生成对抗网络是一种基于可微生成器的生成式建模方法。
生成对抗网络基于博弈模型,其中生成器网络(generator network)必须与其对手判别器(discriminator)竞争。生成器直接生成样本 x = g(z ; θ(g)) 。其对手,判别器网络会尝试区分生成器生成的样本和训练数据中抽取的样本。生成器由 d(x ; θ(g)) 生成一个概率值来判别样本 x 是从训练数据中抽取的样本还是由生成器生成的 ‘赝品’ 。
生成对抗网络是一种生成模型,GANs的结构和我们之前见到的神经网络略为不同。大体上来说,GANs有生成器Generator和辨别器Discriminator组成,基本的结构图如下:
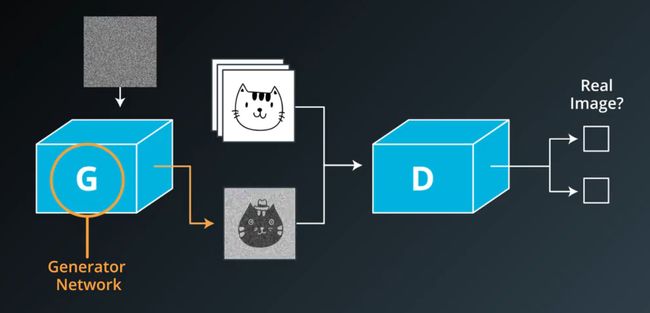
GANs结构示意图
工作原理
我们通常使用两个优化算法来训练GANs。判别器是一个普通的神经网络分类器,训练的过程中,我们使用辨别器 (discriminator) 学习引导生成器。
判别器:
在训练的过程中,我们向辨别器discriminator输入的数据一半来自于真实的训练数据,另一半来自于生成器生成的假图像。在训练的过程中,对于真实数据,判别器尝试向其分配一个接近1的概率(为更好泛化,一般会使用smooth参数将labels设为略小于1的值,如0.9);而对于生成器生成的‘赝品’,判别器尝试向其分配一个接近0的概率。也就是说,对于真实数据,我们使用label=1计算代价函数来训练判别器,其代价函数的计算方法为:
d_loss_real = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(logits=d_logits_real, labels=tf.ones_like(d_logits_real) * (1 - smooth)))
对于生成器,我们使用label=0计算代价函数来训练判别器,其代价函数的计算方法为:
d_loss_fake = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(logits=d_logits_fake, labels=tf.zeros_like(d_logits_fake)))
所以判别器的代价函数为:d_loss = d_loss_real + d_loss_fake
生成器:
与此同时,生成器尝试做相反的事情,它经训练尝试输出能使辨别器分配接近概率1的样本。生成器的代价函数为
g_loss = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(logits=d_logits_fake, labels=tf.ones_like(d_logits_fake)))
随着以上训练的进行,判别器‘被迫’增强自身的判别能力,而生成器‘被迫’生成越来越逼真的输出,以欺骗判别器。理论上,最终生成器和判别器会达到一种均衡“纳什均衡”。
Discriminator和Generator损失计算
GANs和很多其他模型不同,GANs在训练时需要同时运行两个优化算法,我们需要为discriminator和generator分别定义一个优化器,一个用来来最小化discriminator的损失,另一个用来最小化generator的损失。即loss = d_loss + g_loss
d_loss计算方法:
对于辨别器discriminator,其损失等于真实图片和生成图片的损失之和,即 d_loss = d_loss_real + d_loss_fake , losses 均由交叉熵计算而得。在 tensorflow 中可使用以下函数:
tf.nn.sigmoid_cross_entropy_with_logits(logits=logits, labels=labels)
在计算真实数据产生的损失d_loss_real时,我们希望辨别器discriminator输出1;而在计算生成器生成的 ‘假’ 数据所产生的损失d_loss_fake时,我们希望discriminator输出0.
因此,对于真实数据,在计算其损失时,将上式中的labels全部都设为1,因为它们都是真实的。为了是增强辨别器discriminator的泛化能力,可以将labels设为0.9,而不是1.0。
对于生成器生成的‘假’数据,在计算其损失d_loss_fake时,将上式中的labels全部设为0。
g_loss计算方法:
最后,生成器generator的损失用 '假' 数据的logits(即d_logits_fake),但是,现在所有的labels全部设为1(即我们希望生成器generator输出1)。这样,通过训练,生成器generator试图 ‘骗过’ 辨别器discriminator。
实例
一个使用GANs的来生成MNIST数据的代码示例。