日志转换为CSV,JSON; JSON到Parquet或ORC。 对于其他转换,请使用lambda。

具有状态更新的无服务器事件提交 (Serverless Event Submission with Status Updates)
For long and complex workflows, you can integrate API Gateway or AWS AppSync with Step Functions that upon new authorized requests will start this business workflow. Step Functions responds immediately with an execution ID to the caller (Mobile App, SDK, web service, etc.). For legacy systems, you can use the execution ID to poll Step Functions for the business workflow status via another REST API. With WebSockets whether you’re using REST or GraphQL, you can receive business workflow status in real-time by providing updates in every step of the workflow.
对于冗长而复杂的工作流程 ,您可以将API Gateway或AWS AppSync与Step Functions集成在一起,然后在收到新的授权请求后便会启动此业务工作流程。 Step Functions立即以执行ID响应调用方(移动应用,SDK,Web服务等)。 对于旧系统 ,您可以使用执行ID通过另一个REST API来轮询Step Functions以获取业务工作流状态。 无论您使用的是REST还是GraphQL,使用WebSockets,您都可以通过在工作流的每个步骤中提供更新来实时接收业务工作流状态。

Another common scenario is adding SQS or Kinesis as a scaling layer.
另一个常见方案是添加SQS或Kinesis作为缩放层。

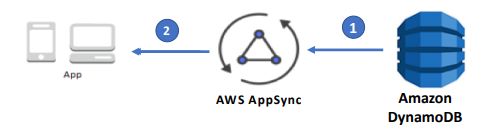
Use AppSync’s ability to provide data mutations updates through subscriptions
使用AppSync的功能通过订阅提供数据突变更新
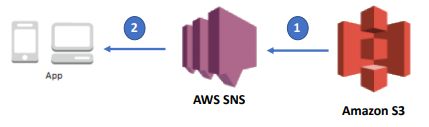
SNS can call back an HTTP endpoint (webhook) via a POST method upon an event, for e.g. S3
SNS可以在事件发生时通过POST方法回调HTTP端点(webhook),例如S3
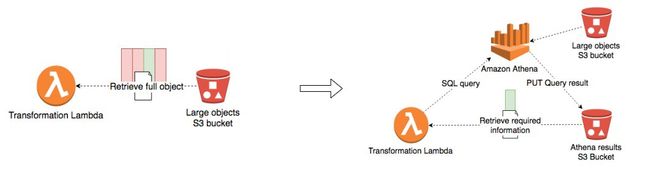
通过转换获取大数据 (Large data retrieval with transformations)
If you use lambda for transformation of a large amount of data where a lot of data is getting filtered out during transformation (represented by red blocks in the left diagram), a better design is to use Amazon Athena to filter out the data first and then load only the required data into lambda (the diagram on the right). Here one could also use S3 Select instead of Athena.
如果您使用lambda进行大量数据的转换,而在转换过程中大量数据被过滤掉(由左图中的红色块表示),则更好的设计是使用Amazon Athena首先过滤掉数据,然后再使用仅将所需的数据加载到lambda中(如右图所示)。 这里也可以使用S3 Select代替Athena。
发展Alexa技能 (Developing Alexa Skills)
One of the most important steps in Alexa Skills design is to start with a voice interaction model or a design script as shown below:
Alexa Skills设计中最重要的步骤之一是从语音交互模型或设计脚本开始,如下所示:
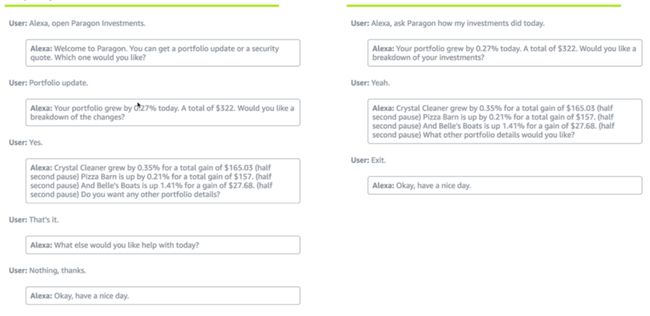
Once the script is available, you should outline things like shortest route to completion (as shown above), alternate paths and decision trees, account linking process etc.
脚本可用后,您应该概述诸如完成任务的最短路径 (如上所示) ,备用路径和决策树,帐户链接过程等内容。
The general architecture involves ASK (Alexa Skills kit) and various serverless components like Lambda and DynamoDB. Alexa Custom Skill is used to create a custom interaction model using Lambda which interacts with DynamoDB for persisting / reading user data like state and session, whereas Alexa Smart Home Skill allows you to control devices such as lights, thermostats, smart TVs, etc. using the Smart Home API. Amazon S3 stores your skills static assets including images, content, and media. Its contents are securely served using CloudFront. Account Linking is needed when your skill must authenticate with another system. This action associates the Alexa user with a specific user in the other system.
通用体系结构涉及ASK (Alexa技能套件)和各种无服务器组件,例如Lambda和DynamoDB。 Alexa自定义技能用于使用Lambda创建自定义交互模型,该Lambda与DynamoDB进行交互以持久化/读取状态和会话等用户数据,而Alexa Smart Home Skill允许您使用以下控件控制设备,例如灯光,恒温器,智能电视等。智能家居API。 Amazon S3存储您的技能静态资产,包括图像,内容和媒体。 使用CloudFront可以安全地提供其内容。 当您的技能必须通过另一个系统进行身份验证时,需要帐户关联 。 此操作将Alexa用户与另一个系统中的特定用户相关联。

部署方式 (Deployment approaches)
The recommended approaches for deployment in the microservice architecture are all-at-once, blue/green and Canary / Linear. The following table shows a comparison between these:
在微服务架构中推荐的部署方法是一次性,蓝/绿和Canary / Linear 。 下表显示了它们之间的比较:

All-at-once is low-effort and can be made with little impact in low-concurrency models, it adds risk when it comes to rollback and usually causes downtime. An example scenario to use this deployment model is for development environments where the user impact is minimal.
一次性操作很省力,在低并发模型中几乎不会产生任何影响,它在回滚时增加了风险,通常会导致停机。 使用此部署模型的示例场景用于用户影响最小的开发环境。
Blue/Green Deployments requires two environments, the blue (older version) and the green (the new version). Since API Gateway allows you to define what percentage of traffic is shifted to a particular environment; this style of deployment can be an effective technique.
蓝色/绿色部署需要两个环境,蓝色(旧版本)和绿色(新版本)。 由于API Gateway允许您定义将多少百分比的流量转移到特定环境; 这种部署方式可能是一种有效的技术。
Canary Deployments don’t require two seperate environments while still allowing to transfer a certain percentage of the traffic to a new version of the application. With Canary deployments in API Gateway, you can deploy a change to your backend endpoint (for example, Lambda) while still maintaining the same API Gateway HTTP endpoint for consumers.
Canary部署不需要两个单独的环境,同时仍然允许将一定百分比的流量传输到应用程序的新版本。 使用API Gateway中的Canary部署,您可以将更改部署到后端终结点(例如Lambda),同时仍为使用者维护相同的API Gateway HTTP终结点。
Important: Lambda allows you to publish one or more immutable versions for individual Lambda functions; such that previous versions cannot be changed. Each Lambda function version has a unique Amazon Resource Name (ARN) and new version changes are auditable as they are recorded in CloudTrail. As a best practice in production, customers should enable versioning to best leverage a reliable architecture.
重要提示 :Lambda允许您为单个Lambda函数发布一个或多个不可变版本; 这样就无法更改以前的版本。 每个Lambda函数版本都有一个唯一的Amazon资源名称(ARN),并且新版本更改可以记录在CloudTrail中,因此可以审核。 作为生产中的最佳实践,客户应启用版本控制以最佳利用可靠的体系结构。
结构完善的框架 (Well-Architected Framework)
The following section digresses from the whitepaper approach a bit by not showing the five pillars (Operational Excellence, Security, Reliability, Performance efficiency and Cost optimization) separately and how to achieve them using different services. The approach taken is rather to show how each service contributes to the different pillars.
下一节与白皮书的方法略有不同,没有分别显示五个Struts(运营卓越,安全性,可靠性,性能效率和成本优化),以及如何使用不同的服务来实现它们。 所采用的方法是显示每种服务如何为不同的Struts做出贡献。
计算层 (Compute Layer)
拉姆达 (Lambda)
Reliability — In order to ensure reliability of the system, throttling is a necessary step thereby ensuring that downstream functionalities don’t get overburdened. Lambda invocations that exceed the concurrency set of an individual function will be throttled by the AWS Lambda Service and the result will vary depending on their event source — Synchronous invocations return HTTP 429 error, Asynchronous invocations will be queued and retried while Stream-based event sources will retry up to their record expiration time. But why Concurrency limits? Because the backend systems might have scaling or other limitations (for e.g. connection pools). Further it also allows for critical path services to have higher priority, provides protection against DDoS attacks and allows for disabling a function by setting concurrency to zero.
可靠性 —为了确保系统的可靠性, 节流是必不可少的步骤,从而确保下游功能不会负担过多。 超出单个功能的并发集的Lambda调用将受到AWS Lambda服务的限制,其结果将取决于其事件源-同步调用返回HTTP 429错误,异步调用将排队并重试,而基于Stream的事件源将重试其记录的到期时间 。 但是为什么并发限制呢? 因为后端系统可能具有扩展性或其他限制(例如,连接池)。 此外,它还允许关键路径服务具有更高的优先级,提供针对DDoS攻击的保护,并通过将并发设置为零来禁用功能 。

Note: For asynchronous processing, use Kinesis Data Streams to effectively control concurrency with a single shard as opposed to Lambda function concurrency control. This gives you the flexibility to increase the number of shards or the parallelization factor to increase concurrency of your Lambda function.
注意:对于异步处理,与Lambda函数并发控制相反,使用Kinesis Data Streams通过单个分片有效地控制并发。 这使您可以灵活地增加分片数或并行化因子,以增加Lambda函数的并发性。
Another important factor for reliability is failure management. Use Lambda Destinations to send contextual information about errors, stack traces, and retries into dedicated Dead Letter Queues (DLQ), such as SNS topics and SQS queues. When consuming from Kinesis or DynamoDB streams, use Lambda error handling controls, such as maximum record age, maximum retry attempts, DLQ on failure, and Bisect batch on function error, to build additional resiliency into your application.
可靠性的另一个重要因素是故障管理 。 使用Lambda目标将有关错误,堆栈跟踪和重试的上下文信息发送到专用的死信队列( DLQ ),例如SNS主题和SQS队列。 在使用Kinesis或DynamoDB流时,请使用Lambda错误处理控件,例如最长记录寿命,最大重试次数,失败时的DLQ和功能错误时的Bisect批处理 ,以在应用程序中建立额外的弹性。
Performance Efficiency — Test different memory settings as CPU, network, and storage IOPS are allocated proportionally. Include the Lambda function in a VPC only when necessary.
性能效率 —测试不同的内存设置,因为CPU,网络和存储IOPS是按比例分配的。 仅在必要时在VPC中包括Lambda函数。

Set your function timeout a few seconds higher than the average execution to account for any transient issues in downstream services. This process is critical as too high a timeout may result in extra costs in case the code is malfunctioning!
将您的函数超时设置为比平均执行时间高几秒钟,以解决下游服务中的所有瞬时问题。 此过程至关重要,因为如果代码出现故障,超时时间过长可能会导致额外的费用 !
If your Lambda function accesses a resource in your VPC, launch the resource instance with the no-publicly-accessible option (avoid DNS resolution of public host names).
如果Lambda函数访问VPC中的资源,请使用no-publicly-accessible选项启动资源实例(避免对公共主机名进行DNS解析)。
Cost Optimization — As Lambda proportionally allocates CPU, network, and storage IOPS based on memory, the faster the execution, the cheaper and more value your function produces due to 100-ms billing incremental dimension. It uses CloudWatch Logs to store the output of the executions to identify and troubleshoot problems on executions as well as monitoring the serverless application. These will impact the cost in the CloudWatch Logs service in two dimensions: ingestion and storage. Thus it is important to set appropriate logging levels and remove unnecessary logging. Also use environment variables to control application logging level and sample logging in DEBUG mode.
成本优化 —随着Lambda根据内存按比例分配CPU,网络和存储IOPS,由于100毫秒的计费增量维度,执行速度更快 ,功能更便宜 ,价值更高。 它使用CloudWatch Logs存储执行的输出,以识别执行中的问题并对其进行故障排除,以及监视无服务器应用程序。 这些会影响在CloudWatch的日志服务的费用在两个方面: 摄入和储存 。 因此,重要的是设置适当的日志记录级别并删除不必要的日志记录。 还可以使用环境变量来控制应用程序日志记录级别和DEBUG模式下的示例日志记录。
For long-running tasks where a lot of waiting is involved, use Step Functions instead of Lambda. The use of global variables to maintain connections to your data stores or other services and resources will increase performance and reduce execution time, which also reduces the cost.
对于涉及大量等待的长时间运行的任务,请使用“步函数”而不是Lambda。 使用全局变量维护与数据存储或其他服务和资源的连接将提高性能并减少执行时间,这也降低了成本。
API网关 (API Gateway)
Security — There are currently four mechanisms to authorize an API call within API Gateway: AWS IAM authorization, Amazon Cognito user pools, API Gateway Lambda authorizer and Resource policies. AWS IAM authorization is for consumers who currently are located within your AWS environment or have the means to retrieve AWS Identity and Access Management (IAM) temporary credentials to access your environment. Lambda authorizer is to be used when you already have an Identity Provider (IdP).
安全性 -当前有四种机制可在API网关内授权API调用: AWS IAM授权,Amazon Cognito用户池,API网关Lambda授权方和资源策略 。 AWS IAM授权适用于当前位于您的AWS环境中或可以检索AWS Identity and Access Management(IAM)临时凭证以访问您的环境的使用者。 当您已经有身份提供者 (IdP)时,将使用Lambda授权 者 。
If you don’t have an IdP, you can leverage Amazon Cognito user pools to either provide built-in user management or integrate with external identity providers, such as Facebook, Twitter, Google+, and Amazon. Amazon API Gateway resource policies are JSON policy documents that can be attached to an API to control whether a specified AWS Principal can invoke the API. This allows fine-grained control like allowing / denying certain IPs or VPCs etc.
如果没有IdP,则可以利用Amazon Cognito用户池提供内置的用户管理或与外部身份提供商(例如Facebook,Twitter,Google +和Amazon)集成。 Amazon API Gateway 资源策略是JSON策略文档,可以将其附加到API以控制指定的AWS Principal是否可以调用该API。 这允许进行细粒度的控制,例如允许/拒绝某些IP或VPC等。
Important: Lambda authorizers and Cognito user pools can also be created and managed in a separate account and then re-used across multiple APIs managed by API Gateway.
重要提示 :Lambda授权者和Cognito用户池也可以在一个单独的帐户中创建和管理,然后在由API Gateway管理的多个API中重复使用。
Reliability — Throttling should be enabled at the API level to enforce access patterns established by a service contract. Returning the appropriate HTTP status codes within your API (such as a 429 for throttling) helps consumers plan for throttled access by implementing back-off and retries accordingly. You can also issue API keys to consumers with usage plans in addition to global throttling to have more granular control.
可靠性 -应该在API级别启用限制以强制执行由服务合同建立的访问模式。 在API中返回适当的HTTP状态代码(例如用于限制的429)可通过实施退避并相应地重试来帮助消费者计划受限制的访问。 除了全局限制之外,您还可以通过使用计划向使用方发出API密钥 ,以进行更精细的控制。
Note: The API keys are NOT a security mechanism to authorize requests, but rather provides you with additional metadata associated with the consumers and requests.
注意:API密钥不是授权请求的安全机制,而是为您提供了与使用者和请求关联的其他元数据。
Performance Efficiency — Use Edge endpoints for geographically dispersed customers. Use Regional for regional customers and when using other AWS services within the same Region.
性能效率 —将Edge端点用于地理位置分散的客户。 对于区域客户以及在同一区域内使用其他AWS服务时,请使用“区域”。
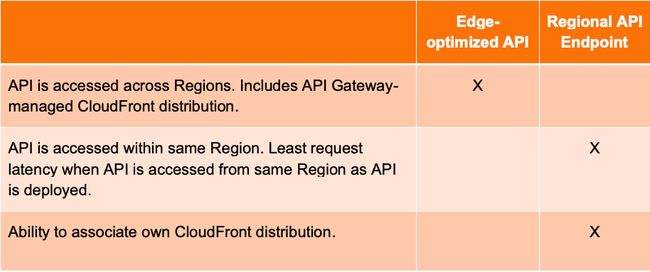
Also make sure that the caching is enabled. Enable content encoding (for compressing the payload).
另外,请确保已启用缓存 。 启用内容编码 (用于压缩有效负载)。
步骤功能 (Step Functions)
Reliability — Step Functions state machines increase reliability of synchronous parts of your application that are transaction-based and require rollback, since it can implement the saga pattern.
可靠性 -步骤功能状态机提高了应用程序基于事务且需要回滚的同步部分的可靠性,因为它可以实现传奇模式。
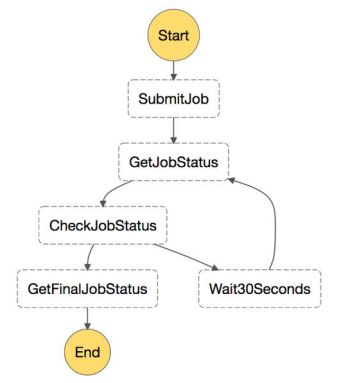
Cost Optimization — For long running task(s), employ the wait state. For example if we start an AWS Batch job and poll it every 30 seconds to see if it has finished, it is better to use step function to implement a poll (GetJobStatus) + wait (Wait30Seconds) + decider (CheckJobStatus). The pricing model for Step Functions is based on transitions between states and thus wont incur cost for wait.
成本优化 —对于长时间运行的任务,请使用等待状态。 例如,如果我们启动一个AWS Batch作业并每30秒对其进行轮询以查看其是否完成,则最好使用step函数来实现轮询(GetJobStatus)+等待(Wait30Seconds)+决策程序(CheckJobStatus)。 步骤功能的定价模型基于状态之间的转换,因此不会产生等待成本。
资料层 (Data Layer)
DynamoDB (DynamoDB)
Performance Efficiency — Use on-demand for unpredictable application traffic, otherwise provisioned mode for consistent traffic. DAX can improve read responses significantly as well as Global and Local Secondary Indexes to prevent full table scan operations.
性能效率 - 按需使用以应对不可预测的应用程序流量,否则采用预 配置模式以保持一致的流量。 DAX可以显着改善读取响应以及全局和本地二级索引,以防止全表扫描操作。
AWS AppSync (AWS AppSync)
Performance Efficiency — Make sure that the caching is enabled.
性能效率 —确保已启用缓存 。
消息传递和流传输层 (Messaging and Streaming Layer)
运动学 (Kinesis)
Performance Efficiency — Use enhanced-fan-out for dedicated input/output channel per consumer in multiple consumer scenarios. Use an extended batch window for low volume transactions with Lambda.
性能效率 —在多个消费者场景中,使用增强型扇出功能为每个消费者提供专用的输入/输出通道。 将扩展的批处理窗口用于Lambda的小批量交易。
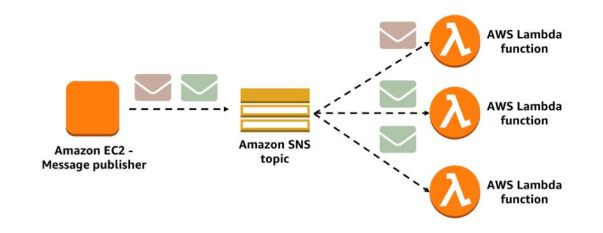
社交网络 (SNS)
Cost Optimization — SNS can filter events based on message attributes and more efficiently deliver the message to the correct subscriber, thus avoiding unnecessary invocations.
成本优化 — SNS可以根据消息属性过滤事件,并更有效地将消息传递给正确的订户,从而避免不必要的调用。
监控和部署层 (Monitoring and Deployment Layer)
CloudWatch (CloudWatch)
Operational Excellence — Amazon CloudWatch provides automated cross service and per service dashboards to help you understand key metrics for the AWS services that you use. For custom metrics, use Amazon CloudWatch Embedded Metric Format to log a batch of metrics that will be processed asynchronously by CloudWatch without impacting the performance of your Serverless application. Some important types of metrics that should be considered:
卓越的运营 -Amazon CloudWatch提供自动化的跨服务和按服务的仪表板,以帮助您了解所使用的AWS服务的关键指标。 对于自定义指标,请使用Amazon CloudWatch 嵌入式指标格式记录一批指标,这些指标将由CloudWatch 异步处理,而不会影响无服务器应用程序的性能。 应考虑的一些重要类型的指标:
Business metrics — Orders placed, debit/credit card operations, flights purchased, etc
业务指标 -下订单,借记/信用卡操作,购买的航班等
Customer Experience Metrics — Perceived latency, time it takes to add an item to a basket or to check out, page load times, etc
客户体验指标 -感知的延迟,将项目添加到购物篮或检出所需的时间,页面加载时间等
System metrics — Percentage of HTTP errors/success, memory utilization, function duration/error/throttling, queue length, stream records length, integration latency, etc
系统指标 -HTTP错误/成功率,内存利用率,函数持续时间/错误/限制,队列长度,流记录长度,集成延迟等百分比
Operational metrics — Number of tickets (successful and unsuccessful resolutions, etc.), number of times people on-call were paged, availability, CI/CD pipeline stats (successful/failed deployments, feedback time, cycle and lead time, etc.)
操作指标 —票证数量(成功和失败的解决方案等),呼叫者被寻呼的次数,可用性,CI / CD管道统计信息(成功/失败的部署,反馈时间,周期和交付时间等)
CloudWatch Alarms should be configured at both individual and aggregated levels. Standardize your application logging to emit operational information about transactions, correlation identifiers, request identifiers across components, and business outcomes. Below is an example of a structured logging using JSON as the output:
CloudWatch警报应配置为单个级别和聚合级别。 标准化您的应用程序日志记录,以发出有关事务,关联标识符,跨组件的请求标识符以及业务结果的操作信息。 以下是使用JSON作为输出的结构化日志记录的示例:

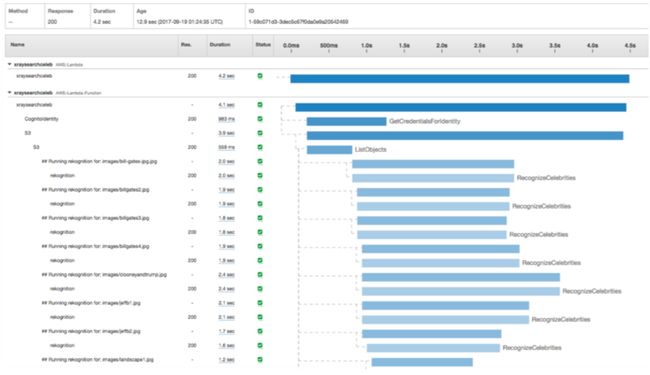
AWS X射线 (AWS X-Ray)
Operational Excellence — Active tracing with AWS X-Ray should be enabled to provide distributed tracing capabilities as well as to enable visual service maps for faster troubleshooting. X-Ray helps you identify performance degradation and quickly understand anomalies, including latency distributions.
卓越的运营 —应启用AWS X-Ray的主动跟踪功能,以提供分布式跟踪功能,并启用可视服务图,以便更快地进行故障排除。 X射线可帮助您识别性能下降并快速了解异常情况,包括延迟分布。

X-Ray also provides two powerful features that can improve the efficiency on identifying anomalies within applications: Annotations and Subsegments. Subsegments are helpful to understand how application logic is constructed and what external dependencies it has to talk to. Annotations are key-value pairs with string, number, or Boolean values that are automatically indexed by AWS X-Ray.
X-Ray还提供了两个强大的功能,可以提高在应用程序内识别异常的效率: 注释和子段 。 子段有助于了解如何构造应用程序逻辑以及必须与之对话的外部依赖关系。 注释是具有字符串,数字或布尔值的键值对,它们由AWS X-Ray自动索引。

你要知道! (You gotta know!)
Direct Integrations — Never use Lambda just for transport, only use it for transformation, i.e. if the Lambda function is not performing custom logic while integrating with other AWS services, chances are that it may be unnecessary. For e.g. you can directly connect the API Gateway to DynamoDB for simple CRUD applications, or connect the API Gateway to Kinesis Firehose to send data to S3, using AWS Service proxy feature. Another possiblity would to connect the client directly to Kinesis Firehose using the SDK.
直接集成 -切勿仅将Lambda用于传输,仅将其用于转换,即,如果Lambda函数在与其他AWS服务集成时未执行自定义逻辑 ,则可能没有必要。 例如,您可以使用AWS Service代理功能将API网关直接连接到DynamoDB以用于简单的CRUD应用程序,或者将API网关连接到Kinesis Firehose以将数据发送到S3。 另一个可能性是使用SDK将客户端直接连接到Kinesis Firehose 。
For service-to-service communication, favor dynamic authentication, such as temporary credentials with AWS IAM over static keys. API Gateway and AWS AppSync both support IAM Authorization that makes it ideal to protect communication to and from AWS services.
对于服务到服务的通信,建议使用动态身份验证 ,例如使用AWS IAM的临时凭证而非静态密钥。 API Gateway和AWS AppSync都支持IAM授权,因此非常适合保护与AWS服务之间的通信。
When synchronous calls are necessary, it’s recommended at a minimum to ensure that the total execution time doesn’t exceed the API Gateway or AWS AppSync maximum timeout.
如果需要同步调用,建议至少确保总执行时间不超过API Gateway或AWS AppSync最大超时 。
AWS SDKs provide back-off and retry mechanisms by default when talking to other AWS services that are sufficient in most cases. However, review and tune them to suit your needs, especially HTTP keepalive, connection, and socket timeouts.
与大多数情况下足够的其他AWS服务进行通信时,默认情况下,AWS开发工具包默认提供退避和重试机制。 但是,请检查并调整它们以适合您的需求,尤其是HTTP keepalive,连接和套接字超时 。
For low-latency requirements where near-to-none business logic is required, Amazon Cognito Federated Identity can provide scoped credentials so that your mobile application can talk directly to an AWS service, for example, when uploading a user’s profile picture, retrieve metadata files from Amazon S3 scoped to a user, etc.
对于需要几乎没有业务逻辑的低延迟要求, Amazon Cognito联合身份可以提供范围凭证,以便您的移动应用程序可以直接与AWS服务对话,例如,在上载用户的个人资料图片,检索元数据文件时从Amazon S3扩展到用户等
Consider reviewing limits for burst and spiky use cases. For example, API Gateway and Lambda have different limits for steady and burst request rates.
考虑查看突发和尖刻用例的限制。 例如,API网关和Lambda对于稳定和突发请求速率具有不同的限制。
In case polling is required between two systems, establish an SLA regarding how often the polling is done. There are two common patterns to ensure that clients aren’t polling more frequently than expected: Throttling and Timestamp for when is safe to poll again.
如果需要在两个系统之间进行轮询,请建立有关轮询频率的SLA。 有两种常见的模式可以确保客户端轮询的频率不会超出预期: 节流和时间戳记何时可以安全地再次轮询。
AWS AppSync can be used to automatically provision DynamoDB Tables from a GraphQL schema. It also provides fine-grained access controls which can be used to filter GraphQL requests down to per-user or group level.
AWS AppSync可用于从GraphQL模式自动设置 DynamoDB表。 它还提供了细粒度的访问控制 ,可用于将GraphQL请求过滤到每个用户或组级别 。
When not using KPL(Kinesis Producer Library), make certain to take into account partial failures for nonatomic operations, such as PutRecords, since the Kinesis API returns both successfully and unsuccessfully processed records upon ingestion time.
当不使用KPL (Kinesis Producer库)时,请确保考虑非原子操作(例如PutRecords)的部分失败,因为Kinesis API在摄取时会返回成功和未成功处理的记录。
For single-page web applications, use AWS Amplify Console to manage atomic deployments, cache expiration, custom domain, and user interface (UI) testing.
对于单页 Web应用程序 ,请使用AWS Amplify Console来管理原子部署,缓存过期,自定义域和用户界面(UI)测试。
For configuration management, use environment variables for infrequent changes, such as logging level and database connection strings. Use AWS System Manager Parameter Store for dynamic configuration, such as feature toggles, and store sensitive data using AWS Secrets Manager.
对于配置管理 ,请使用环境变量进行不频繁的更改 ,例如日志记录级别和数据库连接字符串。 使用AWS System Manager参数存储进行动态配置 (例如功能切换),并使用AWS Secrets Manager存储敏感数据 。
Integrate application dependency vulnerability scans like OWASP Dependency Check within your CI/CD pipeline.
在CI / CD管道中集成应用程序依赖项漏洞扫描,例如OWASP Dependency Check 。
For workloads that require outbound traffic filtering due to compliance reasons, proxies can be used in the same manner that they are applied in non-serverless architectures.
对于由于合规性原因而需要进行出站流量筛选的工作负载,可以使用与在非无服务器架构中应用代理相同的方式来使用代理。
翻译自: https://medium.com/swlh/aws-serverless-application-lens-a-summary-4f740c4f376d
aws服务器