数据结构之串(string)
串(string) :是由零个或多个字符组成的优先数列,又名叫字符串
1.串的比较
给定2个串:s = "a1a2...an", t = "b1b2...bm",当满足以下条件之一时,s<t.
1) n < m,且ai = bi(i=1,2,...,n)
例如: s = "ss", t = "ssu",就有s<t
2)存在某个K<=min(m,n),使得ai = bi (i=1,2,...,k-1), ak < bk
2.串的抽象数据类型
ADT 串(string)
Data
串中元素仅由一个字符组成,相邻元素具有前驱和后继关系.
Operation
StrAssign(T,*chars): 生成一个其值等于字符常量chars的串T.
StrCopy(T,S): 串S存在,由S复制得到T.
ClearString(S): 串S存在,将串清空.
StringEmpty(S): 若串为空,返回true,否则返回false.
StrLentgth(S) : 返回串S的元素个数,即串的长度.
StrCompare(S,L): 比较S和T,若S>T,返回>0,S==T返回0, S<T返回<0
SubString(Sub, S, pos, len): 串S存在,1<=pos<=StrLentgth(S),且 0<=len<=StrLentgth(S)-pos+1,用Sub返回串S的第pos个起
长度为len的子串.
Index(S,T,pos)
Replace(S,T,V) 串S,T,V存在,T是非空串,用V替换S中出现的所有与T相等的不重叠的子串.
StrInsert(S,T,pos): 在串S的第pos个字符之前插入串T.
StrDelete(S,pos,len): 从串S中删除第pos个字符起的长度为len的子串.
endADT
3.串的顺序存储结构与串的链式存储结构
1).Turbo C 语言
在C语言中字符串和字符数组基本上没有区别,都需要结束符;如:char s[4]={'a','b','c','d'};此字符数组的定义编译可以通过,但却没有关闭数组,若其后需要申请内存,那么以后的数据均会放入其中,尽管它的长度不够,但若为 char s[5]={'a','b','c','d'};】
则系统会自动在字符串的最后存放一个结束符,并关闭数组,说明字符数组是有结束符的;而 字符串定义的长度必须大于字符序列的长度,如:char s1[4]={"abcd"};编译不能通过,而应写成char s1[5]={"abcd"};并且系统会自动在字符串的最后存放一个结束符,说明字符串有结束符;
在C语言中使用strlen()函数可以测数组的长度:
char s[4]={'a','b','c','d'};
char s1[5]={"abcd"};
int a=strlen(s);
int b=strlen(s1);
运行后,a=8,b=4;
因为a没有足够的长度,所以没有自动添加结束符,而strlen()函数计算的时候不包含结束符'\0',
所以b=4,但
char s[5]={'a','b','c','d'};
char s1[5]={"abcd"};
int a=strlen(s);
int b=strlen(s1);
结果是a,b均为4;
2).Java语言
字符串和字符串数组都是不需要结束符的;
如:char[] value={'j','a','v','a','语','言'};
String s1=new String(value);
String s2="java语言";
其中字符数组value和字符串s1,s2都没有结束符,
int a=value.length;
int b=s1.length();
int c=s2.length();
运行得到的结果a,b,c都是6,说明字符串和字符串数组都不需要结束符。
但注意此处value.length和s1.length(),在数组中有名常量length可以记录数组对象的长度,而length()是File类中的一个实例方法,用于返回文件的大小,当然也可以返回字符串的大小。
在C语言中,字符数组和字符串均可以使用 变量名[i],如:s[1],s1[2];在java中字符数组可以使用,如:value[2],而字符串就不可以用,如:b[2],c[4],就会发生错误。
4.串的匹配算法
1)BF( Brute Force)算法(朴素算法)

BF算法的设计思想是将主串S的第一个字符和模式串T的第一个字符比较,若相等,则继续比较后续字符;
若不相等,则从主串S的第二个字符起,重新与T的第一个字符比较,直至主串S的一个连续子串字符序列与模式串T相等,
返回值为S中第pos个字符之后中与T匹配的子序列第一个字符的序号,即匹配成功;否则,匹配失败,返回-1。最坏的情况下,时间复杂度为0(strlen(S)*strlen(p)):O(m*n)。
/*p非空,1<= pos <=strlen(p)*/
int match(const char* S, const char* p, int pos)
{
int i = pos,j = 0;
while(i<strlen(S) && j<strlen(p))
{
if(S[i] == p[j]) /*两个字母相等则继续*/
{
i++;
j++;
}
else /*指针后退重新开始匹配*/
{
i = i-j+2; /*i指针退回到上次匹配首位的下一位*/
j=0; /*j退回到串p的首位*/
}
}
if(j > strlen(p))
return i-strlen(p);
else return -1;
}
2)KMP模式匹配算法
I定义:由D.E.Knuth、J.H.Morris和V.R.Pratt共同提出了一个改进算法,消除了Brute-Force算法中串s指针的回溯,完成串的模式匹配。
时间复杂度为O(s.curlen+t.curlen):O(m+n),这就是Knuth-Morris-Pratt算法,简称KMP 算法。
II KMP算法形成过程:
若S[i]≠P[j] ,为使主串指针 i不回溯,可以从模式串的第k个字符开始比较,即让 j重新赋值k。k值如何确定?
若S[i]≠P[j] , j重新赋值为 k,必有:P1P2 …..Pk -1=Si -k +1 Si -k +2 ……Si -1.
同样必有:Pj -k+1Pj -k+2 ……Pj -1= Si -k +1 Si -k +2 ……Si -1.因此Pj -k+1Pj -k+2 ……Pj -1= P1P2…..Pk -1.


III.KMP算法的基本思想:
设目标串为s,模式串为t
i、j 分别为指示s和t的指针,i、j的初值均为0。
若有 si = tj,则i和j分别增1;否则,i不变,j退回至j=next[j]的位置 ( 也可理解为串s不动,模式串t向右移动到si与tnext[j]对齐 );
比较si和tj。若相等则指针各增1;否则 j 再退回到下一个j=next[j]的位置(即模式串继续向右移动),再比较 si和tj。
依次类推,直到下列两种情况之一:
1)j退回到某个j=next[j]时有 si = tj,则指针各增1,继续匹配;
2)j退回至 j=-1,此时令指针各增l,即下一次比较 si+1和 t0。
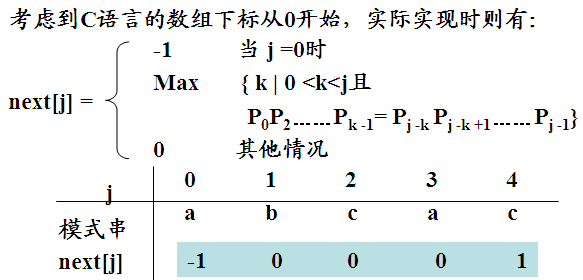
3、next[j]的求法
由定义: next[0]=-1;
设 next[j]= k,则有P0P1P2 …..Pk -1= Pj -kPj -k+2 ……Pj -1. next[j+1]= ?
1)若 Pk=Pj,必有P0P1P2 …..Pk -1Pk= Pj -kPj -k+2 ……Pj -1Pj,因此 next[j+1]=k+1=next[j]+1;
2) 若 Pk≠Pj,则P0P1P2 …..Pk -1Pk≠Pj -kPj -k+2 ……Pj -1Pj.在当前匹配的过程中,已有P0P1P2 …..Pk -1= Pj -kPj -k+2 ……Pj -1。
若Pk≠Pj,应将模式向右滑动至以模式中的next[j]= k个字符和主串中的第j个字符相比较。若 k’=next[k],且Pk’=Pj,则说明存在一个长度为k’的子串相等:
P0P1P2 …..Pk’ -1= Pj –k’Pj –k’+2 ……Pj -1且满足: 0<k’<k<j; Pk’= Pj
此时有:next[j+1]=k’+1=next[k]+1
3)否则 若Pk’≠Pj:继续重复该过程。若k’=0:则令next[j+1]=0 .( k’=0,next(k’)=-1).



IV.KMP算法的C语言描述

V.KMP算法的C语言实现
#include "stdio.h"
#include "stdlib.h"
#include "string.h"
#include "ctype.h"
#define OK 1
#define ERROR 0
typedef int Status; // Status是函数的类型,其值是函数结果状态代码,如OK等
typedef int Boolean; // Boolean是布尔类型,其值是TRUE或false
#define N 16 // 数据元素个数
#define MAXKEYLEN 16 // 关键字的最大长度
#define STACK_INIT_SIZE 10 // 存储空间初始分配量
#define STACKINCREMENT 2 // 存储空间分配增量
typedef struct
{
char *ch;
int length;
}HString;
void InitString(HString &T)
{ // 初始化(产生空串)字符串T
T.length=0;
T.ch=NULL;
}//InitString
int StrAssign(HString &T,char *chars)
{// 生成一个其值等于串常量chars的串T
int i,j;
if(T.ch)
free(T.ch); //释放T原有空间
i=strlen(chars);//求chars的长度i
if(!i)
{//chars的长度为0
T.ch=NULL;
T.length=0;
}//if
else
{
T.ch=(char*)malloc(i*sizeof(char));//分配串空间
if(!T.ch) exit(-1); //失败
for(j=0;j<i;j++)
T.ch[j]=chars[j];
T.length=i;
}//else
return OK;
}//StrAssign
void StrPrint(HString &T)
{
int i;
for(i=0;i<T.length;i++)
printf("%c",T.ch[i]);
printf("\n");
}//StrPrint
void get_next(HString T,int next[])
{ // 求模式串T的next函数修正值并存入数组next
int i=1,j=0;
next[0]=-1;
while(i<T.length)
if(j==-1||T.ch[i]==T.ch[j])
{
++i;
++j;
next[i]=j;
}//if
else j=next[j];
}//get_next
int Index_KMP(HString S,HString T,int pos,int next[])
{ // 利用模式串T的next函数求T在主串S中第pos个字符之后的位置的KMP算法。
// 其中,T非空,1≤pos≤StrLength(S)
int i=pos,j=0;
while(i<S.length&&j<T.length)
if(j==-1||S.ch[i]==T.ch[j]) // 继续比较后继字符
{
++i;
++j;
}
else // 模式串向右移动
j=next[j];
if(j>=T.length) // 匹配成功
return i-T.length;
else
return 0;
}//Index_KMP
void OutprintS(HString &t)
{
StrPrint(t);
}//OutprintS
void InputS(HString &s)
{
char ch[80];
printf("input the String:\n");
scanf("%s",ch);
StrAssign(s,ch);
}//InputS
int main()
{
int i,pos=1,p[N];
HString t,s;
InitString(s);//由于HSring定义了指针,所以必须初始化
InitString(t);
InputS(s);
InputS(t);
printf("串S为: ");
OutprintS(s);
printf("串T为: ");
OutprintS(t);
get_next(t,p);
i=Index_KMP(s,t,pos,p);
printf("主串和子串在第%d个字符处首次匹配\n",i+1);
return 1;
}
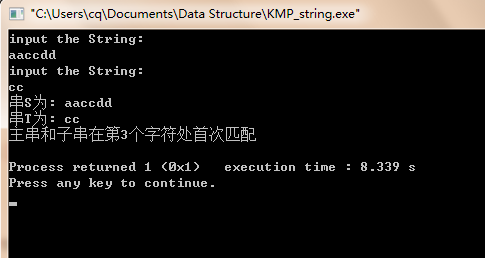
运行结果: