AAAI2020/风格迁移:Ultrafast Photorealistic Style Transfer via Neural Architecture基于神经结构搜索的超快逼真风格转移
AAAI2020/风格迁移:Ultrafast Photorealistic Style Transfer via Neural Architecture基于神经结构搜索的超快逼真风格转移
- 0.摘要
- 1.概述
- 2.相关工作
-
- 2.1.风格迁移
- 2.2.图像到图像的翻译
- 2.3.讨论
- 3.预分析
-
- 3.1.特征聚合
- 3.2.跳跃链接
- 3.3.多风格
- 3.4.Concat v.s. Sum
- 3.5.Upsampling v.s. Unpooling
- 3.6.WCT v.s. AdaIN
- 4.C-Step
- 5.P-Step
-
- 5.1.搜索空间
- 5.2.搜索目标
- 5.3.搜索策略
- 6.实验结果
-
- 6.1.目视对比
- 6.2.定量对比
- 6.3.计算时间对比
- 7.结论
- 附录A:通过艺术风格转移的方法实现更加逼真的风格化效果
- 附录B:预分析的更多结果
-
- 特征聚合
- 跳跃连接
- 多风格
- Concat v.s.Sum
- Upsampling v.s. Unpooling
- WCT v.s. AdaIN
- 附录C: P-Step细节
-
- StyleNAS算法的实现细节
- StyleNAS的实验设置
- 更多由StyleNAS搜索的架构
- StyleNAS搜索效果分析
- NAS融合分析
- 附录D:用户研究
- 附录E:风格化效果控制
- 附录F:逼真的视频传输
- 附录G:我们的失败案例
论文下载
开源代码
0.摘要
真实感风格转换的关键挑战是,算法应该忠实地将参考照片的风格转换为内容照片,而生成的图像应该看起来像相机捕捉到的图像。虽然已经提出了一些照片逼真风格的转移算法,但它们需要依赖于后处理和/或预处理,以使生成的图像看起来逼真。如果我们禁用额外的处理,这些算法将无法在细节保存和照片真实感方面产生似是而非的逼真风格化。在这项工作中,我们提出了这些问题的有效解决方案。我们的方法由构造步(C-step)和加速步(P-step)组成,前者用于构建逼真的风格化网络。在c步中,我们提出了一个基于精心设计的预分析的密集自编码器PhotoNet。PhotoNet集成了特征聚合模块(BFA)和实例归一化跳过链路(INSL)。为了生成真实的风格化图像,我们在解码器和INSLs中引入了多种样式传输模块。PhotoNet在效率和有效性方面都明显优于现有算法。在p步中,我们采用神经结构搜索方法来加速PhotoNet。在师生学习模式下提出了一种自动网络修剪框架,实现了逼真的风格化。从研究中得到的网络架构PhotoNAS在保持风格化效果几乎完整的同时,比PhotoNet实现了显著的加速。我们对图像和视频传输进行了大量的实验。结果表明,与现有的先进方法相比,我们的方法可以在获得20-30倍的加速度的情况下产生良好的结果。值得注意的是,该算法在不进行任何预处理和后处理的情况下取得了较好的性能
1.概述
逼真风格转换是一种图像编辑任务,旨在改变照片的风格,以给定的参考。为了逼真,生成的图像应该保留输入的空间细节,看起来像相机捕获的照片。例如,在图1中,我们将夜间视图照片从暖色转换为冷色,而在另一个示例中,将白天的照片转换为夜间的照片。在这些例子中,输入内容的场景在生成的结果中保持完整。不幸的是,艺术风格转移方法(Gatys, Ecker,和Bethge 2015;2016;Johnson, Alahi,和飞飞2016;Ulyanov等2016;Li等2017;黄和Belongie 2017;Sheng et al. 2018;Li et al. 2019)通常扭曲图像中的精细细节(线条、形状、边界),这是在艺术场景中产生艺术风格所必需的,但在摄影现实风格化中不受欢迎。我们用WCT的例子来说明艺术方法在真实感风格化案例中的失败。1 (b).补充材料中有更多失效案例
图1:逼真风格转换结果。给定(a)一个输入对(Ic:内容,Is:样式),我们展示(b) WCT (Liet al. 2017), © PhotoWCT (Liet al. 2018), (d) WCT2(Yoo et al. 2019)和(e)我们的方法的结果。每个结果都是在没有区域掩模和/或后处理的协助下产生的,以进行公平的比较。虽然比较的方法产生了明显的空间扭曲,提出的方法在细节保存和照片真实感方面获得了更好的风格转移结果
Luanet al.在Gatyset al.(Gatys, Ecker, and Bethge 2016)的基础上,Luanet al.(Luan et al. 2017)引入了一个photorealtic损失项,并采用优化方法进行风格转移。然而,求解优化问题需要大量的时间和计算。为了解决这个问题,Lietal提出PhotoWCT (Li et al. 2018),它使用前馈网络进行风格转移。尽管PhotoWCT应用了多级风格化并使用去池算子代替上采样来增强网络的细节保存,但生成的结果仍然存在如图1 ©所示的失真。为了克服剩余的伪象,他们必须引入紧密形式的后处理和区域掩模(如果有的话)来调节图像的空间亲和力。然而,这样的后处理计算量大,导致结果过于平滑。最近,Yooet al.(Yoo et al. 2019)提出了小波校正迁移Wavelet Corrected Transfer(WCT2),旨在消除后处理步骤,同时保留传输照片的精细细节。虽然使用小波可以提高信号恢复的保真度,但WCT2还需要依靠内容和参考风格照片的区域掩码来进行风格转移。如果这样的区域掩码被禁用,如图所示。1 (d), WCT2的结果出现了明显的失真。由于对于任意的照片很难获得这样的区域掩码(通常必须训练特定的网络来分割输入的照片并手动微调分割结果),PhotoWCT和WCT2的实际使用是有限的。
在网络架构方面,PhotoWCT和WCT2都采用相同的对称自编码器,但使用不同的下采样和上采样模块。然而,专门为逼真风格传输设计的一般网络架构还没有得到很好的研究。这项工作填补了这一空白。具体地说,我们的算法包括一个网络构建步骤(C-step),引入一个高效的自编码器来实现逼真的程式化,然后采用一个修剪步骤(P-step)来压缩自编码器以实现加速。在C-step中,我们首先进行了精心设计的预分析,并根据分析结果引入了瓶颈特征聚合(BFA)和实例归一化跳过链接(INSL)两个架构模块。BFA,受(Yu etal。2018;Zhao等人。2017),采用多分辨率深度特征来改善逼真的程式化效果。INSLis是源自U-Net (Ronneberger, Fischer, and Brox 2015)的跳跃式连接(SC)和实例规范化(Ulyanov, Vedaldi, and lemmit -sky 2016)的结合。INSL实现了高保真度的信息恢复,同时避免了使用SCs时出现的“短路”现象。基于这些模块,我们构建了一个具有BFA和密集放置INSLs的非对称自编码器(photonet)。由于提出的模块,我们的PhotoNet在精细细节保存方面优于DPST (Luan等人。2017),PhotoWCT和WCT2。在P-step中,我们提出了一个师生学习的神经架构搜索框架(即StyleNAS)。PhotoNet是我们NAS搜索空间中的最大架构,其中采用进化算法(Kim et al. 2017)迭代修剪PhotoNet中的可移动算子(除VGG编码器和最小基本算子外的任何算子,以形成解码器)。在体系结构研究的每个循环中,我们首先突变20个新的体系结构。每个体系结构都包含一个预先训练的VGG-19 (Simonyan和Zisser-man 2014),作为编码器和解码器被训练来重建图像。在训练之后,一个验证过程被适应,每个架构的性能通过其与oracle结果的相似性来评估(即PhotoNet)。为了压缩网络结构,我们在此基础上引入了网络复杂度损失来惩罚耗时的网络,最终得到了一组高效有效的网络,用于逼真的风格传输。本文选取了其中的一种photonas进行比较,并在补充材料中列出了更多的检索结构和结果
2.相关工作
2.1.风格迁移
在计算机视觉领域,图像样式转换已经做出了很大的努力。在采用深度神经网络之前,基于笔画绘制(Hertzmann 1998)的几个经典模型,图像类比(Hertzmann et al. 2001;Shih et al. 2013;2014;Frigo等2016;Liao等人2017),或图像过滤(Win-nem oller, Olsen,和Gooch 2006)已经被提出在风格转移的质量、概括和效率之间进行权衡。
盖提塞特等人(盖提斯,埃克,和贝奇2015;2016)首次提出将风格转移建模为一个优化问题——最小化神经网络的深度特征及其Gram矩阵,而这些网络被设计为只适合艺术风格的工作。在照片风格转换场景中,已经提出了神经网络方法(Luan等人2017;Li等人2018)来实现逼真风格的风格转换。这些方法要么引入基于平滑的损失项(Luan et al. 2017),要么利用后处理来平滑传输的图像(Li et al.2018),这不可避免地减少了图像的精细细节,显著增加了时间消耗。最近,Yooetal。(Yoo et al. 2019)提出了WCT2,它允许在没有低效后处理的情况下传输环形逼真风格。然而,WCT2必须借助区域掩模,而区域掩模难以获得,从而限制了其实际应用。
2.2.图像到图像的翻译
除了风格转移,在图像对图像的翻译中,也对照片真实感风格化进行了研究(Isola et al. 2017;Wang et al. 2018;Liu and Tuzel 2016;Taigman, Polyak,和Wolf 2017;Shrivastava等人2017;Liu, Breuel和Kautz 2017;朱等等。2017;黄等人。2018)。真实感风格转换与图像间翻译的主要区别在于,真实感风格转换不需要成对的训练数据(即转换前和转换后的图像)。当然,图像对图像的翻译可以解决更复杂的问题,如男人对女人和猫对狗的适应问题
2.3.讨论
与我们的研究最相关的工作包括eswct、PhotoWCT和WCT2。WCT用于艺术风格化,后两者用于照片-现实风格化。与PhotoWCT相比,该方法在保证样式转移有效性的同时,避免了耗时的后处理和多轮风格化。我们的方法与wct2之间的主要区别是,提出的算法允许在没有任何通过分割内容和样式输入获得的区域掩码的帮助下传输照片样式。与PhotoWCT和WCT2相比,我们的方法产生的结果具有更高的锐度、更少的失真和显著降低的计算成本
3.预分析
为了设计有效的模块/网络,我们首先对影响风格化效果的网络结构因素进行预分析,提出有用的网络模块,以提高风格化效果。我们采用vanilla对称自动编码器作为基线。对于每个被研究的模块,我们将比较它的转移结果与基线在视觉效果和摄影真实感方面。更多的分析结果可在补充材料中获得
3.1.特征聚合
图2:有bfa和没有bfa的自动编码器之间的比较(a)是将WCT作为传输模块放置在瓶颈处的普通自动编码器,它被用作基线。(b)是装有BFAmodule的自动编码器。©为输入内容(Ic)和样式(is)图像,(d)和(e)分别为(a)和(b)产生的结果。(e)中的树包含更详细的枝叶。
特征聚合是将不同层次的深度网络产生的多尺度特征连接在一起的网络模块。特征聚合使网络能够集成来自不同视域的信息,因此可以增强发生在高级特征中的风格化的低级细节保存。在此基础上,我们在自动编码器中引入了**瓶颈特征聚合(BFA)**模块。具体来说,我们首先在VGG-Encoder中调整特征从RELU_1_1到ReLU_4_1到ReLU_5_1的大小,然后在瓶颈处将它们连接在一起。详情请参阅图2 (b)。我们分别在图2 (d)和(e)中展示了有BFA和没有BFA的网络产生的风格转移结果,这表明BFA可以保留更多的细节(例如,图2中更详细的分支和节点)。据我们所知,我们是第一个采用特征聚合模块进行风格转移任务的
3.2.跳跃链接
图3:SC、HFCS和INSL的比较。SC (d)会导致“短路”问题,从而消除基线的程型化效应©。当HFCS打开时,wct2也存在类似的失效情况(e)。提出的INSL (f)可以克服SC的副作用,同时增强细节保存。
跳跃连接(SC)是由FCN (Long, Shelhamer,和Darrell 2015)和U-Net (Ron-neberger, Fischer,和Brox 2015)首次提出的,其中SC可以显著提高他们的分割结果。然而,由于SC会使处于自动编码器瓶颈的传输模块失效,装有SC的自动编码器普遍失去了生成风格化图像的能力。我们称这种现象为“短路”现象。如图3 (d)所示,与不使用SC的图像相比,使用SC的自动编码器产生的图像完全失去了风格
化效果(如图3 ©所示)。这背后的原因放置在自动编码器底层的SCs会短路,阻碍信息流流入瓶颈处的传输模块。有趣的是,如图3 (e)所示,我们发现,如果打开他们提出的高频元件跳过链接(HFCS)并禁用输入区域掩码,wct2也无法实现化。为了解决这个问题,我们引入了InstanceNormalized Skip Links(即INSL)作为SC的替代,它在跳过连接中应用了实例规范化(Ulyanov,Vedaldi,和lemmpitsky 2016)。我们发现,INSL能有效地缓解真实感传输网络的短路现象,增强其细节保存和失真消除能力。INSLs产生的结果见图3 (f)
3.3.多风格
图4:多风格转换。(a)是WCT/PhotoWCT使用的多级风格化策略,它采用五个不同的自动编码器级联进行风格转移。(b)是我们方法的体系结构。请注意,(b)在计算成本上等于最上面蓝框中的自动编码器。从(e)到(g),我们逐步在瓶颈、解码器和INSLs处应用样式传输模块(即wct),其中MS-Dec和MS-INSL分别表示解码器和INSLs处的传输模块。如(e-g)所示,MS-Dec和MS-INSL在不牺牲内容细节的情况下增强了转移效果。请见(e-g)中叶子的颜色。
多风格化是指风格的反复转换。如图4 (a)所示,WCT和PhotoWCT采用了一种称为多级风格化的策略。他们训练了5个自动编码器,并进行了5轮由粗到细的风格化方式。与之相反,WCT2提出渐进式样式化,它使用一个单轮自动编码器,但在自动编码器的每个部分多次逐步执行样式转换模块。在WCT2之后,我们采用了单轮多程式化策略,但只在解码器和INSLs上传递特征。图4(b)说明了我们的策略。如图4 (e-g)所示,MS-Dec和MS-INSL在风格化效果方面可以显著改善所产生的结果。此外,在INSLs上应用样式传输模块(图4 (g))可以进一步消除scl引起的短路现象,增强样式化效果。
3.4.Concat v.s. Sum
图5:“Concat”和“Sum”的比较
在使用跳过链接时,“concat”和“sum”操作符的选择是影响自动编码器性能的一个因素。然而,我们发现使用“concat”与使用“sum”除了风格上的小波动外,通常没有什么具体的区别。对比请参见图5(b) ©
3.5.Upsampling v.s. Unpooling

图6:“Upsampling”和“Unpooling”的比较。
PhotoWCT认为,非池化倾向于使网络产生更少的扭曲。然而,我们发现这两个操作符在我们的设置中产生的结果几乎相同。对比请参见图6(b) ©
3.6.WCT v.s. AdaIN
图7:使用AdaIN和WCT作为迁移模块的比较。使用WCT作为迁移模块©比使用adain (b)获得了更逼真的风格化效果。
WCT和AdaIN是两个广泛使用的迁移模块,来自于艺术风格转移。如图7 (b) ©所示,WCT可以产生更可靠的转移结果。我们认为这是因为AdaIN需要用更复杂的方式训练自动编码器。然而,我们只是训练解码器重建图像,以方便接下来的修剪步骤
4.C-Step
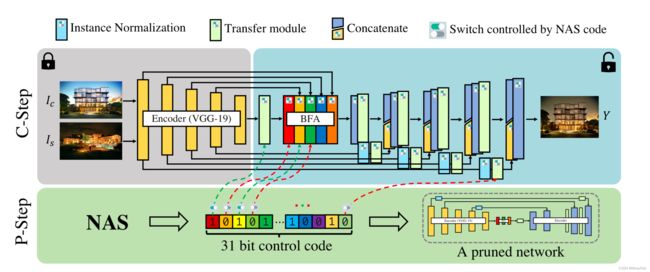
图8:提出的方法的框架。我们的方法包括c步和p步。在c步中,我们构造了一个高效的密集自编码器。在P-step中,我们提出了一种神经结构搜索(StyleNAS)算法来自动裁剪自编码器。在自动修剪的每个循环中,编码器部分(在grep框中)是固定的,而蓝框中的31个操作符由0/1代码控制关闭/打开。请注意,黄色和青色矩形表示顺序卷积运算符。
在分析对真实感风格转换效果有重要影响的架构组件的基础上,构造了一种名为PhotoNet的自动编码器。
图8中的C步部分(即灰框和蓝框)显示了PhotoNet的架构。PhotoNet的编码器是在ImageNet数据集上预训练的VGG-19。解码器被训练成将编码器的深度特征倒转回图像。在PhotoNet的瓶颈中,我们引入了一个BFA模块来利用PhotoNet的多尺度特性。在编码器和解码器之间,我们引入INSLs将信息从编码器阶段(VGG-19中的ReLU_1_1到ReLU_4_1)传输到相应的解码器层。我们的INSL有两个优点:一方面,INSL增强了PhotoNet的细节保存能力,从而提高了照片的真实感。另一方面,所配置的实例归一化可以显著地减弱跳跃式连接引起的短路问题。为了提高逼真风格的传输性能,我们在瓶颈、解码器的每个阶段密集地应用传输模块(即WCT)和INSLs。有趣的是,在INSLs进行样式转换进一步消除了跳过链接引起的短路现象。
在训练过程中,暂时移除所有传输模块,固定编码器。解码器(不含传输模块)在MSCOCO数据集上进行训练(Lin et al.2014),以将编码器的深度特征反转回图像。通过经过训练的网络,我们的PhotoNet直接将一张内容照片和一张风格照片作为输入,输出一张风格传输照片。值得一提的是,我们的PhotoNet和修剪后的版本将在下一部分介绍,不需要任何预处理区域蒙版DPST和WCT2。由于具有较强的细节保存能力,我们的方法在避免使用任何耗时的后处理的同时,对最先进的算法具有较少的失真。基于上述优点,PhotoNet实现了端到端的逼真风格转换
图4 (g)为配备完整的PhotoNet的结果。更多的结果可在补充材料中获得。值得一提的是,PhotoNet分别比WCT2(不包括制作分割掩模的时间)和PhotoWCT快7倍和107倍。
5.P-Step
为了进一步加速PhotoNet,我们提出了一个P-step,在保持PhotoNet的程式化效果的同时,自动修剪PhotoNet并发现更有效的风格传输网络以实现逼真的渲染。我们采用PhotoNet作为最大体系结构,采用师生学习的方式,引入一种名为Style-NAS的神经体系结构搜索方法进行自动修剪。将MSCOCO作为训练数据集和包含40张内容和风格照片的验证数据集,首先将PhotoNet训练为用于后续架构搜索的监督 oracle。P-step由以下三个关键部分组成。
5.1.搜索空间
我们使用装备齐全的PhotoNet及其所有简化版本(删除一些操作符)作为搜索空间。详见图8中灰色和蓝色方框(即c步部分)。在神经结构搜索的每个循环中,都保留了31个操作符选项,以形成一个功能结构,同时可以打开/关闭一个位来决定使用/禁用一个操作符。我们使用31位的字符串对该空间中的任何架构进行编码。例如,在我们的设置中,搜索的PhotoNAS架构被编码为“0101000000100000000000000001111”。通过这种方式,StyleNAS可以以组合的方式从总共231≈2.1×109个可能性中搜索新的体系结构。我们在此将搜索空间记为Θ,表示所有体系结构的全部集合。
5.2.搜索目标
为了从Θ获得高效和有效的架构,我们采用了三个搜索目标:
- 从预训练的监督视觉oracle (PhotoNet)中提取的知识的损失,
- 产生的图像和oracle的感知损失,
- 在架构中使用的操作符的百分比。知识蒸馏损失以监督的方式反映了图像重建误差。我们将整个搜索目标写成
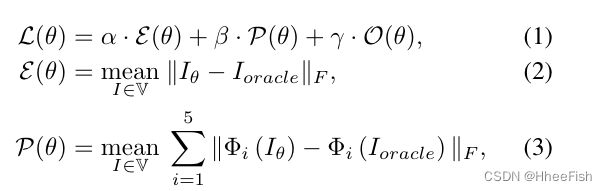
- L(θ)表示结构θ的总体损失
- E(θ)表示由由结构θ和监督oracle产生的网络产生的风格转移图像之间的重建误差;
- P(θ)估计了使用由结构θ和oracle训练的网络产生的知觉损失;
- Φi(·)表示ImageNet预训练vgg-19的第一阶段的输出O(θ)估计了31个bin的θ中算子的百分比
- α、β和γ是一对超参数,在这三个因素之间进行权衡
5.3.搜索策略
我们的搜索策略源自(Kim等人。2017),其中类似并行使用进化策略与地图减少策略的更新机制已被用于从随机初始化迭代改进搜索架构。从搜索空间, StyleNAS算法首先随机绘制P架构 {θ11,θ21,θ41…θP1}⊂Θ(表示为p31位字符串),用于第一轮迭代,其中P代表期望的总体数量。在并行计算环境之上,算法将每个绘制的架构映射到一个特定的GPU卡/工作者,然后训练风格传输网络进行图像重建(WCT模块暂时关闭),并评估训练网络的性能(使用Eq 3中的目标)。随着搜索目标的估计,每个训练工作使用评估的架构以异步方式更新一个共享集,并通过从种群集合中提取的一个结构子集中变异出最好的一个来生成一个新的结构。使用新生成的体系结构,训练工作开始新的迭代训练和评估更新,并从总体集中丢弃最老的模型。在整个过程中,算法保持一个历史架构集,这些架构已经被探索并估计了它们的目标,所有这些都是以异步的方式进行的。在对每个工作人员进行多次迭代之后,算法在算法结束时从总体历史设置中返回具有最小目标的体系结构。详情请参阅附录
6.实验结果
在本节中,我们展示了我们的a算法与最先进的逼真风格化方法的结果比较,即DPST, PhotoWCT和WCT2在视觉效果和时间消耗方面。更多的比较结果、详细的实验设置、用户研究结果、视频转换结果和我们的故障案例可在补充材料中获得。所有的源代码将在未来发布。
6.1.目视对比
图9:与最先进方法的视觉对比。(a)是输入内容(Ic)和风格(is)照片。DPST (b)和WCT2 (d)必须在区域掩模的辅助下运行(显示在左下角),PhotoWCT ©的结果是通过后处理产生的。我们的方法((e) PhotoNet, (f) PhotoNAS)不需要任何预处理和后处理
通过与DPST、PhotoWCT和WCT2的照片真实感程式化结果的比较,验证了所提方法的有效性。由于DPST和wct2的官方代码要求预先获取的区域掩码作为输入参数,因此本部分将DPST提供的图像和相应的分割掩码进行比较。此外,我们根据论文建议,在PhotoWCT中增加了两个后处理步骤。注意,我们的方法(PhotoNet和PhotoNAS)的结果不涉及任何预处理和后处理。
如图9所示,DPST的结果包含显著的伪影,并且相对过平滑。例如,上面照片中建筑物的纹理和下面照片中自行车轮子的细节被模糊化了。此外,底部图像中的墙壁和地面显示出不需要的颜色。尽管PhotoWCT (w/ smooth)(图9 ©)的结果减轻了伪影,但由于必须使用面向平滑的后处理来减少这些伪影,它们仍然存在失真和产生模糊的图像。WCT2在使用区域掩模保存细节方面较前两种方法取得了一定的进展。然而,WCT2有一个新的缺点,即生成的图像在不同区域的边界处往往存在视觉风格不匹配的问题。更糟糕的是,如果这些掩膜不够精确,WCT2往往会生成看起来是制作出来的图像,这严重损害了生成的图像的摄影真实感。请放大图9 (d),在上面的例子中看到天际线,在下面的结果中看到画在墙上的自行车轮廓。WCT2 结果看起来前景被粘贴在背景上,这是不真实的。图9 (e)和(f)显示了我们方法的结果。PhotoNet实现了有效的逼真的程式化和忠实的细节保存。PhotoNAS的结果保持了PhotoNet的风格化效果,同时进一步消除了剩余的失真。值得一提的是,PhotoNAS仅用1/5的时间就达到了这样的结果。注意PhotoNet和PhotoNAS的结果不需要任何预处理和后处理,而其他方法使用预处理(DPST, WCT2)或后处理(PhotoWCT)。无前后处理的对比如图1所示,进一步验证了我们方法的有效性。
6.2.定量对比

表2:风格化方法的定量评价结果。较高的SSIM-Edge和SSIM-Whole得分意味着被测图像在细节方面更接近于输入内容照片。较低的克损失表示评价图像的视觉效果更接近于风格照片。这里DPST和wct2的结果是在没有分割图的帮助下产生的,以便进行公平的比较。
受WCT2的启发,我们采用结构相似度(SSIM)指数来衡量方法的细节保存能力(即照片真实感)。我们对整个图像(命名为SSIM- Whole)和它们整体嵌套的边缘响应(Xie和Tu 2015)(命名为SSIM- edge)计算SSIM。为了评估逼真的风格化效果,我们在WCT之后计算Gram矩阵差(VGG无风格化)。
给定一个包含73个内容和风格照片对的验证数据集,我们定量评估的所提出的方法和最先进的方法的性能。通过在这个验证集上计算上述指标,提出了最新的方法。我们在表2中显示了定量比较结果。所提出的photonet和PhotoNAS在SSIM- Whole和SSIM-Edge方面分别取得了较好的成绩,这意味着我们的方法具有显著的细节保存能力。从表2可以看出,我们的PhotoNet的克损失略高于WCT2。我们认为这是由于细节保存的改进将不可避免地提高GramLoss。这一论断也被PhotoWCT在应用平滑后处理时的克损失大幅增加的事实所证实。
6.3.计算时间对比
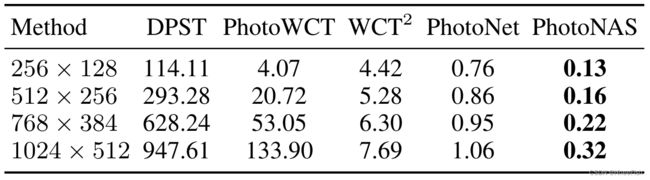
表3:计算时间的比较。
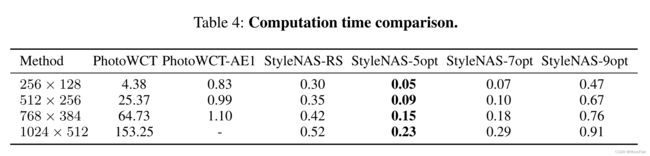
我们对最先进的方法进行了计算时间比较,以证明所提出的和搜索的网络架构的效率。所有的方法都在相同的计算平台上进行了测试,其中包括一个具有16GB RAM的NVIDIA P100 GPUcard。DPST、PhotoWCT和WCT2的时间消耗是通过使用它们的默认设置运行官方发布的代码来评估的。我们比较了不同分辨率的内容和风格图像的计算时间。如表1所示,PhotoNet 实现了比WCT2快6倍的计算速度PhotoNAS几乎比 WCT2快20-30倍。令人惊讶的是,在p步之后,搜索的操作符中只剩下7个。
7.结论
在这篇论文中,我们提出了一个两阶段的方法来解决逼真的风格转移问题。在第一步中,我们分析了常用的网络架构组件对真实感风格转换的影响。在此基础上,我们构建了PhotoNet,利用实例规范化跳过链接(INSL)、瓶颈特征聚合(BFA)以及解码器和INSLs上的多风格化,生成细节丰富、风格化良好的图像。在P-step中,我们引入了一个采用神经结构搜索(Style-NAS)方法和师生学习策略的网络修剪框架。通过新颖的修剪方法,我们发现PhotoNAS,它惊人地简单,并保持风格化效果几乎完整。我们在视觉、定量和计算时间比较方面的大量实验表明,所提出的方法在显著提高程式化效果和真实感的同时大幅减少时间消耗的能力得到了加强。我们的研究也将NAS的应用领域扩展到逼真的风格转移。在未来的工作中,我们计划1)针对风格转换任务设计新的鼻识别方法,2)将工作扩展到生成式副词网络等其他生成式模型和其他低级视觉任务。
附录A:通过艺术风格转移的方法实现更加逼真的风格化效果
图10:用艺术风格转移方法进行写实风格转移的结果。
在这一部分中,我们通过艺术风格转移的方法,展示了更多逼真的风格化结果。给定73对内容和风格的照片,我们进行了onGatys (Gatys, Ecker, and Bethge 2016)、WCT (Li et al.2017)、AdaIN (Huang and Belongie 2017)和Avatar-Net (Sheng et al. 2018)实验。如本文所述,艺术风格转移的方法并不能做出得体的逼真的风格化。我们认为这背后的原因是艺术风格转移方法倾向于追求风格照片和产生的图像之间相对较低的革兰损失(代表艺术风格相似性),这通常可以在形状、线条、颜色和纹理的相似性方面增强艺术风格转移效果。然而,这些对内容细节的不可避免的改变在逼真风格的转移场景中并不受欢迎。因此,艺术风格转移的方法往往不能产生逼真的照片。图10 (b-e)显示了使用最先进的艺术风格转移方法:Gatys、WCT、AdaIN和Avatar-Net的风格化结果。从照片真实感的风格化角度看,产生的图像具有显著的伪影和失真。相反,我们的方法(PhotoNAS)专门为照片真实感风格转移设计,产生了更逼真的程式化结果,如图10 (f)所示。
附录B:预分析的更多结果
在这一部分,我们展示了更多的预分析结果,研究有效的建筑模块,以实现逼真的风格转换。
特征聚合
图11:瓶颈特征聚合(BFA)的结果比较
我们是第一个将瓶颈特征聚合模块引入样式传输任务的。如图11。11、BFA能显著提高写真风格化效果。
跳跃连接
图12:实例规范化跳过链接(INSL)的结果比较。
正如我们的论文所述,所提出的INSL可以解决跳跃连接和WCT2中的HFCS引起的“短路”问题。图12显示了更多baseline©、baseline+SC (d)、WCT2+HFCS (e)和基线+INSL(f)的结果对比,可以看出所提出的INSL的有效性。
多风格
图13:multi - styization策略的结果比较
从图13可以看出,MS-Dec和MS-INSL在保持内容细节完整的情况下,能够增强逼真的风格化效果
Concat v.s.Sum
图14:使用Concat和Sum的结果比较。
见图14
Upsampling v.s. Unpooling
图15:使用上采样和解池的结果比较
见图15
WCT v.s. AdaIN
图16:使用WCT和AdaIN的结果比较。
见图16
附录C: P-Step细节
StyleNAS算法的实现细节

为了寻找有效而高效的网络架构以实现逼真的风格化,我们采用一种进化算法进行黑箱优化。Alg. 1显示了我们的搜索方法。在神经架构搜索过程中,我们使用多达50个GPU卡,每个新架构都在单个GPU卡上进行训练和验证。我们的搜索方法基于Nemo算法 (Kim et al. 2017)。我们发现该搜索算法足以在我们的框架中发现令人满意的网络架构。然而,使用原始Nemo的搜索过程花费了大约96小时,搜索大约190个新的架构。为了加速P-step,我们修改了Nemo算法,将提取新架构的方式从级联改为并行。这种并行策略在每个循环的初始化阶段和新架构的突变阶段都起作用。请在伪代码中查看更多细节,我们的修改用粗体标记。由于改进后的Nemo可以并行使用多张GPU卡进行新架构的训练和验证,因此它减少了2/3的时间消耗,探究同样数量的架构需要花费24小时左右的时间。理论上,这样的修改可能会使搜索结果褪色。然而,我们发现我们改进的Nemo成功地在搜索空间中找到了最好的星结构之一,同时享受了显著的时间消耗减少。由于使用NAS的巨大计算成本和时间消耗(即使在加速之后),我们不尝试其他的搜索方法。而且,该方法已经取得了令人满意的效果。但是,我们将在未来的工作中尝试其他的搜索策略
StyleNAS的实验设置
在我们报道的实验中,StyleNAS超参数设为α= 0.8,β= 0.1, γ= 0.1,以寻找高效有效的体系结构。通过本文引入的三个目标函数的线性组合,StyleNAS算法找到了一组不影响程式化效果的高效网络架构
更多由StyleNAS搜索的架构
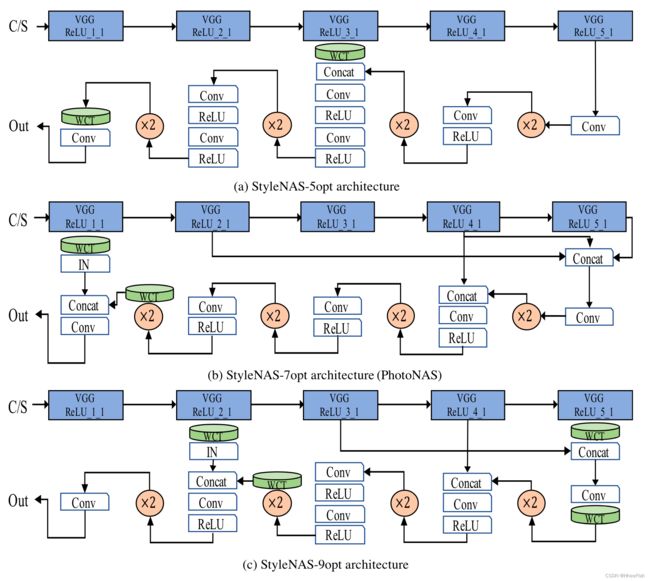
图17:搜索的体系结构:StyleNAS-5opt、StyleNAS-7opt和StyleNAS-9opt
图19©中显示的三条减少线表明,所提出的StyleNAS算法可以降低搜索结构θ中使用的算子的百分比,同时确保图像质量,即E(θ)和p (θ),没有任何妥协。我们选择了三个搜索的网络,分别是StyleNAS -5opt, StyleNAS-7opt和StyleNAS - 9opt,5、7和9个操作符在所有的操作符中分别可以移动。这些网络的体系结构如图17(b-d)所示。注意,StyleNAS-7opt是我们论文中的photonas。
作为参考,我们提供了两个基线算法来与StyleNAS进行比较:
- PhotoWCT-AE1。PhotoWCT的子架构使用PhotoWCT的第一个自动编码器(AE) (Li等人,2018年),将WCT模块放置在瓶颈处。该体系结构具有与StyleNASnetworks相似的参数规模
- StyleNAS-RS。在相同的StyleNAS搜索空间上随机搜索网络。我们随机抽取并评估了大约200个架构,其中StyleNAS-RS是整体搜索目标最低的最佳架构。
图18:逼真的风格转移结果与最先进的方法和随机搜索的建筑对比。(zoom-infor细节。)
图18展示了我们搜索的三种体系结构(即,StyleNAS-5opt, StyleNAS-7opt,和StyleNAS-9opt,通过PhotoNet作为监督oracle进行搜索)产生的样式转移图像的对比示例。我们还将结果与PhotoWCT (Liet al. 2018)、PhotoWCT- ae1和StyleNAS-RS进行了比较。从我们的视觉比较中,我们观察到PhotoWCT (Li et al.2018)生成的图像丢失了相当多的细节(shownin ©)。例如,上面的草地,中间的广告牌上的文字,下面的天空都是模糊的。StyleNAS-RS的结果(见(h))损害了程式化效果,生成的图像质量相对较差。stylenas - xopt网络(见(e-g))创建的图像具有丰富的细节,而不妥协的风格转移效果。PhotoWCT-AE1具有与搜索模型相似的时间消耗。然而,PhotoWCT-AE1无法生成逼真的图像,这证明了StyleNAS在寻找有效网络方面的强大能力。
StyleNAS搜索效果分析
实验结果表明,StyleNAS算法比随机搜索算法更有效。在我们的实验中,Style-NAS算法每轮探索20个架构。我们让stylenas搜索架构7轮。共获得140个结构。其中137个架构被评估,其余3个架构在训练中失败。我们还使用了随机搜索策略,从搜索空间中随机抽取了200个建筑。我们从两种搜索方法中选取了总体目标最低的最佳架构。从随机搜索中得到最好的答案。, StyleNAS- rs的目标函数值为0.0709,而StyleNAS中最好的StyleNAS-7opt的目标函数值为0.0472(在我们的研究中,目标函数值越小越好)。
我们还进行了定量分析,以比较StyleNAS和随机搜索得到的结构。就时间消耗而言,StyleNAS-RS对于评估的所有图像分辨率的样式转移任务花费的时间明显长于StyleNAS-7opt。而最快的网络搜索(StyleNAS-5opt)只消耗StyleNAS-RS的16% ~ 40%的时间。虽然在我们的实验中stylenas - 9opt花的时间比StyleNAS-RS长。但是,StyleNAS-9opt和StyleNAS-7opt获得的图像质量都比StyleNAS-RS好得多,如表5所示。总之,stylenas - rscan在质量和复杂性方面都没有胜过StyleNAS-7opt。详细的比较见表4。请注意StyleNAS-7opt的运行时间,即。由于这两批实验是在不同的平台上进行评估的,因此PhotoNAS与论文正文所展示的是不同的。
NAS融合分析
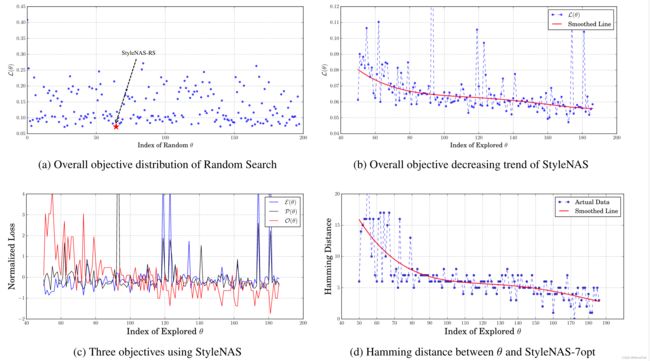
图19:StyleNAS在探索的体系结构索引上的收敛性。
StyleNAS在整体搜索目标和架构方面都可以趋同。图19(b)显示了StyleNAS的整体搜索目标随着所探索的体系结构的数量而减少。我们进一步将整体目标分解为三个部分,图19©表明,当图像质量的两个目标(即。,重建误差和感知损失)在较低的水平上得到保证,第三个目标——操作员的数量在一般意义上减少。StyleNAS搜索网络的趋势表明,所探索的体系结构的规模越来越小,而风格化的效果并不妥协。
我们发现通过StyleNAS搜索的架构也会趋同。我们以stylenas -7光学体系结构的二进制代码为参考,用二进制代码估计历史上所有探索过的体系结构设置到stylenas -7opt的汉明距离。图19(d)通过简单的进化NAS策略提供了在搜索空间中收敛的第一个证据
附录D:用户研究

我们进行了用户研究,主观上论证了所提出的PhotoNAS的有效性。我们随机选择25张内容风格照片对,评价照片真实感风格转换方法。我们收集了DPST (Luan等人2017)、PhotoWCT (Liet等人2018)、WCT2(Yoo等人2019)和我们的PhotoNAS(即stylenas -7opt)的逼真风格化结果,没有任何预处理和后处理以进行公平的比较。我们设计了一个网页,让用户投票他们最喜欢的结果和我们收集统计投票结果。对于每个内容和风格对,我们以匿名随机顺序并排显示DPST、PhotoWCT、WCT2和我们的Pho-toNAS结果,让受试者选择伪影少、失真少、细节多的最佳结果。我们总共获得了180张选票。表5总结了选择的偏好百分比,这表明PhotoNAS比DPST, PhotoWCT和wct2的结果在更少的伪影,更少的失真和更好的细节保存方面有改进
附录E:风格化效果控制
传统的使用前馈自动编码器的艺术风格转移方法(如WCT、AdaIN)通常采用转移特征与内容特征(getfrom VGG编码器)的混合来控制风格化的效果。我们的方法,作为一种基于自动编码器的方法,自然支持这样一种控制样式转换效果的方法。此外,如预分析中所述,还可以使用影响逼真风格转换效果的建筑模块,根据用户的偏好对风格转换效果进行微调。此外,我们发现WCT的一个内部参数对写真风格化效果有微妙的影响。我们通过回顾WCTtransfer模块的细节来开始解释这一点。

![]()
注意,fc和fs分别表示编码器的零均值内容和样式特征。fcs =fΛcs +ms为转移特征,其中ms为均值。在公式8中,我们必须使用−1/2c来得到fΛcs。为了保证数值的稳定性,我们应该增加一个ε,以确保Dc每个元素不太接近于零。所以WCT的最终方程是
![]()
我们发现这对摄影写实的风格化效果有潜移默化的影响。图20显示了具有ε序列的逼真风格转移结果。我们发现,如果内容照片是有噪声的,ε过小通常会使生成的结果包含太多的噪声。请参见图20的底部,例如由过小的ε引起的噪声结果。令人惊讶的是,在某些情况下,风格化效果与较小或较大的ε保持一致。请看图20的首图。我们认为这两个有争议的案例证明了Eq. 9中Es和Ec对Dc和Ds有更强的影响。总体而言,ε在某些情况下对平衡信噪比和保持内容具有一定的作用。我们在实验中选择ε= 0.3。请注意,WCT使用 ε= 1,因为他们使用了更高的ε,所以预计会有更好的内容细节保留。但是我们的方法保留了更多的细节,这证明了我们算法的有效性。此外,我们允许用户调整ε以获得最理想的程式化结果。
图20:不同ε值的风格化效果。最上面一行是一个例子,样式转移的影响保持完整,但ε变化。相反,底部一行显示了一个例子,风格化图像包含更多的噪声和更低的ε值。请放大以查看底部图像中的天空细节。
附录F:逼真的视频传输
图21:逼真的视频传输结果。
因为我们的算法有很强的保存内容细节的能力。该方法可以直接用于实现逼真的视频传输,无需进行任何修改。我们在图21中展示了一系列视频帧。传输的帧风格基本一致,视频稳定。您可以在我们上传的文件中找到传送的视频。
附录G:我们的失败案例
由于我们没有使用预先条件的区域掩模和面向平滑的后处理,我们的方法可能更亲
导致两种失败的情况:1)如果风格照片包含几个显著不同的风格因素,我们的方法可能会在这种情况下褪色。例如,请参见图22 ©的顶部行。建筑物的上部是根据蓝天的风格而不是黄色的灯光渲染的。2)如果输入的内容照片包含明显的噪声,生成的图像也可能看起来有噪声。在某些风格中,这样嘈杂的图像可能看起来不像照片。我们在图22 ©的下面一行展示了这个案例的一个例子。我们将在未来的工作中尝试修复这些失败案例