李宏毅机器学习28——more about auto-encoder
摘要:
上节课讲了auto-encoder,这节课更详细的学习auto-encoder。
主要从两个角度来学习。
一是衡量encoder好坏的其他方法。与minimize reconstruction error不同,这里引入了判别式模型,来衡量embedding和输入的密切程度。通过训练encoder中的参数和判别式模型中的参数,来找到最合适的encoder。
二是对embedding的解释。为了让embedding更好的解释,我们可以通过特征解缠的方法,将不同的信息分类,主要学习两种做法,一个是通过GAN,一个是通过改变encoder的结构,将不同信息分开。
为了使embedding更好的解释,我们还可以将embedding转换成离散的向量,如果是音频信息,这就可以做到噪音过滤了。
还可以训练一个seq2seq2seq的Auto-encoder,将sequence当做embedding,在此基础上加上GAN,就可以生成符合语法的摘要了。
目录
一、衡量encoder好坏的其他方法
1.什么是好的embedding?
2.Discriminator
二、如何让embedding更容易被解释
1.feature disentangle
2.解释embedding
实际应用:
1.VQVAE
2.sequence as embedding
总结:
Auto-encoder主要包含一个编码器(Encoder)和一个解码器(Decoder)。Encoder接收一张图像,输出一个vector,上节课中称他为code,也可以叫它Embedding、Latent Representation或Latent code,这个vector是关于输入图像的表示;然后将vector输入到Decoder中就可以得到重建后的图像,我们希望输出图像和输入图像越接近越好,这个方法叫做reconstruction error。
这节课更深入的学习auto-encoder,主要围绕两方面
一、为什么一定要minimize reconstruction error,有没有其他方法?
二、如何理解embedding?

一、衡量encoder好坏的其他方法
1.什么是好的embedding?
一个好的embedding应该可以很好地代表输入的事物。首先embedding应该和object有密切的关系。
用李宏毅老师的例子,左边的人物始终带着耳机,因此耳机这个vector应该和左边的人物是相联系的。

2.Discriminator
首先我们有一个encoder,
三九(上面的人物)通过encoder,得到的输出为蓝色的embedding
凉宫春日(下边的人物)通过encoder,得到输出为黄色的embedding
我们如何评估一个encoder的好坏呢?
我们可以训练一个discriminator(判别器,GAN中的知识,类似于二分类),输入是一个image和embedding,输出结果是看image和embedding是否是一对。
我们有了训练资料,就可以得到一个loss函数,假设判别器的参数是φ,我们可以训练φ,minimize loss函数。假设最低的loss函数为Ld*。
当Ld*很小时,说明embedding和image是一对(也就是embedding可以代表image,encoder表现很好)
如果是下图中的情况,两个image的embedding都是灰色,判别器没办法区分开image和对应的embedding,yes和no的情况不够明显,这就会使Ld*很大。
因此Ld*很大,就说明encoder转换出的embedding不够有代表性,也就是encoder很差。

上边的结论说明Ld*越小,encoder表现越好。
这样我们可以把这两项连在一起,encoder的参数为θ,那么可以通过minimize Ld*得到表现好的encoder
这两个操作连在一起,可以发现auto-encoder其实就是它的一种特例。
image和vector输入到判别器中,得到的结果score,就是auto-encoder的reconstruction error

二、如何让embedding更容易被解释
1.feature disentangle
一个object包含多个方面的信息。
例如一段语音,处理本身想表示的信息,还包括说话人的音色,环境的杂音等等
一段文字,其中有语义的信息,还有语法的信息。
因此,一段音频通过encoder得到的embedding,其中一些维度表达的是音频的内容信息,另一些维度表达的是说话人、环境杂音等无关的信息。

我们希望encoder可以自动将这两类信息分开,就像下图提供的两种方法一样。

假设我们可以将声音信息和内容信息分开,通过下图的方式,将语音和内容分开,再组合,得到男声说How are you?的音频,这样就能达到变声器的效果

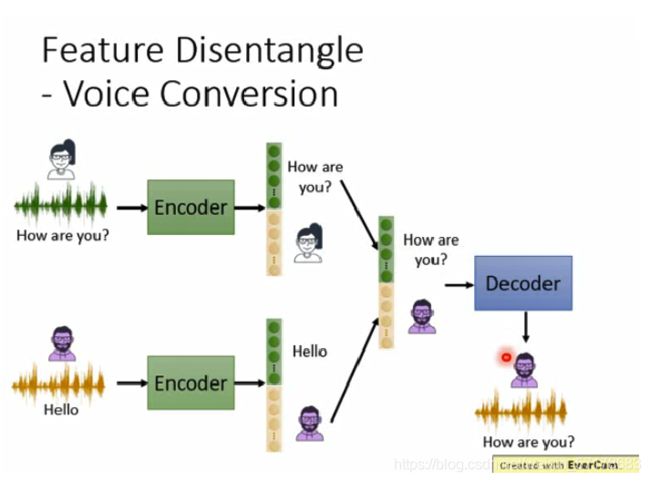
理论和应用都有了,那么最大的问题是如何把声音信息和内容信息分开了。
做法一:
首先,我们训练一个声音信息的分类器,将embedding的前100维吃进去,判断encoder的输入音频是男还是女。我们希望encoder能骗过分类器,让被吃进去的那部分embedding,尽可能不包含声音信息(也就是让分类器表现很差)。如果我们能成功做到的话,这样声音信息就都藏到了embedding的后面,这样前100维就只剩下内容信息了。
实现这个方法,通常使用GAN。其中这个分类器,其实就是discriminator,encoder就是生成器,实际操作中,先训练speaker classifier,再训练encoder,反复训练这两项,直到表现足够好。
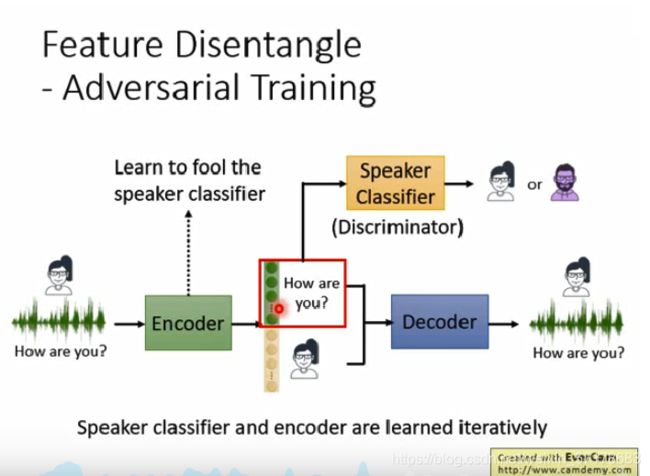
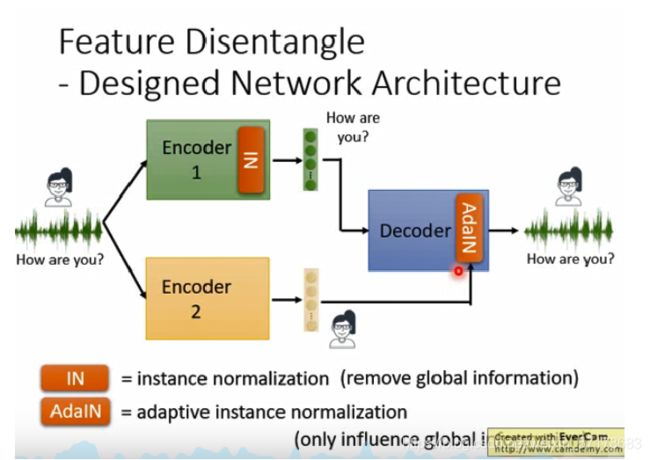
做法二:
改变encoder的架构,使encoder直接将内容信息和声音信息分类,同时在encoder1中使用instance normalization,然后将得到的两个embedding,分别送入decoder重建输入数据,其中encoder2得到的embedding,还经过了adaptive instance normalization。
2.解释embedding
前提:如果embedding可以由连续的向量转变为离散的向量,那应该可以更好的分析embedding的含义。
例如:将embedding转换成one-hot编码,做法很简单,将embedding中最大的维度设置成1,其他维度设置成0。之后将one-hot编码丢个decoder,还原成之前的图片。
同样可以将embedding转换成Binary向量,将embedding中维度大于0.5的项转换成1,小于0.5转换成0,其他做法和上面一样。
这个模型在连续向量到离散向量的这一步,是不可做微分的(无法梯度下降),但是可以通过non differentiable进行计算
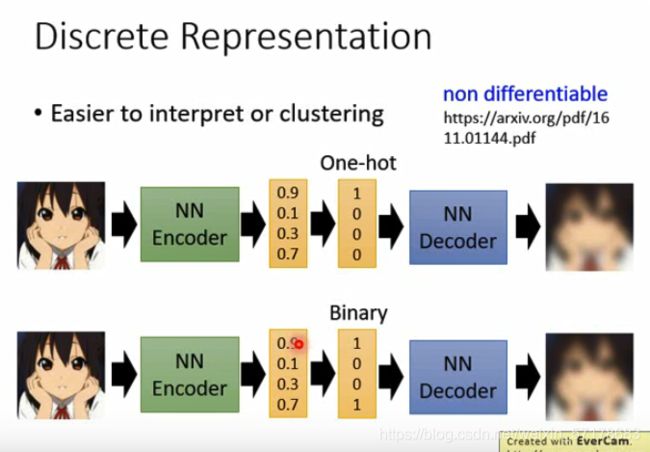
当然,上面两个离散向量的模型比较起来,Binary模型要好,原因有两点:
1、同样的类别,Binary需要的参数量要比one-hot编码少。
2、使用Binary模型可以处理在训练数据中未出现过的类别。
实际应用:
1.VQVAE
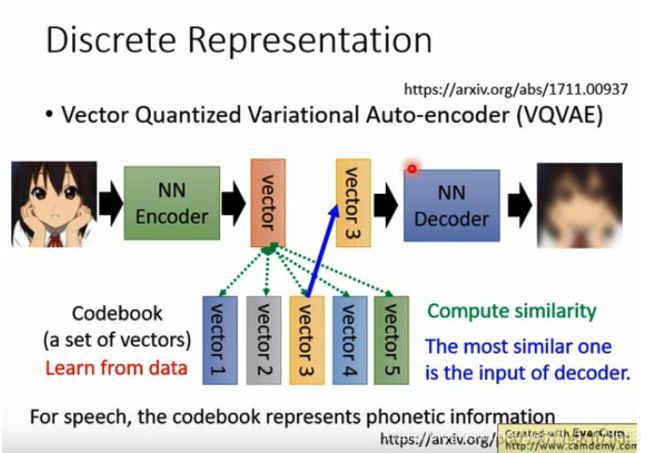
Vector Quantized Variational Auto-encoder (VQVAE)
它引入了通过训练得到的code book。它是将embedding分为了很多的vector,然后比较哪一个和输入更像,就将其丢给decoder重建输入。
第一步:图像通过encoder得到连续的vector。
第二步:用vector与codebook中的5个离散向量Vectori 进行相似度计算,假设vector3与红色vector最接近。
第三步:将vector3当做decoder的输入,用来还原图像。
应用:音频信息过滤
上面的模型中,如果输入的是音频信息,那么声音信息和噪音信息会被过滤掉。
因为上面的Codebook中保存的是离散变量,而内容信息是一个个的字,是离散的信息,容易用离散向量来表示的,而其他信息不适合用离散变量表示,因此会被过滤掉。
2.sequence as embedding
既然可以用离散向量来表示输入信息,那么我们也可以考虑用句子来做embedding
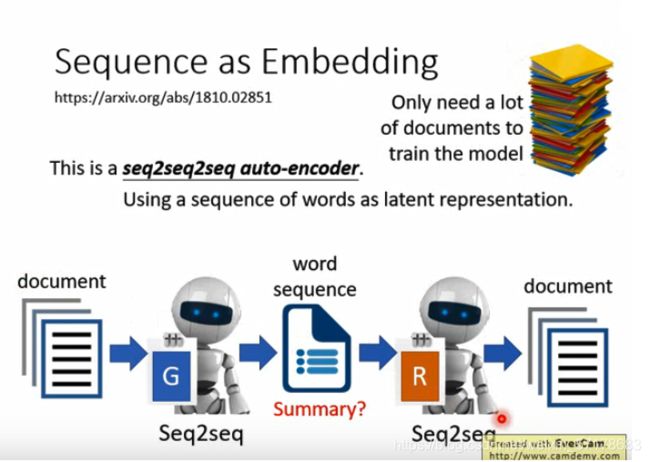
我们可以训练一个seq2seq2seq的Auto-encoder。
例如:输入一篇文章给encoder,输出一段文字作为embedding,然后将这串文字再通过decoder,恢复原文章。中间的文字是应该就是摘要。
但是这个模型效果是不好的,例如:台湾大学会被机器抽取为:湾学,而不是台大。因为模型只要还原原文,回到台湾大学,而没有要求抽取出来的东西要符合语法规则。
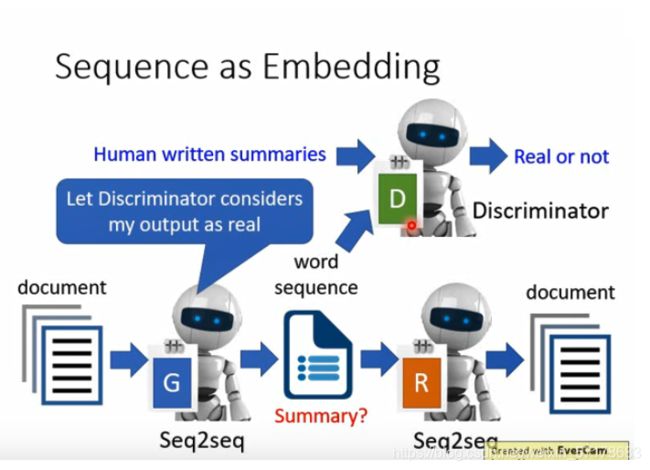
为了让句子符合语法,这就需要GAN。
训练一个判别器,当输入是上面提到的句子时,输出时no;让输入是人写摘要时,输出yes。
然后我们希望整个模型可以骗过判别器,这样得到的encoder和decoder就可以实现生成符合语义的摘要。
总结:
自编码器(Autoencoder,AE),就是一种利用反向传播算法使得输出值等于输入值的神经网络,它现将输入压缩成潜在空间表征,然后将这种表征重构为输出。所以,从本质上来讲,自编码器是一种数据压缩算法,其压缩和解压缩算法都是通过神经网络来实现的。自编码器有如下三个特点:
数据相关性。就是指自编码器只能压缩与自己此前训练数据类似的数据,比如说我们使用mnist训练出来的自编码器用来压缩人脸图片,效果肯定会很差。
数据有损性。自编码器在解压时得到的输出与原始输入相比会有信息损失,所以自编码器是一种数据有损的压缩算法。
自动学习性。自动编码器是从数据样本中自动学习的,这意味着很容易对指定类的输入训练出一种特定的编码器,而不需要完成任何新工作。