GPU底层优化 | 如何让Transformer在GPU上跑得更快?
来源:计算机视觉研究院

计算机视觉研究院专栏
作者:Edison_G
Transformer 对计算和存储的高要求阻碍了其在 GPU 上的大规模部署。在本文中,来自快手异构计算团队的研究者分享了如何在 GPU 上实现基于 Transformer 架构的 AI 模型的极限加速,介绍了算子融合重构、混合精度量化、先进内存管理、Input Padding 移除以及 GEMM 配置等优化方法。



图 1:基于 Transformer 架构的 NLP 模型规模


图 2:基于 Transformer 架构的应用

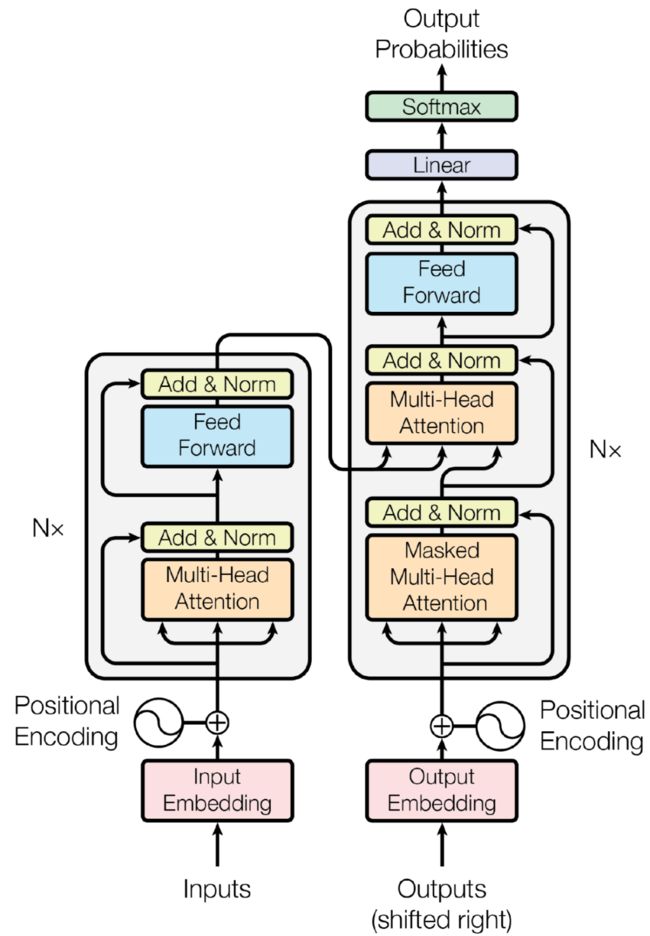
图 3:Transformer 模型的架构

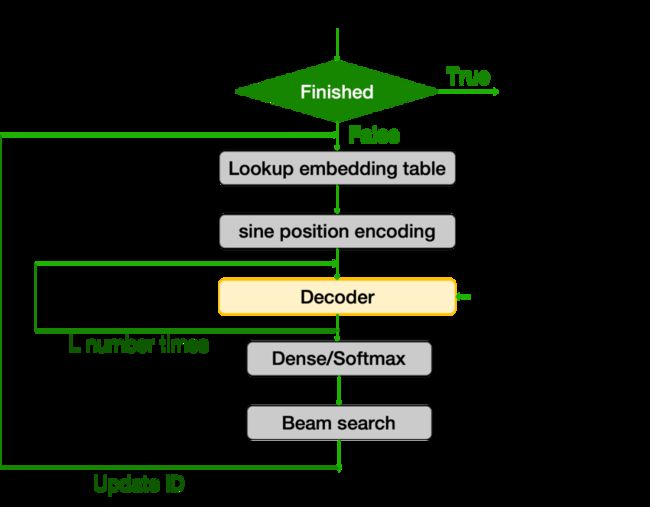
图 4:Beam Search Decoding (Decoder + Beam Search) 流程图

Transformer 家族模型
根据具体模型架构和应用的不同,研究者将 Transformer 家族的模型分为四大类(如图 5):
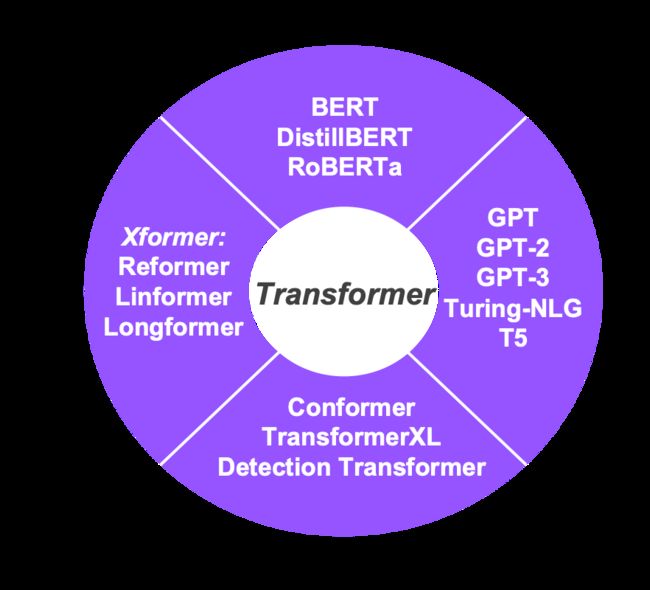
图 5:经典的基于 Transformer 结构的 AI 模型




图 6:Transformer 架构中 Self-attention 和 Feedforward 模块的 CUDA kernel 融合和重构,参见[14]


图 7:Transformer FP16 版本的几个关键 CUDA kernel 采用的量化精度


图 8:Transformer CUDA 实现的内存管理



图 9:输入 Padding 移除的方案 - 通过引入 Offset Mask,移除 Padding 的 Sequence 和原始的 Sequence 可以互相转换重建


图 10:通过对 CUDA Kernel 的分类判断是否可以移除 Padding


图 11:Transformer GEMM 配置的优化
总结

参考文献
[1] M. Luong et al, Effective Approaches to Attention-based Neural Machine Translation, arXiv:1508.04025v5 (2015).
[2] A. Vaswani et al. Attention is all you need, Advances in neural information processing systems (2017).
[3] J. Devlin et al. Bert: Pre-training of deep bidirectional transformers for language understanding, arXiv:1810.04805 (2018).
[4] A. Radford et al. Language Models are Unsupervised Multitask Learners, 2019.
[5] https://www.microsoft.com/en-us/research/blog/turing-nlg-a-17-billion-parameter-language-model-by-microsoft/
[6] C. Raffe et al. Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer, arXiv:1910.10683v3 (2019).
[7] T. Brown et al, Language Models are Few-Shot Learners, arXiv: 2005.14165v4 (2020).
[8] N. Carion et al, End-to-End Object Detection with Transformers, arXiv: 2005.12872 (2020).
[9] M. Chen et al, Generative Pretraining from Pixels, ICML (2020).
[10] F. Yang et al, Learning Texture Transformer Network for Image Super-Resolution, CVPR (2020).
[11] D. Zhang et al, Feature Pyramid Transformer, ECCV (2020).
[12] Y. Zhao et al, The SpeechTransformer for Large-scale Mandarin Chinese Speech Recognition. ICASSP 2019.
[13] A. Gulati et al, Conformer: Convolution-augmented Transformer for Speech Recognition, arXiv:2005.08100v1 (2020).
[14] https://github.com/NVIDIA/DeepLearningExamples/tree/master/FasterTransformer
© THE END
推荐阅读
PyTorch深度学习技术生态
麻省理工喊你来上课,深度学习课程,关键还是免费资源!
如何看待Transformer在CV上的应用前景,未来有可能替代CNN吗?


