【数据库开发】国产数据库之达梦DM
文章目录
- 1、简介
- 2、达梦线上实验室
-
- 2.1 查看达梦数据库运行状态
- 2.2 查看达梦数据库版本
- 2.3 创建用户并授权
-
- 2.3.1 创建用户
- 2.3.2 授予用户基本权限
- 2.3.3 查看用户信息
- 2.4 切换用户
-
- 2.4.1 切换到DM用户
- 2.4.2 查看当前登录用户
- 2.5 创建表并添加约束
-
- 2.5.1 创建表
- 2.5.2 添加表约束
- 2.5.3 查看表结构
- 2.5.4 查看表主键外键
- 2.6 验证数据表 CRUD 功能
-
- 2.6.1 插入数据
- 2.6.2 修改数据
- 2.6.3 验证更新表记录能力
- 2.6.4 删除数据
- 2.7 批量插入及选择排序
-
- 2.7.1 批量插入数据
- 2.7.2 查看插入数据
- 2.7.3 排序数据
- 2.8 验证分组查询
-
- 2.8.1 插入准备数据
- 2.8.2 分组查询
- 2.9 创建视图
-
- 2.9.1 定义视图
- 2.9.2 通过视图简化查询
- 2.10 创建索引
-
- 2.10.1 创建普通索引
- 2.10.2 查看创建的索引
- 2.10.3 删除索引
- 2.11 体验事务特性
-
- 2.11.1 插入数据并创建保存点
- 2.11.2 更新数据记录
- 2.11.3 不提交查看数据记录
- 2.11.4 回滚到保存点
- 2.11.5 验证保存点特性
- 2.12 序列
-
- 2.12.1 创建序列
- 2.12.2 查询下一个序列号
- 2.12.3 查询当前序列号
- 2.13 创建物化视图
-
- 2.13.1 定义物化视图
- 2.13.2 查看物化视图
- 2.13.3 表中插入数据
- 2.13.4 验证物化视图特性
- 2.14 创建函数
-
- 2.14.1 创建生成随机数函数
- 2.14.2 调用函数生成随机数
- 2.15 存储过程
-
- 2.15.1 创建存储过程
- 2.15.2 调用存储过程
- 2.15.3 查看上浮后的薪资
- 2.16 触发器
-
- 2.16.1 创建表级触发器
- 2.16.2 更新表数据
- 2.17 分区表
-
- 2.17.1 创建间隔分区表
- 2.17.2 插入数据
- 2.17.3 查询分区信息
- 2.17.4 检索某个分区数据
- 2.17.5 插入数据,自动新增分区表
- 2.18 WITH 子句
-
- 2.18.1 定义 WITH FUNCTION 子句
- 2.18.2 定义 WITH AS 子句
- 结语
1、简介
https://www.dameng.com/
达梦数据库管理系统(DM8)
新一代大型通用关系型数据库,全面支持 ANSI SQL 标准和主流编程语言接口/开发框架。行列融合存储技术,在兼顾 OLAP 和 OLTP 的同时,满足 HTAP 混合应用场景。

https://www.modb.pro/dbRank
国产数据库排行榜,墨天轮国产数据库流行度排行于2019年6月推出,通过50个左右维度的数据来考察近200个国产数据库的流行度排行,每月1日更新排行数据,用于体现国产数据库的流行度。


2、达梦线上实验室
如果您是初次接触达梦数据库,我们强烈建议您加入本次线上实验室的试玩旅程。在这里,您将置身于达梦公司自主研发的新一代大型通用关系型数据库 DM8 的仿真环境中,通过 “用户权限”,“操作数据表”,“检索数据”,“创建索引”,“事务特性” 五大板块,初步体验 DM8 的基本特性。同时我们也提供了创建物化视图、存储过程等一系列“SQL 高级特性”供高级玩家探索。
https://www.dameng.com/list_103.html
https://eco.dameng.com/tour/?source_url=https://www.dameng.com/list_103.html

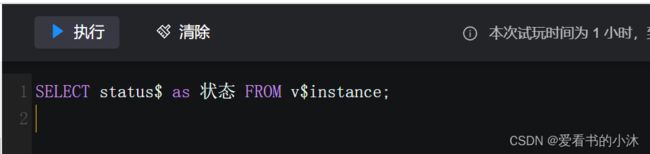
2.1 查看达梦数据库运行状态
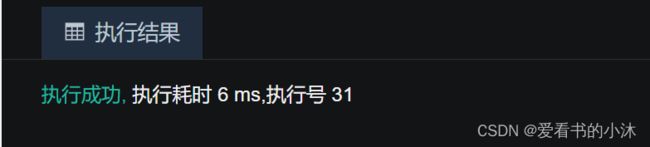
SELECT status$ as 状态 FROM v$instance;

2.2 查看达梦数据库版本
SELECT banner as 版本信息 FROM v$version;


2.3 创建用户并授权
默认以 sysdba 用户进入试玩页面,按步骤创建你的专属普通用户并授权。
2.3.1 创建用户
使用 CREATE USER 语句创建用户"爱看书的小沐",登录密码为 “123456789”。
CREATE USER 爱看书的小沐 IDENTIFIED BY "123456789";

2.3.2 授予用户基本权限
使用 GRANT 语句给 用户“爱看书的小沐”授予 RESOURCE 角色;
GRANT RESOURCE TO 爱看书的小沐;

给 用户“爱看书的小沐”授予 dmhr 用户下 employee 表的 select 权限;
GRANT SELECT ON dmhr.employee TO 爱看书的小沐;


给 用户“爱看书的小沐”授予 dmhr 用户下 department 表的 select 权限;
GRANT SELECT ON dmhr.department TO 爱看书的小沐;


2.3.3 查看用户信息
通过字典表 dba_users 查看基本信息。
SELECT username,account_status,created FROM dba_users
WHERE username='爱看书的小沐';


SELECT username,account_status,created FROM dba_users;


2.4 切换用户
需从 sysdba 用户切换到 DM 用户.
2.4.1 切换到DM用户
使用 conn 命令切换用户。
conn 爱看书的小沐/123456789;


2.4.2 查看当前登录用户
使用 user 关键字返回当前登录用户。
SELECT user FROM DUAL;

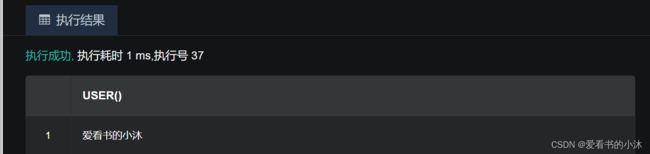
若服务器返回当前登录用户是"爱看书的小沐" ,则用户切换成功.
2.5 创建表并添加约束
用户"爱看书的小沐" 登录成功后,先完成数据表创建.
2.5.1 创建表
使用 CREATE TABLE 语句创建 employee 表。
CREATE TABLE employee
(
employee_id INTEGER,
employee_name VARCHAR2(20) NOT NULL,
hire_date DATE,
salary INTEGER,
department_id INTEGER NOT NULL
);


使用 CREATE TABLE 语句创建 department 表。
CREATE TABLE department
(
department_id INTEGER PRIMARY KEY,
department_name VARCHAR(30) NOT NULL
);
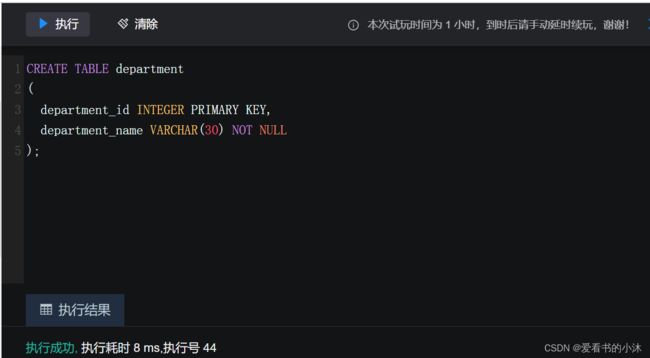
2.5.2 添加表约束
使用 ALTER TABLE 语句给表增加非空约束。
ALTER TABLE employee MODIFY( hire_date not null);


使用 ALTER TABLE 语句给表增加主键约束。
ALTER TABLE employee ADD constraint pk_empid
PRIMARY KEY(employee_id);


使用 ALTER TABLE 语句给表增加外键约束。
ALTER TABLE employee ADD constraint fk_dept FOREIGN KEY
(department_id) REFERENCES department (department_id);


2.5.3 查看表结构
使用 desc 语句查看表结构。
DESC employee;

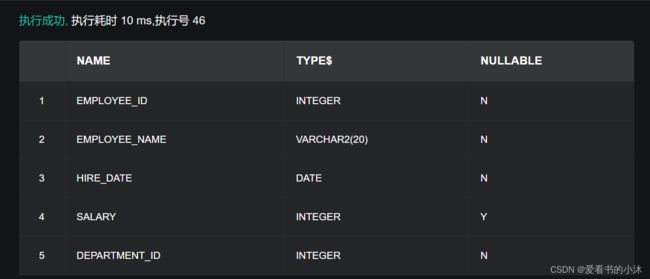
2.5.4 查看表主键外键
通过系统表 all_constraints 查看自定义的主键、外键。
SELECT table_name, constraint_name, constraint_type FROM
all_constraints WHERE owner='爱看书的小沐' AND table_name='EMPLOYEE';

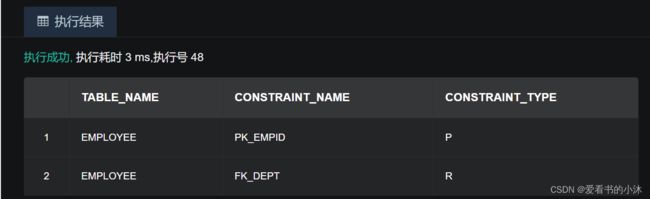
2.6 验证数据表 CRUD 功能
达梦数据库支持完整的 CRUD 基本操作。
2.6.1 插入数据
使用 INSERT INTO 语句向 department 表插入数据记录。
INSERT INTO department VALUES(666001, '研发中心');
INSERT INTO department VALUES(666002, '销售中心');
INSERT INTO department VALUES(666003, '行政中心');
INSERT INTO department VALUES(101, '研发中心2');


select * from department


使用 INSERT INTO 语句向 employee 表插入数据记录。
INSERT INTO employee VALUES
(910001, '小沐','2022-10-07 00:00:00', 5000, 666001);
INSERT INTO employee VALUES
(910002, '戈戈','2022-10-05 00:00:00', 5500, 666002);
INSERT INTO employee VALUES
(910003, '狄狄','2022-10-02 00:00:00', 6500, 666003);
SELECT * FROM employee;

插入数据后,使用 commit 语句提交事务。
commit;
因为 employee 员工表和 department 部门表存在主外键约束,所以此示例中须按顺序执行插入语句,即先在 department 表中插入数据。
2.6.2 修改数据
使用 UPDATE 语句更新表数据。
UPDATE employee SET salary='3000' WHERE employee_id=10001;


更新数据后,使用 commit 语句提交事务。
commit;
2.6.3 验证更新表记录能力
在修改数据记录并提交事务后 ,查看更新后的结果。
SELECT salary,employee_id FROM employee;
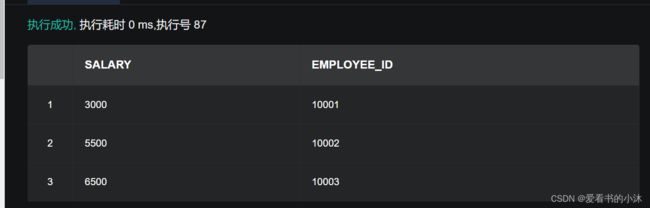
2.6.4 删除数据
使用 DELETE FROM 语句删除表数据。
DELETE FROM employee;
使用 DELETE FROM 语句删除表中满足条件的数据。
DELETE FROM department WHERE department_id=666003;


删除数据后,使用 commit 语句提交事务。
commit;
2.7 批量插入及选择排序
达梦数据库支持各种数据检索功能。
2.7.1 批量插入数据
在 t1 表中批量插入 123456条数据记录。
CREATE TABLE t1 AS
SELECT rownum AS id,
trunc(dbms_random.value(0, 100)) AS random_id,
dbms_random.string('x', 20) AS random_string
FROM dual
connect BY level <= 123456;

2.7.2 查看插入数据
SELECT COUNT(*) FROM t1;

2.7.3 排序数据
SELECT * FROM t1 where rownum<100 ORDER BY id DESC;

2.8 验证分组查询
2.8.1 插入准备数据
INSERT INTO department (department_id, department_name)
SELECT department_id, department_name FROM dmhr.department;


commit;
使用 INSERT INTO 语句在 employee 表中插入批量数据。
INSERT INTO employee
(employee_id, employee_name, hire_date, salary, department_id)
SELECT employee_id, employee_name, hire_date, salary,
department_id FROM dmhr.employee;


commit;
2.8.2 分组查询
使用 GROUP BY、HAVING 语句实现分组过滤。
SELECT dept.department_name as 部门, count(*) as 人数
FROM employee emp, department dept
where emp.department_id=dept.department_id
GROUP BY dept.department_name
HAVING count(*) > 20;


2.9 创建视图
2.9.1 定义视图
例如需要查询薪资大于 10000 且入职时间大于等于 2013 年 8 月 1 日 员工的部门名称、姓名、薪资、入职时间。
使用 CREATE OR replace VIEW 语句定义视图 v1。
CREATE OR replace VIEW v1 AS
SELECT dept.department_name, emp.employee_name,
emp.salary,emp.hire_date
FROM employee emp, department dept
WHERE salary > 10000
AND hire_date >= '2013-08-01'
AND emp.department_id = dept.department_id;

2.9.2 通过视图简化查询
使用 视图 v1 检索数据。
SELECT * FROM v1 WHERE hire_date > '2014-10-23';

2.10 创建索引
2.10.1 创建普通索引
使用 CREATE INDEX 语句创建普通索引。
CREATE INDEX ind_emp_salary ON employee(salary);

2.10.2 查看创建的索引
通过字典表 user_indexes 查看已创建索引的名称、类型。
SELECT table_name, index_name, index_type
from user_indexes WHERE index_name='IND_EMP_SALARY';

2.10.3 删除索引
使用 DROP INDEX 语句删除索引。
DROP INDEX IND_EMP_SALARY;
2.11 体验事务特性
2.11.1 插入数据并创建保存点
在 employee 表中插入一条数据记录。
INSERT INTO employee VALUES
(910004, '爱看书的小沐', '2022-05-30 00:00:00', 3555, 101);

使用 SAVEPOINT 语句创建保存点。
SAVEPOINT my_insert;

2.11.2 更新数据记录
使用 UPDATE 语句更新数据记录,不提交。
UPDATE employee SET department_id=102 WHERE employee_id=910004;

2.11.3 不提交查看数据记录
使用 SELECT 语句查看在不提交状态下的数据记录。

2.11.4 回滚到保存点
使用 ROLLBACK TO 语句回滚到保存点 my_insert。
ROLLBACK TO my_insert;

2.11.5 验证保存点特性
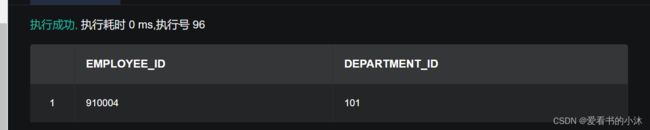
在回滚保存点成功后,再次查看数据记录,验证保存点特性,事务会回滚到保存点的状态。
SELECT employee_id, department_id FROM employee
WHERE employee_id=910004;
2.12 序列
2.12.1 创建序列
使用 CREATE SEQUENCE 语句创建序列。
CREATE SEQUENCE SEQ1_xiaomu
START WITH 1 INCREMENT BY 1 MAXVALUE 10000
CACHE 5 NOCYCLE;

2.12.2 查询下一个序列号
SELECT seq1_xiaomu.nextval() FROM dual;

2.12.3 查询当前序列号
SELECT seq1_xiaomu.currval() FROM dual;

2.13 创建物化视图
2.13.1 定义物化视图
使用 CREATE MATERIALIZED VIEW 语句定义物化视图。 刷新方式:完全;刷新时机:基表数据提交。
CREATE MATERIALIZED VIEW mv1_xiaomu BUILD IMMEDIATE REFRESH
COMPLETE ON COMMIT AS
SELECT department_id as 部门号, count(*) as 人数
FROM employee GROUP BY department_id;

2.13.2 查看物化视图
使用物化视图 mv1_xiaomu 检索数据。
SELECT * FROM mv1_xiaomu WHERE 部门号='101';

2.13.3 表中插入数据
在 employee 表中插入一条数据记录,验证物化视图特性。
INSERT INTO employee VALUES(910005, '小羊',
'2022-05-31 00:00:00', 1800, 101);
commit;


2.13.4 验证物化视图特性
SELECT * FROM mv1_xiaomu WHERE 部门号='101';

2.14 创建函数
2.14.1 创建生成随机数函数
使用 CREATE OR REPLACE FUNCTION 语句创建函数。
CREATE OR REPLACE FUNCTION random_xiaomu
(pass_len IN NUMBER) RETURN VARCHAR2 AS
l_pw VARCHAR2(128);
BEGIN l_pw = dbms_random.string('x', pass_len);
RETURN l_pw;
END;

2.14.2 调用函数生成随机数
SELECT random_xiaomu(12) FROM dual;

2.15 存储过程
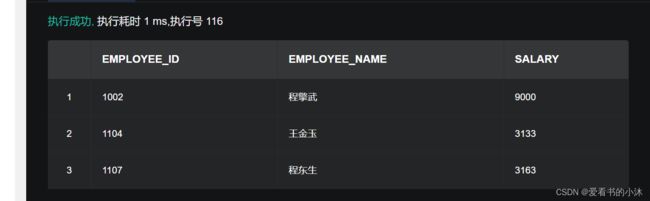
2.15.1 创建存储过程
使用 SELECT 语句查询 102 部门所有员工入职时间大于 2012 年 3 月 1 日 的员工上浮前的薪资。
SELECT employee_id, employee_name, salary
FROM 爱看书的小沐.employee
WHERE department_id=102 AND hire_date >= to_date
('2012-03-01 00:00:00', 'yyyy-mm-dd hh24:mi:ss');
使用 CREATE OR REPLACE PROCEDURE 语句创建存储过程 proc。
CREATE OR REPLACE PROCEDURE proc
(dept_in 爱看书的小沐.employee.department_id%TYPE, hire_in varchar2(24))
AS CURSOR by_dept_cur IS
SELECT * FROM 爱看书的小沐.employee WHERE department_id=dept_in;
BEGIN FOR rec IN by_dept_cur
LOOP
IF rec.hire_date > to_date(hire_in, 'yyyy-mm-dd hh24:mi:ss')
THEN
UPDATE 爱看书的小沐.employee set salary=salary+salary*0.15
WHERE employee_id=rec.employee_id;
END IF;
END LOOP;
commit;
END;

2.15.2 调用存储过程
begin
proc(102, '2012-03-01 00:00:00');
end;

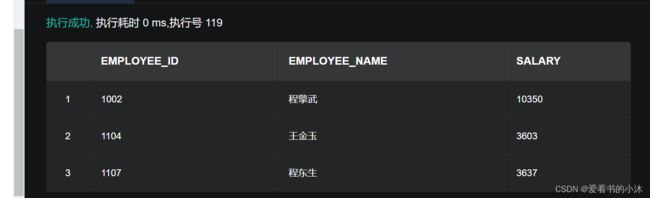
2.15.3 查看上浮后的薪资
使用 SELECT 语句查询 102 部门所有员工入职时间大于 2012 年 3 月 1 日 的员工上浮后的薪资。
SELECT employee_id, employee_name, salary FROM 爱看书的小沐.employee
WHERE department_id=102 AND hire_date >= to_date
('2012-03-01 00:00:00', 'yyyy-mm-dd hh24:mi:ss');
2.16 触发器
表级触发器是基于表中数据的触发器,它通过针对相应表对象的插入/删除/修改等 DML 语句的触发。
2.16.1 创建表级触发器
创建表 trg_xiaomu , 记录员工姓名更新前后的值。
CREATE TABLE trg_xiaomu(name_old varchar, name_new varchar);
![]()
CREATE OR REPLACE TRIGGER trg1_xiaomu
BEFORE
UPDATE OF EMPLOYEE_NAME ON employee
FOR EACH ROW
DECLARE
BEGIN
INSERT INTO trg_xiaomu VALUES(:old.employee_name,
:new.employee_name);
END;
![]()
2.16.2 更新表数据
更新编号为 1001 的员工姓名为 ‘达梦_小沐’。
UPDATE employee SET employee_name='达梦_小沐' WHERE
employee_id=1001;
commit;
SELECT name_old , name_new FROM trg_xiaomu;

2.17 分区表
2.17.1 创建间隔分区表
创建分区表 emp_part, 起始分区时间为小于 2007 年 1 月 1 日。
CREATE TABLE emp_part
(
EMPLOYEE_ID INT PRIMARY KEY,
EMPLOYEE_NAME VARCHAR(20),
IDENTITY_CARD VARCHAR(18),
EMAIL VARCHAR(50) NOT NULL,
PHONE_NUM VARCHAR(20),
HIRE_DATE DATE NOT NULL,
JOB_ID VARCHAR(10) NOT NULL,
SALARY INT,
COMMISSION_PCT INT,
MANAGER_ID INT,
DEPARTMENT_ID INT
)
PARTITION BY RANGE(hire_date)
INTERVAL (NUMTOYMINTERVAL(1,'year'))
(
PARTITION P_BEFORE_2007 VALUES less than (to_date('2007-01-01','yyyy-mm-dd'))
)
STORAGE
(
FILLFACTOR 85,
BRANCH(32,32)
);

2.17.2 插入数据
INSERT INTO emp_part SELECT * FROM dmhr.employee;
commit;

2.17.3 查询分区信息
SELECT table_name,partition_name, high_value FROM user_tab_partitions
WHERE table_name='EMP_PART' ORDER BY high_value;

2.17.4 检索某个分区数据
按分区名称检索数据如下:
SELECT * FROM emp_part PARTITION(P_BEFORE_2007);

2.17.5 插入数据,自动新增分区表
INSERT INTO emp_part(EMPLOYEE_ID,EMPLOYEE_NAME,IDENTITY_CARD,EMAIL,
PHONE_NUM,HIRE_DATE,JOB_ID,SALARY,COMMISSION_PCT,MANAGER_ID,DEPARTMENT_ID)
VALUES(9990,'小沐2022','340102196202303999','[email protected]','110',
'2022-05-30','11',1500.00,0,1001,101);
commit;
SELECT table_name,partition_name, high_value FROM user_tab_partitions
WHERE table_name='EMP_PART' ORDER BY high_value;

2.18 WITH 子句
2.18.1 定义 WITH FUNCTION 子句
通过员工编号获取对应的薪资。
WITH FUNCTION GetSalary(emp_id INT) RETURN INT AS
DECLARE
sal int;
BEGIN
SELECT salary into sal FROM dmhr.employee WHERE employee_id=emp_id;
RETURN sal;
END;
SELECT GetSalary(2001) FROM DUAL;

2.18.2 定义 WITH AS 子句
例如:统计入职时间最早和最迟的员工的编号、姓名和入职时间。
WITH t AS (
SELECT MAX(hire_date) max_hd, MIN(hire_date) min_hd FROM dmhr.employee)
SELECT employee_name, employee_id, hire_date FROM dmhr.employee
WHERE hire_date IN
(
SELECT t.max_hd FROM t
UNION ALL
SELECT t.min_hd FROM t
);
结语
如果您觉得该方法或代码有一点点用处,可以给作者点个赞,或打赏杯咖啡;╮( ̄▽ ̄)╭
如果您感觉方法或代码不咋地//(ㄒoㄒ)//,就在评论处留言,作者继续改进;o_O???
如果您需要相关功能的代码定制化开发,可以留言私信作者;(✿◡‿◡)
感谢各位大佬童鞋们的支持!( ´ ▽´ )ノ ( ´ ▽´)っ!!!